 FPGA图像处理基础----实现缓存卷积窗口
FPGA图像处理基础----实现缓存卷积窗口

像素行与像素窗口
一幅图像是由一个个像素点构成的,对于一幅480*272大小的图片来说,其宽度是480,高度是272。在使用FPGA进行图像处理时,最关键的就是使用FPGA内部的存储资源对像素行进行缓存与变换。由于在图像处理过程中,经常会使用到卷积,因此需要对图像进行开窗,然后将开窗得到的局部图像与卷积核进行卷积,从而完成处理。
图像数据一般按照一定的格式和时序进行传输,在我进行实验的时候,处理图像时,让其以VGA的时序来进行工作,这样能够为我处理行缓存提供便利。
基于FIFO的行缓存结构
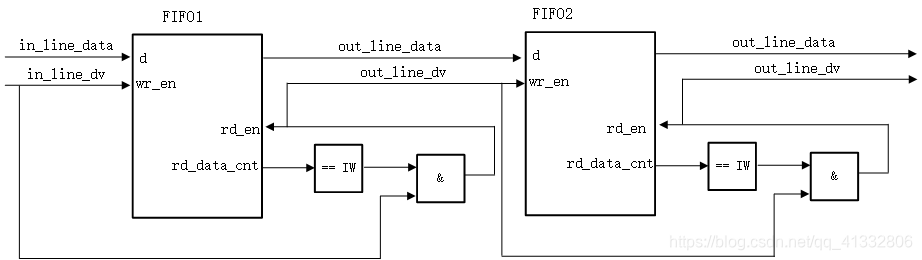
在FPGA中对图像的一行数据进行缓存时,可以采用FIFO这一结构,如上图所示,新一行图像数据流入到FIFO1中,FIFO1中会对图像数据进行缓存,当FIFO1中缓存有一行图像数据时,在下一行图像数据来临的时候,将FIFO1中缓存的图像数据读出,并传递给下一个FIFO,于此同时,将新一行的图像数据缓存到FIFO1中,这样就能完成多行图像的缓存。
若要缓存多行图像,下面的菊花链式的结果更能够直观地表现图像数据地流向。
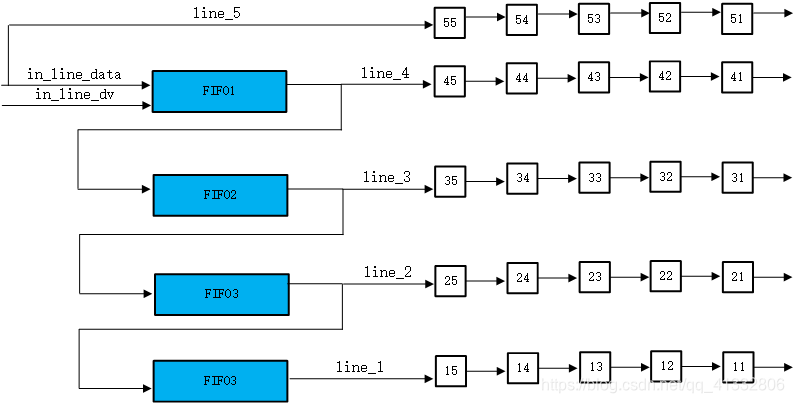
新输入地图像缓存到FIFO1当中,当FIFO中缓存有一行数据的时候,下一个输入像素来临的时候,会将数据从本FIFO中读出,并给到下一个FIFO,来形成类似于一个流水线的结构。
上面的图中,就是实现一个5X5大小的窗口的一个结构图。
代码设计
实现一个可以生成任意尺寸大小的开窗的模块,需要注意参数的使用,可以通过调节KSZ来调整窗口的大小。最终将窗口中的图像像素,转换成一个一维的数据输出给到下一个模块。
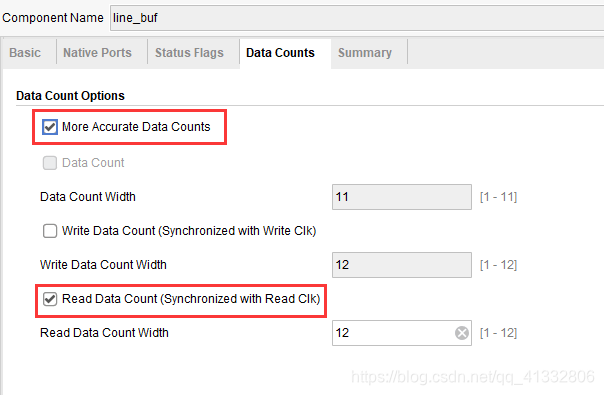
在设计的时候,对于FIFO要选择精准计数模式,这样才能让流水正常工作起来。
在代码中通过generate语句来实现多个line_buffer的例化,line buffer的个数可以根据卷积窗口的大小来选择,例如3X3大小的卷积窗口需要缓存两行,5X5大小的卷积窗口需要缓存4行,可以通过设置参数来选择要例化多少个line_buffer。
时序设计
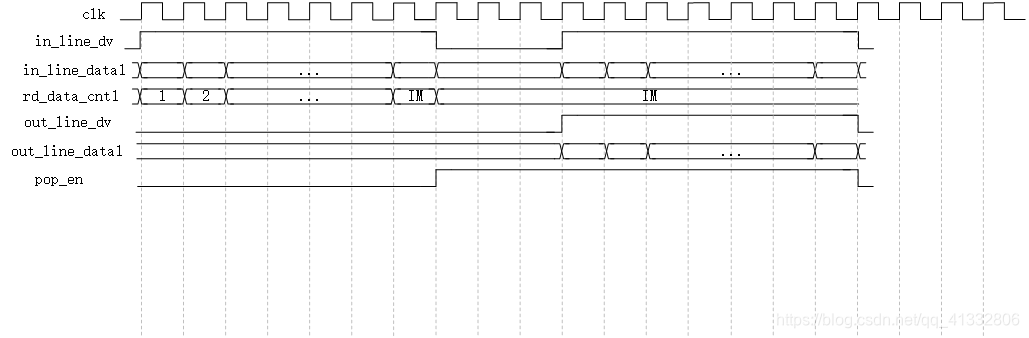
在设计FIFO的菊花链结构时,需要根据当前FIFO中存储的数据个数来判断,这时候使用到精准计数模式,可以反应FIFO中的存储的数据。当FIFO中存储有一行数据的时候,使能pop_en信号,表示当前可以将数据从FIFO中读出。
在将数据写入到FIFO中的时候,需要对数据进行扩充,也即需要对输入的图像的边界补充数据,因为进行卷积之后的图像将会比原始图像数据尺寸减少,因此在形成卷积窗口时,将图像扩充,能够让图像处理完成之后,保持原来的尺寸,只是会在边界出现黑边。
win_buf这个模块的最终输出,就是一个矩阵内的所有像素,组成一个信号输出到外部,供进行卷积的处理。
/*============================================ # # Author: Wcc - 1530604142@qq.com # # QQ : 1530604142 # # Last modified: 2020-07-08 20:02 # # Filename: win_buffer.v # # Description: # ============================================*/ `timescale 1ns / 1ps module win_buf #( //========================================== //parameter define //========================================== parameterKSZ = 3,//卷积核大小 parameterIMG_WIDTH = 128,//图像宽度,每个Line_buffer需要缓存的数据量 parameterIMG_HEIGHT= 128 //图像高度 )( input wire clk , inputwirerst , inputwirepi_hs, inputwirepi_vs, inputwirepi_de, inputwirepi_dv, inputwire[7: 0]pi_data, //输出图像新有效信号 output wirepo_dv, inputwirepo_hs, inputwirepo_vs, inputwirepo_de, //输出3X3图像矩阵 outputwire[8*KSZ*KSZ - 1: 0]image_matrix ); //========================================== //internal signals //========================================== reg frame_flag;//当前处于一帧图像所在位置 //========================================== //linebuffer 缓存数据 //========================================== //KSZ * KSZ 大小的卷积窗口,需要缓存(KSZ - 1行) wire [7:0]wr_buf_data[KSZ-2: 0];//写入每个buffer的数据 wire wr_buf_en [KSZ-2: 0];//写每个buffer的使能 wire full [KSZ-2: 0];//每个buffer的空满信号 wire empty [KSZ-2: 0]; wire [11:0]rd_data_cnt [KSZ-2: 0];//每个bufeer的内存数据个数 wirerd_buf_en[KSZ-2: 0];//读出每个buffer的使能信号 wire [7:0]rd_buf_data[KSZ-2: 0];//读出每个buffer的数据 reg pop_en [KSZ-2: 0];//每个buffer可以读出数据信号 reg pi_dv_dd [KSZ-2 : 0];//输入有效数据延时 wireline_vld;//行图像数据有效信号 wire [7:0]in_line_data; reg [7:0]pi_data_dd [KSZ-2 : 0]; reg [1:0]pi_vs_dd; reg [KSZ-2 : 0]po_dv_dd; reg [KSZ-2 : 0]po_de_dd; reg [KSZ-2 : 0]po_hs_dd; reg [KSZ-2 : 0]po_vs_dd; reg [0 : 0]po_dv_r; reg [0 : 0]po_de_r; reg [0 : 0]po_hs_r; reg [0 : 0]po_vs_r; reg [12:0]cnt_col ;//行列计数器 wireadd_cnt_col; wireend_cnt_col; reg [12:0]cnt_row ; wireadd_cnt_row; wireend_cnt_row ; localparamMATRIX_SIZE = KSZ * KSZ; //输出列数据延时,形成矩阵 reg[7:0]matrix_data[MATRIX_SIZE - 1: 0]; reg [8*KSZ*KSZ - 1: 0]image_matrix_r; assign image_matrix = image_matrix_r; assign po_dv = po_dv_r; assign po_hs = po_hs_r; assign po_vs = po_vs_r; assign po_de = po_de_r; //----------------pi_vs_dd------------------ always @(posedge clk) begin if (rst==1'b1) begin pi_vs_dd <= 'd0; end else begin pi_vs_dd <= {pi_vs_dd[0], pi_vs}; end end //----------------frame_flag------------------ always @(posedge clk) begin if (rst==1'b1) begin frame_flag <= 1'b0; end //检测到上升沿,结束上一帧 else if (pi_vs_dd[0] == 1'b1 && pi_vs_dd[1] == 1'b0) begin frame_flag <= 1'b0; end //检测到下降沿,开始本帧 else if(pi_vs_dd[0] == 1'b0 && pi_vs_dd[1] == 1'b1) begin frame_flag <= 1'b1; end end //========================================== //pi_dv_dd //进行边界的扩充,以3X3的窗口为例,需要在图像的 //外围各边添加一行一列的的空白像素 //若是5X5的窗口,需要在图像的外围各边,添加2行2列 //========================================== generate genvar i; //对于KSZ*KSZ的卷积核,每一行需要延时(KSZ-1)拍 for (i = 0; i < KSZ-1; i = i + 1) begin:Expand_the_boundary_dv if (i == 0) begin always @(posedge clk) begin if (rst==1'b1) begin pi_dv_dd[i] <= 1'b0; pi_data_dd[i] <= 'd0; end else begin pi_dv_dd[i] <= pi_dv; pi_data_dd[i] <= pi_data; end end end else begin always @(posedge clk) begin if (rst==1'b1) begin pi_dv_dd[i] <= 1'b0; pi_data_dd[i] <= 'd0; end else begin pi_dv_dd[i] <= pi_dv_dd[i - 1]; pi_data_dd[i] <= pi_data_dd[i - 1]; end end end end endgenerate assign line_vld = pi_dv_dd[KSZ-2] | pi_dv; assign in_line_data = pi_data_dd[(KSZ>>1) - 1]; //========================================== //行列计数器 //========================================== //----------------cnt_col------------------ always @(posedge clk) begin if (rst == 1'b1) begin cnt_col <= 'd0; end else if (add_cnt_col) begin if(end_cnt_col) cnt_col <= 'd0; else cnt_col <= cnt_col + 1'b1; end else begin cnt_col <= 'd0; end end assign add_cnt_col = frame_flag == 1'b1 && line_vld == 1'b1; assign end_cnt_col = add_cnt_col &&cnt_col == (IMG_WIDTH + KSZ-1) - 1; //----------------cnt_row------------------ always @(posedge clk) begin if (rst == 1'b1) begin cnt_row <= 'd0; end else if (add_cnt_row) begin if(end_cnt_row) cnt_row <= 'd0; else cnt_row <= cnt_row + 1'b1; end end assign add_cnt_row = end_cnt_col == 1'b1 ; assign end_cnt_row = add_cnt_row &&cnt_row == IMG_HEIGHT - 1; //========================================== //输入到line_buffer,构成对齐的列 //通过例化FIFO的方式,来完成行缓存 //当FIFO缓存有一行数据时,将数据读出,并填充到下一个FIFO中 //========================================== generate genvar j; for (j = 0; j < KSZ - 1; j = j + 1) begin:multi_line_buffer //第一个 line_buffer if (j == 0) begin : first_buffer //写入第一个line_buffer的数据是从外部输入的数据 assign wr_buf_data[j] = in_line_data; assign wr_buf_en[j] = line_vld; end //其他line_buffer else begin : other_buffer //写入其他line_buffer的数据是上一个line_buffer中输出的数据 assign wr_buf_en[j] = rd_buf_en[j - 1] ; assign wr_buf_data[j] = rd_buf_data[j - 1] ; end //----------------rd_buf_en------------------ //从buffer中读出数据 //pop_en是当前FIFO中已经缓存了一行的图像数据的指示信号 //wr_buf_en是当前新一行写入的有效数据指示信号 assign rd_buf_en[j] = pop_en[j] & wr_buf_en[j]; always @(posedge clk) begin if (rst==1'b1) begin pop_en[j] <= 0; end //当前不处于图像有效数据区域 else if (frame_flag == 1'b0) begin pop_en[j] <= 1'b0; end //当buffer中缓存有一行图像数据时(扩充的图像行) else if (rd_data_cnt[j] >= IMG_WIDTH+2) begin pop_en[j] <= 1'b1; end end line_buf line_buffer ( .wr_clk(clk), // input wire wr_clk .rd_clk(clk), // input wire rd_clk .din(wr_buf_data[j]), // input wire [7 : 0] din .wr_en(wr_buf_en[j]), // input wire wr_en .rd_en(rd_buf_en[j]), // input wire rd_en .dout(rd_buf_data[j]), // output wire [7 : 0] dout .full(full[j]), // output wire full .empty(empty[j]), // output wire empty .rd_data_count(rd_data_cnt[j]) // output wire [11 : 0] rd_data_count ); end endgenerate //========================================== //得到矩阵中的每一行的第一个数据 //========================================== generate genvar k; for (k = 0; k < KSZ; k = k + 1) begin:matrix_data_first_col if (k == KSZ -1) begin //最后一行数据为刚输入的数据 always @(*) begin matrix_data[KSZ * k] = in_line_data; end end else begin //从buffer中读取出来的图像书籍 //以3X3为例,buffer是菊花链的结果 //最开始输入的数据,在最后一个buffer中被读出 //最后输入的数据,在第一个buffer中被读出 always @(*) begin matrix_data[KSZ * k] = rd_buf_data[(KSZ -2) - k]; end end end endgenerate //========================================== //延时得到矩阵数据 //以3X3为例 //matrix[0]~[2] ==>p13,p12,p11 //matrix[3]~[5] ==>p23,p22,p21 //matrix[6]~[8] ==>p33,p32,p31 //KSZ-1 clk //========================================== generate genvar r,c; for (r = 0; r < KSZ; r = r + 1) begin:row for (c = 1; c < KSZ; c = c + 1) begin:col always @(posedge clk) begin if (rst==1'b1) begin matrix_data[r*KSZ + c] <= 'd0; end else begin matrix_data[r*KSZ + c] <= matrix_data[r*KSZ + (c-1)]; end end end end endgenerate //========================================== //输出图像矩阵 //以3X3为例 //image_matrix [7:0] ==> p13 //image_matrix [15:8] ==> p12 //image_matrix [23:16] ==> p11 //1 clk //========================================== generate genvar idx; for (idx = 0; idx < KSZ*KSZ; idx = idx + 1) begin:out_put_data always @(posedge clk) begin if (rst==1'b1) begin po_dv_r <= 1'b0; po_de_r <= 1'b0; po_hs_r <= 1'b0; po_vs_r <= 1'b0; image_matrix_r[8*(idx+1) -1 : 8*(idx)] <= 'd0; end else begin po_dv_r <= po_dv_dd[KSZ-2] & line_vld; po_de_r <= po_de_dd[KSZ-2] & line_vld; po_hs_r <= po_hs_dd[KSZ-2] ; po_vs_r <= po_vs_dd[KSZ-2] ; if (po_dv_dd[KSZ-2] & line_vld == 1'b1) begin image_matrix_r[8*(idx+1) -1 : 8*(idx)] <= matrix_data[idx]; end else begin image_matrix_r[8*(idx+1) -1 : 8*(idx)] <= 'd0; end end end end endgenerate //========================================== //(KSZ-1) clk //========================================== always @(posedge clk) begin if (rst==1'b1) begin po_vs_dd <= 'd0; po_hs_dd <= 'd0; po_de_dd <= 'd0; po_dv_dd <= 'd0; end else begin po_vs_dd <= {po_vs_dd[KSZ-3:0], pi_vs}; po_hs_dd <= {po_hs_dd[KSZ-3:0], pi_hs}; po_de_dd <= {po_de_dd[KSZ-3:0], pi_de}; po_dv_dd <= {po_dv_dd[KSZ-3:0], pi_dv}; end end endmodule
仿真验证
3X3开窗

输入的第三行数据的前三个数据是:0x00,0x78,0x7c
输入的第二行数据的前三个数据是:0x00,0x7d,0x7d
输入的第一行数据的前三个数据是:0x00,0x7e,0x7f
输出的第一个矩阵的值是:0x0078_7c00_7d7d_007e_7f
输入行数据第一个数据是0x00这是因为扩充了边界的原因。
可以看到,设置KSZ为3,可以得到一个位宽为72bit的输出数据,该数据包含了一个窗口中的9个数据。
5X5开窗
设置开窗大小为5x5之后,也可以看到输出信号的位宽变为了8*25=200bit,也就是一个5X5大小的矩阵中的数据。

输入的第5行数据的前5个数据是:0x00,0x00,0x7e,0x7c,0x7f
输入的第4行数据的前5个数据是:0x00,0x00,0x7e,0x7e,0x7e,
输入的第3行数据的前5个数据是:0x00,0x00,0x78,0x7c,0x7c
输入的第2行数据的前5个数据是:0x00,0x00,0x7d,0x7d,0x7a
输入的第1行数据的前5个数据是:0x00,0x00,0x7e,0x7f,0x7d
从输出结果看,输出的矩阵数据,刚好是这5行的前5数据,并且前两个数据是0x00,这是因为在每一行前面补充了两个0的原因。
经过测试,这种开窗算子是能够完成任意此村的开窗的。
实际应用
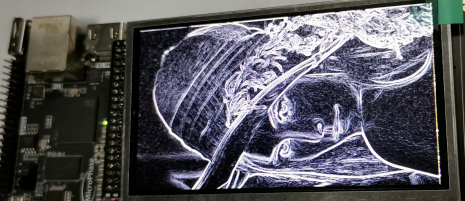
在实际应用中,我也将这个模块正确地使用上了,完成了一个3x3的sobel算子和5x5的均值滤波。
原始图像

3x3 Sobel
原文链接:
https://tencentcloud.csdn.net/678a0adeedd0904849a65d80.html
-
FPGA
+关注
关注
1665文章
22581浏览量
641058 -
图像处理
+关注
关注
29文章
1352浏览量
59803 -
缓存
+关注
关注
1文章
248浏览量
27854
原文标题:FPGA图像处理基础----实现缓存卷积窗口
文章出处:【微信号:gh_9d70b445f494,微信公众号:FPGA设计论坛】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
FPGA设计经验之图像处理
基于赛灵思FPGA的卷积神经网络实现设计
基于FPGA的图像平滑处理
【工程源码】基于FPGA的图像处理之行缓存(linebuffer)的设计

如何使用FPGA实现顺序形态图像处理器的硬件实现
基于FPGA的图像实时处理系统设计




评论