 算力革命:RoCE实测推理时延比InfiniBand低30%的底层逻辑
算力革命:RoCE实测推理时延比InfiniBand低30%的底层逻辑

在人工智能与大数据技术爆发的时代,算力基础设施的革新成为驱动产业升级的核心引擎。作为 AI 数据中心网络架构的关键枢纽,800G 智能交换机正以其极致的性能、灵活的扩展性和智能化的管理能力,重新定义高速网络的标准。
本文将深度解析 AI 智算场景打造的800G AI RoCE交换机,从外部规格的硬件创新到内部架构的芯片级设计,从企业级操作系统的功能突破到实测数据的性能验证,全方位展现其如何通过领先的技术架构破解 AI 训练与推理中的网络效率瓶颈,助力数据中心在高带宽、低延迟、高可靠性的需求下实现算力资源的最优配置。
算力基础设施—AI 智算RoCE网络交换机
外观展示
这款 800G AI 智能交换机在配备了 64 个 800G OSFP 网络接口,能够支持25G/50G/100G/200G/400G 等多种速率,可灵活适配不同的网络环境需求。

管理接口提供了 RJ45 MGMT Port、USB 2.0 Port 以及 RJ45 Console Port,为设备的管理和配置提供了丰富的选择。还具备 2 个 10G 端口,可作为 INT 端口用于其他管理功能,为设备的扩展应用提供了可能。
交换机设有 6 个 LED 指示灯,左侧的 LED 指示灯(LINK/ACT)用于展示管理口的网络链路状态和数据活动情况,右侧的 LED 指示灯(SYS)则显示系统整体状态,此外还有 BMC(面板管理控制器状态)、P(电源模块状态)、F(风扇模块状态)和 L(定位指示灯,用于维护期间识别设备),通过这些指示灯,运维人员可以快速了解设备的运行状况。
采用 1+1 热插拔电源设计,每个电源额定功率 3200W,且符合 80Plus 钛金能效标准,确保了设备供电的稳定和高效。同时,配备 3+1 个热插拔风扇模块,为设备的散热提供了可靠保障。
内部架构

采用了 Marvell Teralynx 10 ASIC(以下简称TL10),这是一款 5 纳米单芯片可编程处理器,能提供 51.2Tbps 带宽和约 560 纳秒的端口转发时延,在业内处于领先水平。更详细的内部架构请参见:51.2T 800G AI智算交换机软硬件系统设计全揭秘 - 星融元Asterfusion
散热设计上,采用 3D 均热风冷散热,这种高效的风冷设计使系统在 2180W 满负荷运行时仍能有效控制温度和噪音,即便在高负荷使用状态下,风扇转速仅为 60%,保证了设备的稳定运行和良好的工作环境。
精确时间协议 PTP 模块支持热插拔,PTP 和 SyncE 同步精度高达 10 纳秒,为对时间同步要求高的应用场景提供了有力支持。
COMe 模块由 x86 英特尔至强处理器和 AsterNOS 驱动,为先进的数据中心 / 人工智能路由提供智能控制平面。面板管理控制器(BMC)模块采用可插拔式设计,适用于模块化、可升级的带外管理,支持性能升级扩展,增强了设备的可扩展性和灵活性。
AI RoCE 交换机操作系统(AsterNOS)
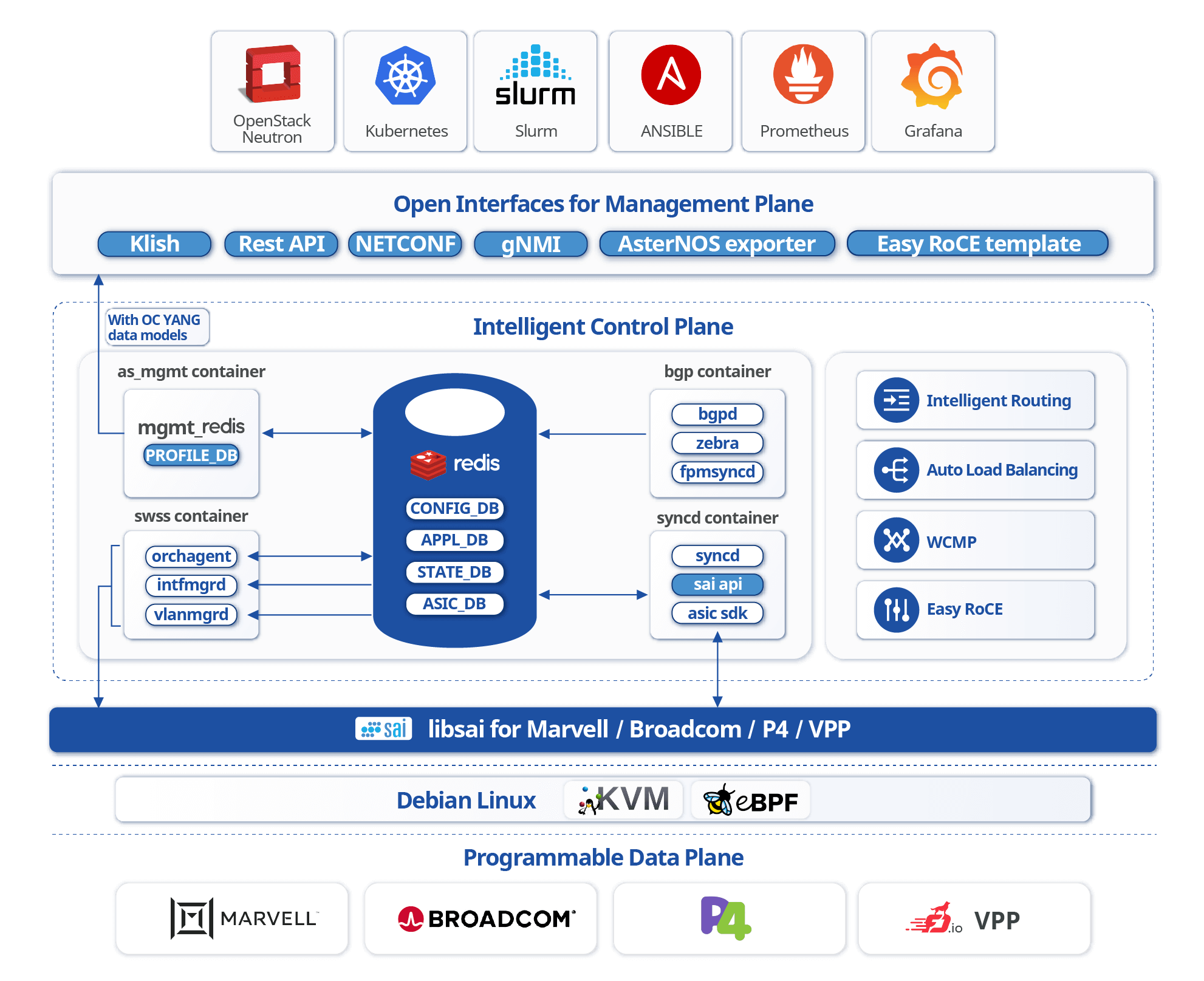
基于企业级SONiC的增强特性
- 超高速以太网优化:通过动态流量整形和优先级队列技术,实现网络利用率超90%,较传统以太网提升30%。
- AI场景专属功能:flowlet级负载均衡:根据GPU集群负载动态分配流量,减少数据拥塞。INT+WCMP路由:结合带内遥测与加权多路径算法,训练任务延迟降低20.4%,token生成速率提升27.5%。

- EasyRoCE :EasyRoCE 是星融元依托开源、开放的网络架构与技术,为AI 智算、高性能计算等场景的RDMA 融合以太网(RoCE)提供的一系列实用特性和小工具。从前期规划实施到日常运维监控, EasyRoCE 简化了各环节的复杂度并改善了操作体验,更提供二次开发和集成空间,供网络架构师充分利用开放网络的最新技术成果
(RE)RoCE Exporter:以容器的方式运行在AsterNOS网络操作系统内,从运行AsterNOS的交换机设备上导出RoCE网络相关监控指标(到自定义HTTP端口),供统一监控平台进行可视化呈现。
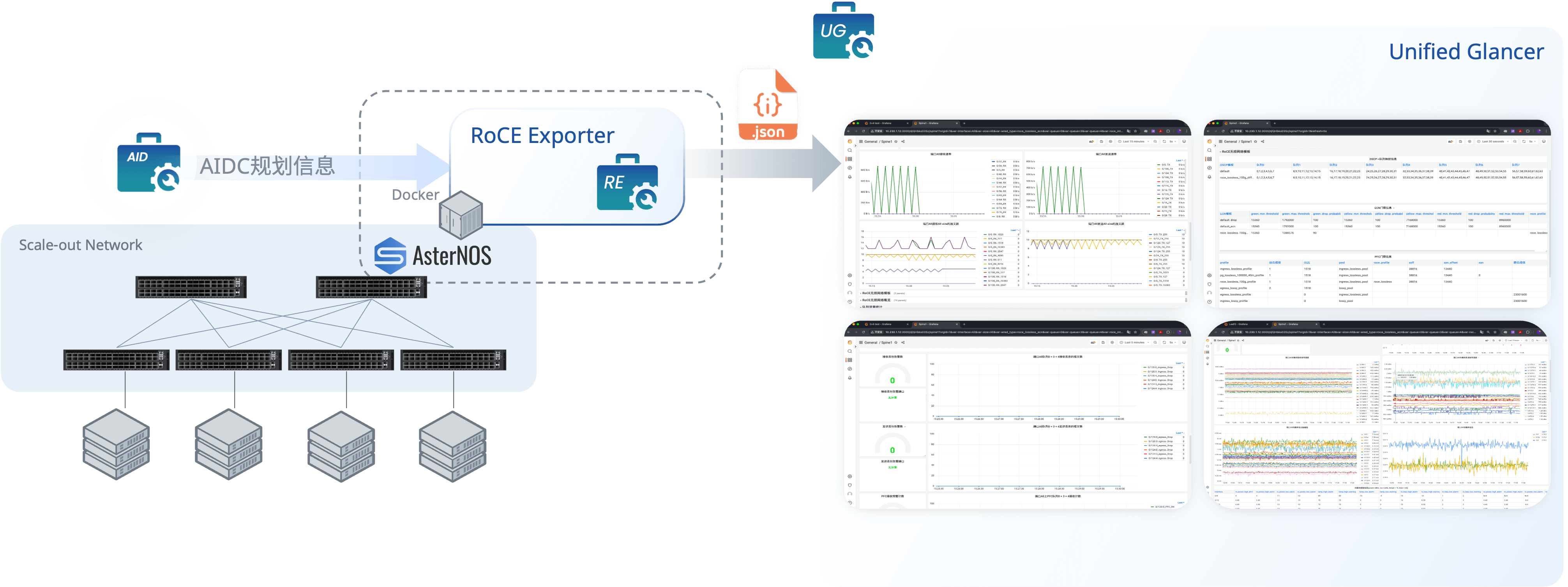
- 接口收发带宽和速率
- RoCE、PFC、ECN、DSCP配置状态信息
- 拥塞控制信息(ECN标记包,PFC帧数等)
- 队列Buffer信息
- ……
企业版 SONiC vs 社区版



AsterNOS 同时支持 Linux Bash 和思科风格命令行界面(Klish),这种双风格命令行界面帮助网络工程师轻松适应并快速部署,提升了操作的便利性和效率。
800G 数据中心交换机(TL10平台)实测数据
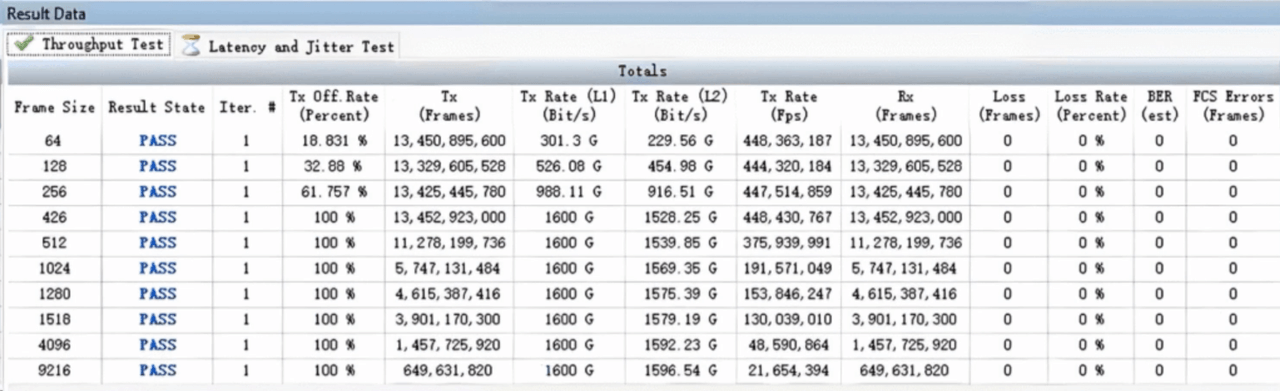
CX864E-N蛇形吞吐测试
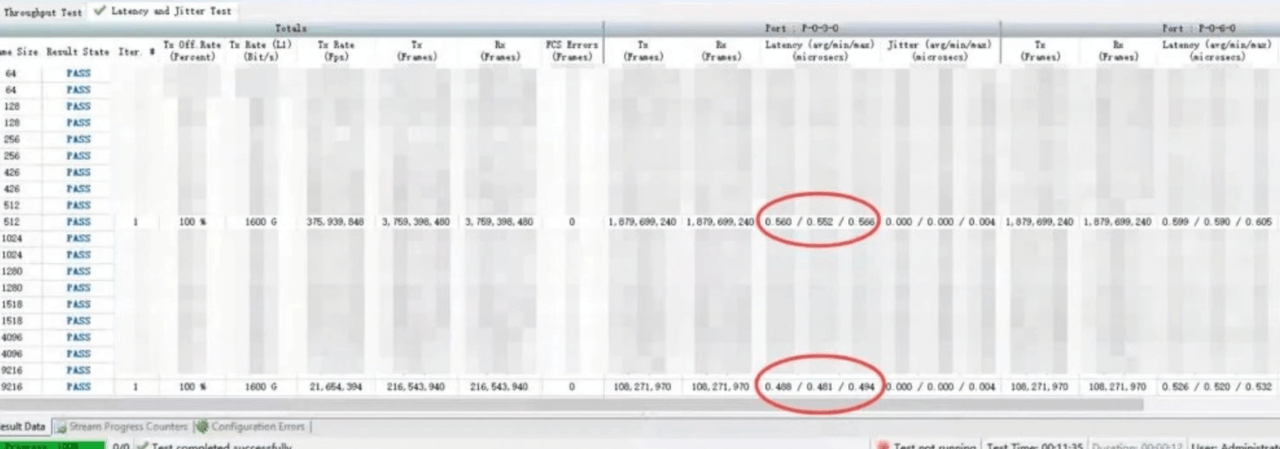
CX864E-N的端口转发时延
实测数据展示了该交换机在不同测试场景下的出色表现,各项指标均达到较高水平,验证了其性能的稳定性和可靠性。
DeepSeek模型推理指标对比:IB vs RoCE
- 推理时延:90% token 间隔延迟,指 90% token 间隔时间的最大值,用以衡量模型连续生成 token 的稳定性和连贯性。推理时延越低,系统的稳定性越高。
- Token 平均生成速率(Token Generation Rate):单位为 token 每秒(tokens/s)。反映了模型推理的整体吞吐能力,TGR 越高,表示系统单位时间内处理能力越强。
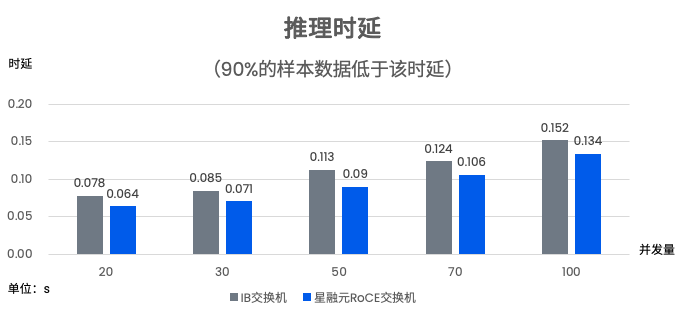
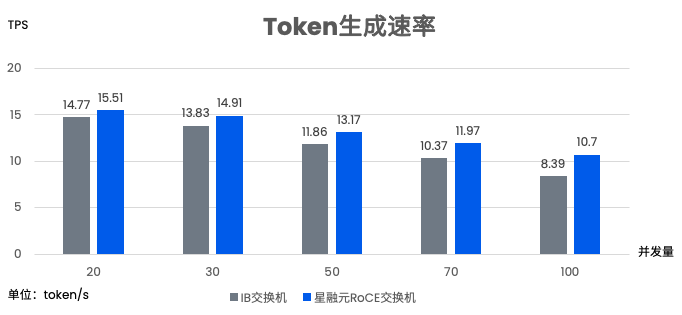
与IB网络场景下数据对比可见,星融元RoCEv2组网,推理时延明显优于IB,token 连贯性更好;token生成速度、中文字符速度明显优于IB。
800G AI智能交换机通过硬件革新与AsterNOS软件协同,为AI算力集群与超大规模数据中心提供“高吞吐、低时延、易运维”的一站式解决方案。其模块化设计、企业级SONiC支持及RoCEv2性能优势,正加速AI基础设施向开放解耦、智能高效的下一代架构演进。
-
InfiniBand
+关注
关注
1文章
31浏览量
9585 -
算力
+关注
关注
2文章
1677浏览量
16833
发布评论请先 登录
时延小于1毫秒,工信部发布全光算力网络重磅利好政策

科技云报到:AI算力革命,终结云计算20年降价史
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
Hailo-8算力卡 + RK3588实测!26TOPS加持,助力AI视觉升级!

力争百万 Tokens 推理成本降低百倍:云天励飞发布未来三年大算力芯片战略,首曝 DeepVerse 路线图

算力积木+3D堆叠!GPNPU架构创新,应对AI推理需求

在英伟达Thor平台部署EtherCAT主站:实测高性能、低抖动与低占用
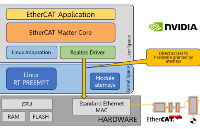
在英伟达Thor平台部署EtherCAT主站:实测高性能、低抖动与低占用
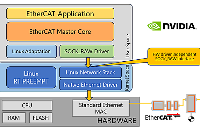
在高性能 AI 平台上部署 EtherCAT 主站:实测低抖动、低占用方案

国产AI芯片真能扛住“算力内卷”?海思昇腾的这波操作藏了多少细节?
光交换机:纳秒速率、低时延与高密度端口重构AI算力网络
算力与电力的终极博弈,填上了AIDC的“电力黑洞”
积算科技上线赤兔推理引擎服务,创新解锁FP8大模型算力
RoCE网络规划还在手动算IP?这套工具让运维效率飙升




评论