 理解LLM中的模型量化
理解LLM中的模型量化

作者:Shaoni Mukherjee
编译:ronghuaiyang,来源:AI公园
导读
在本文中,我们将探讨一种广泛采用的技术,用于减小大型语言模型(LLM)的大小和计算需求,以便将这些模型部署到边缘设备上。这项技术称为模型量化。它使得人工智能模型能够在资源受限的设备上高效部署。
在当今世界,人工智能和机器学习的应用已成为解决实际问题不可或缺的一部分。大型语言模型或视觉模型因其卓越的表现和实用性而备受关注。如果这些模型运行在云端或大型设备上,并不会造成太大问题。然而,它们的大小和计算需求在将这些模型部署到边缘设备或用于实时应用时构成了重大挑战。
边缘设备,如我们所说的智能手表或Fitbits,拥有有限的资源,而量化是一个将大型模型转换为可以轻松部署到小型设备上的过程。随着人工智能技术的进步,模型复杂度呈指数增长。将这些复杂的模型容纳在智能手机、物联网设备和边缘服务器等小型设备上是一项重大挑战。然而,量化是一种减少机器学习模型大小和计算需求的技术,同时不会显著牺牲其性能。量化已被证明在提高大型语言模型的内存和计算效率方面非常有用,从而使这些强大的模型更加实用和易于日常使用。
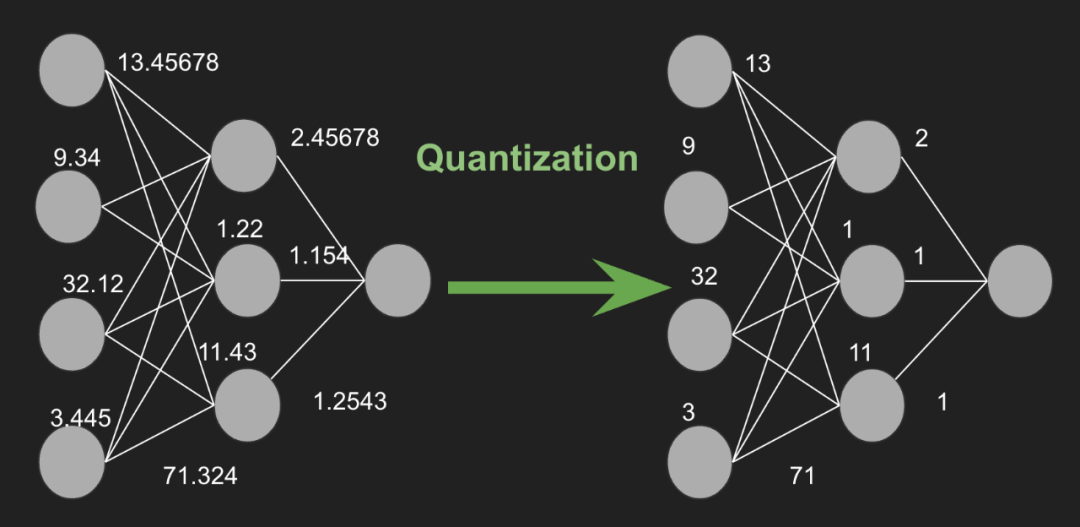
模型量化涉及将神经网络的参数(如权重和激活)从高精度(例如32位浮点数)表示转换为较低精度(例如8位整数)格式。这种精度的降低可以带来显著的好处,包括减少内存使用、加快推理时间和降低能耗。
什么是模型量化?模型量化的益处
模型量化是一种减少模型参数精度的技术,从而降低了存储每个参数所需的位数。例如,考虑一个32位精度的参数值7.892345678,它可以被近似为8位精度下的整数8。这一过程显著减小了模型的大小,使得模型能够在内存有限的设备上更快地执行。
除了减少内存使用和提高计算效率外,量化还可以降低能耗,这对于电池供电的设备尤为重要。通过降低模型参数的精度,量化还能加快推理速度,因为它减少了存储和访问这些参数所需的内存。
模型量化有多种类型,包括均匀量化和非均匀量化,以及训练后的量化和量化感知训练。每种方法都有其自身的模型大小、速度和准确性之间的权衡,这使得量化成为在广泛的硬件平台上部署高效AI模型的一个灵活且必不可少的工具。
不同的模型量化技术
模型量化涉及各种技术来减少模型参数的大小,同时保持性能。
以下是几种常见的技术:
1. 训练后的量化
训练后的量化(PTQ)是在模型完全训练之后应用的。PTQ可能会降低模型的准确性,因为在模型被压缩时,原始浮点值中的一些详细信息可能会丢失。
- 准确性损失:当PTQ压缩模型时,可能会丢失一些重要的细节,这会降低模型的准确性。
- 平衡:为了在使模型更小和保持高准确性之间找到合适的平衡,需要仔细调优和评估。这对于那些准确性至关重要的应用尤其重要。
简而言之,PTQ可以使模型变得更小,但也可能降低其准确性,因此需要谨慎校准以维持性能。
这是一种简单且广泛使用的方法,包括几种子方法:
- 静态量化:将模型的权重和激活转换为较低精度。使用校准数据来确定激活值的范围,这有助于适当地缩放它们。
- 动态量化:仅量化权重,而在推理期间激活保持较高精度。根据推理时观察到的范围动态量化激活。
2. 量化感知训练
量化感知训练(QAT)将量化集成到训练过程中。模型在前向传播中模拟量化,使模型能够学会适应降低的精度。这通常比训练后的量化产生更高的准确性,因为模型能够更好地补偿量化误差。QAT在训练过程中增加了额外的步骤来模拟模型被压缩后的表现。这意味着调整模型以准确处理这种模拟。这些额外步骤和调整使训练过程更具计算要求。它需要更多的时间和计算资源。训练后,模型需要经过彻底的测试和微调,以确保不会失去准确性。这为整个训练过程增加了更多的复杂性。
3. 均匀量化
在均匀量化中,值范围被划分为等间距的间隔。这是最简单的量化形式,通常应用于权重和激活。
4. 非均匀量化
非均匀量化为不同的区间分配不同的大小,通常使用诸如对数或k均值聚类等方法来确定区间。这种方法对于参数具有非均匀分布的情况更为有效,可能在关键范围内保留更多信息。
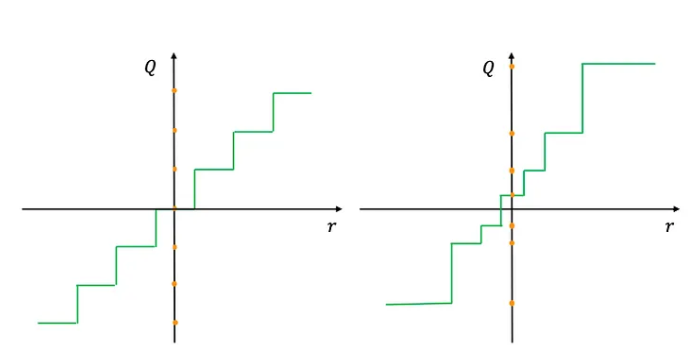
均匀量化和非均匀量化
5. 权重共享
权重共享涉及将相似的权重聚类,并在它们之间共享相同的量化值。这种技术减少了唯一权重的数量,从而实现了进一步的压缩。权重共享量化是一种通过限制大型神经网络中唯一权重的数量来节省能量的技术。
益处:
- 抗噪性:该方法更好地处理噪声。
- 可压缩性:可以在不牺牲准确性的情况下缩小网络的规模。
6. 混合量化
混合量化在同一模型中结合了不同的量化技术。例如,权重可以被量化到8位精度,而激活则保持较高的精度,或者不同的层可以根据它们对量化的敏感性使用不同级别的精度。这种技术通过将量化应用于模型的权重(模型的参数)和激活(中间输出)来减小神经网络的大小并加快速度。
- 量化两个部分:它同时压缩模型的权重和计算的数据激活。这意味着两者都使用较少的位数存储和处理,从而节省了内存并加快了计算速度。
- 内存和速度提升:通过减少模型需要处理的数据量,混合量化使得模型更小、更快。
- 复杂性:因为它同时影响权重和激活,所以实施起来可能比仅仅量化其中一个更复杂。它需要精心调优以确保模型在保持高效的同时仍然保持准确性。
7. 仅整数量化
在仅整数量化中,权重和激活都被转换为整数格式,并且所有计算都使用整数算术完成。这种技术对于优化整数操作的硬件加速器特别有用。
8. 按张量和按通道量化
按张量量化:在整个张量(例如,一层中的所有权重)上应用相同的量化尺度。
按通道量化:在一个张量的不同通道上使用不同的尺度。这种方法可以通过允许卷积神经网络中的量化更细粒度,从而提供更好的准确性。
9. 自适应量化
自适应量化方法根据输入数据分布动态调整量化参数。这些方法通过针对数据的具体特征定制量化,有可能达到更高的准确性。
每种技术都有其在模型大小、速度和准确性之间的权衡。选择适当的量化方法取决于部署环境的具体要求和约束。
模型量化面临的挑战与考虑因素
在AI中实施模型量化涉及到应对几个挑战和考虑因素。主要的问题之一是准确性权衡,因为减少模型数值数据的精度可能会降低其性能,特别是对于需要高精度的任务。为了管理这一点,采用的技术包括量化感知训练、混合方法(结合不同精度级别)以及量化参数的迭代优化,以保持准确性。此外,不同硬件和软件平台之间的兼容性可能存在问题,因为并非所有平台都支持量化。解决这个问题需要广泛的跨平台测试,使用标准化框架(如TensorFlow或PyTorch)以获得更广泛的兼容性,有时还需要为特定硬件开发定制解决方案以确保最佳性能。
实际应用案例
模型量化在各种实际应用中广泛使用,其中效率和性能至关重要。
以下是一些示例:
- 移动应用:量化模型用于移动应用中的任务,如图像识别、语音识别和增强现实。例如,量化神经网络可以在智能手机上高效运行,以识别照片中的目标或提供实时的语言翻译,即使在计算资源有限的情况下也是如此。
- 自动驾驶汽车:在自动驾驶汽车中,量化模型帮助实时处理传感器数据,如识别障碍物、读取交通标志和做出驾驶决策。量化模型的效率使得这些计算可以快速完成,并且功耗较低,这对于自动驾驶汽车的安全性和可靠性至关重要。
- 边缘设备:量化对于将AI模型部署到无人机、物联网设备和智能摄像头等边缘设备至关重要。这些设备通常具有有限的处理能力和内存,因此量化模型使它们能够高效地执行复杂的任务,如监控、异常检测和环境监测。
- 医疗保健:在医学影像和诊断中,量化模型用于分析医学扫描和检测异常,如肿瘤或骨折。这有助于在硬件计算能力有限的情况下提供更快、更准确的诊断,例如便携式医疗设备。
- 语音助手:数字语音助手如Siri、Alexa和Google Assistant使用量化模型处理语音命令、理解自然语言并提供响应。量化使这些模型能够在家庭设备上快速高效地运行,确保顺畅且响应迅速的用户体验。
- 推荐系统:在线平台如Netflix、Amazon和YouTube使用量化模型提供实时推荐。这些模型处理大量用户数据以建议电影、产品或视频,量化有助于管理计算负载,同时及时提供个性化推荐。
量化提高了AI模型的效率,使它们能够在资源受限的环境中部署,而不显著牺牲性能,从而改善了广泛应用中的用户体验。
总结思考
量化是人工智能和机器学习领域的一项关键技术,解决了将大型模型部署到边缘设备的挑战。量化显著减少了神经网络的内存占用和计算需求,使它们能够在资源受限的设备和实时应用中部署。正如本文讨论的,量化的一些好处包括减少内存使用、加快推理时间和降低功耗。技术如均匀量化和非均匀量化,以及创新方法如权重共享和混合量化。尽管量化具有优势,但也带来了挑战,特别是在保持模型准确性方面。然而,随着近期的研究和量化方法的发展,研究人员继续致力于解决这些问题,推动低精度计算的可能性边界。随着深度学习社区不断创新发展,量化将在部署强大且高效的AI模型中扮演关键角色,使先进的AI功能能够广泛应用于更多的应用场景和设备。总之,量化不仅仅是技术优化那么简单——它在AI进步中扮演着至关重要的角色。
-
人工智能
+关注
关注
1819文章
50290浏览量
266826 -
语言模型
+关注
关注
0文章
573浏览量
11341 -
LLM
+关注
关注
1文章
350浏览量
1394
发布评论请先 登录
后量化模型在 iMX93 NPU 上运行,但输出不正确怎么解决
Google正式发布LLM评测基准Android Bench

AWQ/GPTQ量化模型加载与显存优化实战
【CIE全国RISC-V创新应用大赛】+ 一种基于LLM的可通过图像语音控制的元件库管理工具
NVIDIA TensorRT LLM 1.0推理框架正式上线
广和通发布端侧情感对话大模型FiboEmo-LLM
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
3万字长文!深度解析大语言模型LLM原理

DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测
如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践

使用瑞萨MPU芯片RZ/V2H部署DeepSeek-R1模型

小白学大模型:从零实现 LLM语言模型



评论