 中国电提出大模型推理加速新范式Falcon
中国电提出大模型推理加速新范式Falcon

近日,中国电信翼支付针对大模型推理加速的最新研究成果《Falcon: Faster and Parallel Inference of Large Language Models through Enhanced Semi-Autoregressive Drafting and Custom-Designed Decoding Tree》已被 AAAI 2025 接收。
论文中提出的 Falcon 方法是一种增强半自回归投机解码框架,旨在增强 draft model 的并行性和输出质量,以有效提升大模型的推理速度。Falcon 可以实现约 2.91-3.51 倍的加速比,在多种数据集上获得了很好的结果,并已应用到翼支付多个实际业务中。

论文标题: https://longbench2.github.io
论文链接:
https://arxiv.org/pdf/2412.12639
研究背景
大型语言模型 (LLMs) 在各种基准测试中展现了卓越的表现,然而由于自回归 (AR) 解码方式,LLMs 在推理过程中也面临着显著的计算开销和延迟瓶颈。
为此,研究学者提出 Speculative Decoding (投机采样) 方法。Speculative Decoding 会选择一个比原始模型 (Target Model) 轻量的 LLM 作为 Draft Model,在 Draft 阶段使用 Draft Model 连续生成若干个候选 Token。
在 Verify 阶段,将得到的候选 Token 序列放入到原始 LLM 做验证 & Next Token 生成,实现并行解码。通过将计算资源导向于验证预先生成的 token,Speculative Decoding 大大减少了访问 LLM 参数所需的内存操作,从而提升了整体推理效率。
现有的投机采样主要采用两种 Draft 策略:自回归 (AR) 和半自回归 (SAR) draft。AR draft 顺序生成 token,每个 token 依赖于前面的 token。这种顺序依赖性限制了 draft 模型的并行性,导致显著的时间开销。
相比之下,SAR draft 同时生成多个 token,增强了 draft 过程的并行化。然而,SAR draft 的一个重要局限是它无法完全捕捉相同 block 内 draft tokens 之间的相互依赖关系,可能导致生成的 token 接受率较低。
因此,在投机采样中,平衡低 draft 延迟与高推测准确性以加速 LLMs 的推理速度,是一个重大挑战。
为此,翼支付提出了 Falcon,一个增强的半自回归(SAR)投机解码框架,旨在增强 draft model 的并行性和输出质量,从而提升 LLMs 的推理效率。Falcon 集成了 Coupled Sequential Glancing Distillation(CSGD)方法,提高了 SAR draft model 的 token 接受率。
此外,Falcon还设计了一种专门的 decoding tree 来支持 SAR 采样,使得 draft model 可以在一次前向传播中生成多个 token,并且也能够支持多次前向传播。这种设计有效提升 LLMs 对 token 的接受率,进一步加快了推理速度。
研究方法
Falcon的架构如图 1 所示,可以看到,该半自回归解码框架主要由三个组件构成:Embedding Layer、LM-Head和半自回归解码 Head。
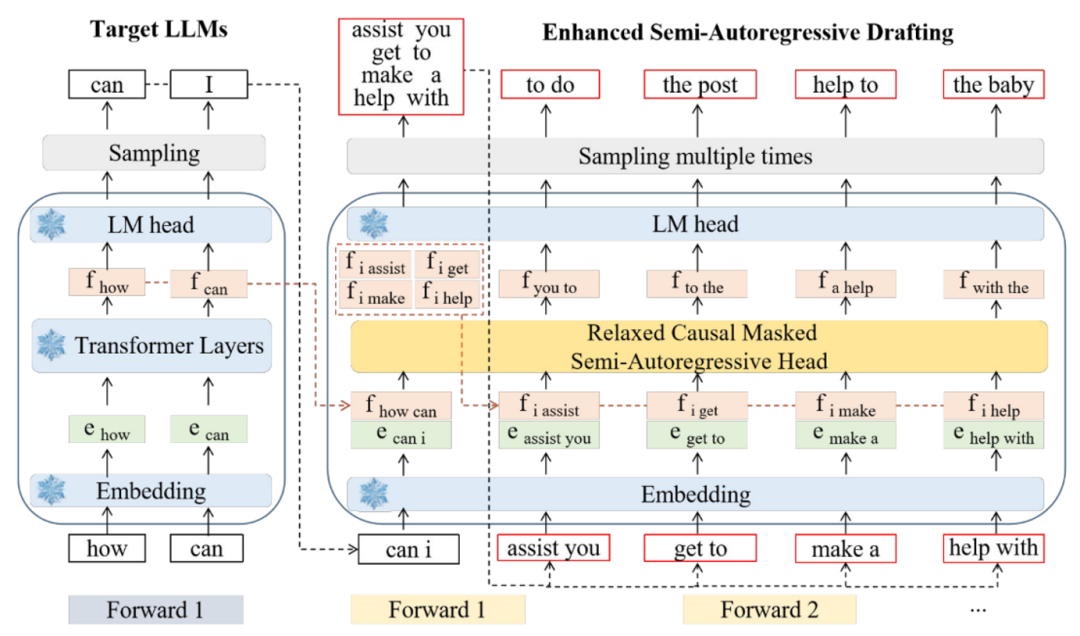
▲图1.Falcon框架图
具体来讲,Falcon 将一个时间步长之前的连续特征序列和当前 token 序列连接起来,以同时预测接下来的 k 个标记。例如,当 k = 2 时,Falcon 使用初始特征序列 (f1, f2) 和提前一个时间步长的标记序列 (t2, t3) 来预测特征序列 (f3, f4)。
随后,将预测得到的特征 (f3, f4) 与下一个标记序列 (t4, t5) 连接,形成新的输入序列。这个新输入序列用于预测后续的特征序列 (f5, f6) 和标记序列 (t6, t7),从而促进 draft 过程的继续。Draft model 多次 forward 之后生成的 token 被组织成树结构,输入到大模型中进行 verify,通过 verify 的 token 被大模型接收,并基于此基础开始下一个循环。
2.1 Coupled Sequential Glancing Distillation
当前推测解码方法的准确性相对较低,主要原因是 token 之间的上下文信息不足。CSGD 通过用真实 token 和 hidden states 替换一些初始预测来改善这一点,将正确信息重新注入解码过程中,从而提高后续预测的准确性和连贯性。模型结构及训练流程如下图:
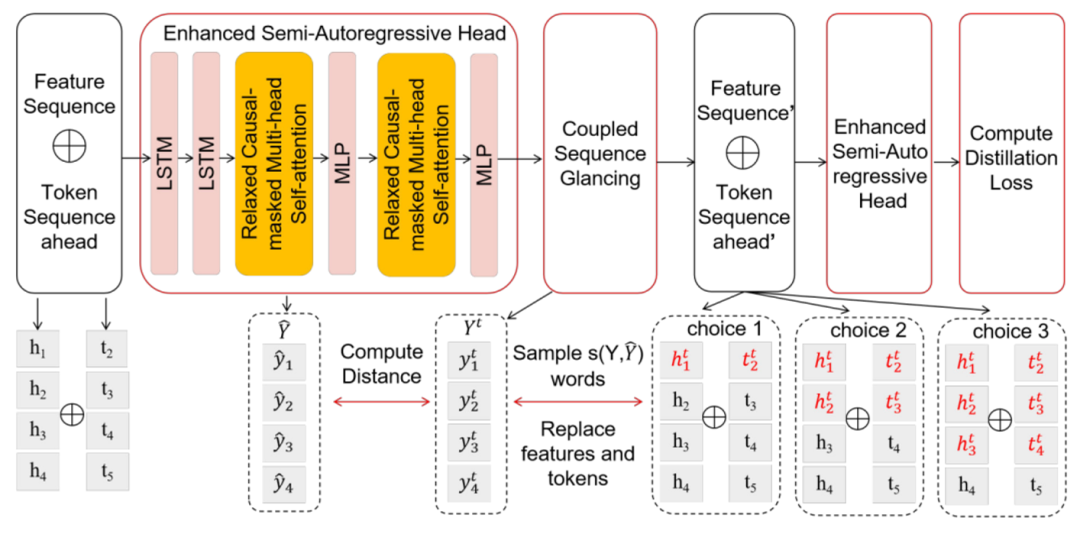
▲图2. CGSD方法示意图
在训练过程中,一个时间步长之前的连续特征序列和当前 token 序列连接起来,并输入到 draft model 中,形成一个融合序列,其维度为 (bs, seq_len, 2 * hidden_dim)。
draft model 由一个混合 Transformer 网络组成,该网络包括两层 LSTM、Relaxed Causal-Masked 多头注意力机制,以及 MLP 网络。其中 LSTM 网络将融合序列的维度减少到 (bs, seq_len, hidden_dim),并保留关于过去 token 的信息,从而提高模型的准确性。
Relaxed Causal-Masked 多头注意力机制能够在保持因果关系的同时,专注于输入序列的相关部分。MLP 层进一步处理这些信息,以做出最终预测。
当序列首次通过 draft model 后,会生成初始的 token 预测 。然后,我们计算 draft model 的预测与真实 token Y 之间的汉明距离,以此来衡量预测的准确性。接下来,我们将一定数量连续预测的 token 序列
。然后,我们计算 draft model 的预测与真实 token Y 之间的汉明距离,以此来衡量预测的准确性。接下来,我们将一定数量连续预测的 token 序列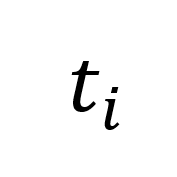 和特征序列
和特征序列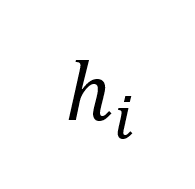 替换为来自 LLMs 的正确 token 序列
替换为来自 LLMs 的正确 token 序列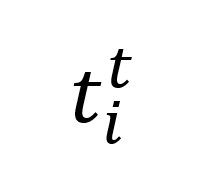 和特征序列
和特征序列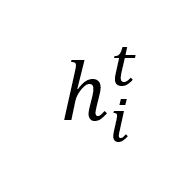 。
。
CSGD 与传统的 glancing 方法不同,后者仅随机替换 token。相反,CSGD 选择性地同时替换预测之前的连续 token 和特征序列,如图 2 中虚线框标注的 choice 1、choice 2、choice3 所示。
这种方法增强了对 token 间的关系的理解,并确保 draft model 能够有效利用提前时间步长的 token 序列,这在 SAR 解码中尤为重要。随后,修正后的 token 和特征序列被重新输入到 draft model 中以计算训练损失。
在训练过程中,我们采用了知识蒸馏,损失函数包括 draft model 的输出特征与真实特征之间的回归损失以及蒸馏损失,具体的损失函数如下:
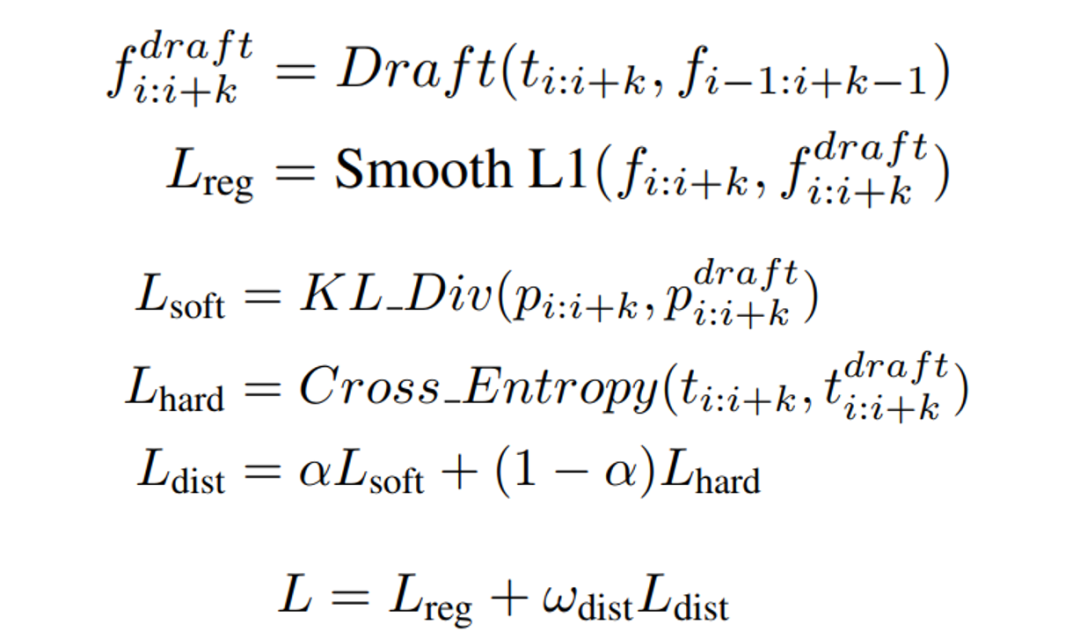
2.2 Custom-Designed Decoding Tree
当前基于树的推测解码方法通过在每个起草步骤生成多个 draft token 来提升推测效率。然而,这些方法仍然需要 draft model 按顺序生成 token,这限制了推测效率的进一步提高。
为了解决这一局限性,CDT (Custom-Designed Decoding Tree) 支持 draft model 在一次前向传递中生成多个 token (k 个),并且在每个 draft 步骤中支持多次前向传递。因此,与现有方法相比,CDT 生成的草稿标记数量是其 k 倍。
Draft model 多次 forward 之后,生成的 token 被组织成树结构,输入到大模型中进行 verify。LLM 使用基于树的并行解码机制来验证候选 token 序列的正确性,被接受的 token 及其相应的特征序列会在后续继续进行前向传递。在传统的自回归(AR)解码中,使用因果掩码,其结构为下三角矩阵。它确保了前面的 token 不能访问后面的信息。
相比之下,Falcon 采用了一种 causal 因果掩码 (如图 3 所示),允许模型访问同一 k*k 的 block 内的 token 以及相应的之前的连续 token。这一增强显著提高了 drafter 生成 token 的效率,使 LLM 能够同时验证更多的 token,从而加快了 LLM 的整体推理速度。
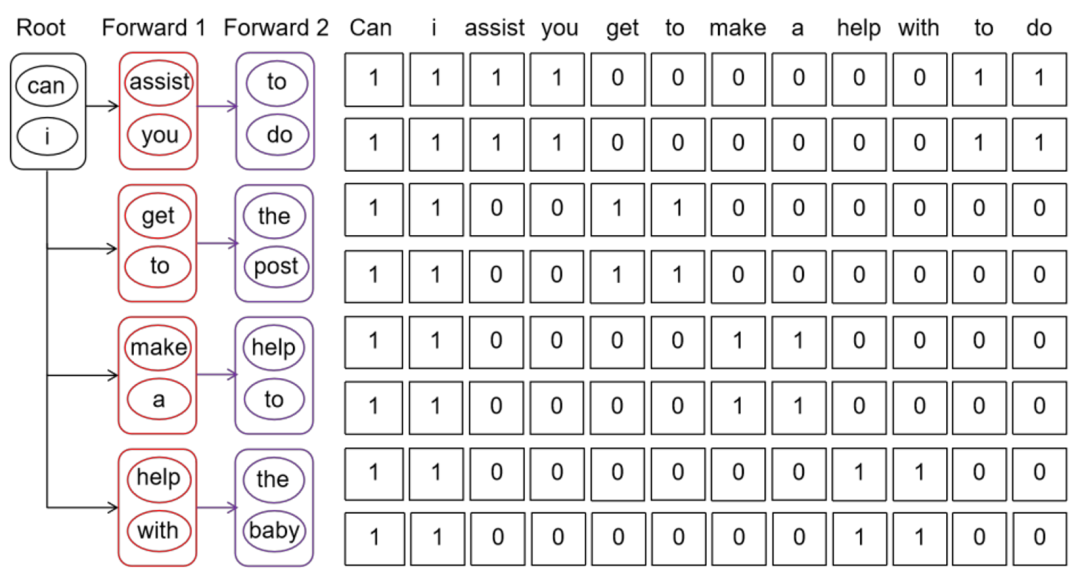
▲图3. Custom-Designed Decoding Tree方法示意图

实验结果
我们在多个数据集和多个模型上进行了广泛的实验,验证了本文方法的有效性。和现有的方法相比,Falcon 展现了优越的性能,具体如下图:
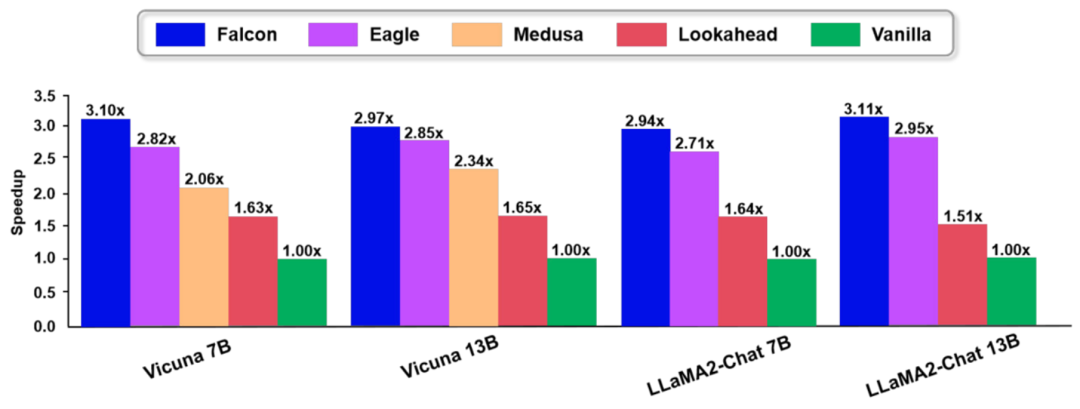
▲图4. Falcon实验结果图
业务潜力
Falcon 大模型可以实现约 2.91-3.51 倍的加速比,相当于同等条件下推理成本下降至约原先的 1/3,从而大幅降低了大模型推理计算相关成本。
当前,Falcon 技术已转化至翼支付大模型产品 InsightAI 平台,并已服务诸如翼支付数字人客服、借钱-翼小橙、人力-翼点通、财务-翼小财等多个业务应用。
总结
投机采样是大模型推理加速的一个核心方法。当前,主要的挑战是如何提升 draft model 的准确率、采样效率,并提升大模型的验证效率。文章提出了 Falcon 方法,一种基于增强半自回归投机解码框架。Falcon 通过 CSGD 这种训练方法以及半自回归的模型设计,显著提升了 draft model 的预测准确率以及采样效率。
此外,为了让大模型能验证更多的 token,本文精心设计了一个 decoding tree,有效提升了 draft model 的效率,从而提升了验证效率。Falcon 在多种数据集上可以实现约 2.91-3.51x 的加速比并应用到翼支付的众多业务中,获得了很好的效果。
-
大模型
+关注
关注
2文章
3902浏览量
5329
原文标题:AAAI 2025 | 加速比高达3.51倍!中国电提出大模型推理加速新范式Falcon
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
COMPUTEX 2026|美格智能发布 MEIGINE AI 推理引擎,五大突破重新定义端侧大模型部署范式

中国电科重磅亮相第九届数字中国建设峰会
Arm SME2技术加速腾讯翻译大模型推理

LLM推理模型是如何推理的?




评论