 PPTAgent: 大模型驱动的PPT自动生成
PPTAgent: 大模型驱动的PPT自动生成

论文题目
PPTAgent: Generating and Evaluating Presentations Beyond Text-to-Slides
论文链接
https://arxiv.org/abs/2501.03936
项目仓库
https://github.com/icip-cas/PPTAgent
演示视频
在数字化时代,演示文稿(PPT)作为信息传递的重要媒介,其自动化生成需求愈发迫切。然而,一份优秀的演示文稿不仅需要引人入胜的故事线,还需要抓人眼球的视觉效果和内容的有效组织,这对创作者提出了极高的要求。针对这一挑战,中国科学院软件研究所中文信息处理实验室提出了一种突破性的演示文稿自动生成框架 PPTAgent。
不同于传统的端到端生成方法,PPTAgent 借鉴了人类创作 PPT 的过程,采用基于编辑的工作流程。正如经验丰富的演讲者往往会参考优秀的演示文稿来优化自己的作品,PPTAgent 也通过分析和编辑参考演示文稿来生成新的内容。
PPTAgent 设计的框架包含两个关键阶段:首先是“演示文稿分析”阶段,系统会深入分析作为参考的演示文稿,提取每张幻灯片的语义信息。随后在“演示文稿生成”阶段,系统首先会基于文档内容生成详细的演示大纲,并为每张幻灯片分配合适的参考模板及相关文档段落。对于待生成的每张幻灯片,PPTAgent 能够根据输入内容自动调整幻灯片参考模板中的文本和视觉元素,通过生成的代码指令来完成元素的创建、编辑和删除等操作。通过这种方式,PPTAgent 不仅确保了生成内容的连贯性,还保持了视觉设计的美观度。
同时,我们还提出了首个全面的演示文稿评估框架 PPTEval,从内容、设计和结构连贯性三个维度评估演示文稿的质量,为自动化生成技术的改进提供了细粒度的反馈。实验结果表明,PPTAgent 能够生成高质量的演示文稿,在 PPTEval 的评估中取得了 3.67 的平均得分,并在来自不同领域的实验数据上展现出了 97.8%的任务成功率。
PPTAgent
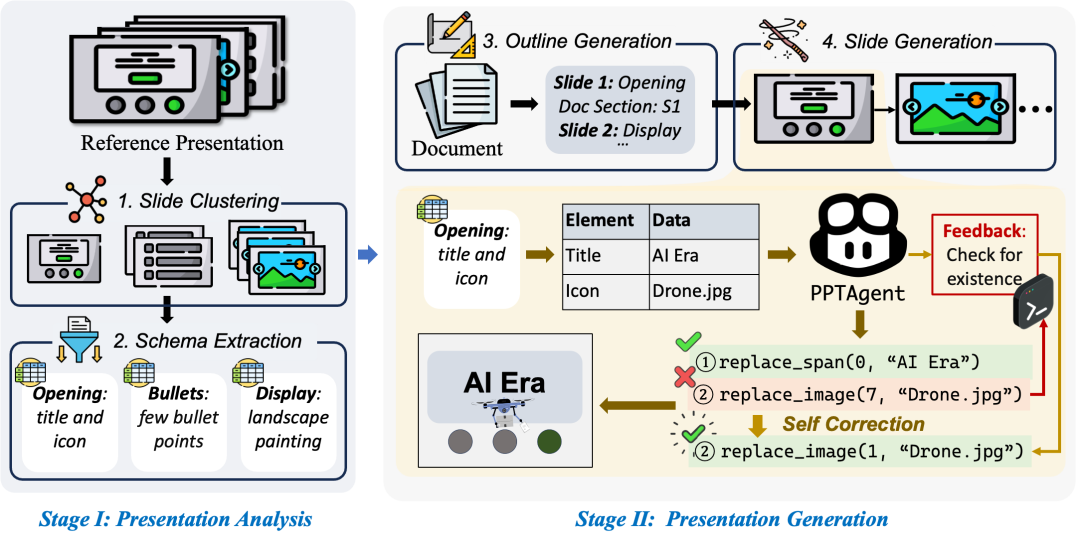
阶段一:演示文稿分析 在这个阶段,PPTAgent 首先对参考演示文稿进行全面分析以提取其中包含的语义信息。具体来说:
根据功能将幻灯片分为两大类:支持演示结构的幻灯片(如开场页)和传递具体内容的幻灯片(如要点页)。针对不同类型,PPTAgent 采用基于图片相似度或大语言模型的方法对参考演示文稿中的幻灯片进行聚类,并利用大语言模型的上下文感知能力对该页的功能进行描述。
考虑到现实世界中幻灯片内容的复杂性和碎片性,我们利用大语言模型进一步地提取幻灯片的内容模式(schema),包括幻灯片元素的类别、形式和具体内容。这些信息为后续的编辑过程提供了重要指导。
阶段二:演示文稿生成
在生成阶段,我们采用了基于编辑的生成范式,具体流程包括:
首先根据上一阶段分析得到的幻灯片语义信息和输入文档生成结构化大纲,为新演示文稿中的每张幻灯片指定参考模板和输入文档中的相关内容。
基于我们设计的 API 接口,生成可执行的代码指令来对幻灯片中的元素进行编辑修改。此外,我们还引入了实时的错误反馈机制,系统能够根据执行过程中的错误反馈进行自我纠正,显著提高了生成的稳定性。
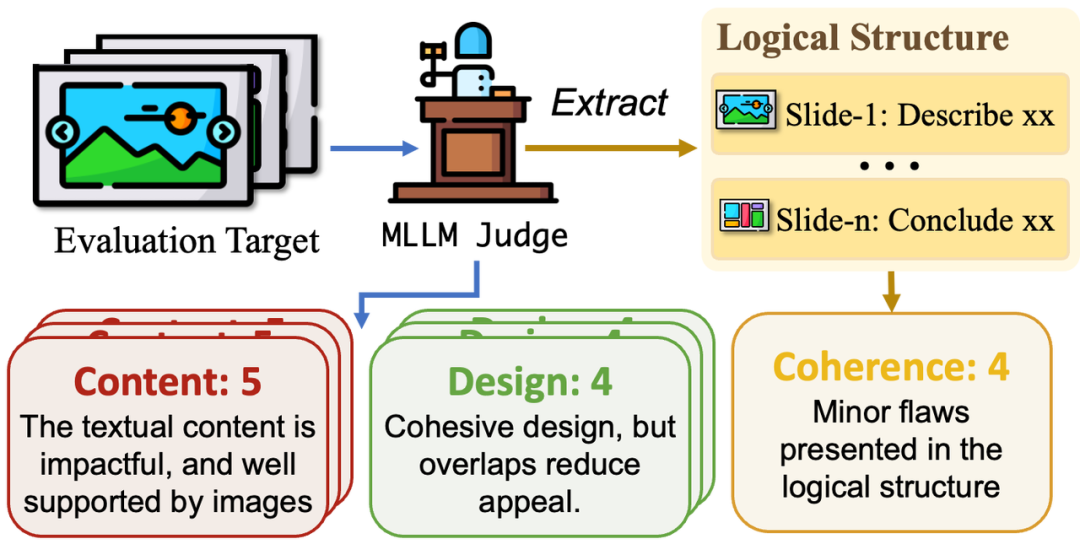
PPTEval:基于 LLM-as-a-Judge 范式的幻灯片质量评估
此外,为了能够有效和全面地评估生成幻灯片的质量,我们还开发了 PPTEval 评估框架,利用大语言模型来从三个维度对演示文稿进行全面评估:
内容(Content):评估幻灯片中文本和图像的相关度、文本内容信息量和质量,确保传达的信息简洁、准确且具备实用性。
设计(Design):关注幻灯片的色彩搭配、视觉元素的使用和整体设计的专业性,确保视觉呈现和内容相辅相成。
连贯性(Coherence):评估幻灯片的逻辑结构和上下文信息的完整性,确保内容流畅且符合逻辑,观众易于理解。
实验
数据集
为了全面评估 PPTAgent 的性能,我们首先构建了一个包含 10,448 份多领域演示文稿的数据集 Zenodo10K,这也是目前已知最大的幻灯片数据集。在此基础上,我们在三个常用的大语言模型:GPT-4o、Qwen2.5-72B(Qwen2.5)和 Qwen2-VL-72B(Qwen2-VL)上进行了实验。
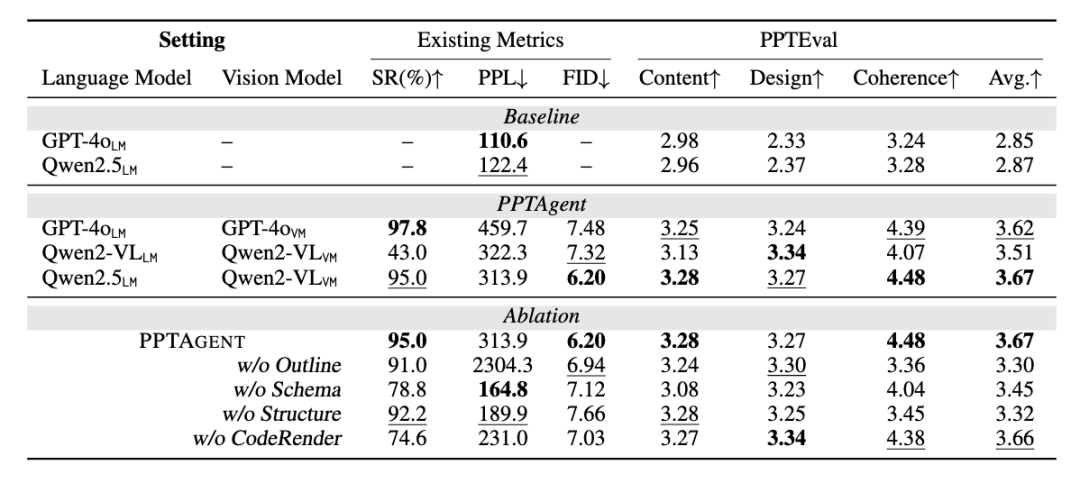
实验结果
超高的生成成功率:PPTAgent 展现出卓越的鲁棒性,使用 GPT-4o 或 Qwen2.5+Qwen2-VL 组合时,均实现了超过 95%的生成成功率。这一成绩远超此前模板编辑任务仅有 10%的成功率。
全方位的质量提升:与基线方法相比,PPTAgent 在幻灯片的各个维度都取得了显著进步:
设计维度得分提升 40%(3.24 vs 2.33)
连贯性维度提升 34%(4.39 vs 3.28)
内容质量提升 9%(3.25 vs 2.98)
开源模型的出色表现:值得一提的是,Qwen2.5 与 Qwen2-VL 的组合有效地克服了 Qwen2-VL 在语言处理方面的局限性,其整体表现也达到了与 GPT-4o 相当的水平,展现了开源大模型在专业领域的应用潜力。
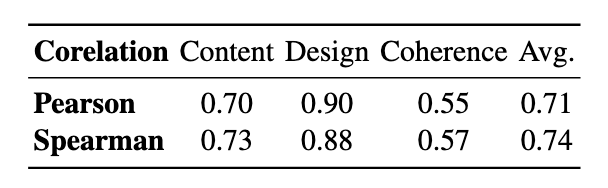
评估结果的可靠性验证:为确保评估结果的可靠性,我们将 PPTEval 的评估结果与人工评估进行了一致性分析。分析结果表明,PPTEval 在三个维度上的平均皮尔逊相关系数为 0.71,显示其能够有效地代替人类评估幻灯片的质量。
总结
通过这项研究,我们将演示文稿的自动生成重新定义为一个基于编辑的两阶段任务。PPTAgent 充分利用了大语言模型对代码的理解和生成能力,通过分析参考演示文稿的文本特征和布局模式,有效地组织和生成新的演示文稿。在多个领域的实验验证中,PPTAgent 都能够鲁棒地生成高质量幻灯片。同时,我们提出的 PPTEval 评估框架为演示文稿生成任务提供了可靠的评估手段,为该领域的未来发展奠定了重要基础。 这项技术有望开创一种全新的无监督演示文稿生成范式,为未来研究提供了新的思路。通过这项技术,我们期待能够帮助更多人高效地创作专业的演示文稿,让信息传递变得更加便捷。最后,通过开源的 PPTAgent、PPTEval 和大规模幻灯片数据集 Zenodo10K,我们希望能够推动整个领域的发展,激发更多创新性的研究成果。
-
ppt
+关注
关注
1文章
48浏览量
18282 -
大模型
+关注
关注
2文章
3864浏览量
5298
原文标题:PPTAgent: 大模型驱动的PPT自动生成,解放打工人
文章出处:【微信号:gh_e5b9d8c5c1d4,微信公众号:中科院软件所中文信息处理实验室】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
大模型赋能制造业:AISOP 如何实现 SOP 全流程智能化生成与落地
小鹏发布 X-World 世界模型:已全面应用第二代VLA
大晓机器人开源实时生成世界模型Kairos 3.0-4B

如何构建适合自动驾驶的世界模型?

大模型支撑后勤保障方案生成系统软件平台
五大大模型支撑后勤保障方案生成系统软件的应用与未来发展
世界模型是让自动驾驶汽车理解世界还是预测未来?

pdf转换ppt怎么转换
不只有AI协作编程(Vibe Coding):生成式系统级芯片(GenSoC)将如何把生成式设计推向硬件层面
VLA和世界模型,谁才是自动驾驶的最优解?
真正免费的AI生成PPT工具盘点:告别收费陷阱
如何让大模型生成你想要的测试用例?

小红书:通过商品标签API自动生成内容标签,优化社区推荐算法

生成式 AI 重塑自动驾驶仿真:4D 场景生成技术的突破与实践




评论