 华人学者Nature上发表最新成果 世界最快光子AI加速器
华人学者Nature上发表最新成果 世界最快光子AI加速器

人工神经网络广泛应用于人脸识别、语音翻译、医疗诊断、自动驾驶等重要领域,其性能主要由硬件算力决定,目前所广泛应用的神经网络硬件都基于数字电子架构。然而,该架构的两个本质局限—冯诺曼依瓶颈与电子速率瓶颈,极大限制了神经网络硬件的潜在算力。首先,数字架构中,数据的存储和运算是分布式的,因而在计算过程中,会有大量的能源和算力消耗在数据的反复读取和存储中,此限制被称为冯诺曼依瓶颈。其次,由于电子微处理器中的寄生电容和互联时延问题,电子系统存在着本质的带宽限制,导致电子微处理器的主频事实上在过去十年已没有明显提升,此限制也被称为电子速率瓶颈。
光子神经网络工作于模拟架构中,即数据在硬件系统中的实时位置与进行运算的位置相同,因而规避了冯诺曼依瓶颈。此外,宽达数十太赫兹的光谱也为高速运算提供了充足的带宽。目前已有来自加州大学、麻省理工学院、明斯特大学等单位的研究团队做出了一系列在网络尺度、可集成性、片上存储等方面的突破,然而尚未能实现较高运算速度与高维数据处理能力,光子神经网络的超高运算潜力尚未得到证实。
近日,澳大利亚研究人员徐兴元博士(莫纳什大学)、谭朦曦博士、David Moss教授(斯文本科技大学)、Arnan Mitchell教授(皇家墨尔本理工大学)等首次提出并实现了基于波长、时间交织的光子卷积加速器。该文章以“ 11 TOPS photonic convolutional accelerator for optical neural networks”为题发表在Nature。
研究人员通过采用集成高品质因素、高非线性微环与波导色散调控,实现了高相干度、易于产生的集成克尔孤子晶体光频梳。
研究人员将该光频梳进行频域整形并且与高速光电调制相结合,实现了输入数据在并行波长通道上的组播与加权,然后采用光学色散介质作为缓存,对组播信号进行了步进延时(步长为单个码元时长),从而在时域上对齐了不同波长通道中需要加权求和的码元,最后通过光电转换实现处理结果的高速实时读取(如图1所示)。通过这一系列步骤,波长构架的卷积窗口(感知域)即可在时域以超过60GBaud的速率滑动,结合克尔光频梳所实现的高并行度(C波段90个波长通道),实现了11 TOPS(太运算每秒)的运算速度,即每秒可完成11万亿次运算。
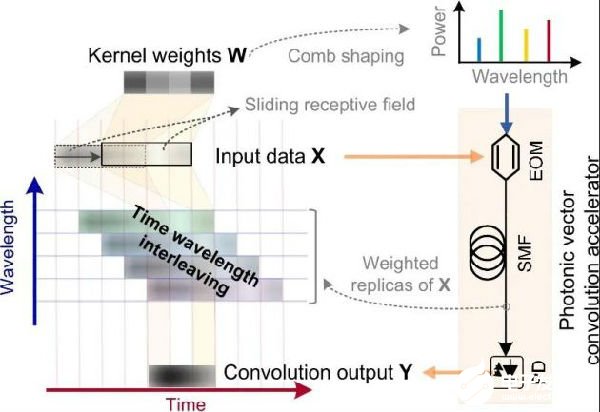
图1 卷积加速器工作原理
图源:Nature 589, 44–51 (2021)。 Fig 1
通过这一系列步骤,数学模型抽象的神经元突触就被光频梳在实际物理系统中实现,其中突触连接的权重由光频梳的光功率体现。最终实验验证了高维图片处理(实验结果如图2所示)以及深度学习光子卷积神经网络(实验结果如图3所示)。
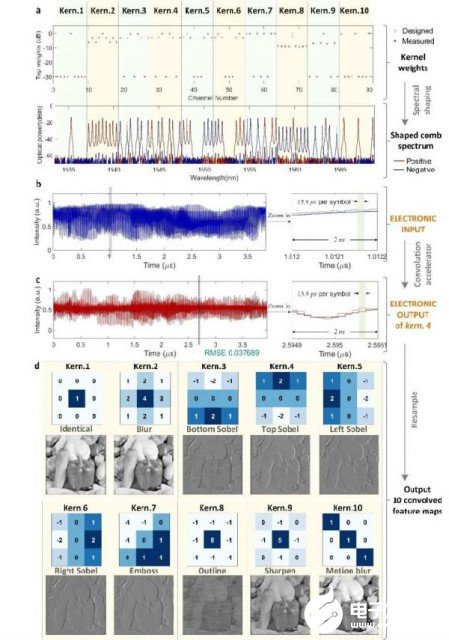
图2 卷积图像处理结果
图源:Nature 589, 44–51 (2021)。 Fig 3
在国际相关研究成果的基础上实现了数个突破,包括:
1. 由于集成克尔光频梳所提供的大量波长通道,运算速度首次突破到11 TOPS以上;
2. 首次实现了利用光学手段进行高维数据处理(25万像素点),为光子神经网络的进一步实际应用如人脸识别等展现了可能;
3. 实现了500张MINIST手写数字图片的高速分类预测,准确率达到88%以上;
4. 实现了具备高速光电接口的硬件加速器,速度可达64G Baud以上,并且可与现有电子或者光学硬件兼容互联;
5. 结合应用了集成克尔光频梳,为实现光子神经网络的单片集成奠定了基础。
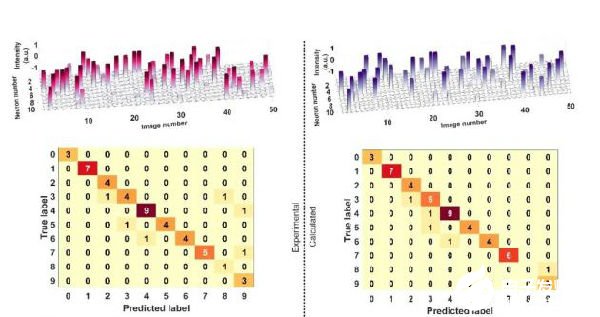
图3 卷积神经网络50张手写数字识别结果。上图为全连接层神经元输出幅度,下图为混淆矩阵。
图源:Nature 589, 44–51 (2021)。 Fig 6
后续,研究人员将继续优化本方案的性能指标,如处理速度、并行度、体积与可集成性、功耗等。本工作实验证明了光子神经网络硬件的运算潜力,并且具有高速光电接口,未来可作为通用卷积特征提取前端与其他光电模数架构互联,在卷积神经网络中可承担70%以上的运算负荷,大幅提升系统整体算力,在未来实时人工智能应用场景如无人驾驶、医疗诊断等方面有重要应用。
责任编辑:PSY
-
晶体管
+关注
关注
78文章
10284浏览量
146488 -
人工智能
+关注
关注
1813文章
49780浏览量
261862 -
光子芯片
+关注
关注
3文章
110浏览量
25195 -
AI加速器
+关注
关注
1文章
73浏览量
9442
发布评论请先 登录
边缘计算中的AI加速器类型与应用

亚马逊云科技第三期创业加速器圆满收官 助力初创释放Agentic AI潜力 加速全球化进程
航裕电源以大电流技术为国内外超导加速器项目提供优质方案
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
Andes晶心科技推出新一代深度学习加速器
Arm神经技术是业界首创在 Arm GPU 上增添专用神经加速器的技术,移动设备上实现PC级别的AI图形性能
粒子加速器 —— 科技前沿的核心装置

机器学习赋能的智能光子学器件系统研究与应用

基于双向块浮点量化的大语言模型高效加速器设计
光子 AI 处理器的核心原理及突破性进展
曦智科技时隔八年再登《Nature》,光电混合计算架构首次公开

嵌入式AI加速器DRP-AI 详细介绍





 工商网监
工商网监
评论