 为什么无图智驾不使用SLAM建立局部语义地图?
为什么无图智驾不使用SLAM建立局部语义地图?

[首发于智驾最前沿微信公众号]智驾无图的概念已经在自动驾驶领域流传颇深,过去几年,自动驾驶高度依赖高精地图,但现在更追求像人一样开车,也就是在不依赖预设地图的情况下,实时感知并理解周围环境。
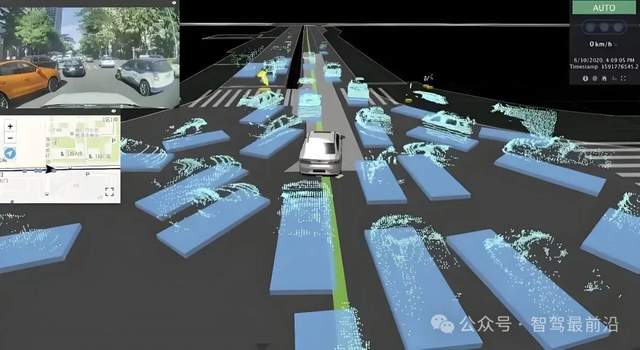
在这个过程中,BEV、Occupancy(占用网络)和Transformer的组合成了主流,而曾经在机器人领域立下汗马功劳的SLAM方案,却没有在智驾领域大放异彩。为什么无图智驾不使用SLAM建立局部语义地图?

为什么传统的几何建图跟不上变化?
传统的SLAM方案(即即时定位与地图构建)核心逻辑是基于几何约束的。它依赖于如系统提取出路边建筑的边缘、交通标志的转角等特征点的匹配,然后通过复杂的数学公式计算这些点在三维空间中的坐标。这种方案在处理静态、刚性的环境时会非常精确,但在城市交通这种动态、非刚性的环境下,几何逻辑就会遭遇严重的挑战。

图片源自:网络
因为SLAM方案在构建局部语义地图时,本质上是在做一种拼图工作。它需要先识别出图像里的车、人、路缘石,然后尝试把这些带语义标签的物体投影到地图坐标系里。一旦图像中出现了遮挡,或者是车辆在颠簸中导致相机角度发生了微小的偏移,几何投影就会产生错位,导致地图里的物体出现重影或位置漂移。更关键的是,这种方案对算力的消耗分布不均,随着环境复杂度的提升,维护一个精细的局部特征地图会占用大量的内存和处理时间。
在此基础上,语义断层也是一个无法回避的问题。传统的语义地图方案要求系统必须先看懂物体,才能将其画进地图。但在实际驾驶中,我们会遇到各种无法被归类的东西,比如路边垂下的树枝、洒在地上的建筑垃圾,或者是形状怪异的特种车辆。SLAM方案如果无法给这些物体贴上准确的标签,它们在局部地图里可能就是缺失的,这对自动驾驶的高安全要求来说是一个巨大的隐患。

Transformer是如何重塑空间感的?
BEV方案之所以在自动驾驶领域崛起,核心在于它引入了Transformer这种能够处理全局关联的架构,其彻底改变了空间特征的转化方式。在传统的方案中,我们要把2D图像转为3D空间,需要依赖深度估计,也就是先猜每一个像素点离我有多远,再把它投射出去。但猜深度本身就是一个极不稳定的过程,容易受到光影、雨雾的干扰。

图片源自:网络
Transformer引入了主动询问的机制。在BEV空间里,算法会先预设好一张空的鸟瞰图画布,画布上的每一个位置(我们称之为Query,即查询量)都会主动去向所有的摄像头画面打听,在你们的视野里,有没有哪个像素的信息是属于我这个地理位置的?这种机制不再强求系统去精准计算深度,而是通过大规模数据的学习,让系统建立起一种类似于人类的空间感。它知道当左侧相机出现一个车头,后侧相机出现一个车尾时,它们在BEV画布上应该汇聚成同一个物理实体的特征。
这种方式的最大优势在于它能够实现特征级的融合,而不是结果级的拼接。过去我们是把每个相机算出的结果强行凑在一起,现在我们是在最底层的特征阶段就把360度的信息融为一体。由于Transformer具有全局注意力机制,它甚至可以利用道路的整体轮廓来推断被遮挡区域的情况。如当一辆货车挡住了侧方视角时,系统可以结合前后的车道线走向,在BEV空间里脑补出货车后方的道路结构,这种逻辑的连贯性是传统SLAM方案难以企及的。

占用网络如何解决感知死角?
如果说BEV和Transformer联手解决了视野重构与空间还原的问题,让车辆看清了世界长什么样以及空间怎么分布,那么占用网络存在的意义,就是通过判定空间是否被占据,绕过了传统识别方案中必须先给物体分类的要求,解决了因为系统叫不出物体名字而造成的感知漏洞。
在SLAM语义地图里,如果系统识别不出一个物体是什么,它可能就会忽略这个物体的物理存在。而占用网络将空间细分为一个个微小的体素块,它的任务极其纯粹,即判断每一个小方块是被占据了,还是空的。

图片源自:网络
这种基于几何占用而非语义识别的逻辑,为智驾系统提供了一层物理保底。它把世界看作是一个充满障碍物的物理空间,而不是一张贴满标签的分类表。当车辆行驶在路上,无论前方是一个倒下的路标、一堆洒落的纸箱,还是一辆横着的事故车,占用网络都能实时反馈出那片空间是不可逾越的。它不需要知道那个东西叫什么,只需要知道那里的物理空间被占据了,从而引导车辆进行避让。
同时,这种方案还带来了极高的时空连续性。通过将Transformer处理后的特征注入到占用网络中,系统可以存储过去几个帧的信息,形成带记忆的4D空间感知。即使某个障碍物在某一瞬间被其他车辆遮挡了,系统依然记得在那个体素块里曾经检测到了物体,并能根据物体的运动趋势预测它现在的位置。这种对物理世界的连续理解能力,让无图智驾方案在处理复杂路口和突发状况时,表现得远比依赖静态语义地图的方案要从容和安全。

为什么这种组合成为了必然选择?
BEV、Transformer和Occupancy的结合,实际上是将原本支离破碎的感知环节统一到了同一个坐标系和同一种数学语言下。SLAM方案之所以没有在智驾领域得到应用,本质上是因为它试图在一个不断变动的世界里建立一套永恒不变的坐标,这在复杂的城市环境中成本太高、容错率太低。

图片源自:网络
自动驾驶需要拥抱不确定性,通过利用Transformer的强大拟合能力去处理相机间的视差和遮挡,利用BEV视角提供统一的决策基础,再利用占用网络补齐对未知物体的识别短板,可以让自动驾驶实现老司机的驾驶能力。这种架构不仅对传感器的安装位置、型号具有更强的兼容性,更重要的是,它极大简化了感知与下游规控环节的对接流程。
当规控系统拿到的不再是几个飘忽不定的语义标签和一堆散乱的点云,而是一张高清、实时、且包含了物理占用信息的3D鸟瞰图时,路径规划就会变得像玩赛车游戏一样直观。这种从底层逻辑上的简化与重构,正是无图智驾能够快速落地、并表现出超越人类司机反应潜力的根本原因,也是众多车企敢于选择无图的原因。
-
SLAM
+关注
关注
24文章
460浏览量
33424 -
自动驾驶
+关注
关注
794文章
15001浏览量
181597
发布评论请先 登录
为什么自动驾驶方案不再强调地图了?

ROS2 SLAM建图与导航实战--基于米尔RK3576开发板
面向视觉语言导航的任务驱动式地图学习框架MapDream介绍

SLAM如何为自动驾驶提供空间感知能力?
自动驾驶中的“无图”真的不需要地图吗?
什么是激光雷达 3D SLAM技术?

从高精地图到轻地图,再到“无图”,谁才是真需求?

自动驾驶中如何将稀疏地图与视觉SLAM相结合?
什么样的地图在自动驾驶中才能称为“轻图”?
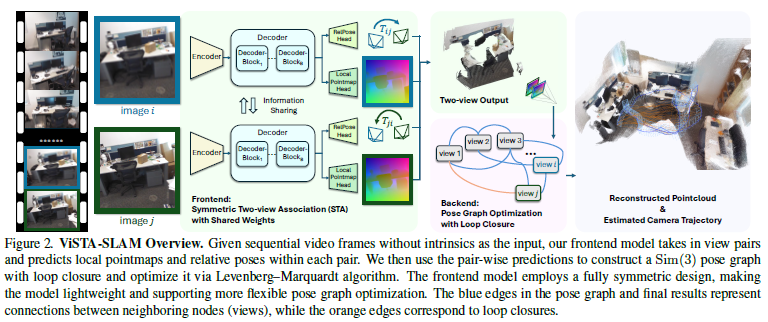
全新轻量级ViSTA-SLAM系统介绍
从“有图”到“无图”再到“轻图”,自动驾驶地图选择为何这么折腾?
又一智驾供应商要被收购?
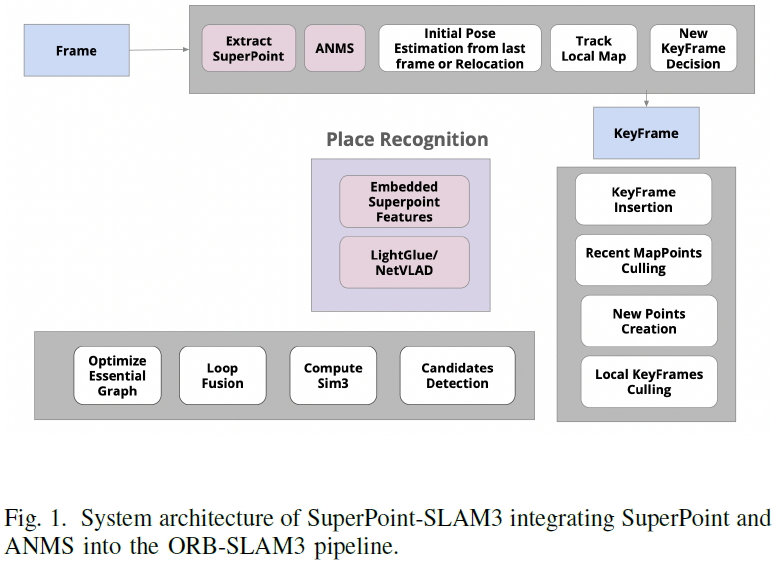
基于深度学习的增强版ORB-SLAM3详解
一种适用于动态环境的实时RGB-D SLAM系统




评论