 片上多核系统与片上网络的发展
片上多核系统与片上网络的发展

1. 片上多核系统与片上网络的发展中的
1.1 片上多核系统发展的两条演进路线
系统级芯片也被称为片上系统,是指在单个芯片内部实现大部分甚至完整的电子系统功能的一种芯片。这种芯片是高端电子系统的核心,随着集成电路工艺技术的发展也逐步向中低端电子系统发展。如今,很多诸如腕表、手环之类的可穿戴设备以及智能玩具等低端嵌入式设备也都以系统级芯片为核心来开展设计。可以说片上系统已经成为集成电路,尤其是数字集成电路的主要实现形式。
由于集成电路工艺在摩尔定律的驱使下飞速发展,单位面积上的晶体管数量不断增加。根据登纳德缩放比例(晶体管面积的缩小使得其所消耗的电压以及电流会以差不多相同的比例缩小。也就是说,如果晶体管的大小减半而时钟频率不变,该晶体管的功耗将会降至四分之一)。,使用新的集成电路工艺可以让设计者可以大大地提高芯片的时钟频率,因为提高频率所带来的更多的功耗会与晶体管缩放减少的功耗抵消,芯片的性能可以依靠不断的提升时钟频率来获得提高(当然,也要配合架构设计的改进,例如利用增加的晶体管设计更多而且更为合理的高速缓存)。这样在芯片内部集成更多的晶体管的时候,提高芯片时钟频率成为了一个“免费的午餐”。
而2005年前后,晶体管微缩到一定程度以后量子隧穿效应(指像电子等微观粒子能够穿入或穿越位势垒的量子行为)开始慢慢介入,使得晶体管漏电现象开始严重。漏电现象的出现打破了原先登纳德所提出的定律。单纯提高时钟频率将造成芯片功耗难以控制。功耗增大除了更费电不环保之外,带来的最大问题是增加的功耗会转化为热量。在微小的芯片面积上大量功耗密集堆积会导致温度急剧增加。如果散热做的不好,芯片的寿命将大大减少甚至变得不稳定。在这种情况下,提高芯片的时钟频率不再是免费的午餐。在没有解决晶体管漏电的问题之前,单纯的增加芯片的时钟频率因为随之而来的散热问题而变得不再现实。于是芯片研究商们开始纷纷停止高频芯片的研发,转而向低频多核的架构开始研究,用更多但频率更低的核心来替代一个高频率的核心。这种具备多个运算核心的片上系统就是片上多核系统。
近10年来片上多核系统一直是数字集成电路领域的热点,经过众多研究者的不断努力诞生了大量很有意义的研究成果。片上网络,本质上是为了解决片上多核系统中不同的核心之间,核心与非核心(Un-Core)硬件单元之间数据传输问题的一种“片上通信”方案。因此要理解清楚片上系统的发展脉络,必须要先从片上多核系统的发展入手。否则就会出现“无的放矢”和“盲人摸象”的问题。但由于片上多核系统的研究者背景和应用领域不同导致发展演进过程较为复杂而难以理解。2012年本人及所在研究小组开始切入片上网络相关时,由于对于片上多核系统的理解不深,导致研究出现了诸多波折与困扰,导致在一年多的时间中整体研究徘徊不前。
为减少这一问题对于大家理解片上网络的影响,作为我们系列文章的开头,本文将首先总结片上多核系统的演进历史与现状。从而让大家理解出现片上网络这一技术背后的推动力,也可以看出片上网络多年来一直徘徊不前的原因。
下面就开始进入我们的正题:
第一款被大众所熟知的商用化片上多核系统是著名处理器芯片提供商之一的AMD公司面向个人电脑推出的ATHLON X2双核中央处理器Central Processing Unit (CPU),该款CPU在商业上大获成功。此后商用化片上多核系统的研制开始进入高潮。2005 年Intel发布了64位双核处理器Montecito[1],而IBM公司则发布了具有9个核心的Cell处理器[2]。此后的10年间,片上多核系统开始大量的被应用于各种信息基础设备,成为高性能电子设备的核心器件。
但实际上片上多核系统的研究开始于上个世纪90年代中期,在过去的20多年中片上多核系统架构一直处于不断发展和演进中。由于应用领域和研究人员的学术背景不同,片上多核系统的研究从一开始就有着明显的“流派”之分。随着研究的持续深入,片上多核系统出现了越来越多的技术分支。这不但让广大吃瓜群众难以辨识,对于很多刚接触片上多核系统研究的硕士生和低年级博士生而言,搞清楚这些技术分支的区别与联系也并不是一件轻松的工作。
简单来说,片上多核系统由于起源不同、应用领域不同以及研究者的学术背景不同等原因,发展出了不同的技术路线。上文提到的Intel公司发布的Montecito处理器[1]和IBM公司发布的Cell处理器[2]就代表了两种最主要的技术路线。
Montecito处理器这一类片上多核系统源于Symmetric Multi-Processing System (SMP)系统,被称之为Chip Multiprocessors (CMP)(国内一般翻译为单芯片多处理器),主要用于高性能通用计算领域。Cell处理器这一类片上多核系统则由片上系统Systemon-Chip (SoC)演进而来,被称为Multi-Processors System-on-Chip (MPSoC)。这类片上多核系统主要作为一种高端的嵌入式处理器被应用于通信、信号处理、多媒体处理等领域。为方便行文,后文中直接使用CMP和MPSoC来指代这两类处理器。
采用CMP架构的片上多核系统通常被应用于工作站、服务器、云计算平台等通用计算设备,所运行的主要应用通常是以科学计算、仿真模拟为代表的大数据量通用计算。这类片上多核系统大多采用数据并行的并行程序开发模式,以共享存储器的方式来交换数据。这样的好处在于开发难度较低、程序的通用性较好,可以借用类似于OpenMP[3]这样已经较为成熟的并行编程模型加以开发。又由于科学计算、仿真模拟这类应用的特点通常是数据量超大,但不同处理器上所运行的核心程序往往是相同的。因此采用共享存储的方式可以使得多个处理器核心可以很容易共享同一块虚拟地址空间,这使得同一程序可以很方便的同时运行在不同的核心上,也可以很方便的共享同一个操作系统或管理程序。
Hydra处理器是1996年美国斯坦福大学研制集成了4个核心的处理器[4],它被认为是首款具备CMP性质的片上多核系统。
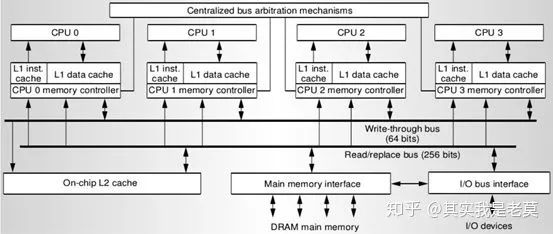
图1 Hydra处理器架构图,它被认为是首款具备CMP性质的片上多核系统
Hydra处理器采用了四个MIPS 处理核心,每个核心拥有私有的指令缓存(I-Cache)和数据缓存(D-Cache)。二级缓存为四个核心共享,通过核心自身的存储控制器(Memory Controller, MC)及一组总线与二级缓存(L2 Cache)、主存储器接口(Main Memory Interface)和输入输出总线接口(I/O Bus Interface)互连。由于片上的二级缓存为四个核心所共享,因此四个核心实质上在逻辑上具备单一的内存地址空间。这也使得共享同一个操作系统或管理程序成为可能。Hydra处理器为后续CMP架构片上多核系统的发展奠定了基础,这一架构的片上多核系统在后续的演进过程中始终被Hydra处理器的初始设计所影响。
而MPSoC诞生初期的主要代表是一些集成了多个数字信号处理器(Digital Signal Processor DSP)和微处理器(Microprocessor Unit MPU)的专用芯片。这些芯片主要被应用于数字电视、多媒体播放器等信号处理设备。与追求高性能的通用计算不同,MPSoC 主要应用领域所面临的主要问题是计算的实时性。由于计算任务的确定性更强,使得MPSoC的设计者和使用者能够也必须要精确的划分任务并合理的分配任务以应对各种挑战。
图2所示的Viper处理器[5],即为最早的一批MPSoC之一。
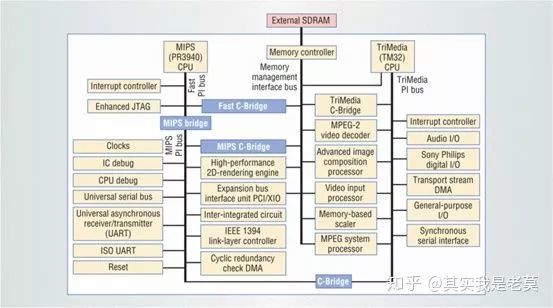
图2 Viper处理器架构示意图,它是早期MPSoC的代表之一
从图2中可以看出,整个芯片可以被划分为两个相对独立的子系统。分别以MIPS(PR3940)CPU和TriMedia(TM32)CPU为核心。图左侧为以MIPS(PR3940)CPU为核心的子系统,这部分子系统的架构类似于一个通用的嵌入式SoC芯片,集成了如UART、IEEE 1394协议控制器之类的接口模块。图右侧为以TriMedia(TM32)CPU为核心,在这一子系统中集成了如MPEG-2视频解码器、视频输入处理器等多媒体处理单元,实质上构成了一个专用的多媒体处理器。因此可以很清楚的判断Viper处理器中以MIPS(PR3940)CPU为核心的子系统主要负责通用处理器控制和数据传输方面的功能,而以MIPS(PR3940)CPU为核心的子系统则主要负责多媒体信号处理。两个子系统相对独立,通过Fast C-Bridge、MIPS C-Bridge以及C-Bridge三个总线桥相互连接。
Viper处理器的架构很清晰的体现了MPSoC的一些典型特点:按任务需求划分为若干独立的子系统,每个子系统完成一个专门的功能,子系统之间相对独立等。这种架构设计方法充分体现了嵌入式系统的特性,因而被后来的研究者所继承和发扬。
RAW[6]是一代具有划时代意义的片上多核系统。虽然它被发表于1997年,但它却奠定了今后20年采用片上网络互联的CMP的基本架构。

图3 首次采用Tile结构和网络化互联的CMP架构芯片:RAW
RAW是由美国麻省理工学院于1997年提出并流片验证(从这里也可以看出美国在于高端系统芯片领域的积累深厚,回想我们1997年的芯片设计水平也才刚刚进入到能把EDA工具流程用起来,开始做ASIC的水平。龙芯等一大批处理器芯片设计都要等到2000以后)。
RAW微处理器架构采用了一种被称为Tile(国内有国内文献有直译为瓦片,为避免歧义本文中均使用英文原文指代)的模块划分方式。这种划分方法把CPU、私有Cache(L1 Cache)、共享Cache(L2 Cache)的一个Bank(一直不知道这个该怎么翻译……)、网络接口(Network Interface NI)等硬件资源构建为一个独立的Tile。在不同的Tile在芯片规划的平面内按一定的规律整齐排列,Tile和Tile之间通过NoC加以互联。这种采用Tile来划分和组织片上多核系统的方式优势在于每个核心比较规整,有利于芯片后端设计并具备较好的可扩展性。此后虽然有一些其它形式的核心划分与组织方式的论文发表,但基于Tile的划分与组织方式始终被绝对部分研究者(灌水者)所继承。
接下来看一看比较近的一点的CMP架构的片上多核系统,32核心SPARC M7处理器[7]。发布于2015年的ISSCC上。
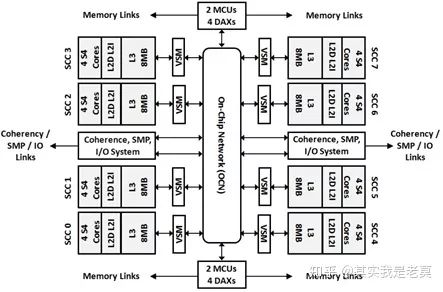
图4 32核心SPARC M7处理器逻辑结构图
该款处理器共有32个核心,每4个核心构成一个组(文章中称其为SCC),总共8个组。每个组内部共享L2 Cache,但其它组不能访问。L3 Cache为全局共享Cache,可以被所有的所有核心访问。L3 Cache同样被划分为8个独立的bank,和对应的每个组一起组成了一个完整的Tile。
为了更有效的互联各个不同的Tile,研究者为SPARC M7处理器设计了三套不同的片上网络。分别是采用环网(Ring)结构的请求网络(Request Network),采用广播(Broadcasting)结构的响应网络(Responses Network)以及采用网格(Mesh)结构的数据网络(Data Network)。不同的片上网络分别传送不同的控制信息和数据,从而使得访问Cache的效率能最大限度的提高。
片上网络成为CMP架构的片上多核系统内部互联的主流方式之后,片上缓存的组织方式也相应的发生了改变。在使用总线或交换结构的时代,CPU访问不同Cache Bank的时间是基本保持一致的。但在使用片上网络作为内部互联以后,CPU访问不同的Cache Bank的时间已经不可能保持一致了。因此一种被称为非均匀高速缓存体系结构(Non-uniform Cache Architecture, NUCA)的概念被提出。NUCA是基于片上网络的CMP片上多核系统所必然要面临的问题,但对NUMA的研究也推动了基于片上网络的CMP片上多核系统向前持续演进。改进NUMA条件下CMP架构片上多核系统的访存效率,也成为提升CMP架构片上多核系统性能的主要途径。由于这部分内容涉及到较多存储体系结构方面的研究,在计算机系统结构的研究中属于另外一个领域。超出了本文甚至本系列文章所讨论的范围,因而在此不再进一步展开讨论。
当然,也不是所有的CMP架构的片上多核系统从此就走上了依靠NoC互联的道路。当核心数量不多的时候确实没有必要考虑使用NoC。例如AMD的Zen就是没有依靠NoC而采用了一种叫Core Complex (CCX)的方式互联[8]。
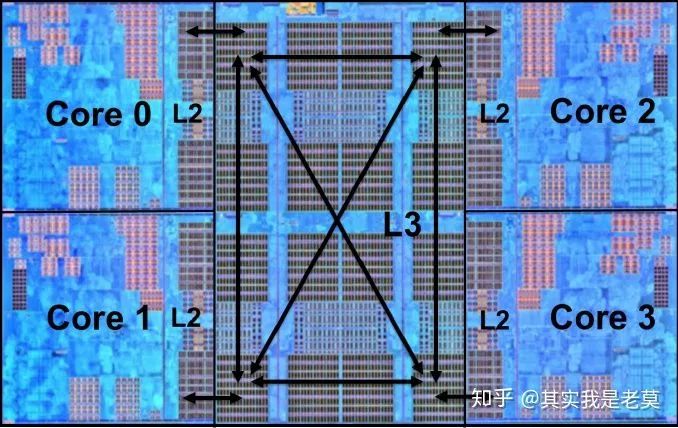
图5 采用CCX互联的Zen,依然具备CMP架构的基本特征
从图5可以看出,Zen虽然核心比较少,但仍然是典型的CMP架构。
谈了很久的CMP,我们回头再来看一看MPSoC。相比于CMP的规整、对称的架构,MPSoC是由若干个独立的子系统构成的。图6是Intel在今年ISSCC上发布的面向机器人的Robot SoC[9]。
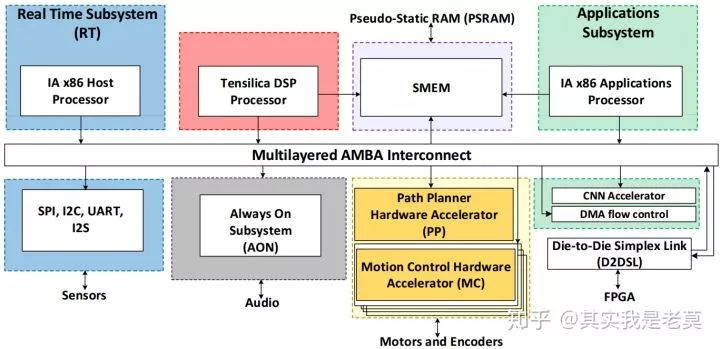
图6 面向机器人的Robot SoC,典型的MPSoC架构
图6中有若干个子系统。左边第一个是以X86处理器为核心的实时子系统,主要负责对外接口通信与控制,所以和SPI、I2C等外设接口划分到一起了。Tensilica DSP则是负责信号处理运算的一个子系统。有一个Always on子系统是常开的,主要负责音频方面的处理,应该是用于芯片的唤醒。还有路径规划硬件加速器、运动控制硬件加速器等一系列加速器以及由X86处理器配合CNN加速的应用子系统,用于实现人工智能算法。
图7是Robot SoC[9]所实现的算法,可以看出是由多个独立任务构成的。这种形式的应用比较容易被划分为若干个独立子系统来实现。这也是MPSoC主要应用领域里的各种算法 的基本特征。
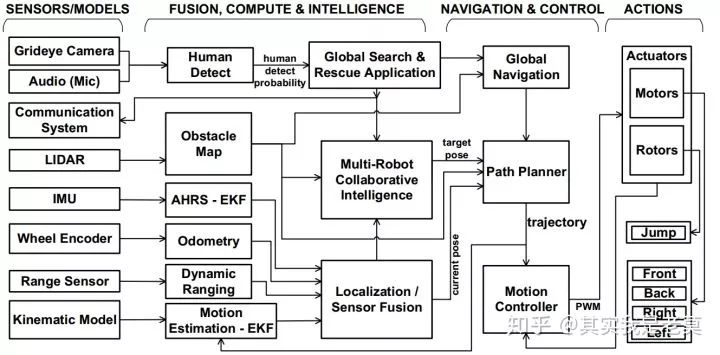
图7 Robot SoC所需要实现的算法
如果芯片内部的子系统较多,关系复杂,当然也可以依靠NoC来互联。比如刚刚被收购的sonics公司就给了这么一个例子[10]。
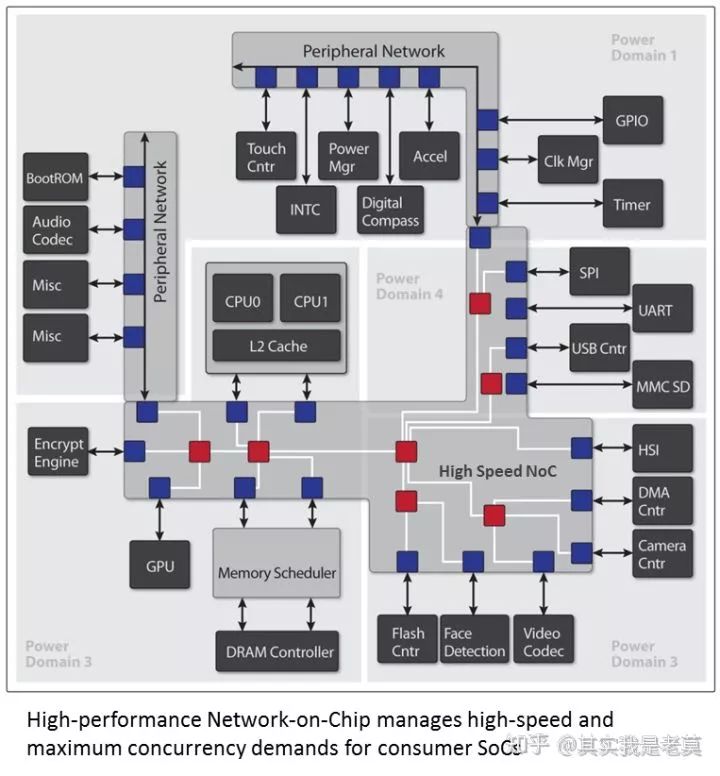
图8 Sonics公司给出的高性能片上网络在SoC中的应用
可以看出,在MPSoC中有多个独立的子系统时,使用片上网络是一种必要的片上通信方式。
最后,我们稍作总结:
1.片上多核系统是现在系统级集成电路的主要实现形式;
2.片上多核系统分为CMP和MPSoC两种架构;
3.CMP主要用于通用计算,大多采用数据并行的并行程序开发模式,以共享存储器的方式来交换数据,通常以对称的Tile形式来组织芯片硬件结构;
4.MPSoC主要用于嵌入式设备,大多是由多个相对独立的子系统构成,一般“按需设计”,结构极不对称。
本次先谈到这里,下回来谈一下不同片上多核系统的互联需求。也讲一下片上多核系统的发展如何引导片上网络的发展的。
参考文献:
[1] C. Mcnairy, R. Bhatia. Montecito: A Dual-Core, Dual-Thread Itanium Processor[J]. IEEE Micro, 2005, 25(2):10–20
[2] J. Kahle. The cell processor architecture[C]. 38th annual IEEE/ACM International Symposium on Microarchitecture, Washington, DC, 2005, 49–56
[3] Dagum L, Menon R. OpenMP: an industry standard API for shared-memory programming[J]. IEEE computational science and engineering, 1998, 5(1): 46-55.
[4]K. Olukotun, B. A. Nayfeh, L. Hammond, et al. The case for a single-chip multiprocessor[C]. Seventh international conference on Architectural support for programming languages and operating systems, New York, 1996, 2–11
[5]S. Dutta, R. Jensen, A. Rieckmann. Viper: A multiprocessor SOC for advanced set-top box and digital TV systems[J]. IEEE Design Test of Computers, 2001, 18(5):21–31
[6]J. Babb, M. Frank, V. Lee, et al. The RAW benchmark suite: computation structures for general purpose computing[C]. The 5th Annual IEEE Symposium on Field-Programmable Custom Computing Machines, Vancouver, 1997, 134 – 143
[7] Oracle, Redwood Shores, CA:A 20nm 32-Core 64MB L3 Cache SPARC M7 Processor 2015 IEEE International Solid-State Circuits Conference
[8] Singh, Teja, et al. "3.2 Zen: A next-generation high-performance× 86 core." 2017 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2017.
[9] Honkote, Vinayak, et al. "2.4 A Distributed Autonomous and Collaborative Multi-Robot System Featuring a Low-Power Robot SoC in 22nm CMOS for Integrated Battery-Powered Minibots." 2019 IEEE International Solid-State Circuits Conference-(ISSCC). IEEE, 2019.
[10]NoC | The Traffic Cop
-
集成电路
+关注
关注
5446文章
12478浏览量
372765 -
多核系统
+关注
关注
0文章
11浏览量
7618 -
处理器芯片
+关注
关注
0文章
123浏览量
20312
原文标题:【博文连载】详说片上网络之一:片上多核系统与片上网络的发展
文章出处:【微信号:ChinaAET,微信公众号:电子技术应用ChinaAET】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
瑞苏盈科亮相第四届欧洲核子研究组织(CERN)片上系统研讨会

PI加热片知识FAQ

新思科技UCIe IP解决方案实现片上网络互连
上海光机所在片上稳频激光器研究方面取得重要进展
分享两种前沿片上互连技术
MCU片上Flash
浅谈MCU片上RAM
太阳诱电触觉技术和音响用压电振动片


从片上系统(SoC)到立方体集成电路(CIC)

PI发热片制作流程(上)





 工商网监
工商网监
评论