 瑞芯微(EASY EAI)RV1126B 模型部署API说明
瑞芯微(EASY EAI)RV1126B 模型部署API说明

1. 基础数据结构定义
1.1 rknn_sdk_version
结构体rknn_sdk_version用来表示RKNN SDK的版本信息,结构体的定义如下:

1.2 rknn_input_output_num
结构体rknn_input_output_num表示输入输出tensor个数,其结构体成员变量如下表所示:

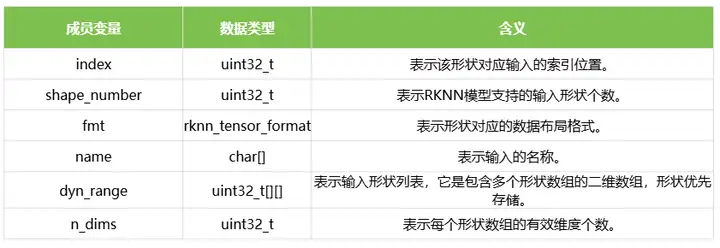
1.3 rknn_input_range
结构体rknn_input_range表示一个输入的支持形状列表信息。它包含了输入的索引、支持的形状个数、数据布局格式、名称以及形状列表,具体的结构体的定义如下表所示:
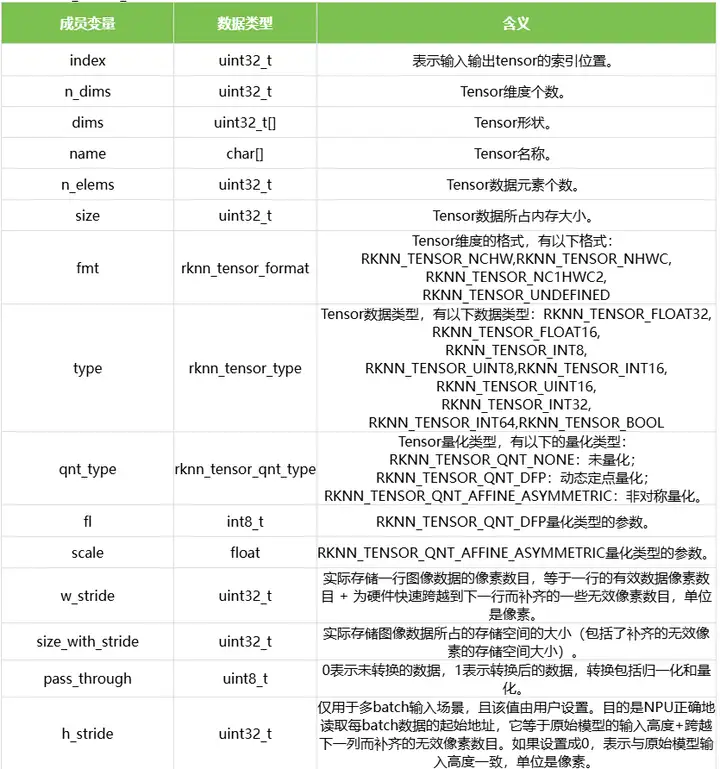
1.4 rknn_tensor_attr
结构体rknn_tensor_attr表示模型的tensor的属性,结构体的定义如下表所示:
1.5 rknn_perf_detail
结构体rknn_perf_detail表示模型的性能详情,结构体的定义如下表所示(RV1106/RV1106B/RV1103/RV1103B/RK2118暂不支持):

1.6 rknn_perf_run
结构体rknn_perf_run表示模型的总体性能,结构体的定义如下表所示(RV1106/RV1106B/RV1103/RV1103B/RK2118暂不支持):

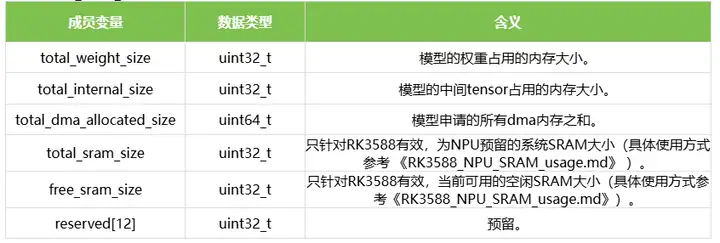
1.7 rknn_mem_size
结构体rknn_mem_size表示初始化模型时的内存分配情况,结构体的定义如下表所示:
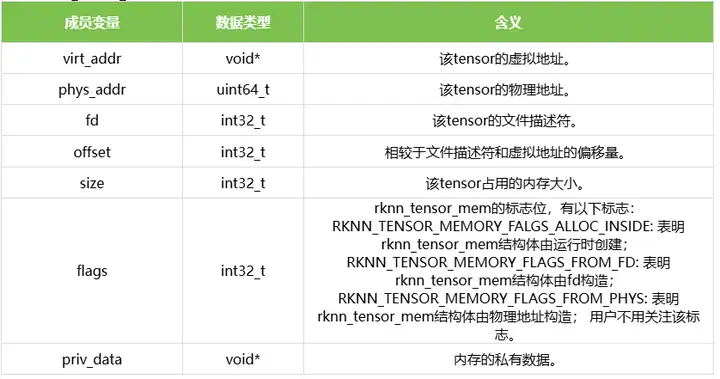
1.8 rknn_tensor_mem
结构体rknn_tensor_mem表示tensor的内存信息。结构体的定义如下表所示:
1.9 rknn_input
结构体rknn_input表示模型的一个数据输入,用来作为参数传入给rknn_inputs_set函数。结构体的定义如下表所示:
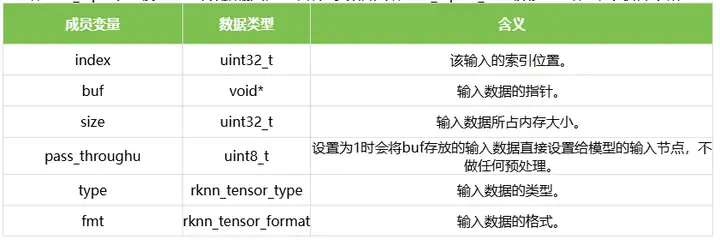
1.10 rknn_output
结构体rknn_output表示模型的一个数据输出,用来作为参数传入给rknn_outputs_get函数,在函数执行后,结构体对象将会被赋值。结构体的定义如下表所示:
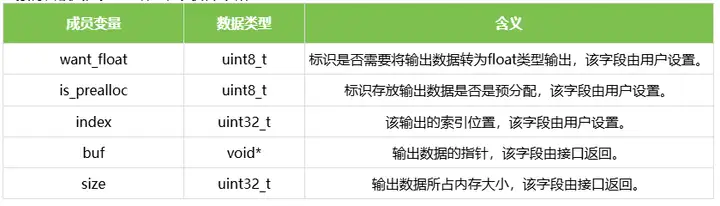
1.11 rknn_init_extend
结构体rknn_init_extend表示初始化模型时的扩展信息。结构体的定义如下表所示(RV1106/RV1106B/RV1103/RV1103B/RK2118暂不支持):
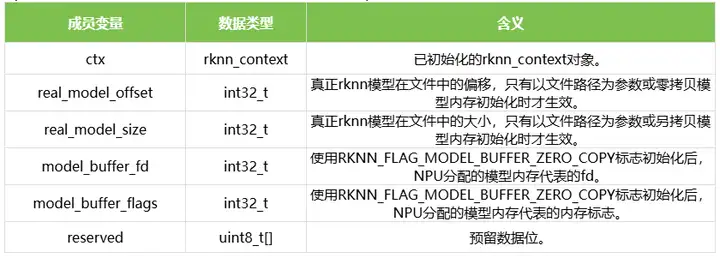
1.12 rknn_run_extend
结构体rknn_run_extend表示模型推理时的扩展信息,目前暂不支持使用。结构体的定义如下表所示:
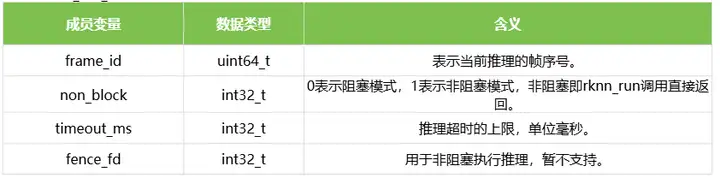
1.13 rknn_output_extend
结构体rknn_output_extend表示获取输出的扩展信息,目前暂不支持使用。结构体的定义如下表所示:

1.14 rknn_custom_string
结构体rknn_custom_string表示转换RKNN模型时,用户设置的自定义字符串,结构体的定义如下表所示:

2. 基础API说明
2.1 rknn_init
rknn_init初始化函数功能为创建rknn_context对象、加载RKNN模型以及根据flag和rknn_init_extend结构体执行特定的初始化行为。

示例代码如下:
rknn_context ctx;
int ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL);
各个初始化标志说明如下:
RKNN_FLAG_COLLECT_PERF_MASK:用于运行时查询网络各层时间;
RKNN_FLAG_MEM_ALLOC_OUTSIDE:用于表示模型输入、输出、权重、中间tensor内存全部由用户分配,它主要有两方面的作用:
1. 所有内存均是用户自行分配,便于对整个系统内存进行统筹安排。
2. 用于内存复用,特别是针对RV1103/RV1106/RV1103B/RV1106B/RK2118这种内存极为紧张的情况。
假设有模型A、B 两个模型,这两个模型在设计上串行运行的,那么这两个模型的中间tensor的内存就可以复用。示例代码如下:
rknn_context ctx_a, ctx_b;
rknn_init(&ctx_a, model_path_a, 0, RKNN_FLAG_MEM_ALLOC_OUTSIDE, NULL);
rknn_query(ctx_a, RKNN_QUERY_MEM_SIZE, &mem_size_a, sizeof(mem_size_a));
rknn_init(&ctx_b, model_path_b, 0, RKNN_FLAG_MEM_ALLOC_OUTSIDE, NULL);
rknn_query(ctx_b, RKNN_QUERY_MEM_SIZE, &mem_size_b, sizeof(mem_size_b));
max_internal_size = MAX(mem_size_a.total_internal_size, mem_size_b.total_internal_size);
internal_mem_max = rknn_create_mem(ctx_a, max_internal_size);
internal_mem_a = rknn_create_mem_from_fd(ctx_a, internal_mem_max->fd,
internal_mem_max->virt_addr, mem_size_a.total_internal_size, 0);
rknn_set_internal_mem(ctx_a, internal_mem_a);
internal_mem_b = rknn_create_mem_from_fd(ctx_b, internal_mem_max->fd,
internal_mem_max->virt_addr, mem_size_b.total_internal_size, 0);
rknn_set_internal_mem(ctx_b, internal_mem_b);
RKNN_FLAG_SHARE_WEIGHT_MEM:用于共享另一个模型的weight权重。主要用于模拟不定长度模型输入(RKNPU运行时库版本大于等于1.5.0后该功能被动态shape功能替代)。比如对于某些语音模型,
输入长度不定,但由于NPU无法支持不定长输入,因此需要生成几个不同分辨率的RKNN模,其中,只有一个RKNN模型的保留完整权重,其他RKNN模型不带权重。在初始化不带权重RKNN模型时,使用该标志能让当前上下文共享完整RKNN模型的权重。假设需要分辨率A、B两个模型,则使用流程如下:
1. 使用RKNN-Toolkit2生成分辨率A的模型。
2. 使用RKNN-Toolkit2生成不带权重的分辨率B的模型,rknn.config()中,remove_weight要设置成True,主要目的是减少模型B的大小。
3. 在板子上,正常初始化模型A。
4. 通过RKNN_FLAG_SHARE_WEIGHT_MEM的flags初始化模型B。
5. 其他按照原来的方式使用。板端参考代码如下:
rknn_context ctx_a, ctx_b;
rknn_init(&ctx_a, model_path_a, 0, 0, NULL);
rknn_init_extend extend;
extend.ctx = ctx_a;
rknn_init(&ctx_b, model_path_b, 0, RKNN_FLAG_SHARE_WEIGHT_MEM, &extend);
RKNN_FLAG_COLLECT_MODEL_INFO_ONLY:用于初始化一个空上下文,仅用于调用rknn_query接口查询模型weight内存总大小和中间tensor总大小,无法进行推理;
RKNN_FLAG_INTERNAL_ALLOC_OUTSIDE: 表示模型中间tensor由用户分配,常用于用户自行管理和复用多个模型之间的中间tensor内存;
RKNN_FLAG_EXECUTE_FALLBACK_PRIOR_DEVICE_GPU: 表示所有NPU不支持的层优先选择运行在GPU上,但并不保证运行在GPU上,实际运行的后端设备取决于运行时对该算子的支持情况;
RKNN_FLAG_ENABLE_SRAM: 表示中间tensor内存尽可能分配在SRAM上;
RKNN_FLAG_SHARE_SRAM: 用于当前上下文尝试共享另一个上下文的SRAM内存地址空间,要求当前上下文初始化时必须同时启用RKNN_FLAG_ENABLE_SRAM标志;
RKNN_FLAG_DISABLE_PROC_HIGH_PRIORITY: 表示当前上下文使用默认进程优先级。不设置该标志,进程nice值是-19;
RKNN_FLAG_DISABLE_FLUSH_INPUT_MEM_CACHE: 设置该标志后,runtime内部不主动刷新输入tensor缓存,用户必须确保输入tensor在调用 rknn_run 之前已刷新缓存。主要用于当输入数据没有CPU访问时,减少runtime内部刷cache的耗时。
RKNN_FLAG_DISABLE_FLUSH_OUTPUT_MEM_CACHE: 设置该标志后,runtime不主动清除输出tensor缓存。此时用户不能直接访问output_mem->virt_addr,这会导致缓存一致性问题。 如果用户想使用
output_mem->virt_addr,必须使用 rknn_mem_sync (ctx, mem, RKNN_MEMORY_SYNC_FROM_DEVICE)来刷新缓存。该标志一般在NPU的输出数据不被CPU访问时使用,比如输出数据由 GPU 或 RGA 访问以减少刷新缓存所需的时间。
RKNN_FLAG_MODEL_BUFFER_ZERO_COPY:表示rknn_init接口的传入的模型buffer是rknn_create_mem或者rknn_create_mem2接口分配的内存,runtime内部不需要拷贝一次模型buffer,减少运行时的内存占用,但需要用户保证上下文销毁前模型内存有效,并且在销毁上下文后释放该内存。初始化上下文时,rknn_init接口的rknn_init_extend参数,其成员real_model_offset、real_model_size、model_buffer_fd和model_buffer_flags根据rknn_create_mem2接口返回的rknn_tensor_mem设置。
RKNN_MEM_FLAG_ALLOC_NO_CONTEXT:在使用rknn_create_mem2接口分配内存时,设置该标志后,允许ctx参数是0或者NULL。从而用户在未初始化任何一个上下文之前就能获取NPU驱动分配的内存,返回的内存结构体需使用rknn_destroy_mem接口释放,释放的接口可使用任意一个上下文作为参数。
示例代码如下:
rknn_tensor_mem* model_mem = rknn_create_mem2(ctx, model_size,
RKNN_MEM_FLAG_ALLOC_NO_CONTEXT);
memcpy(model_mem->virt_addr, model_data, model_size);
rknn_init_extend init_ext;
memset(&init_ext, 0, sizeof(rknn_init_extend));
init_ext.real_model_offset = 0;
init_ext.real_model_size = model_size;
init_ext.model_buffer_fd = model_mem->fd;
init_ext.model_buffer_flags = model_mem->flags;
int ret = rknn_init(&ctx, model_mem->virt_addr, model_size, RKNN_FLAG_MODEL_BUFFER_ZERO_COPY,
&init_ext);
// do rknn inference...
rknn_destroy_mem(ctx, model_mem);
rknn_destroy(ctx);
2.2 rknn_set_core_mask
rknn_set_core_mask函数指定工作的NPU核心,该函数仅支持RK3576/RK3588平台,在单核NPU架构的平台上设置会返回错误。

示例代码如下:
rknn_context ctx;
rknn_core_mask core_mask = RKNN_NPU_CORE_0;
int ret = rknn_set_core_mask(ctx, core_mask);
在RKNN_NPU_CORE_0_1及RKNN_NPU_CORE_0_1_2模式下,目前以下OP能获得更好的加速:Conv、DepthwiseConvolution、Add、Concat、Relu、Clip、Relu6、ThresholdedRelu、PRelu、LeakyRelu,其余类型OP将fallback至单核Core0中运行,部分类型OP(如Pool类、ConvTranspose等)将在后续更新版本中支持。
2.3 rknn_set_batch_core_num
rknn_set_batch_core_num函数指定多batch RKNN模型(RKNN-Toolkit2转换时设置rknn_batch_size大于1导出的模型)的NPU核心数量,该函数仅支持RK3588/RK3576平台。
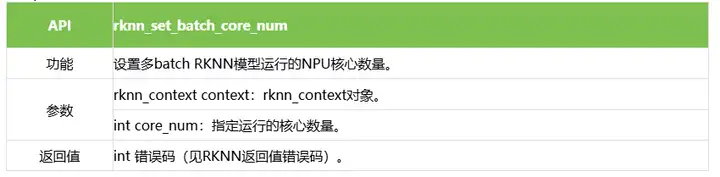
示例代码如下:
rknn_context ctx;
int ret = rknn_set_batch_core_num(ctx, 2);
2.4 rknn_dup_context
rknn_dup_context生成一个指向同一个模型的新context,可用于多线程执行相同模型时的权重复用。RV1106/RV1103/RV1106B/RV1103B/RK2118平台暂不支持 。

示例代码如下:
rknn_context ctx_in;
rknn_context ctx_out;
int ret = rknn_dup_context(&ctx_in, &ctx_out);
2.5 rknn_destroy
rknn_destroy函数将释放传入的rknn_context及其相关资源。

示例代码如下:
rknn_context ctx;
int ret = rknn_destroy(ctx);
2.6 rknn_query
rknn_query函数能够查询获取到模型输入输出信息、逐层运行时间、模型推理的总时间、SDK版本、内存占用信息、用户自定义字符串等信息。
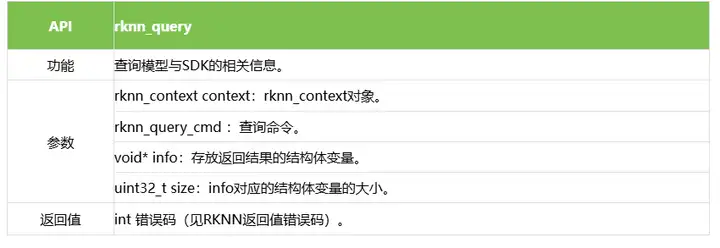
当前SDK支持的查询命令如下表所示:
| 查询命令 | 返回结果结构体 | 功能 |
|---|---|---|
| RKNN_QUERY_IN_OUT_NUM | rknn_input_output_num | 查询输入输出tensor个数。 |
| RKNN_QUERY_INPUT_ATTR | rknn_tensor_attr | 查询输入tensor属性。 |
| RKNN_QUERY_OUTPUT_ATTR | rknn_tensor_attr | 查询输出tensor属性。 |
| RKNN_QUERY_PERF_DETAIL | rknn_perf_detail | 查询网络各层运行时间,需要调用rknn_init接口时,设置RKNN_FLAG_COLLECT_PERF_MASK标志才能生效。 |
| RKNN_QUERY_PERF_RUN | rknn_perf_run | 查询推理模型(不包含设置输入/输出)的耗时,单位是微秒。 |
| RKNN_QUERY_SDK_VERSION | rknn_sdk_version | 查询SDK版本。 |
| RKNN_QUERY_MEM_SIZE | rknn_mem_size | 查询分配给权重和网络中间tensor的内存大小。 |
| RKNN_QUERY_CUSTOM_STRING | rknn_custom_string | 查询RKNN模型里面的用户自定义字符串信息。 |
| RKNN_QUERY_NATIVE_INPUT_ATTR | rknn_tensor_attr | 使用零拷贝API接口时,查询原生输入tensor属性,它是NPU直接读取的模型输入属性。 |
| RKNN_QUERY_NATIVE_OUTPUT_ATTR | rknn_tensor_attr | 使用零拷贝API接口时,查询原生输出tensor属性,它是NPU直接输出的模型输出属性。 |
| RKNN_QUERY_NATIVE_NC1HWC2_INPUT_ATTR | rknn_tensor_attr | 使用零拷贝API接口时,查询原生输入tensor属性,它是NPU直接读取的模型输入属性与RKNN_QUERY_NATIVE_INPUT_ATTR查询结果一致。 |
| RKNN_QUERY_NATIVE_NC1HWC2_OUTPUT_ATTR | rknn_tensor_attr | 使用零拷贝API接口时,查询原生输出tensor属性,它是NPU直接输出的模型输出属与RKNN_QUERY_NATIVE_OUTPUT_ATTR查询结果一致性。 |
| RKNN_QUERY_NATIVE_NHWC_INPUT_ATTR | rknn_tensor_attr | 使用零拷贝API接口时,查询原生输入 tensor属性与RKNN_QUERY_NATIVE_INPUT_ATTR查询结果一致 。 |
| RKNN_QUERY_NATIVE_NHWC_OUTPUT_ATTR | rknn_tensor_attr | 使用零拷贝API接口时,查询原生输出NHWC tensor属性。 |
| RKNN_QUERY_DEVICE_MEM_INFO | rknn_tensor_mem | 查询模型buffer的内存属性。 |
| RKNN_QUERY_INPUT_DYNAMIC_RANGE | rknn_input_range | 使用支持动态形状RKNN模型时,查询模型支持输入形状数量、列表、形状对应的数据布局和名称等信息。 |
| RKNN_QUERY_CURRENT_INPUT_ATTR | rknn_tensor_attr | 使用支持动态形状RKNN模型时,查询模型当前推理所使用的输入属性。 |
| RKNN_QUERY_CURRENT_OUTPUT_ATTR | rknn_tensor_attr | 使用支持动态形状RKNN模型时,查询模型当前推理所使用的输出属性。 |
| RKNN_QUERY_CURRENT_NATIVE_INPUT_ATTR | rknn_tensor_attr | 使用支持动态形状RKNN模型时,查询模型当前推理所使用的NPU原生输入属性。 |
| RKNN_QUERY_CURRENT_NATIVE_OUTPUT_ATTR | rknn_tensor_attr | 使用支持动态形状RKNN模型时,查询模型当前推理所使用的NPU原生输出属性。 |
各个指令用法的详细说明,如下:
1. 查询SDK版本
传入RKNN_QUERY_SDK_VERSION命令可以查询RKNN SDK的版本信息。其中需要先创建rknn_sdk_version结构体对象。
示例代码如下:
rknn_sdk_version version;
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version, sizeof(rknn_sdk_version));
printf("sdk api version: %s\n", version.api_version);
printf("driver version: %s\n", version.drv_version);
2. 查询输入输出tensor个数
在rknn_init接口调用完毕后,传入RKNN_QUERY_IN_OUT_NUM命令可以查询模型输入输出tensor的个数。其中需要先创建rknn_input_output_num结构体对象。
示例代码如下:
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
printf("model input num: %d, output num: %d\n", io_num.n_input, io_num.n_output);
3. 查询输入tensor属性(用于通用API接口)
在rknn_init接口调用完毕后,传入RKNN_QUERY_INPUT_ATTR命令可以查询模型输入tensor的属性。其中需要先创建rknn_tensor_attr结构体对象 (注意:RV1106/RV1103/RV1106B/RV1103B/RK2118查询出来的tensor是原始输入native的tensor) 。
示例代码如下:
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++) {
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));
}
4. 查询输出tensor属性(用于通用API接口)
在rknn_init接口调用完毕后,传入RKNN_QUERY_OUTPUT_ATTR命令可以查询模型输出tensor的属性。其中需要先创建rknn_tensor_attr结构体对象。
示例代码如下:
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
}
5. 查询模型推理的逐层耗时
在rknn_run接口调用完毕后,rknn_query接口传入RKNN_QUERY_PERF_DETAIL可以查询网络推理时逐层的耗时,单位是微秒。使用该命令的前提是,在rknn_init接口的flag参数需要包含
RKNN_FLAG_COLLECT_PERF_MASK标志。
示例代码如下:
rknn_context ctx;
int ret = rknn_init(&ctx, model_data, model_data_size, RKNN_FLAG_COLLECT_PERF_MASK, NULL);
...
ret = rknn_run(ctx,NULL);
...
rknn_perf_detail perf_detail;
ret = rknn_query(ctx, RKNN_QUERY_PERF_DETAIL, &perf_detail, sizeof(perf_detail));
6. 查询模型推理的总耗时
在rknn_run接口调用完毕后,rknn_query接口传入RKNN_QUERY_PERF_RUN可以查询上模型推理(不包含设置输入/输出)的耗时,单位是微秒。
示例代码如下:
rknn_context ctx;
int ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL);
...
ret = rknn_run(ctx,NULL);
...
rknn_perf_run perf_run;
ret = rknn_query(ctx, RKNN_QUERY_PERF_RUN, &perf_run, sizeof(perf_run));
7. 查询模型的内存占用情况
在rknn_init接口调用完毕后,当用户需要自行分配网络的内存时,rknn_query接口传入RKNN_QUERY_MEM_SIZE可以查询模型的权重、网络中间tensor的内存(不包括输入和输出)、推演模型所用的所有DMA内存的以及SRAM内存(如果sram没开或者没有此项功能则为0)的占用情况。使用该命令的前提是在rknn_init接口的flag参数需要包含RKNN_FLAG_MEM_ALLOC_OUTSIDE标志。
示例代码如下:
rknn_context ctx;
int ret = rknn_init(&ctx, model_data, model_data_size, RKNN_FLAG_MEM_ALLOC_OUTSIDE , NULL);
rknn_mem_size mem_size;
ret = rknn_query(ctx, RKNN_QUERY_MEM_SIZE, &mem_size, sizeof(mem_size));
8. 查询模型中用户自定义字符串
在rknn_init接口调用完毕后,当用户需要查询生成RKNN模型时加入的自定义字符串,rknn_query接口传入RKNN_QUERY_CUSTOM_STRING可以获取该字符串。例如,在转换RKNN模型时,用户填入“RGB”的自定义字符来标识RKNN模型输入是RGB格式三通道图像而不是BGR格式三通道图像,在运行时则根据查询到的“RGB”信息将数据转换成RGB图像。
示例代码如下:
rknn_context ctx;
int ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL);
rknn_custom_string custom_string;
ret = rknn_query(ctx, RKNN_QUERY_CUSTOM_STRING, &custom_string, sizeof(custom_string));
9. 查询原生输入tensor属性(用于零拷贝API接口)
在rknn_init接口调用完毕后,传入RKNN_QUERY_NATIVE_INPUT_ATTR命令(同RKNN_QUERY_NATIVE_NC1HWC2_INPUT_ATTR)可以查询模型原生输入tensor的属性。其中需要先创建rknn_tensor_attr结构体对象。
示例代码如下:
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++) {
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_NATIVE_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));
}
10. 查询原生输出tensor属性(用于零拷贝API接口)
在rknn_init接口调用完毕后,传入RKNN_QUERY_NATIVE_OUTPUT_ATTR命令(同RKNN_QUERY_NATIVE_NC1HWC2_OUTPUT_ATTR)可以查询模型原生输出tensor的属性。其中需要先创建rknn_tensor_attr结构体对象。
示例代码如下:
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_NATIVE_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
}
11. 查询NHWC格式原生输入tensor属性(用于零拷贝API接口)
在rknn_init接口调用完毕后,传入RKNN_QUERY_NATIVE_NHWC_INPUT_ATTR命令可以查询模型NHWC格式输入tensor的属性。其中需要先创建rknn_tensor_attr结构体对象。
示例代码如下:
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++) {
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_NATIVE_NHWC_INPUT_ATTR,
&(input_attrs[i]), sizeof(rknn_tensor_attr));
}
12. 查询NHWC格式原生输出tensor属性(用于零拷贝API接口)
在rknn_init接口调用完毕后,传入RKNN_QUERY_NATIVE_NHWC_OUTPUT_ATTR命令可以查询模型NHWC格式输出tensor的属性。其中需要先创建rknn_tensor_attr结构体对象。
示例代码如下:
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_NATIVE_NHWC_OUTPUT_ATTR,
&(output_attrs[i]), sizeof(rknn_tensor_attr));
}
13. 查询模型buffer的内存属性(注:仅RV1106/RV1103/RV1106B/RV1103B/RK2118支持该查询)
在rknn_init接口调用完毕后,传入RKNN_QUERY_DEVICE_MEM_INFO命令可以查询Runtime内部开辟的模型buffer的包括fd、物理地址等属性。
rknn_tensor_mem mem_info;
memset(&mem_info, 0, sizeof(mem_info));
ret = rknn_query(ctx, RKNN_QUERY_DEVICE_MEM_INFO, &mem_info, sizeof(mem_info));
14. 查询RKNN模型支持的动态输入形状信息(注:RV1106/RV1103/RV1106B/RV1103B/RK2118不支持该接口)
在rknn_init接口调用完毕后,传入RKNN_QUERY_INPUT_DYNAMIC_RANGE命令可以查询模型支持的输入形状信息,包含输入形状个数 、输入形状列表、输入形状对应的布局和名称等信息。其中需要先创建rknn_input_range结构体对象。
示例代码如下:
rknn_input_range dyn_range[io_num.n_input];
memset(dyn_range, 0, io_num.n_input * sizeof(rknn_input_range));
for (uint32_t i = 0; i < io_num.n_input; i++) {
dyn_range[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_DYNAMIC_RANGE,
&dyn_range[i], sizeof(rknn_input_range));
}
15. 查询RKNN模型当前使用的输入动态形状
在rknn_set_input_shapes接口调用完毕后,传入RKNN_QUERY_CURRENT_INPUT_ATTR命令可以查询模型当前使用的输入属性信息。其中需要先创建rknn_tensor_attr结构体(注:
RV1106/RV1103/RV1106B/RV1103B/RK2118不支持该命令)。
示例代码如下:
rknn_tensor_attr cur_input_attrs[io_num.n_input];
memset(cur_input_attrs, 0, io_num.n_input * sizeof(rknn_tensor_attr));
for (uint32_t i = 0; i < io_num.n_input; i++) {
cur_input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_CURRENT_INPUT_ATTR,
&(cur_input_attrs[i]), sizeof(rknn_tensor_attr));
}
16. 查询RKNN模型当前使用的输出动态形状
在rknn_set_input_shapes接口调用完毕后,传入RKNN_QUERY_CURRENT_OUTPUT_ATTR命令可以查询模型当前使用的输出属性信息。其中需要先创建rknn_tensor_attr结构体(注:
RV1106/RV1103/RV1106B/RV1103B/RK2118不支持该命令)。
示例代码如下:
rknn_tensor_attr cur_output_attrs[io_num.n_output];
memset(cur_output_attrs, 0, io_num.n_output * sizeof(rknn_tensor_attr));
for (uint32_t i = 0; i < io_num.n_output; i++) {
cur_output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_CURRENT_OUTPUT_ATTR,
&(cur_output_attrs[i]), sizeof(rknn_tensor_attr));
}
17. 查询RKNN模型当前使用的原生输入动态形状
在rknn_set_input_shapes接口调用完毕后,传入RKNN_QUERY_CURRENT_NATIVE_INPUT_ATTR命令可以查询模型当前使用的原生输入属性信息。其中需要先创建rknn_tensor_attr结构体(注:
RV1106/RV1103/RV1106B/RV1103B/RK2118不支持该命令)。
示例代码如下:
rknn_tensor_attr cur_input_attrs[io_num.n_input];
memset(cur_input_attrs, 0, io_num.n_input * sizeof(rknn_tensor_attr));
for (uint32_t i = 0; i < io_num.n_input; i++) {
cur_input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_CURRENT_NATIVE_INPUT_ATTR,
&(cur_input_attrs[i]), sizeof(rknn_tensor_attr));
}
18. 查询RKNN模型当前使用的原生输出动态形状
在rknn_set_input_shapes接口调用完毕后,传入RKNN_QUERY_CURRENT_NATIVE_OUTPUT_ATTR命令可以查询模型当前使用的原生输出属性信息。其中需要先创建rknn_tensor_attr结构体(注:RV1106/RV1103/RV1106B/RV1103B/RK2118不支持该命令)。
示例代码如下:
rknn_tensor_attr cur_output_attrs[io_num.n_output];
memset(cur_output_attrs, 0, io_num.n_output * sizeof(rknn_tensor_attr));
for (uint32_t i = 0; i < io_num.n_output; i++) {
cur_output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_CURRENT_NATIVE_OUTPUT_ATTR,
&(cur_output_attrs[i]), sizeof(rknn_tensor_attr));
}
2.6rknn_inputs_set
通过rknn_inputs_set函数可以设置模型的输入数据。该函数能够支持多个输入,其中每个输入是rknn_input结构体对象,在传入之前用户需要设置该对象,注:RV1106/RV1103/RV1106B/RV1103B/RK2118不支持该接口。

示例代码如下:
rknn_input inputs[1];
memset(inputs, 0, sizeof(inputs));
inputs[0].index = 0;
inputs[0].type = RKNN_TENSOR_UINT8;
inputs[0].size = img_width*img_height*img_channels;
inputs[0].fmt = RKNN_TENSOR_NHWC;
inputs[0].buf = in_data;
inputs[0].pass_through = 0;
ret = rknn_inputs_set(ctx, 1, inputs);
2.7 rknn_run
rknn_run函数将执行一次模型推理,调用之前需要先通过rknn_inputs_set函数或者零拷贝的接口设置输入数据。

示例代码如下:
ret = rknn_run(ctx, NULL);
2.8 rknn_outputs_get
rknn_outputs_get函数可以获取模型推理的输出数据。该函数能够一次获取多个输出数据。其中每个输出是rknn_output结构体对象,在函数调用之前需要依次创建并设置每个rknn_output对象。
对于输出数据的buffer存放可以采用两种方式:一种是用户自行申请和释放,此时rknn_output对象的is_prealloc需要设置为1,并且将buf指针指向用户申请的buffer;另一种是由rknn来进行分配,此时
rknn_output对象的is_prealloc设置为0即可,函数执行之后buf将指向输出数据。注:RV1106/RV1103/RV1106B/RV1103B/RK2118不支持该接口

示例代码如下:
rknn_output outputs[io_num.n_output];
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++) {
outputs[i].index = i;
outputs[i].is_prealloc = 0;
outputs[i].want_float = 1;
}
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
2.9 rknn_outputs_release
rknn_outputs_release函数将释放rknn_outputs_get函数得到的输出的相关资源。

示例代码如下:
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);
2.10 rknn_create_mem_from_phys
当用户需要自己分配内存让NPU使用时,通过rknn_create_mem_from_phys函数可以创建一个rknn_tensor_mem结构体并得到它的指针,该函数通过传入物理地址、虚拟地址以及大小,外部内存相关的信息会赋值给rknn_tensor_mem结构体。

示例代码如下:
//suppose we have got buffer information as input_phys, input_virt and size
rknn_tensor_mem* input_mems [1];
input_mems[0] = rknn_create_mem_from_phys(ctx, input_phys, input_virt, size);
2.11 rknn_create_mem_from_fd
当用户要自己分配内存让NPU使用时,rknn_create_mem_from_fd函数可以创建一个rknn_tensor_mem结构体并得到它的指针,该函数通过传入文件描述符fd、偏移、虚拟地址以及大小,外部内存相关的信息会赋值给rknn_tensor_mem结构体。

示例代码如下:
2.12 rknn_create_mem
当用户要NPU内部分配内存时,rknn_create_mem函数可以分配用户指定的内存大小,并返回一个rknn_tensor_mem结构体。

示例代码如下:
//suppose we have got buffer size
rknn_tensor_mem* input_mems [1];
input_mems[0] = rknn_create_mem(ctx, size);
2.13 rknn_create_mem2
当用户要NPU内部分配内存时,rknn_create_mem2函数可以分配用户指定的内存大小及内存类型,并返回一个rknn_tensor_mem结构体。

rknn_create_mem2与rknn_create_mem的主要区别是rknn_create_mem2带了一个alloc_flags,可以指定分配的内存是否cacheable的,而rknn_create_mem不能指定,默认就是cacheable。
示例代码如下:
2.14 rknn_destroy_mem
rknn_destroy_mem函数会销毁rknn_tensor_mem结构体,用户分配的内存需要自行释放。

示例代码如下:
rknn_tensor_mem* input_mems [1];
int ret = rknn_destroy_mem(ctx, input_mems[0]);
2.15 rknn_set_weight_mem
如果用户自己为网络权重分配内存,初始化相应的rknn_tensor_mem结构体后,在调用rknn_run前,通过rknn_set_weight_mem函数可以让NPU使用该内存。

示例代码如下:
rknn_tensor_mem* weight_mems [1];
int ret = rknn_set_weight_mem(ctx, weight_mems[0]);
2.16 rknn_set_internal_mem
如果用户自己为网络中间tensor分配内存,初始化相应的rknn_tensor_mem结构体后,在调用rknn_run前,通过rknn_set_internal_mem函数可以让NPU使用该内存。

示例代码如下:
rknn_tensor_mem* internal_tensor_mems [1];
int ret = rknn_set_internal_mem(ctx, internal_tensor_mems[0]);
2.17 rknn_set_io_mem
如果用户自己为网络输入/输出tensor分配内存,初始化相应的rknn_tensor_mem结构体后,在调用rknn_run前,通过rknn_set_io_mem函数可以让NPU使用该内存。

示例代码如下:
rknn_tensor_attr output_attrs[1];
rknn_tensor_mem* output_mems[1];
ret = rknn_query(ctx, RKNN_QUERY_NATIVE_OUTPUT_ATTR, &(output_attrs[0]), sizeof(rknn_tensor_attr));
output_mems[0] = rknn_create_mem(ctx, output_attrs[0].size_with_stride);
rknn_set_io_mem(ctx, output_mems[0], &output_attrs[0]);
2.18rknn_set_input_shape(deprecated)
该接口已经废弃,请使用rknn_set_input_shapes接口绑定输入形状。当前版本不可用,如要继续使用该接口,请使用1.5.0版本SDK并参考1.5.0版本的使用指南文档。
2.19 rknn_set_input_shapes
对于动态形状输入RKNN模型,在推理前必须指定当前使用的输入形状。该接口传入输入个数和rknn_tensor_attr数组,包含了每个输入形状和对应的数据布局信息,将每个rknn_tensor_attr结构体对象的
索引、名称、形状(dims)和内存布局信息(fmt)必须填充,rknn_tensor_attr结构体其他成员无需设置。在使用该接口前,可先通过rknn_query函数查询RKNN模型支持的输入形状数量和动态形状列表,要求输入数据的形状在模型支持的输入形状列表中。初次运行或每次切换新的输入形状,需要调用该接口设置新的形状,否则,不需要重复调用该接口。

示例代码如下:
for (int i = 0; i < io_num.n_input; i++) {
for (int j = 0; j < input_attrs[i].n_dims; ++j) {
//使用第一个动态输入形状
input_attrs[i].dims[j] = dyn_range[i].dyn_range[0][j];
}
}
ret = rknn_set_input_shapes(ctx, io_num.n_input, input_attrs);
if (ret < 0) {
fprintf(stderr, "rknn_set_input_shapes error! ret=%d\n", ret);
return -1;
}
2.20 rknn_mem_sync
rknn_create_mem函数创建的内存默认是带cacheable标志的,对于带cacheable标志创建的内存,在被CPU和NPU同时使用时,由于cache行为会导致数据一致性问题。该接口用于同步一块带cacheable标志创建的内存,保证CPU和NPU访问这块内存的数据是一致的。

示例代码如下:
ret =rknn_mem_sync(ctx, &outputs[0].mem,
RKNN_MEMORY_SYNC_FROM_DEVICE);
if (ret < 0) {
fprintf(stderr, " rknn_mem_sync error! ret=%d\n", ret);
return -1;
}
3. 矩阵乘法数据结构定义
3.1 rknn_matmul_info
rknn_matmul_info表示用于执行矩阵乘法的规格信息,它包含了矩阵乘法的规模、输入和输出矩阵的数据类型和内存排布。结构体的定义如下表所示:
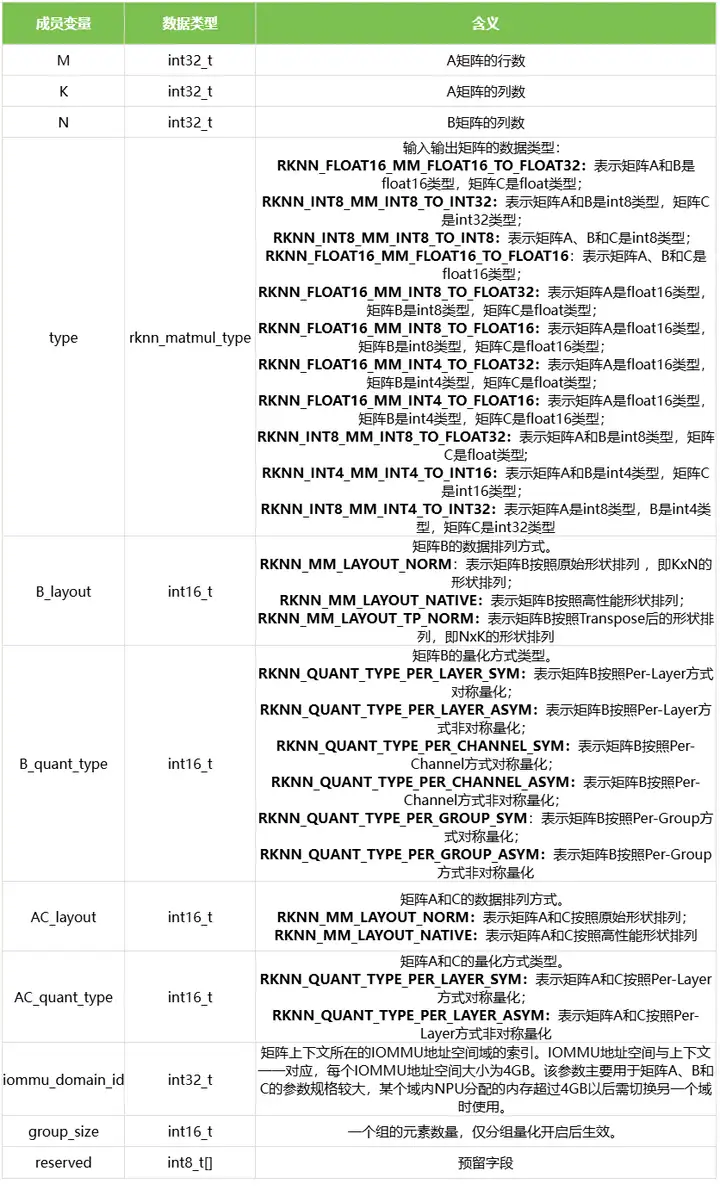
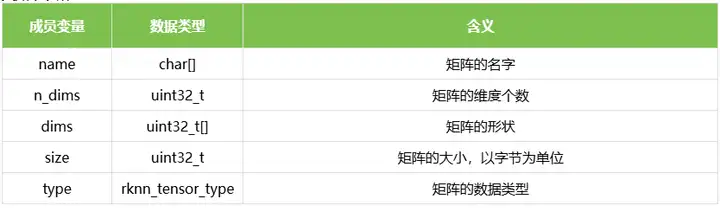
3.2 rknn_matmul_tensor_attr
rknn_matmul_tensor_attr表示每个矩阵tensor的属性,它包含了矩阵的名字、形状、大小和数据类型。结构体的定义如下表所示:
3.2 rknn_matmul_io_attr
rknn_matmul_io_attr表示矩阵所有输入和输出tensor的属性,它包含了矩阵A、B和C的属性。结构体的定义如下表所示:

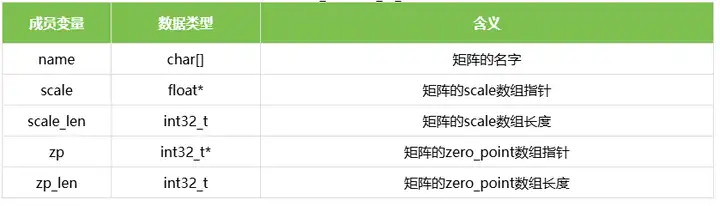
3.3 rknn_quant_params
rknn_quant_params表示矩阵的量化参数,包括name以及scale和zero_point数组的指针和长度,name用来标识矩阵的名称,它可以从初始化矩阵上下文时得到的rknn_matmul_io_attr结构体中获取。结构体定义如下表所示:
3.4 rknn_matmul_shape
rknn_matmul_shape表示某个特定shape的矩阵乘法的M、K和N,在初始化动态shape的矩阵乘法上下文时,需要提供shape的数量,并使用rknn_matmul_shape结构体数组表示所有的输入的shape。结构体定义如下表所示:

4. 矩阵乘法API说明
4.1 rknn_matmul_create
该函数的功能是根据传入的矩阵乘法规格等信息,完成矩阵乘法上下文的初始化,并返回输入和输出tensor的形状、大小和数据类型等信息。

示例代码如下:
rknn_matmul_info info;
memset(&info, 0, sizeof(rknn_matmul_info));
info.M = 4;
info.K = 64;
info.N = 32;
info.type = RKNN_INT8_MM_INT8_TO_INT32;
info.B_layout = RKNN_MM_LAYOUT_NORM;
info.AC_layout = RKNN_MM_LAYOUT_NORM;
rknn_matmul_io_attr io_attr;
memset(&io_attr, 0, sizeof(rknn_matmul_io_attr));
int ret = rknn_matmul_create(&ctx, &info, &io_attr);
if (ret < 0) {
printf("rknn_matmul_create fail! ret=%d\n", ret);
return -1;
}
4.2 rknn_matmul_set_io_mem
该函数用于设置矩阵乘法运算的输入/输出内存。在调用该函数前,先使用rknn_create_mem接口创建的rknn_tensor_mem结构体指针,接着将其与rknn_matmul_create函数返回的矩阵A、B或C的
rknn_matmul_tensor_attr结构体指针传入该函数,把输入和输出内存设置到矩阵乘法上下文中。在调用该函数前,要根据rknn_matmul_info中配置的内存排布准备好矩阵A和矩阵B的数据。

示例代码如下:
// Create A
rknn_tensor_mem* A = rknn_create_mem(ctx, io_attr.A.size);
if (A == NULL) {
printf("rknn_create_mem fail!\n");
return -1;
}
memset(A->virt_addr, 1, A->size);
rknn_matmul_io_attr io_attr;
memset(&io_attr, 0, sizeof(rknn_matmul_io_attr));
int ret = rknn_matmul_create(&ctx, &info, &io_attr);
if (ret < 0) {
printf("rknn_matmul_create fail! ret=%d\n", ret);
return -1;
}
// Set A
ret = rknn_matmul_set_io_mem(ctx, A, &io_attr.A);
if (ret < 0) {
printf("rknn_matmul_set_io_mem fail! ret=%d\n", ret);
return -1;
}
4.3 rknn_matmul_set_core_mask
该函数用于设置矩阵乘法运算时可用的NPU核心(仅支持RK3588和RK3576平台)。在调用该函数前,需要先通过rknn_matmul_create函数初始化矩阵乘法上下文。可通过该函数设置的掩码值,指定需要使用的核心,以提高矩阵乘法运算的性能和效率。

示例代码如下:
rknn_matmul_set_core_mask(ctx, RKNN_NPU_CORE_AUTO);
4.4 rknn_matmul_set_quant_params
rknn_matmul_set_quant_params用于设置每个矩阵的量化参数,支持Per-Channel量化、Per-Layer量化和PerGroup量化方式的量化参数设置。当使用Per-Group量化时,rknn_quant_params中的scale和zp数组的长度等于N*K/group_size。当使用Per-Channel量化时,rknn_quant_params中的scale和zp数组的长度等于N。当使用Per-Layer量化时,rknn_quant_params中的scale和zp数组的长度为1。在rknn_matmul_run之前调用此接口设置所有矩阵的量化参数。如果不调用此接口,则默认量化方式为Per-Layer量化,scale=1.0,zero_point=0。

示例代码如下:
rknn_quant_params params_a;
memcpy(params_a.name, io_attr.A.name, RKNN_MAX_NAME_LEN);
params_a.scale_len = 1;
params_a.scale = (float *)malloc(params_a.scale_len * sizeof(float));
params_a.scale[0] = 0.2;
params_a.zp_len = 1;
params_a.zp = (int32_t *)malloc(params_a.zp_len * sizeof(int32_t));
params_a.zp[0] = 0;
rknn_matmul_set_quant_params(ctx, ¶ms_a);
4.5 rknn_matmul_get_quant_params
rknn_matmul_get_quant_params用于rknn_matmul_type类型等于RKNN_INT8_MM_INT8_TO_INT32并且Per-Channel量化方式时,获取矩阵B所有通道scale归一化后的scale值,获取的scale值和A的原始scale值相乘可以得到C的scale值。可以用于在矩阵C没有真实scale时,近似计算得到C的scale。

示例代码如下:
float b_scale;
rknn_matmul_get_quant_params(ctx, ¶ms_b, &b_scale);
4.6 rknn_matmul_create_dyn_shape(deprecated)
该接口已废弃,改用rknn_matmul_create_dynamic_shape接口。
4.7 rknn_matmul_create_dynamic_shape
rknn_matmul_create_dynamic_shape用于创建动态shape矩阵乘法上下文,该接口需要传入rknn_matmul_info结构体、shape数量以及对应的shape数组,shape数组会记录多个M、K和N值。在初始化成功后,会得到rknn_matmul_io_attr的数组,数组中包含了所有的输入输出矩阵的shape、大小和数据类型等信息。目前支持设置多个不同的M,K和N。

示例代码如下:
const int shape_num = 2;
rknn_matmul_shape shapes[shape_num];
for (int i = 0; i < shape_num; ++i) {
shapes[i].M = i+1;
shapes[i].K = 64;
shapes[i].N = 32;
}
rknn_matmul_io_attr io_attr[shape_num];
memset(io_attr, 0, sizeof(rknn_matmul_io_attr) * shape_num);
int ret = rknn_matmul_create_dynamic_shape(&ctx, &info, shape_num, shapes, io_attr);
if (ret < 0) {
fprintf(stderr, " rknn_matmul_create_dynamic_shape fail! ret=%d\n", ret);
return -1;
}
4.8 rknn_matmul_set_dynamic_shape
rknn_matmul_set_dynamic_shape用于指定矩阵乘法使用的某一个shape。在创建动态shape的矩阵乘法上下文后,选取其中一个rknn_matmul_shape结构体作为输入参数,调用此接口设置运算使用的shape。

示例代码如下:
ret = rknn_matmul_set_dynamic_shape(ctx, &shapes[0]);
if (ret != 0) {
fprintf(stderr, "rknn_matmul_set_dynamic_shapes fail!\n");
return -1;
}
4.9 rknn_B_normal_layout_to_native_layout
rknn_B_normal_layout_to_native_layout用于将矩阵B的原始形状排列的数据(KxN)转换为高性能数据排列方式的数据。
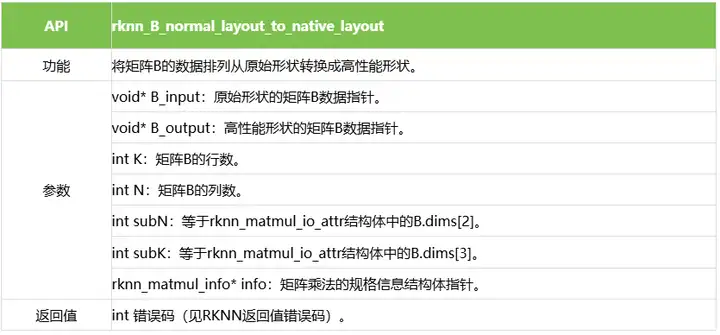
示例代码如下:
int32_t subN = io_attr.B.dims[2];
int32_t subK = io_attr.B.dims[3];
rknn_B_normal_layout_to_native_layout(B_Matrix, B->virt_addr, K, N, subN, subK, &info);
4.10 rknn_matmul_run
该函数用于运行矩阵乘法运算,并将结果保存在输出矩阵C中。在调用该函数前,输入矩阵A和B需要先准备好数据,并通过rknn_matmul_set_io_mem函数设置到输入缓冲区。输出矩阵C需要先通过
rknn_matmul_set_io_mem函数设置到输出缓冲区,而输出矩阵的tensor属性则通过rknn_matmul_create函数获取。

示例代码如下:
int ret = rknn_matmul_run(ctx);
4.11 rknn_matmul_destroy
该函数用于销毁矩阵乘法运算上下文,释放相关资源。在使用完rknn_matmul_create函数创建的矩阵乘法上下文指针后,需要调用该函数进行销毁。

示例代码如下:
int ret = rknn_matmul_destroy(ctx);
5. 自定义算子数据结构定义
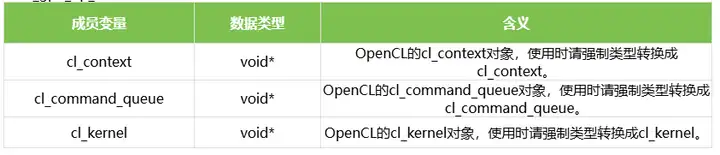
5.1rknn_gpu_op_context
rknn_gpu_op_context表示指定GPU运行的自定义算子的上下文信息。结构体的定义如下表所示:
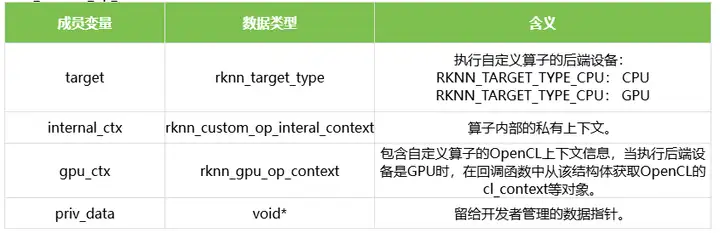
5.2 rknn_custom_op_context
rknn_custom_op_context表示自定义算子的上下文信息。结构体的定义如下表所示:
5.3 rknn_custom_op_tensor
rknn_custom_op_tensor表示自定义算子的输入/输出的tensor信息。结构体的定义如下表所示:

5.4 rknn_custom_op_attr
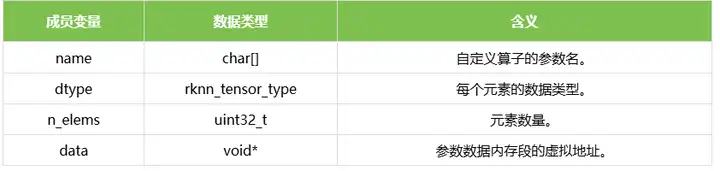
rknn_custom_op_attr表示自定义算子的参数或属性信息。结构体的定义如下表所示:
5.5 rknn_custom_op
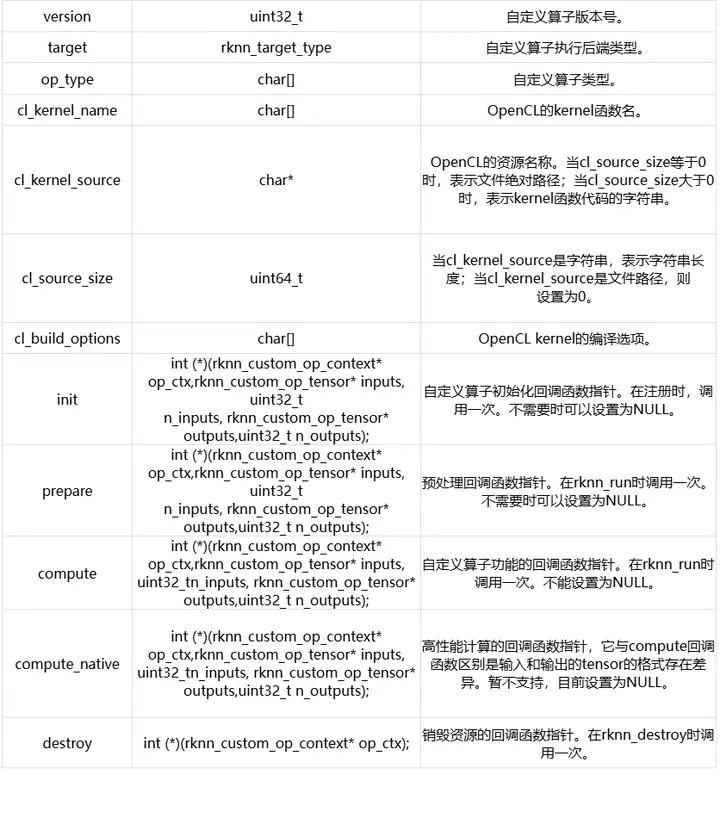
rknn_custom_op表示自定义算子的注册信息。结构体的定义如下表所示:
6. 自定义算子API说明
6.1rknn_register_custom_ops
在初始化上下文成功后,该函数用于在上下文中注册若干个自定义算子的信息,包括自定义算子类型、运行后端类型、OpenCL内核信息以及回调函数指针。注册成功后,在推理阶段,rknn_run接口会调用开发者实现的回调函数。

示例代码如下:
// CPU operators
rknn_custom_op user_op[2];
memset(user_op, 0, 2 * sizeof(rknn_custom_op));
strncpy(user_op[0].op_type, "cstSoftmax", RKNN_MAX_NAME_LEN - 1);
user_op[0].version = 1;
user_op[0].target = RKNN_TARGET_TYPE_CPU;
user_op[0].init = custom_op_init_callback;
user_op[0].compute = compute_custom_softmax_float32;
user_op[0].destroy = custom_op_destroy_callback;
strncpy(user_op[1].op_type, "ArgMax", RKNN_MAX_NAME_LEN - 1);
user_op[1].version = 1;
user_op[1].target = RKNN_TARGET_TYPE_CPU;
user_op[1].init = custom_op_init_callback;
user_op[1].compute = compute_custom_argmax_float32;
user_op[1].destroy = custom_op_destroy_callback;
ret = rknn_register_custom_ops(ctx, user_op, 2);
if (ret < 0) {
printf("rknn_register_custom_ops fail! ret = %d\n", ret);
return -1;
}
6.2 rknn_custom_op_get_op_attr
该函数用于在自定义算子的回调函数中获取自定义算子的参数信息,例如Softmax算子的axis参数。它传入自定义算子参数的字段名称和一个rknn_custom_op_attr结构体指针,调用该接口后,参数值会存储在rknn_custom_op_attr结构体中的data成员中,开发者根据返回的结构体内dtype成员将该指针强制转换成C语言中特定数据类型的数组首地址,再按照元素数量读取出完整参数值

示例代码如下:
rknn_custom_op_attr op_attr;
rknn_custom_op_get_op_attr(op_ctx, "axis", &op_attr);
if (op_attr.n_elems == 1 && op_attr.dtype == RKNN_TENSOR_INT64) {
axis = ((int64_t*)op_attr.data)[0];
}
…
7. RKNN返回值错误码
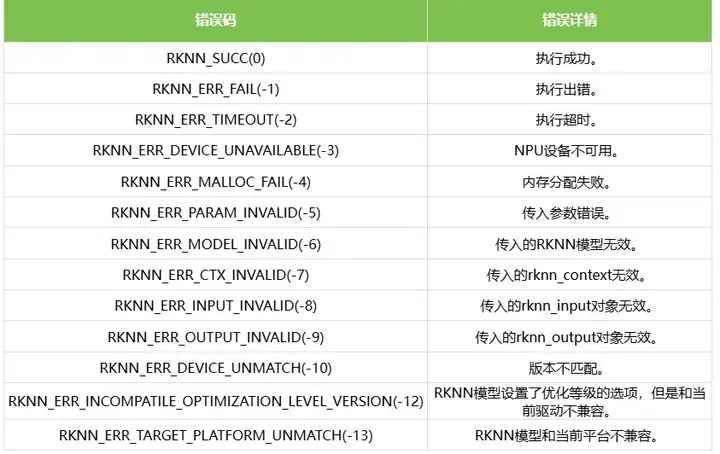
RKNN API函数的返回值错误码定义如下表所示:
-
人工智能
+关注
关注
1821文章
50395浏览量
267179 -
开发板
+关注
关注
26文章
6439浏览量
121243 -
瑞芯微
+关注
关注
27文章
868浏览量
54692 -
EASY-EAI灵眸科技
+关注
关注
4文章
113浏览量
3731 -
RV1126B
+关注
关注
0文章
102浏览量
256
发布评论请先 登录
瑞芯微(EASY EAI)RV1126B 音频输入

瑞芯微(EASY EAI)RV1126B PWM使用

瑞芯微(EASY EAI)RV1126B 音频输出

【EASY EAI Nano-TB(RV1126B)开发板试用】+初识篇
【EASY EAI Nano-TB(RV1126B)开发板试用】命令行功能测试-shell脚本进行IO控制-红绿灯项目
【EASY EAI Nano-TB(RV1126B)开发板试用】命令行功能测试-shell脚本进行IO控制-红绿灯按钮项目
【EASY EAI Nano-TB(RV1126B)开发板试用】+1、开箱上电
【EASY EAI Nano-TB(RV1126B)开发板试用】介绍、系统安装
RV1126系列选型指南:从RV1126到RV1126B,一文看懂升级差异

【免费试用】EASY EAI Nano-TB(RV1126B)开发套件评测

瑞芯微RV1126B特性概述
替代升级实锤!实测RV1126B,CPU性能吊打RV1126

瑞芯微(EASY EAI)RV1126B 人体关键点识别
瑞芯微(EASY EAI)RV1126B rknn-toolkit-lite2使用方法




评论