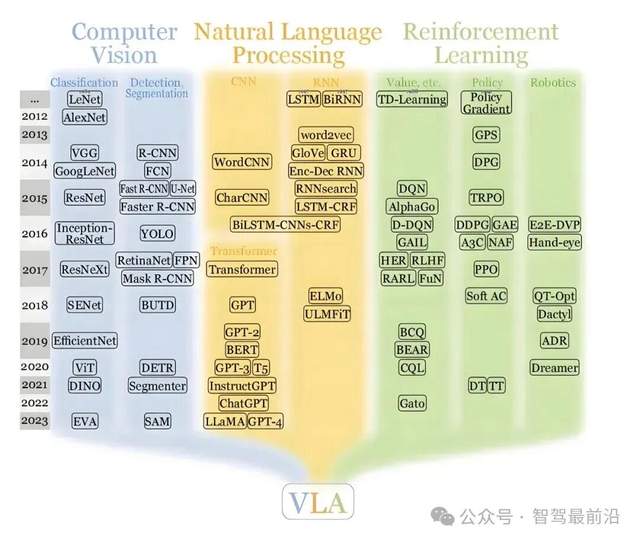
 VLA和世界模型在自动驾驶中可以融合吗?
VLA和世界模型在自动驾驶中可以融合吗?

[首发于智驾最前沿微信公众号]随着VLA(视觉-语言-动作模型)与世界模型在自动驾驶领域的关注度日益提升,这两项技术已成为众多主机厂研发布局的重点方向。前者强调将感知、语义推理与动作生成整合到同一个大模型中,以实现端到端的决策输出;后者则致力于在系统内部构建对物理环境的动态模拟与未来状态推演,以提升对复杂场景的预见与应对能力。那么,这两项技术是否可以深度融合,从而让自动驾驶系统实现更智能、更可靠的驾驶行为呢?
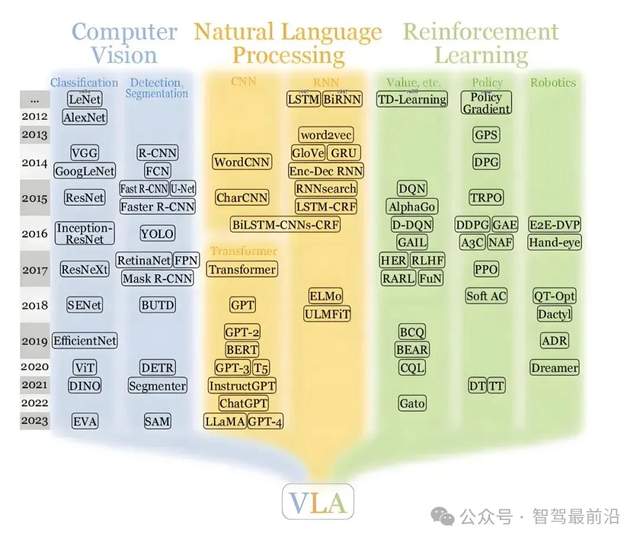
什么是VLA和世界模型
在自动驾驶中,VLA(Vision-Language-Action)是一种端到端的方法,其核心在于将“感知”“理解”与“执行”整合进同一个大模型中统一处理。VLA系统通过摄像头等传感器获取路面视觉信息,并将其转化为高维特征。这些特征随后被输入到经过扩展的大型视觉-语言模型(这类模型原本是为了文本和图像理解设计的)中,从而在模型内部完成语义推理,其不仅能识别车道线、行人、交通标志等要素,还能进一步分析行人意图、交通规则优先级等复杂情境。模型的输出被直接映射为如转向、加速或制动等具体的控制指令。
VLA的特点在于,它将传统自动驾驶流程中的感知、预测、规划与控制等多个模块,融合为“看—想—做”一体的连贯过程,并试图通过一个统一的网络实现从图像输入到动作输出的完整决策链条。
图片源自:网络
世界模型(WorldModel)则有着不同的核心设想。它不是单纯地把感知和控制打包成一个模型,而是在系统内部构建一个对外部物理环境的“动态模拟器”。换句话说,世界模型不仅能让自动驾驶系统看到当前的环境,还能在内部脑海里“演练”未来可能发生的场景。通过学习环境的动态规律,从而预测其他车辆、行人、信号灯等会如何变化,为决策提供更深层次的支持。世界模型的本质是在模型内部建立对世界的理解和因果关系,而不是只对当下图像产生反应;它强调的是对未来的推演与预测能力。

两种方法的本质差异
如果把自动驾驶比作“人类开车”,传统模块化方案就是把驾驶任务拆解为多个环节,一部分负责看路(感知),另一部分分析交通状况(理解与预测),再一部分做出决策(规划),最后一部分执行操作(控制)。VLA则是将这些环节尽可能地整合进一个统一的大模型,让它能够从视觉输入直接生成动作输出,并在模型内部借助语言或语义推理进行辅助决策。
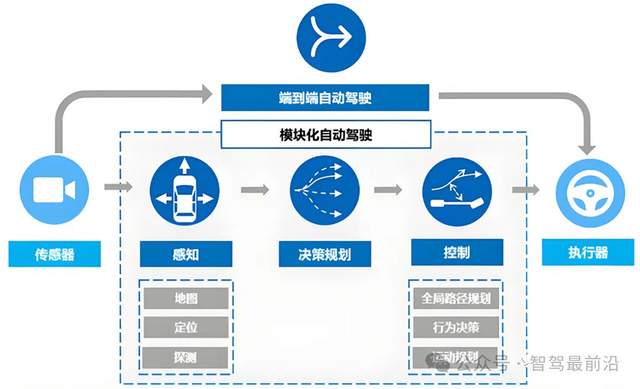
模块化与端到端的区别,图片源自:网络
世界模型的思路则是在系统内部设置一块看不见的“推演黑板”,持续模拟未来几秒甚至更长时间的路况变化,并将预测结果反馈给决策模块,使自动驾驶系统具备前瞻能力。
从技术角度看,VLA的核心是在一个统一的模型框架里融合感知、推理和动作生成,它的优势在于能够处理复杂的语义理解任务,同时使输出更加自然、直观。世界模型的核心是在模型内部建立对环境状态和动态规律的认识,从而支持基于当前状态进行多步未来预测。
VLA和世界模型在侧重点上有所不同,VLA偏向“从感知到行动”的端到端映射和高层语义推理,世界模型则偏向环境动态的模拟与未来情景的推演。VLA更接近“图像→语言→动作”的链式处理流程,而世界模型更侧重于“内部环境模型构建与预测推演”。它们并非相互排斥的技术路线,而是分别强化了自动驾驶系统的不同能力维度。
实际应用中融合的可能性
VLA与世界模型并不是彼此割裂的技术路径。就有技术显示,可以将世界模型的预测能力与VLA的“感知—推理—动作”能力相结合,使两者形成互补,从而提升自动驾驶系统的整体性能。
一种典型的融合思路是让VLA模型在学习动作输出的同时,也使其学习预测环境状态的变化,这本质上就是把世界模型的能力嵌入到VLA的训练目标中去。比如由中国科学院自动化研究所等机构提出的DriveVLA-W0框架,就提出利用世界模型来预测未来视图,从而为VLA模型提供更密集的训练信号。
传统VLA模型主要是通过采集到的动作数据来监督训练,由于动作信号维度低、信息稀疏,监督信号有限。引入世界模型后,模型还需预测未来图像,这使其内部必须学习环境动态规律,从而提升了数据利用效率和模型泛化能力。该策略提升了模型对环境动态的理解,同时保留了VLA的端到端输出能力。
图片源自:网络
此外,还有技术方案提出从架构层面推动两者的统一,设计能够同时涵盖视觉、语言、动作与动态预测的融合模型。这类架构通过共享内部表示让系统既具备良好的场景理解和动作规划能力,又能预测未来状态,这类融合模型在一些仿真测试或者机器人控制任务中表现出比单一方法更优的性能。虽然这些研究大多还处于实验阶段,但它们确实证明了VLA与世界模型在原理层面存在结合的可能性。

为什么融合能带来优势
自动驾驶的核心难点之一就是环境的复杂性和不确定性。驾驶环境瞬息万变,不同车辆、行人、信号灯以及道路情况都会影响决策。单纯依赖当前时刻的感知进行决策,难以应对未来几秒内可能发生的复杂变化,世界模型所强调的内部预测优势就在此处体现。世界模型让系统不只是“看到现在”,还能“想象接下来可能发生什么”,从而支持更稳健的规划。
此外,自动驾驶中的语义理解和高级推理也至关重要。车辆需要理解交通标志、判断行人意图、结合交通规则等,这些属于更高层的认知任务。VLA在这方面有优势,因为它借助大型视觉-语言模型的推理能力,可以把视觉输入映射到语义空间,使自动驾驶系统具备更强的抽象理解能力。
如果把世界模型比作一个能预测未来的“内部仿真器”,把VLA比作一个能理解场景语义和规则的“大脑”,那么二者结合就能让自动驾驶系统既能预判未来,又能做出基于语义理解的合适动作。这样的融合可以让系统在面对复杂场景时做出更稳健、更可靠的判断和控制。
技术融合的难点与挑战
想把世界模型引入VLA,训练过程就需要更多计算资源和数据支持。世界模型的训练依赖于从海量视频序列中学习环境动态规律,通过预测未来帧或状态来驱动内部表征的形成。这就需要极大规模的视频数据与强大的计算资源支撑,而自动驾驶系统本身的训练已对资源有很高要求,二者的结合将进一步提高训练门槛。
融合后的模型结构也会变得更复杂。在VLA里面,原本就有感知和推理两个大块,现在又要增加世界模型部分的动态预测,这就要求内部表示既要适合高层语义任务,又要能支持未来预测。这两种任务对内部表征的要求并不完全一致,这无疑增加了设计的难度。
实时性和车载部署也是难点。在实验室里跑大模型并融合世界模型预测可能效果很好,但在实际车辆上实时运行时会有严格的延迟约束和算力限制。这就要求在模型设计时就考虑如何压缩模型、如何在算力受限的环境中部署这种融合策略,否则就算理论上可行,在工程上也很难落地。

最后的话
VLA与世界模型虽然侧重点不同,却能为自动驾驶系统提供不同的能力。VLA主要解决系统能否在复杂交通场景中“看懂语义并做出合理动作”的问题;而世界模型则弥补了系统能否深入理解环境动态规律,在风险发生前进行预测与推演的能力。
将这两种能力融入同一架构中,自动驾驶的决策将不再仅依赖于当前时刻的感知结果,而是建立在对场景语义、动态演变与未来预期的综合理解之上。这种转变意味着自动驾驶正从“高性能感知系统”迈向真正具备环境理解和因果推理能力的智能体,这才是它走向高可靠性和规模化落地所必须跨过的一道门槛。
审核编辑 黄宇
-
Vla
+关注
关注
0文章
22浏览量
5915 -
自动驾驶
+关注
关注
794文章
14985浏览量
181461
发布评论请先 登录
未来已来,多传感器融合感知是自动驾驶破局的关键
FPGA在自动驾驶领域有哪些应用?
FPGA在自动驾驶领域有哪些优势?
【话题】特斯拉首起自动驾驶致命车祸,自动驾驶的冬天来了?
自动驾驶真的会来吗?
自动驾驶的到来
UWB主动定位系统在自动驾驶中的应用实践
自动驾驶汽车的定位技术
自动驾驶中常提的世界模型是个啥?
自动驾驶上常提的VLA与世界模型有什么区别?
VLA和世界模型,谁才是自动驾驶的最优解?
VLA能解决自动驾驶中的哪些问题?
VLA与世界模型有什么不同?





评论