 声智科技全球首发新一代人机交互框架
声智科技全球首发新一代人机交互框架

全球人工智能产业正经历人机交互范式升级。过去两个月中,以OpenAI、Meta为代表的行业领军企业加速推进交互技术创新迭代,推动产业进入关键变革期。值得关注的是,a16z合伙人Olivia Moore与Anish Acharya在深度访谈中系统阐释了"语音交互将成为AI应用最具突破潜力的核心接口"这一战略判断,明确指出在消费级市场,语音交互极可能发展为用户接触AI系统的首要触点,甚至演进为主导型交互模态。
作为声学计算与人机交互领域的深耕者,声智科技自创立以来始终致力于声学计算与人机交互核心技术研发。在AIoT发展初期阶段,公司即构建起具备行业领先性的人机交互技术架构,成功赋能智能音箱、摄像头等终端设备实现语音交互功能,形成"技术前瞻布局-产品快速迭代-市场精准适配"的良性发展模式。
在全球化AI技术竞速背景下,声智科技率先取得革命性突破。2025年5月正式发布了创新性论文《面向真实世界人机交互的非线性声学计算与强化学习协同框架》。
论文题目:A Synergistic Framework of Nonlinear Acoustic Computing and Reinforcement Learning for Real-World Human-Robot Interaction
代码链接:https://github.com/soundai2016/nonlinear-acoustic-rl-hri
论文链接:https://arxiv.org/abs/2505.01998
论文首次提出与国际标准接轨的新一代真实世界人机交互框架,并同步公布全栈算法的测试数据,多项指标均处于业界领先水平。
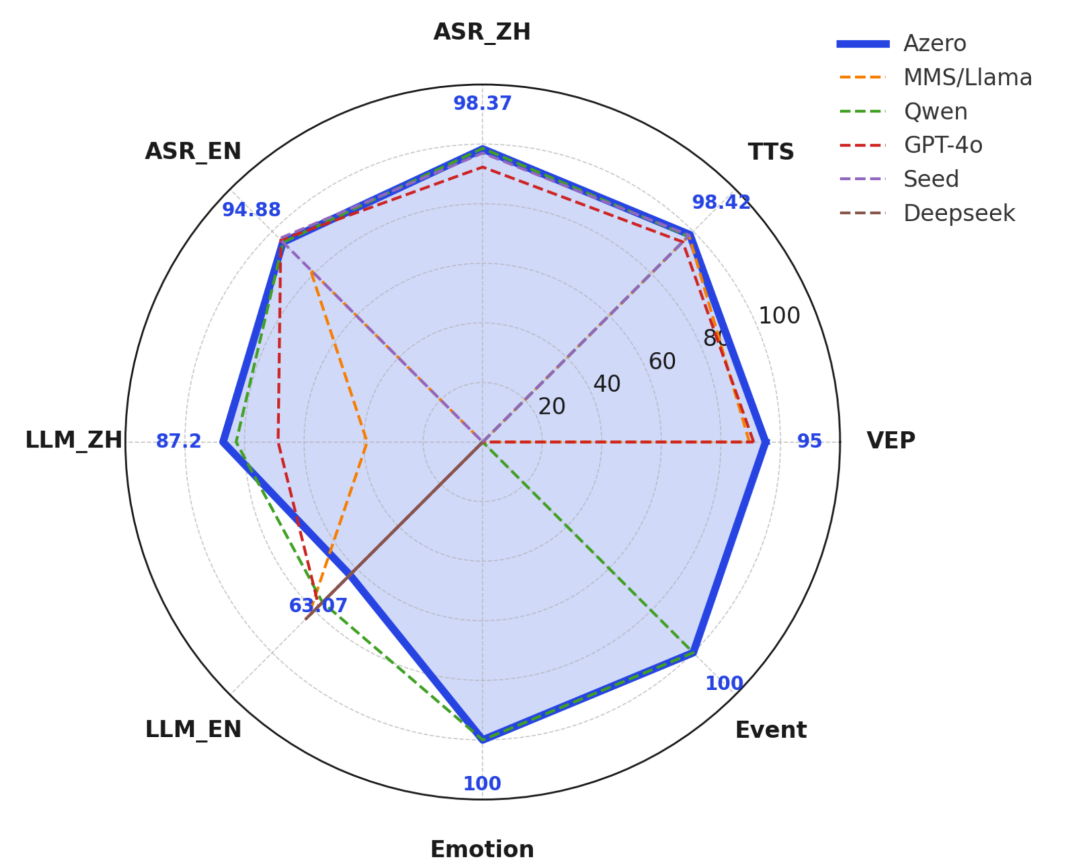
以上数据来源于公开论文,对 Azero、MMS/Llama、Qwen、GPT-4o、Seed 和 Deepseek 六家公司的系列模型在八项关键指标(语音增强模型VEP、语音克隆模型TTS、语音识别中文模型ASR_ZH、语音识别英文模型ASR_EN、语言模型中文能力LLM_ZH、语言模型英文能力LLM_EN、声音情感识别模型Emotion、声学事件识别模型Event)上的统一测评,结果显示 Azero 以信号蓝粗实线突出其卓越表现:在声学语音增强(VEP 95)和语音克隆合成质量(TTS 98.42)上稳居榜首,中英文识别准确率分别达到 98.37% 和 94.88%,中文理解能力 87.2 分优于多数竞品;值得一提的是,Azero 兼具实时的声音情感和声学事件识别能力,充分证明了其在远场声学、语音克隆、多语交互及语言理解上的全栈算法与领先实力。
该研究突破传统线性声学模型限制,通过非线性计算与强化学习的协同优化,成功实现复杂场景下的自适应交互能力,为"AI融入真实世界(Real World Experience)"战略目标提供了关键技术支撑。在持续深化技术布局的同时,声智着力构建基于听觉感知的入口级技术,致力于打造具备真实场景理解能力的人机交互架构,为下一代AI应用产品落地提供底层技术架构支持,推动人机交互从"被动接收"向"主动感知"的跨越式发展。
全场景语音识别:
畅通真实世界的"沟通桥梁"
声智科技在声学信号处理领域的突破,本质上是对"复杂环境听觉能力"的革命性重构。
噪声抑制:
从 "可听" 到 "听清" 的质变跨越
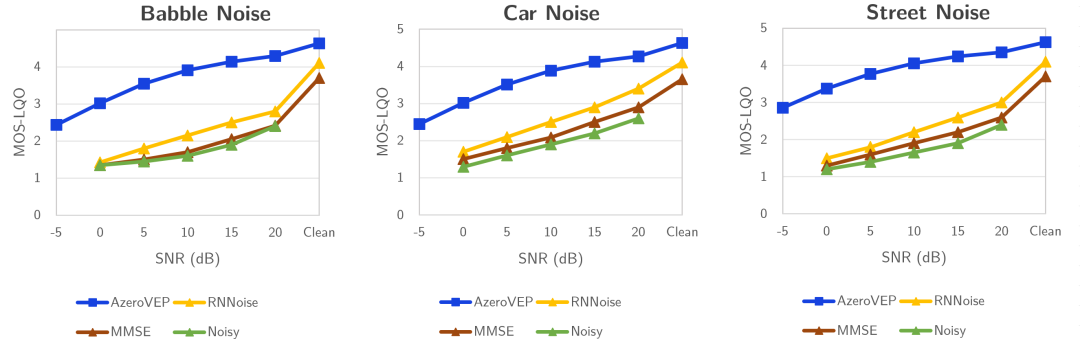
在对声音降噪算法进行深入分析时,通常会在多种信噪比(SNR)条件下进行系统测试——从极端低信噪比(如–5dB的强噪环境)到高信噪比(如20dB的低噪环境),并结合多种评测指标(如PESQ、MOS-LQO、STOI、SDR等)来全面量化算法在不同噪声强度与类型(白噪、Babble噪声、交通噪声、街道噪声等)下的性能表现。通过对比各个SNR点上的语音清晰度、可懂度和音质恢复效果,可以直观地评估算法的低信噪比鲁棒性、高信噪比分辨力以及对多场景噪声的普适适应能力。
在极端噪声环境下,声智噪声分离模型可实现信噪比提升,首次在超高频噪声场景中实现"噪声隔离级"清晰语音还原。
以下是声智Azero算法在本次测试中展现的两大核心优势特性。
一是极低信噪比鲁棒性,在-5dB极低信噪比噪声环境下,仅有Azero算法能够处理 ,并且性能表现良好,具有更好的鲁棒性和实时性。
二是多场景普适性,在Babble Noise、 Car Noise、Street Noise 等真实场景中,降噪性能均大幅领先海外降噪技术评测结果(详见下图蓝色线条),且对噪声类型的识别范围更宽泛、在极低信噪比的恶劣环境下仍能进行高清晰度的人声增强,真正实现"地铁喧哗中听清耳语,闹市街头精准拾音"。
声音克隆:
音色相似度与合成准确率评测双登顶
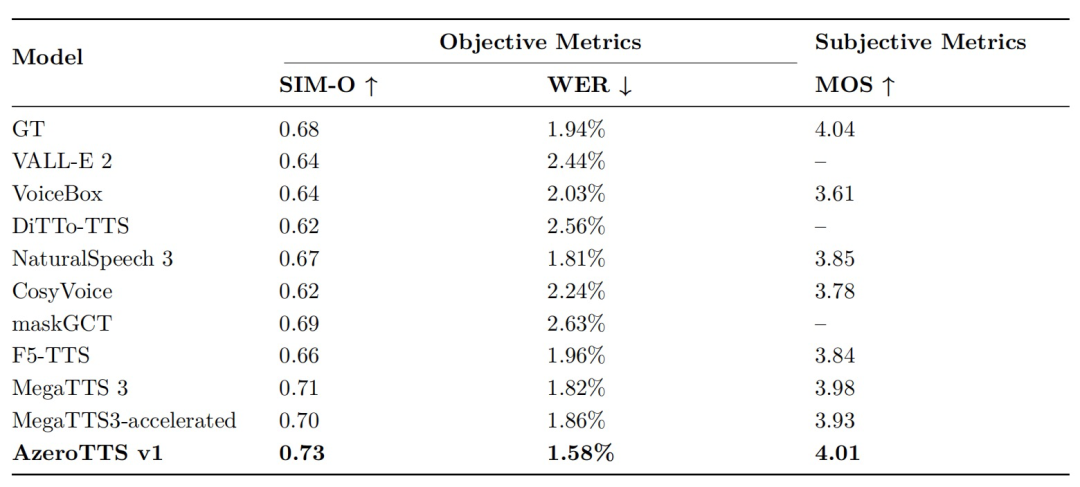
在声音克隆技术中,AzeroTTS的SIM-O音色相似度达0.73,词错率WER低至1.58%,MOS自然度评分4.01,等同于真实语音。对比LibriSpeech数据集,其内容准确率超越VALL-E2、VoiceBox等国际顶尖模型,在低成本的真实环境下能够实现"音色复刻如临其境,内容还原分毫不差"。自创始以来,声智科技十分注重面向真实场景的用户服务落地,声音克隆技术目前已在声智APP上线,面向全球用户不断提升体验感。
情感感知:
实时捕捉人类情绪的"第六感官"
在强噪声环境下,可精准区分多种声音情感及400+声学环境事件(如爆竹声、引擎轰鸣声、婴儿笑声)。即使在车水马龙的街头,也能通过语音语调变化捕捉用户的细微情绪,为智能设备赋予超强"共情力"。
毫秒级响应:
构建低延迟交互基石
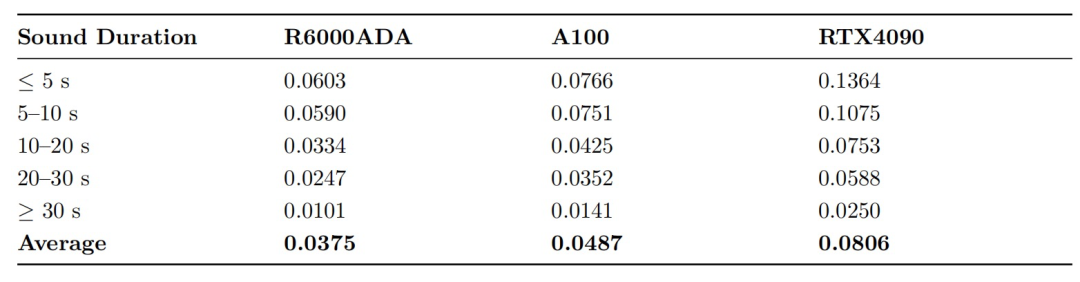
通过波束成形与残差网络优化,在RTX6000Ada平台上,平均RTF低至0.0375(A100为0.0487,RTX4090为0.0806),即使在30秒以上长音频处理中,RTF仅0.0101,真正满足实时通话、直播降噪等毫秒级延迟敏感场景需求。
全场景语音识别:
畅通真实世界的"沟通桥梁"
声智的语音技术优势,不仅在于"听得清",更在于"听得准""听得懂"。
复杂噪声精准识别:
准确率超越OpenAI
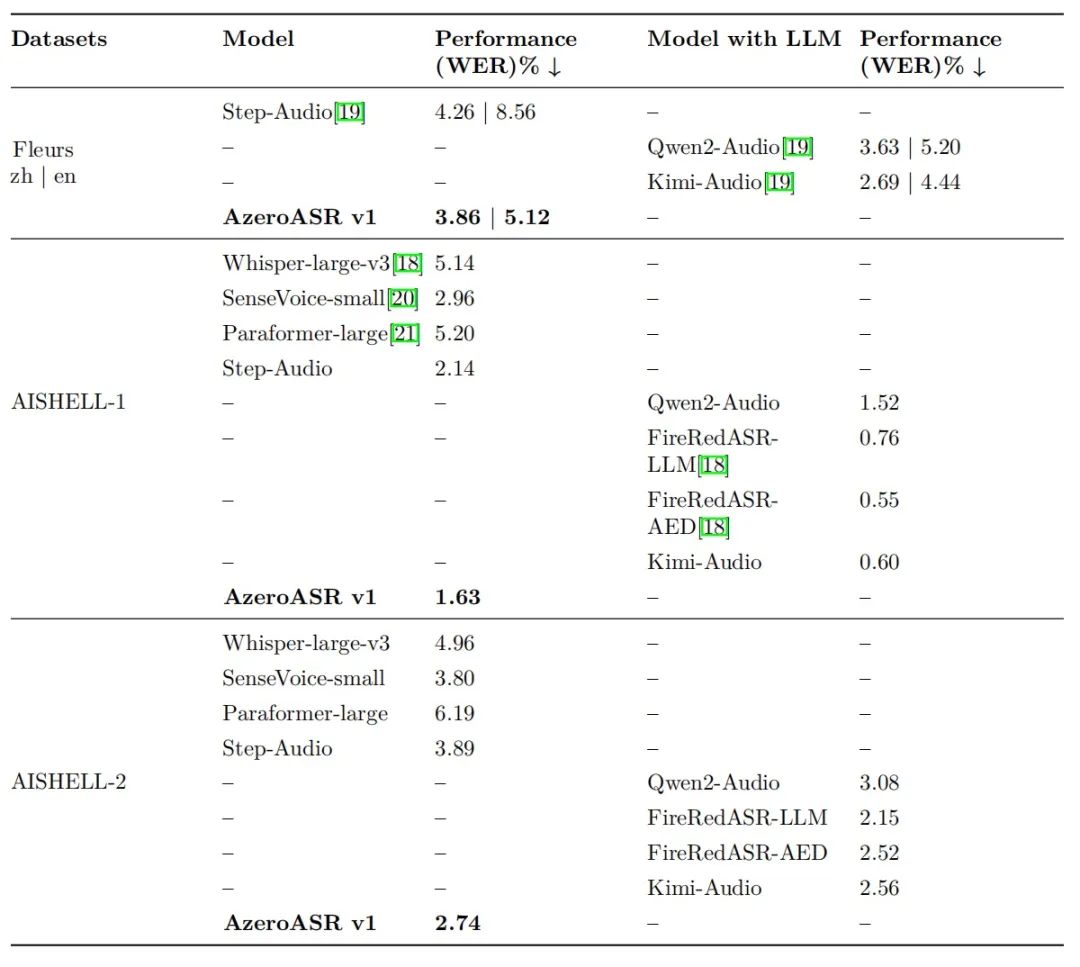
中文场景:在AISHELL-1数据集上,WER指标优于其他模型;AISHELL-2复杂场景下,领先行业平均水平。
英文场景:Fleurs数据集上WER指标测评表现优异,且不依赖大型语言模型做后处理校正,纯模型原始输出即达行业顶尖水平。
多种语言混杂识别:
真实场景21种语言识别准确率90%+
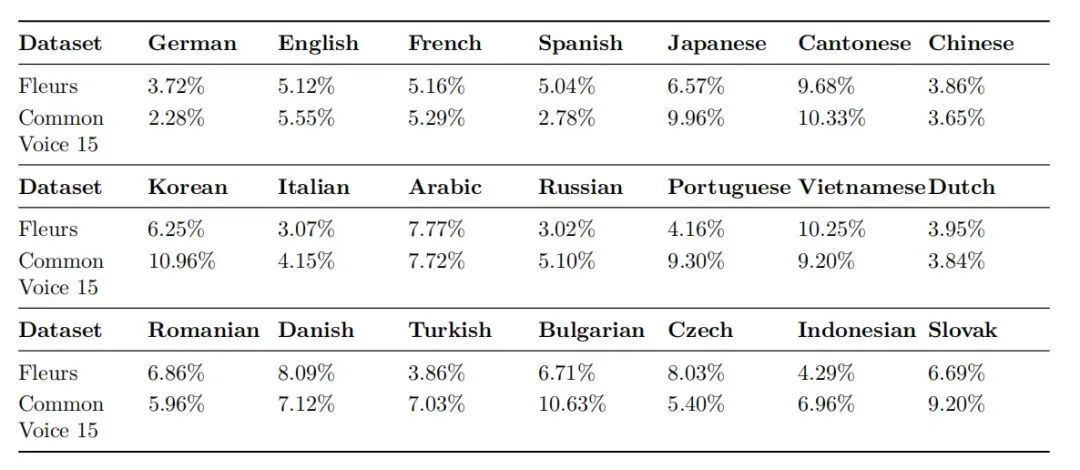
在真实语言场景下,香港、新加坡、马来西亚等具有典型多语系特征的区域,因其独特的语言生态对智能系统的多语交互能力提出了更高要求。这些地区涉及不同语言变体的复杂转换——香港的粤语夹杂英语词汇的港式表达、新加坡融合福建方言的华语形态、马来西亚带有马来语元素的华文语境,都要求语言识别技术具备深度文化适应能力。
面向此种真实环境需求,声智在Fleurs和CommonVoice两个国际权威的多语种语音数据集上进行了全面测试,实验结果表明,声智的语音识别模型在不同语种下均表现出色,识别准确率稳定保持在90%以上。从欧洲小语种到亚洲地方语言,实现"一套模型,全球通听"的跨语言识别与翻译。
"轻量""智答"语言模型:
让机器学会"耳脑协同"的交互艺术
在新一代人机交互的技术架构中,语言模型从"算力竞赛"转向"效能突围"。基于声学技术构建的底层感知系统,轻量级语言模型承担着人机交互的"认知中枢"角色,通过精准的语义泛化、逻辑推理与意图提炼,在低成本的算力条件下实现语音指令的高效解析与自然响应,构建贴近真实场景的交互体验。这种"小而精"的技术路径,使语言模型真正成为连接用户需求与设备功能的效能枢纽,推动人机交互从"技术堆砌"向"体验优先"转型,为智能硬件和AI应用服务落地提供可持续的技术底座。
"小而精"技术路径:
评测位列第一梯队
AzeroGPT:依托数亿级参数量基底,在权威榜单中表现亮眼;
C-Eval:人文社科领域、STEM领域排名靠前,超越多数语言大模型;
Livebenchcode_v5:轻量化设计使其算力需求远低于传统大模型,性价比优势显著。

从技术构想走向场景落地:
开启主动感知人机交互新纪元
“ 在人工智能技术高速迭代的今天,当行业目光逐渐从模型参数竞赛转向真实场景价值落地,声智科发布的人机交互框架,正以"可落地、可验证、可生长"的技术特质,打破"实验室技术"与"现实应用"的壁垒,让"机器理解人类"不再停留在理论构想,而是成为触手可及的交互体验。声智的 "主动感知" 框架深度锚定三大核心体验维度:"闻声知意,懂你所需"、"闻声辨境,知你所求"、"听你所言,知你所想"。声智的技术突围,源于对"场景价值"的深度解构,通过非线性声学计算技术穿透复杂环境噪声,结合强化学习构建场景化决策模型,形成"感知 - 理解 - 预测 - 优化"的闭环能力。这种"轻量架构 + 重场景适配"的设计,在智能汽车、工业机器人、智慧医疗等领域实现低成本快速部署,同时保持复杂环境指令解析准确率。
智慧生活:
设备从"听见"到"听懂"再到"预判需求"
在智慧生活场景下使设备具备"听觉认知"能力,用户可感知到设备从"被动接收指令"转变为"主动适应场景,核心技术闭环(声学采样→动态优化→环境分析→精准输出)能带来核心生活场景革新,如通勤、办公、居家等,从喧嚣闹市到静谧空间,每一次声音的处理都是"主动感知"技术的生动演绎,它正引领我们迈向面向真实世界的多场景自适应人机交互新纪元,让智慧感知深度融入生活,重塑每一个与声音相伴的瞬间,为生活注入更智能、更贴心的体验。
智慧医疗健康:
个性化监测与关怀
智慧医疗健康场景正呈现"感知-解析-响应"全链路的突破性革新 。例如AI助听设备可精准处理环境音,滤除干扰,动态补偿个体听觉差异,让用户清晰感知声音,实现更贴心的健康关怀。当用户发现自己的咳嗽声能被转化为肺炎风险指数,当帕金森患者从语音震颤分析中获得黄金干预期,当地方方言不再成为医患沟通壁垒,语音交互已超越工具属性,成为贯穿预防-诊断-治疗-康复全流程的医疗新界面。这种变革不仅体现在参数提升,更让每个生命个体感知到:医疗健康服务开始真正"听懂"并"理解"人类最自然的表达方式。
AI机器人:
听觉系统的场景化演进
AI机器人可通过声学智能实现从物理执行到环境共生的跨越式进化,通过AI声学降噪算法与AI声学分类算法的处理,AI机器人能够精准捕捉真实世界的声音信息,并对声音事件与声音情感进行深度解析,实时构建环境模型,让机器人能够理解所处的声学环境。家庭服务机器人能根据厨房环境底噪中的燃气泄漏特征音提前2秒报警,当教育机器人从儿童断续抽泣声中识别焦虑指数并切换安抚模式,人类正见证机器人突破物理传感器的局限,它们不仅能“听见”声音,更能理解声波背后隐藏的机器状态、生理特征与情感意图,这种基于声学全息感知的交互进化,让人机协作从精准响应升级为预见性共融。
声智科技在人机交互框架领域取得的技术突破,不仅体现在评测体系性能指标的量化提升,更重要的是实现了从基础功能实现到体验价值创造的全链路技术升级。伴随全球AI产业的高速演进,工业机器人、智能汽车、精准医疗及航天科技等战略领域正面临智能化升级的迫切需求。依托新一代人机交互框架的技术优势,声智通过构建智能听觉感知系统与决策中枢系统的深度协同,以非线性声学计算为技术底座,推动AI交互范式从被动响应向主动认知演进。该系统不仅能实现毫秒级实时需求响应,更通过多模态行为建模与预测算法,在用户需求显性化前完成服务预判。
我们创新性地将非线性声学计算与深度强化学习相结合,构建出具备环境认知与意图推理能力的智能交互系统。这种技术融合使机器系统突破传统规则引擎的限制,形成场景自适应的动态决策能力:通过实时声场建模准确解析物理环境特征,结合强化学习算法持续优化交互策略,最终实现"场景理解-用户认知-行为预判"的三维智能闭环。这种进化将重新定义人机交互范式,使智能设备具备情境感知与自主决策能力,推动智能服务向认知智能阶段演进。
值得强调的是,真实场景数据与用户体验指标的深度融合正成为技术迭代的核心驱动力。声智建立的"数据-算法-体验"协同进化机制,不仅加速非线性声学模型的场景适应能力,更通过强化学习框架实现交互策略的持续优化。这种双向赋能的技术路径,正在重塑人机协作的底层逻辑,为各行业智能化转型提供可进化的认知中枢系统。但我们需要清醒认识到,真正的真实世界体验模型尚未真正落地,特别是在物理规律约束建模、多模态感知融合等关键领域仍存在突破空间,AI时代才刚刚开始。
-
机器人
+关注
关注
213文章
31494浏览量
223794 -
AI
+关注
关注
91文章
41295浏览量
302669 -
声智科技
+关注
关注
0文章
91浏览量
2380
原文标题:声智全球首发新一代人机交互框架:非线性声学与强化学习让AI融入真实世界
文章出处:【微信号:声智科技,微信公众号:声智科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
10寸人机交互装置引领开关柜智能运维新时代

人机界面交互装置:10KV开关柜的“智慧中枢”

从“人机交互”到“数字预演”:详解 HMI、SCADA 与虚拟调试的闭环架构

中科创达旗下Rightware携手高通发布智能汽车人机交互解决方案
时识科技CES 2026趋势看点前瞻
澎峰科技荣获2025新一代人工智能创业大赛总决赛二等奖
声智科技携手英飞凌探讨新一代声学感知技术方案
CIE全国RISC-V创新应用大赛 呼吸机人机交互系统
眼电EOG人机交互会是未来交互的一种主流吗?

AI眼镜或成为下一代手机?谷歌、苹果等巨头扎堆布局
重构未来自适应人机交互的创新技术

边聊安全 | 人机交互对功能安全的影响

人机交互:连接人类与数字世界的桥梁




评论