 自动驾驶中常提的VLA是个啥?
自动驾驶中常提的VLA是个啥?

[首发于智驾最前沿微信公众号]随着自动驾驶技术落地,很多新技术或在其他领域被使用的技术也在自动驾驶行业中得到了实践,VLA就是其中一项,尤其是随着端到端大模型的提出,VLA在自动驾驶中的使用更加普遍。那VLA到底是个啥?它对于自动驾驶行业来说有何作用?
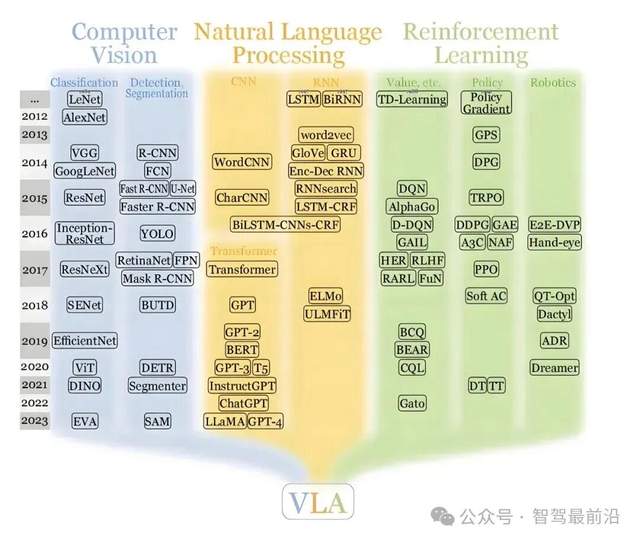
VLA全称为“Vision-Language-Action”,即视觉-语言-动作模型,其核心思想是将视觉感知、语言理解与动作决策端到端融合,在一个统一的大模型中完成从环境观察到控制指令输出的全过程。与传统自动驾驶系统中感知、规划、控制模块化分工的思路不同,VLA模型通过大规模数据驱动,实现了“图像输入、指令输出”的闭环映射,有望大幅提高系统的泛化能力与场景适应性。
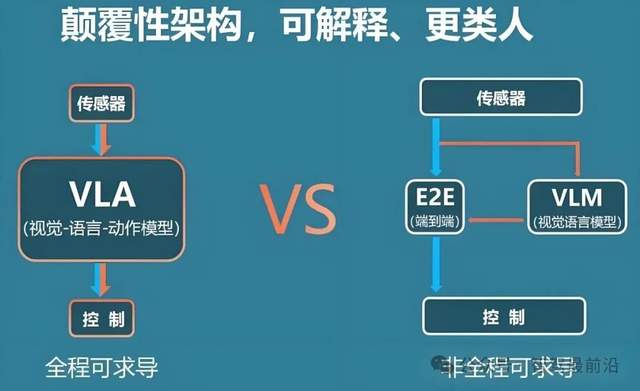
VLA最早由GoogleDeepMind于2023年在机器人领域提出,旨在解决“视觉-语言-动作”三者协同的智能体控制问题。DeepMind的首个VLA模型通过将视觉编码器与语言编码器与动作解码器结合,实现了从摄像头图像和文本指令到物理动作的直接映射。这一技术不仅在机器人操作上取得了突破,也为智能驾驶场景引入了全新的端到端思路。
在自动驾驶领域,感知技术通常由雷达、激光雷达、摄像头等多种传感器负责感知,感知结果经过目标检测、语义分割、轨迹预测、行为规划等一系列模块处理,最后由控制器下发方向盘和油门等动作指令。整个流程虽条理清晰,却存在模块间误差累积、规则设计复杂且难以覆盖所有极端场景的短板。VLA模型正是在此背景下应运而生,它舍弃了中间的手工设计算法,直接用统一的神经网络从多模态输入中学习最优控制策略,从而简化了系统架构,提高了数据利用效率。
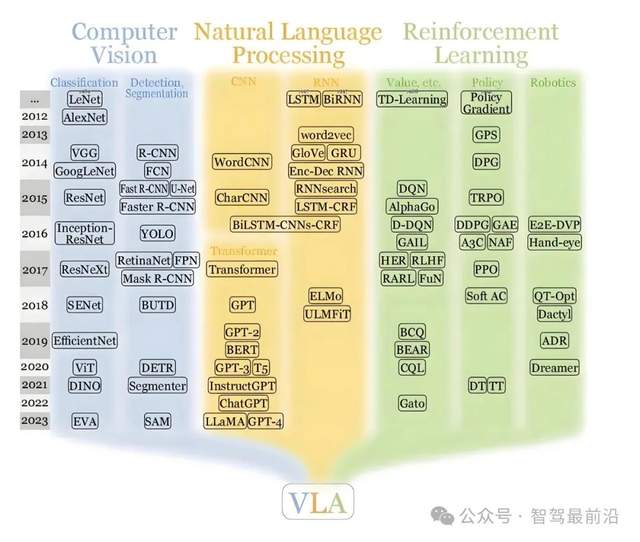
VLA模型通常由四个关键模块构成。第一是视觉编码器,用于对摄像头或激光雷达等传感器采集的图像和点云数据进行特征提取;第二是语言编码器,通过大规模预训练的语言模型,理解导航指令、交通规则或高层策略;第三是跨模态融合层,将视觉和语言特征进行对齐和融合,构建统一的环境理解;第四是动作解码器或策略模块,基于融合后的多模态表示生成具体的控制指令,如转向角度、加减速命令等。
在视觉编码器部分,VLA模型一般采用卷积神经网络或视觉大模型(VisionTransformer)对原始像素进行深度特征抽取;同时,为了增强对三维场景的理解,部分研究引入三维空间编码器,将多视角图像或点云映射到统一的三维特征空间中。这些技术使VLA在处理复杂道路环境、行人辨识和物体追踪上拥有较传统方法更强的表现力。
语言编码器则是VLA与传统端到端驾驶模型的最大差异所在。通过接入大规模预训练语言模型,VLA能够理解自然语言形式的导航指令(如“前方在第二个红绿灯右转”)或高层安全策略(如“当检测到行人时务必减速至5公里/小时以下”),并将这些理解融入决策过程。这种跨模态理解能力不仅提升了系统的灵活性,也为人车交互提供了新的可能。
跨模态融合层在VLA中承担着“粘合剂”作用,它需要设计高效的对齐算法,使视觉与语言特征在同一语义空间内进行交互。一些方案利用自注意力机制(Self-Attention)实现特征间的深度融合,另一些方案则结合图神经网络或Transformer结构进行多模态对齐。这些方法的目标都是构建一个统一表征,以支持后续更准确的动作生成。
动作解码器或策略模块通常基于强化学习或监督学习框架训练。VLA利用融合后的多模态特征,直接预测如转向角度、加速度和制动压力等连续控制信号。这一过程省去了传统方案中复杂的规则引擎和多阶段优化,使整个系统在端到端训练中获得了更优的全局性能。但同时也带来了可解释性不足、安全验证难度增大等挑战。
VLA模型的最大优势在于其强大的场景泛化能力与上下文推理能力。由于模型在大规模真实或仿真数据上学习了丰富的多模态关联,它能在复杂交叉路口、弱光环境或突发障碍物出现时,更迅速地做出合理决策。此外,融入语言理解后,VLA可以根据指令灵活调整驾驶策略,实现更自然的人机协同驾驶体验。
国内外多家企业已开始将VLA思想应用于智能驾驶研发。DeepMind的RT-2模型在机器人控制上展示了端到端视觉-语言-动作融合的潜力,而元戎启行公开提出的VLA模型,被其定义为“端到端2.0版本”,元戎启行CEO周光表示“这套系统上来以后城区智驾才能真正达到好用的状态”。智平方在机器人领域推出的GOVLA模型,也展示了全身协同与长程推理的先进能力,为未来智能驾驶提供了新的参考。
VLA虽然给自动驾驶行业提出了新的可能,但实际应用依旧面临很多挑战。首先是模型可解释性不足,作为“黑盒子”系统,很难逐步排查在边缘场景下的决策失误,给安全验证带来难度。其次,端到端训练对数据质量和数量要求极高,还需构建覆盖多种交通场景的高保真仿真环境。另外,计算资源消耗大、实时性优化难度高,也是VLA商用化必须克服的技术壁垒。
为了解决上述问题,也正在探索多种技术路径。如有通过引入可解释性模块或后验可视化工具,对决策过程进行透明化;还有利用Diffusion模型对轨迹生成进行优化,确保控制指令的平滑性与稳定性。同时,将VLA与传统规则引擎或模型预测控制(MPC)结合,以混合架构提高安全冗余和系统鲁棒性也成为热门方向。
未来,随着大模型技术、边缘计算和车载硬件的持续进步,VLA有望在自动驾驶领域扮演更加核心的角色。它不仅能为城市复杂道路提供更智能的驾驶方案,还可扩展至车队协同、远程遥控及人机交互等多种应用场景。智驾最前沿以为,“视觉-语言-动作”一体化将成为自动驾驶技术的主流方向,推动智能出行进入新的“端到端2.0”时代。
VLA作为一种端到端多模态融合方案,通过将视觉、语言和动作三大要素集成到同一模型中,为自动驾驶系统带来了更强的泛化能力和更高的交互灵活性。尽管仍需解决可解释性、安全验证与算力优化等挑战,但其革命性的技术框架无疑为未来智能驾驶的发展指明了方向。随着业界不断积累实践经验、优化算法与完善安全体系,VLA有望成为自动驾驶领域的“下一代技术基石”。
审核编辑 黄宇
-
Vla
+关注
关注
0文章
25浏览量
5921 -
自动驾驶
+关注
关注
795文章
15057浏览量
182001
发布评论请先 登录
自动驾驶中常提的鲁棒性是个啥?
自动驾驶中常提的SLAM到底是个啥?
自动驾驶大模型中常提的Token是个啥?对自动驾驶有何影响?
自动驾驶中常提的“NOA”是个啥?
自动驾驶中常提的“点云”是个啥?
自动驾驶中常提的HMI是个啥?
自动驾驶中常提的世界模型是个啥?
自动驾驶中常提的惯性导航系统是个啥?可以不用吗?
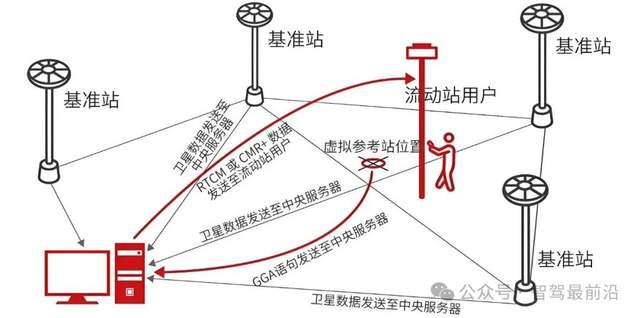
自动驾驶中常提的RTK是个啥?
自动驾驶中常提的硬件在环是个啥?
自动驾驶中常提的ODD是个啥?
自动驾驶中常提的“专家数据”是个啥?
自动驾驶上常提的VLA与世界模型有什么区别?
自动驾驶中常提的“强化学习”是个啥?

VLA能解决自动驾驶中的哪些问题?



评论