 AMD推出新款纤薄尺寸电子交易加速卡
AMD推出新款纤薄尺寸电子交易加速卡

— AMD Alveo UL3422 加速卡为高频交易员在争夺最快交易执行的竞争中提供了优势,同时降低了进入门槛 —
AMD(超威,纳斯达克股票代码:AMD)今日宣布推出 AMD Alveo UL3422 加速卡 ,这是其创纪录的加速卡系列1的最新成员,专为超低时延电子交易应用而设计。AMD Alveo UL3422 为交易商、做市商和金融机构提供了一款针对机架空间和成本进行优化的纤薄型加速卡,旨在快速部署到各种服务器中。
Alveo UL3422 加速卡由 AMD Virtex UltraScale+ FPGA 提供支持,其采用新颖的收发器架构,具备硬化且经过优化的网络连接核,专为高速交易定制打造。它可实现超低时延交易执行,达到低于 3 纳秒的 FPGA 收发器时延和突破性的“tick-to-trade”性能,这是标准现成 FPGA 无法实现的1。
“在竞争日益激烈的高速交易领域,速度是终极优势。Alveo UL3422 卡提供了更低成本的切入点,同时仍可提供尖端的时延性能,使其能够为希望在超低时延交易领域保持竞争力的各种规模的公司所采用。”
—— Yousef Khalilollahi
AMD 公司副总裁兼自适应计算事业部总经理
新款纤薄尺寸规格,实现具性价比的部署
Alveo UL3422 加速卡采用纤薄的全高、半长( FHHL )尺寸规格封装,旨在适用于各种服务器和共置交换数据中心。
与前代产品相比,Alveo UL3422 加速卡减少了端口密度、板载内存和连接选项,但依然采用相同的 AMD Virtex UltraScale+ VU2P FPGA 来实现超低时延。
因此,Alveo UL3422 以现有 Alveo UL3524 加速卡一半的尺寸提供了同等性能,后者保持着当前 STAC-T0 基准测试 tick-to-trade 性能世界纪录1。Alveo UL3422 纤薄的全高半长尺寸规格令金融机构能够具性价比地优化计算密度和机架空间。
生态系统解决方案与快捷交易路径
Alveo UL3422 加速卡旨在通过利用可用的基础设施生态系统解决方案和参考设计来实现快速部署,从而为交易开发人员提供快速完成设计并投入市场所需的优势。
其由不断壮大的生态系统合作伙伴解决方案网络提供支持,这些解决方案提供 IP 和开发框架,以实现交易解决方案的快速实施。
Exegy
Exegy 是一家端到端前台交易解决方案提供商,通过其开发框架( nxFramework )支持 AMD Alveo UL3422 卡。nxFramework 是一种硬件和软件开发环境,旨在为金融行业高效构建和维护超低时延 FPGA 应用。
Hypertec
Hypertec 是一家面向金融服务行业的硬件、云和增值解决方案提供商,与 AMD 密切合作。该公司的 HF X410R-G6 服务器经过认证,可支持 Alveo UL3422 加速卡,使其成为首款针对此卡进行全面优化的 1U 服务器。
Xelera Technologies
Xelera Technologies 是一家面向高速网络技术和机器学习( ML )应用的软件提供商, 与 AMD 合作助力应对高频交易中机器学习算法的时延缺陷。借助 Xelera Silva,用户可以利用实时的、基于机器学习的交易决策,同时还能使用 XGBoost、LightGBM、CatBoost 以及其他高级模型。
Alveo UL3422采用 AMD Vivado 设计套件支持传统 FPGA 流程,并附带一套参考设计和性能基准,使 FPGA 设计人员能够快速探索关键指标并根据规范制定定制交易策略。
AMD 还为开发人员提供了开源且受到社区支持的 FINN 开发框架,令低时延 AI 模型能够部署到高性能交易系统中。FINN 项目采用 PyTorch 和神经网络量化技术,旨在缩小 AI 模型尺寸的同时保持准确性。FINN 编译器可生成能与 AMD FPGA 共同使用的量化神经网络( QNN )硬件 IP 块。
AMD Alveo UL3422 加速卡目前已上市,面向全球金融服务客户量产出货。
1. 2024 年 AMD 可操作时延世界纪录基于 AMD 和 Exegy 委托 Strategic Technology Analysis Center, LLC (STAC) 于 2024 年 4 月进行的第三方测试,使用 STAC-T0 基准测试搭载 AMD Virtex Ultrascale+ VU2P FPGA 的 AMD Alveo UL3524 加速卡,在搭载 AMD EPYC 7313 处理器的 Dell PowerEdge R7525 服务器上运行 Exegy nxFramework 和 Exegy nxTCP-UDP-10g-ULL IP 核。AMD 保持着此前的时延世界纪录(2020 年)。基于相同的硅片和产品特性,Alveo UL3524 加速卡的规定结果已外推至 AMD Alveo UL3422 卡。(ALV-20)。
-
FPGA
+关注
关注
1664文章
22504浏览量
639305 -
amd
+关注
关注
25文章
5708浏览量
140423 -
服务器
+关注
关注
14文章
10364浏览量
91761 -
加速卡
+关注
关注
1文章
75浏览量
11364
原文标题:AMD 扩展 Alveo 产品组合,推出全球极快的纤薄尺寸电子交易加速卡
文章出处:【微信号:赛灵思,微信公众号:Xilinx赛灵思官微】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
选择AMD Alveo V80加速卡的五大理由
AMD Alveo MA35D媒体加速卡的AMA SDK 1.4.0版本发布
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN标准嵌入式开发板

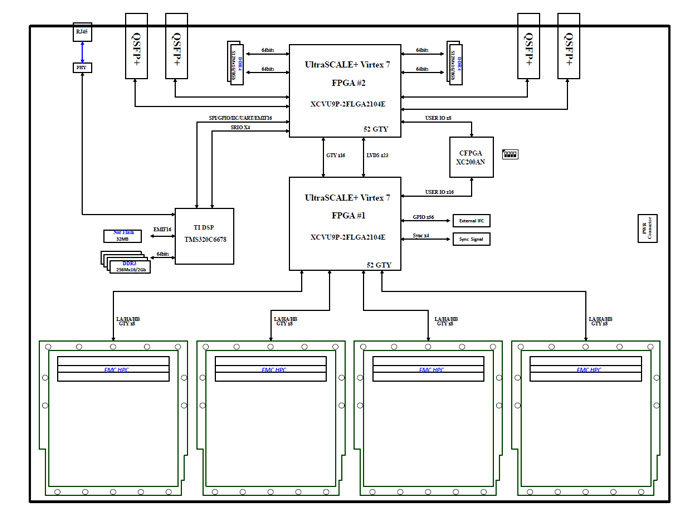
高速信号处理设计方案:413-基于双XCVU9P+C6678的100G光纤加速卡
昆仑芯R200 AI加速卡技术规格解析

迈向云端算力巅峰:昆仑芯K200 AI加速卡全面解读

深圳光量子工厂启示:PCI 加速卡为何偏向 25MHz 2016 有源晶振?

算力密度翻倍!江原D20加速卡发布,一卡双芯重构AI推理标杆

虚拟电厂加速卡不是噱头!万点规模VPP的性能分水岭
新品 | LLM-8850 Card, AX8850边缘设备AI加速卡

25W 功耗稳跑 104TOPS!H2 加速卡:让智能医疗设备的 AI 分析 “快又稳”
智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!


边缘AI运算革新 DeepX DX-M1 AI加速卡结合Rockchip RK3588多路物体检测解决方案




评论