今年以来可以说是最热的赛道,而AI大模型对算力的需求爆发,也带动了AI服务器中各种类型的芯片需求,所以本期核芯观察将关注ChatGPT背后所用到的算力芯片产业链,梳理目前主流类型的AI算力芯片产业上下游企业以及运作模式。 接上期Chat
2023-05-28 00:34:00 3883
3883 
今年以来可以说是最热的赛道,而AI大模型对算力的需求爆发,也带动了AI服务器中各种类型的芯片需求,所以本期核芯观察将关注ChatGPT背后所用到的算力芯片产业链,梳理目前主流类型的AI算力芯片产业上下游企业以及运作模式。 接上期Chat
2023-06-04 05:05:433560 
的缩写,即每秒所能够进行的浮点运算数目(每秒浮点运算量)。 算力可以分为通用算力、智能算力和超算算力。早前通用算力占整体算力的比重达到90%以上,近些年随着人工智能技术的发展,智能算力规模迅速增长。从需求层面看,2022年,中国智能算力规模为268百亿亿次/秒(EFLOPS),已经超过通用算力规
2024-02-06 00:08:008229 我用的是xinlinx spartan6 FPGA,我想知道它的IP核RAM是与FPGA独立的,只是集成在了一起呢,还是占用了FPGA的资源来形成一个RAM?如果我以ROM的形式调用该IP核,在
2013-01-10 17:19:11
语言编程的,因此可以根据图像处理的实际需求,动态地调整硬件资源的使用。这使得FPGA在处理图像时能够实现更高的能效比,从而降低系统的功耗。这对于需要长时间运行的图像处理系统尤为重要。
五、可重配置性
2024-10-09 14:36:26
有谁知道现在国内外有哪些公司卖FPGA的图像处理相关的IP核?
2015-04-28 21:34:24
进行处理其给出结果的延时是两行图像的时间。还有这个算子法和现在卷积神经网络中最前面的卷积层运算是类似的。
FPGA中的Block Ram是重要和稀缺资源,能缓存的图像数据行数是有限的,所以这个
2024-06-12 16:26:07
inference在设备端上做。嵌入式设备的特点是算力不强、memory小。可以通过对神经网络做量化来降load和省memory,但有时可能memory还吃紧,就需要对神经网络在memory使用上做进一步优化
2021-12-23 06:16:40
卷积神经网络为什么适合图像处理?
2022-09-08 10:23:10
的突破。AlexNet 在百万 量级的 ImageNet数据集上对于图像分类的精度大幅 度超过传统方法,一举摘下了视觉领域竞赛 ILSVRC2012的桂冠。自 AlexNet之后,研究者从卷积神经网 络
2022-08-02 10:39:39
融合和视频处理技术,从而提高汽车的安全性能。
目标识别跟踪:RK3588可提供6TOPS高性能NPU算力,支持深度学习算法和人脸识别等应用,并可通过PCIe 3.0高速接口从FPGA端接收高帧率图像
2024-07-17 10:49:03
本帖最后由 enlinux123 于 2014-11-7 16:41 编辑
想参加技术培训学习可以加张工2232894713最近一段时间一直在研究基于FPGA的图像处理,乘着这个机会和大家交流
2014-11-05 09:50:00
* 16 * 16(INT8 MAC) * 2 * 0 55G / 1024 = 17.6 TOPS
如果enable winograd INT8的算力可以提高一倍,winograd 要求卷积核必须是3*3
2023-09-19 08:11:10
膨胀处理,其中B是一个卷积模板或卷积核,其形状可以为正方形或圆形,通过模板B与图像A进行卷积计算,扫描图像中的每一个像素点,用模板元素与二值图像元素做“与”运算,如果都为0,那么目标像素点为0,否则
2018-11-23 16:39:34
已下是rx580显卡算力9-11 Mh 没有开启计算模式,挖几分种重启自动开启,计算模式只支持WIN1022-28 Mh 原版BIOS,开启时序,并设置超频29-32 Mh 正常算力,卡体质不同算力
2021-07-23 06:59:09
sTm32可以做卷积核滤波图片吗
2023-09-21 07:17:26
,能够实现高效地图像检测、识别、分类等AI应用。早前在该架构基础之上,深鉴科技做出了第一代FPGA产品,已经在摄像头市场实现了批量出货。 DPU计算核心采用全流水设计结构设计,内部集成了大量的卷积运算器
2018-03-23 15:27:20
,得到训练参数2、利用开发板arm与FPGA联合的特性,在arm端实现图像预处理已经卷积核神经网络的池化、激活函数和全连接,在FPGA端实现卷积运算3、对整个系统进行调试。4、在基本实现系统的基础上
2018-12-19 11:37:22
项目名称:基于cortex-m系列核和卷积神经网络算法的图像识别试用计划:本人在图像识别领域有三年多的学习和开发经验,曾利用nesys4ddr的fpga开发板,设计过基于cortex-m3的软核
2019-04-09 14:12:24
。将一个卷积核在(x,y)空间像素点的输出,和它前后的几个卷积核上的输出做权重归一化。使用了重叠的最大值池化层。3x3的池化核,步长为2,因此产生了重叠池化效应,使得一个像素点在多个池化结果中均有输出
2018-06-07 17:26:31
车载以太网在数据发送过程中的编码,4b-3b-2t-pam3。其中在3b-2t的时候,导致频率降为原来的2/3,所以100base-T1的mdi传输频率为66.7MHz;对于1000base-T1,同样采用4b-3b-2t-pam3的编码方式,为什么传输频率为750MHz呢?
2023-12-13 11:24:39
in Network。AlexNet中卷积层用线性卷积核对图像进行内积运算,在每个局部输出后面跟着一个非线性的激活函数,最终得到的叫做特征函数。而这种卷积核是一种广义线性模型,进行特征提取时隐含地假设了特征是线性
2018-05-08 15:57:47
,这就是IP核。
IP核一般原厂做一些资源开放,定制的IP核一般就要收费了。像做图像、音视频处理,AI等,开发可能会涉及到这一方面。IP核有优点也有缺点:IP核往往不能跨平台使用;IP核不透明,看不到内部核心代码等。
有关IP核有这方面资料可以分享探讨交流学习。
2024-04-29 21:01:16
最近行业都在说“算力是AI的命门”,但国产芯片真的能接住这波需求吗?
前阵子接触到海思昇腾910B,实测下来有点超出预期——7nm工艺下算力直接拉到256 TFLOPS,比上一代提升了40%,但功耗
2025-10-27 13:12:41
,减少了硬件资源的占用。该方案在Cyclone II FPGA 芯片EP2C35F484 上实现,占用 20 070 个逻辑单元(少于60% 的资源),系统最高时钟达到100 MHz 。与传统的128 位数据路径设计相比,更方便与处理器进行接口。
2012-08-11 11:53:10
结构,即在内存中开辟一个整数数组来进行计数,但是在FPGA 中定义数组是非常消耗资源的,尤其是当数组成员的位宽很大时。例如用触发器来统计256 灰度的720p 图像的直方图,将消耗4000 个逻辑单元
2012-05-14 12:37:37
FPGA 上实现卷积神经网络 (CNN)。CNN 是一类深度神经网络,在处理大规模图像识别任务以及与机器学习类似的其他问题方面已大获成功。在当前案例中,针对在 FPGA 上实现 CNN 做一个可行性研究
2019-06-19 07:24:41
背景介绍数据、算法和算力是人工智能技术的三大要素。其中,算力体现着人工智能(AI)技术具体实现的能力,实现载体主要有CPU、GPU、FPGA和ASIC四类器件。CPU基于冯诺依曼架构,虽然灵活,却
2021-07-26 06:47:30
大侠好,欢迎来到FPGA技术江湖,江湖偌大,相见即是缘分。大侠可以关注FPGA技术江湖,在“闯荡江湖”、\"行侠仗义\"栏里获取其他感兴趣的资源,或者一起煮酒言欢。
今天
2023-05-25 18:08:24
目前市场上炙手可热的芯片矿机 当数芯动 A10PRO , 7g 版本的 算力750m 功耗 1300w 这款机器厂家出厂时预定价格在 48900 左右那时候定的客户到如今 机器价格已经涨到
2021-07-23 07:39:58
的可以参考一下,欢迎一起交流学习。话不多说,上货。
使用FPGA做图像处理优势最关键的就是:FPGA能进行实时流水线运算,能达到最高的实时性。因此在一些对实时性要求非常高的应用领域,做图像处理
2023-06-08 15:55:34
。
内置独立NPU, 算力达 1TOPS,可用于轻量级人工智能应用。
支持几乎全格式的H.264解码,支持1080p@60fps的解码,支持4K@30fps的H.265解码,以及1080p@60fps
2024-12-24 15:07:12
需要大量向量计算的任务中表现出色,例如图像和视频处理等。(三)通用的 AI 算力融合方式 :以 CPU 核融合方式提供原生 AI 算力。生态对接 :实现与所有主流 AI 生态的快速对接,方便
2025-01-06 17:37:36
The HFA1110 is a unity gain closed loop buffer that achieves-3dB bandwidth of 750MHz, while
2009-01-08 18:21:29 12
12 内嵌ARM核的FPGA芯片EPXA10及其在图像驱动和处理方面的应用
2006-04-16 23:33:071544 FPGA调查显示门阵列的没落,Xilinx和Altera仍占统计地位
一个由EETimes、Piper-Jaffray和位于Sandia National Labs的FPGA Mission Assurance Center组织的FPGA用户调查显示,已经预言了很长时间的
2008-10-17 08:32:59719 腾视科技AI算力模组TS-SG-SM9系列搭载算能高集成度处理器CV186AH/BM1688片,功耗低、算力强、接口丰富、兼容性好。7.2-16TOPS INT8算力,兼容INT4/INT8
2025-10-20 10:16:03
基于FPGA硬件实现固定倍率的图像缩放,将2维卷积运算分解成2次1维卷积运算,对输入原始图像像素先进行行方向的卷积,再进行列方向的卷积,从而得到输出图像像素。把图像缩放过程
2012-05-09 15:52:0435 基于FPGA的经济型MPEG2运动图像编码器IP核设计
2016-08-30 15:10:149 a) 通过反复堆叠3*3的小型卷积核和2*2的最大池化层构建。 b) VGGNet拥有5段卷积,每一段卷积网络都会将图像的边长缩小一半,但将卷积通道数翻倍:64 —>128 —>256 —>512 —>512 。这样图像的面积缩小到1/4,输出通道数变为2倍,输出tensor的总尺寸每次缩小一半。
2018-08-21 15:10:274308 
我们都知道,卷积核的作用在于特征的抽取,越是大的卷积核尺寸就意味着更大的感受野,当然随之而来的是更多的参数。
2018-08-24 11:10:3523694 本文以适合FPGA实现为目的,提出一种具有计算规则性的快速二值图像连通域标记算法。与传统的二值图像标记算法相比,该算法具有运算简单性、规则性和可扩展性的特点,适合以FPGA实现。选用在100MHz
2018-11-14 10:07:007716 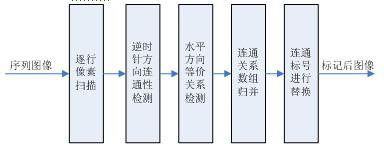
电子发烧友网为你提供TI(ti)DS90CR288A相关产品参数、数据手册,更有DS90CR288A的引脚图、接线图、封装手册、中文资料、英文资料,DS90CR288A真值表,DS90CR288A管脚等资料,希望可以帮助到广大的电子工程师们。
2018-10-16 11:10:12

与 FCN 通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归
2018-09-26 17:22:02920 在许多疾病的病理学诊断中,细胞核的形状、特征的变化是病变发生与否的重要依据,利用计算机智能分割出病理组织切片中的细胞核能为疾病诊断提供更多的参考。本研究将卷积神经网络应用在乳腺癌病理组织切片图像中
2018-11-14 17:34:056 /APC连接器。BGO747(FCO,SCO)用于CATV光节点系统,工作在40~750MHz频率范围内。工作时放大器电源脚和光二极管偏压脚连接24V(DC)电压,其模块包括一个适合波长1290
2019-03-29 09:05:01601 2.0GHz,G90T主频达到2.05GHz;GPU方面搭载了720Hz Mali-G76 MC4,主频高达800Mhz,并且内置双核APU,支持10GB LPDDR4x运存,频率最高可达2133MHz,可为手机带来强劲性能,安兔兔跑分超22万。
2019-08-04 10:16:082753 HPC 是算力坊内生的生态系统代币,支撑着算力坊项目的运行,是算力坊生态系统中重要的支付载体, HPC 将算力坊数万台矿机算力为价值担保,提供可靠的去中心化加密货币算力服务。
2019-08-26 11:51:582096 ARM Cortex-A15,主频1.5GHz
DSP C66x,主频750MHz
2个双核ARM Cortex-M4,主频213MHz
2个双核PRU,主频200MHz
2019-12-03 14:57:346253 
ARM Cortex-A15,主频1.5GHz
DSP C66x,主频750MHz
2个双核ARM Cortex-M4,主频213MHz
2个双核PRU,主频200MHz
2019-12-03 14:50:474863 
RM Cortex-A15,主频1.5GHz
DSP C66x,主频750MHz
2个双核ARM Cortex-M4,主频213MHz
2个双核PRU,主频200MHz
2019-12-03 16:27:216617 
图像卷积操作(convolution),或称为核操作(kernel),是进行图像处理的一种常用手段,
2020-03-13 16:44:033791 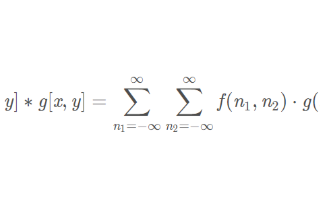
9月11日,在2020腾讯全球数字生态大会上,腾讯云副总裁刘煜宏透露,腾讯云大数据平台的算力弹性资源池达500万核,每日分析任务数达1500万,每日实时计算次数超过40万亿,能支持超过一万亿维度
2020-09-11 10:53:24978 ,采集卡上使用DS90CR288进行并转串处理,这种方式占用FPGA管脚资源多。当传输24bit RGB信号时,需要使用24(信号)+4(同步控制)+1(时钟)=29个管脚,而使用lvds传输,使用altlvds_tx核,只需要5对lvds信号即可,共占用10个管脚。
2020-12-30 16:57:2725 ,英伟达的崛起离不开 AI 产业的发展。英伟达主攻的 GPU 在算力上约超出 CPU 2~3 个数量级,与 AI 产业结合效果更佳,这也是英伟达能够在当前市场以底层算力芯片赢得高速发展的重要原因。 但是,算力更强的 GPU 芯片也暴露出另一个显著问题:利用率低。 “AWS 在
2020-12-30 17:05:095800 
本文通过通俗易懂的文字解释了图像卷积、边缘提取以及滤波去燥的概念及其分类。 一、图像卷积 现在有一张图片 f(x,y) 和一个kernel核 w(a,b)。 卷积(Convolution):卷积
2021-04-30 09:38:516433 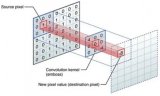
为更好地提取烟雾图像的全局特征,提出一种基于膨胀卷积和稠密连接的烟雾识别方法。依次堆叠膨胀率不同的膨胀卷积,扩大卷积核的感受野,使得卷积核能够感知更广泛的烟雾图像区域,在不同膨胀卷积层之间设计稠密
2021-05-14 11:32:369 在FPGA上生成8086指令兼容的软核以及外设并在此基础上跑通pc机上吃豆子PACMAN游戏项目(深圳市优能电源技术有限公司)-在FPGA上生成8086指令兼容的软核以及外设,并在此基础上跑通pc机上吃豆子PACMAN游戏项目
2021-09-16 12:17:3713 本期开小灶Heyro将带领大家进入下一趟旅程——基于卷积神经网络的图像分类算法讲解,从而帮助大家了解在卷积神经网络结构下衍生出的被用于图像分类的经典算法。
2022-04-06 14:50:366370 由基于CPU芯片的服务器所提供的算力,主要用于基础通用计算。日常提到的云计算、边缘计算等都属于基础算力,它为移动计算、物联网等提供计算支持。基础算力占整体算力的比重由2016年的95%下降至2020年的57%,但其依旧是算力主力。
2022-05-13 14:36:579612 算力网络的核心特征,是它通过算力,实现了对算力资源、网络资源的全面接管,可以让网络实时感知用户的算力需求,以及自身的算力状态。经过分析后,算力网络可以调度不同位置、不同类型的算力资源,为用户服务。
2022-08-17 09:32:236766 给出目前的框图,如下所示,外部输入25M,由Interface的PLL生成150/750MHz(离开148.5MHz有点偏差也没关系),hdmi_ip接收前面测试的RGB数据后,模拟HDMI协议
2022-09-06 10:16:383822 算力网络是“一种根据业务需求,在云、网、边之间按需分配和灵活调度计算资源、存储资源以及网络资源的新型信息基础设施”。
2022-12-14 15:48:008793 算力网络的核心特征,是它通过算力,实现了对算力资源、网络资源的全面接管,可以让网络实时感知用户的算力需求,以及自身的算力状态。经过分析后,算力网络可以调度不同位置、不同类型的算力资源,为用户服务。
2022-12-14 16:09:055809 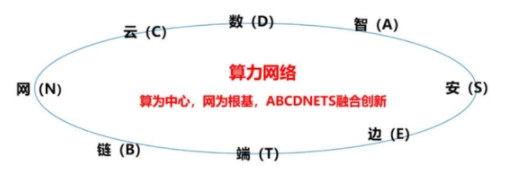
卷积神经网络(CNN)在图像和语音领域使用广泛,神经网络算法相比传统的算法消耗了更多算力。为了探索对计算的优化,我们进一步看到 AlexNet 模型(一种 CNN)的推理过程的各个层的计算资源消耗占比。
2023-05-09 11:37:202628 
算力服务层基于分布式微服务架构,支持应用解构成原子化功能 组件并组成算法库,由 API Gateway统一调度,实现 原子化算法按需实例 化。 算力平台层将算力资源抽象描述形成算力能力模板并对算力
2023-05-25 16:47:213 电子发烧友网站提供《PyTorch教程8.1之深度卷积神经网络(AlexNet).pdf》资料免费下载
2023-06-05 10:09:580 的选择 智能算力水平是国家智能化、数字化发展水平的集中体现,是数字化应用建设及发展的底层基础。《2021-2022全球计算力指数评估报告》数据显示,美国、日本、德国、英国等15个国家在AI算力上的支出占总算力支出比重从2016年的9%增加到了12%,预计到2025年
2023-06-05 10:40:022434 
英伟达A100的算力是多少? 英伟达A100的算力为19.5 TFLOPS(浮点运算每秒19.5万亿次)。 V100 用 300W 功率提供了 7.8TFLOPS 的推断算力,有 210 亿个晶体管
2023-08-08 15:28:4543608 不同领域的应用。 1.图像识别 卷积神经网络最早应用在图像识别领域。其核心思想是通过多层滤波器来提取图像的特征。卷积层主要包括卷积核、填充和步幅。卷积核通过滑动窗口的方式在输入图像上进行卷积运算,生成特征图。填充可以用来控
2023-08-21 16:49:295898 各种任务表现出色。在本文中,我们将介绍常见的卷积神经网络模型,包括LeNet、AlexNet、VGG、GoogLeNet、ResNet、Inception和Xception。 1. LeNet
2023-08-21 17:11:415641 打造一个AI大模型究竟需要多少算力?公开数据显示,ChatGPT初始所需的算力就是1万块英伟达A100(一种AI芯片),价格超过7亿元。后续的调优训练每天消耗算力大概是3640PFLOPS,需要7至8个算力达500PFLOPS的数据中心支持,建设成本约为三、四十亿元。
2023-08-23 16:09:081460 打造全国算力一张“网”
2023-12-15 18:56:192310 
英伟达H200的算力非常强大。作为新一代AI芯片,H200在性能上有了显著的提升,能够处理复杂的AI任务和大数据分析。然而,具体的算力数值可能因芯片配置、应用场景以及优化方向等因素而有所不同。
2024-03-07 16:15:044436 目标是使上海市智能算力总量超越30EFlops,占比达总计算力的50%以上。同时,要求算力网络的节点间单向时间延迟稳定在1毫秒之内,领先存储的容量份额增长至50%以上。
2024-03-25 16:33:471459 4月11日,2024年度中兴通讯云网生态峰会在南京成功举办,本届峰会以“合作共赢,数智同兴”为主题。期间,中兴通讯高级副总裁张万春发表了题为《全栈智算基础设施,解锁新质生产力》的主题演讲。
2024-04-15 18:26:281650 摩尔线程创始人兼CEO张建中在会上透露,为了满足国内对AI算力的迫切需求,他们正在积极寻求与国内顶尖科研机构的深度合作,共同推动更大规模的AI智算集群项目。
2024-05-10 16:36:052065 徐冰认为,国产芯片崛起以及算力商品化带来的投资价值,使中美算力差距有望逐步缩小。只要中国持续在算力研发上投入资金及资源,便能拉近与美国的算力差距。
2024-05-28 11:25:082337 卷积操作 卷积神经网络的核心是卷积操作。卷积操作是一种数学运算,用于提取图像中的局部特征。在图像识别中,卷积操作通过滑动窗口(或称为滤波器、卷积核)在输入图像上进行扫描,计算窗口内像素值与滤波器的加权和,生成新的特征图(Feature Map)。 1.2 激活函数 卷积层的输出通常会通过
2024-07-02 14:28:152804 和应用范围。 一、卷积神经网络的基本原理 1. 卷积层(Convolutional Layer) 卷积层是CNN的核心组成部分,其主要功能是提取图像中的局部特征。卷积层由多个卷积核(或滤波器)组成,每个卷积核负责提取图像中的一个特定特征。卷积核在输入图像上滑动,计算卷积核与图像的局部区域的
2024-07-02 15:30:582803 分类。 1. 卷积神经网络的基本概念 1.1 卷积层(Convolutional Layer) 卷积层是CNN中的核心组件,用于提取图像特征。卷积层由多个卷积核(或滤波器)组成,每个卷积核负责提取图像中的特定特征。卷积操作通过将卷积核在输入图像上滑动,计算卷积核与图像的局部区域的点积,生成特
2024-07-03 10:51:081132 在《算力系列基础篇——算力101:从零开始了解算力》中,相信各位粉丝初步了解到人工智能的“发动机”和核心驱动力:算力!算力!算力!(重要的事情说三遍)今天,一起学习一下计算机性能是如何影响算力
2024-07-11 08:04:57104 
经典卷积网络模型在深度学习领域,尤其是在计算机视觉任务中,扮演着举足轻重的角色。这些模型通过不断演进和创新,推动了图像处理、目标检测、图像生成、语义分割等多个领域的发展。以下将详细探讨几个经典的卷积
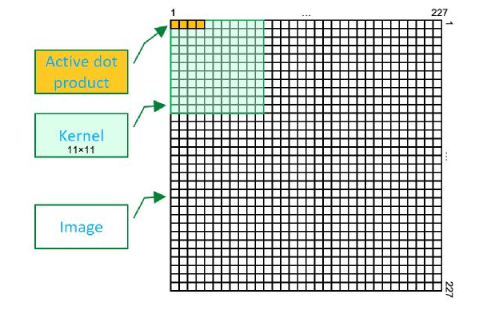
2024-07-11 11:45:281961 卷积运算是图像处理中一种极其重要的操作,广泛应用于图像滤波、边缘检测、特征提取等多个方面。它基于一个核(或称为卷积核、滤波器)与图像进行相乘并求和的过程,通过这一操作可以实现对图像的平滑、锐化、边缘检测等多种效果。本文将从卷积运算的基本概念、原理、应用以及代码示例等方面进行详细阐述。
2024-07-11 15:15:464942 N为一个奇数,如3、5、7等。奇数大小的卷积核有助于确定一个中心像素点,便于计算。 大小选择 :卷积核的大小决定了滤波器的范围。较大的卷积核可以覆盖更多的像素点,从而更好地平滑图像,但也可能导致图像细节丢失过多。因此,在
2024-09-29 09:29:402463 高斯卷积核函数在图像采样中的意义主要体现在以下几个方面: 1. 平滑处理与去噪 平滑图像 :高斯卷积核函数通过其权重分布特性,即中心像素点权重最高,周围像素点权重逐渐降低,实现了对图像的平滑处理
2024-09-29 09:33:471176 FPGA(现场可编程门阵列)加速深度学习模型是当前硬件加速领域的一个热门研究方向。以下是一些FPGA加速深度学习模型的案例: 一、基于FPGA的AlexNet卷积运算加速 项目名称
2024-10-25 09:22:031856 随着AI技术的广泛应用,算力需求呈现出爆发式增长。AI算力租赁作为一种新兴的服务模式,正逐渐成为企业获取算力资源的重要途径。
2024-10-31 10:31:381215 企业AI算力租赁是指企业通过互联网向专业的算力提供商租用所需的计算资源,以满足其AI应用的需求。以下是对企业AI算力租赁的介绍,由AI部落小编为您整理。
2024-11-14 09:30:463028 ),是深度学习的代表算法之一。 一、基本原理 卷积运算 卷积运算是卷积神经网络的核心,用于提取图像中的局部特征。 定义卷积核:卷积核是一个小的矩阵,用于在输入图像上滑动,提取局部特征。 滑动窗口:将卷积核在输入图像上滑动,每次滑动一个像素点。 计算卷积:将卷积核与输入图像的局部区域进行逐元素相乘,然
2024-11-15 14:47:482526 1月7日,南京信易达发布了旗下最新算力平台“C-MOM智能算力融合平台V3.0”,并更新了全新的UI视觉与交互系统。 该平台集成了HPC超算中心、AI智算中心、C-AMC应用中心、C-DCM数据中心
2025-01-08 10:56:451379 
像素行与像素窗口 一幅图像是由一个个像素点构成的,对于一幅480*272大小的图片来说,其宽度是480,高度是272。在使用FPGA进行图像处理时,最关键的就是使用FPGA内部的存储资源对像
2025-02-07 10:43:291528 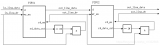
,这份报告极具前瞻性与指导意义。报告显示,在算力规模方面,中国智能算力增速远超预期,2024年中国智能算力规模达725.3EFLOPS,同比增长74.1%,是同期通用
2025-03-07 13:27:471935 
AI 训练与推理中的网络效率瓶颈,助力数据中心在高带宽、低延迟、高可靠性的需求下实现算力资源的最优配置。
2025-05-28 14:08:401930 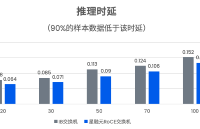
 电子发烧友App
电子发烧友App



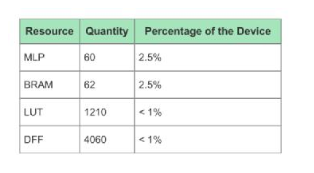
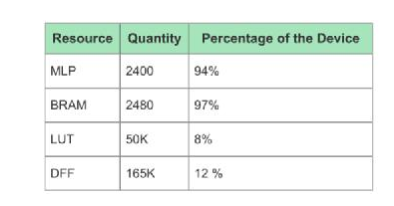
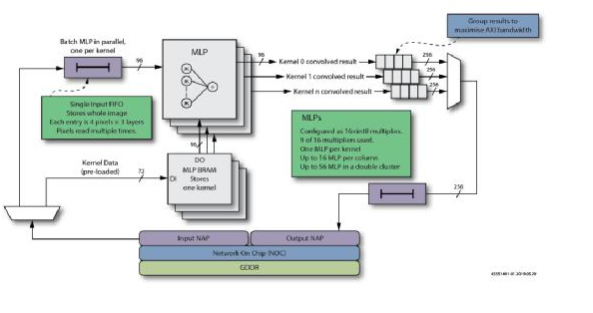

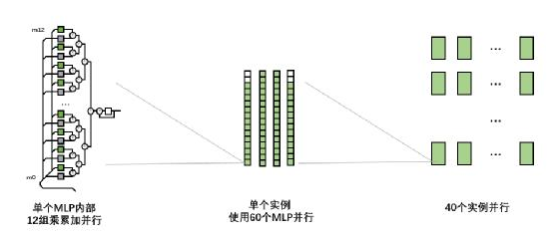








 工商网监
工商网监
评论