 全新 NVIDIA NeMo Retriever微服务大幅提升LLM的准确性和吞吐量
全新 NVIDIA NeMo Retriever微服务大幅提升LLM的准确性和吞吐量

企业能够通过提供检索增强生成功能的生产就绪型 NVIDIA NIM 推理微服务,充分挖掘业务数据的价值。这些微服务现已集成到 Cohesity、DataStax、NetApp 和 Snowflake 平台中。
如果缺乏准确性,生成式 AI 应用不但无法产生价值,有时甚至还会产生负价值。而准确性的根源在于数据。
为帮助开发者高效获取最佳的专有数据,以便为他们的 AI 应用生成知识渊博的回答,NVIDIA 宣布推出四项全新的 NVIDIA NeMo Retriever NIM 推理微服务。
Llama 3.1 模型集也同期发布。当与适用于该模型集的 NVIDIA NIM 推理微服务相结合时,NeMo Retriever NIM 推理微服务不仅能够使企业扩展到代理式 AI 工作流(在此工作流中,AI 应用可以在最少的干预或监督下准确运行),还能够提供极为精准的检索增强生成(RAG)。
通过 NeMo Retriever,企业可以将自定义模型与各种业务数据无缝连接,并使用 RAG 为 AI 应用作出高度准确的回答。这套生产就绪型微服务实际上为创建高度准确的 AI 应用提供了非常精准的信息检索功能。
例如当开发者创建 AI 智能体和客服聊天机器人、分析安全漏洞或从复杂的供应链信息中提取洞察时,NeMo Retriever 能够大幅提高模型的准确性和吞吐量。
NIM 推理微服务实现了高性能、易于使用的企业级推理。开发者能够使用 NeMo Retriever NIM 微服务并充分利用自己的数据,来获得这一切。
已正式发布的全新 NeMo Retriever 向量化和重排序 NIM 微服务如下:
NV-EmbedQA-E5-v5:一个常用社区基础向量化模型,针对文本问答检索进行了优化
NV-EmbedQA-Mistral7B-v2:一个常用多语言社区基础模型,针对文本向量化功能进行了微调,以实现高度准确的问答
Snowflake-Arctic-Embed-L:一个经过优化的社区模型
NV-RerankQA-Mistral4B-v3:一个常用社区基础模型,针对文本重排功能进行了微调,以实现高度准确的问答
这些模型加入到 NIM 微服务集中,可通过 NVIDIA API 目录轻松访问。
向量化和重排序模型
NeMo Retriever NIM 微服务包含两种模型——向量化和重排序模型,以及确保透明度和可靠性的开放式和商业化服务。
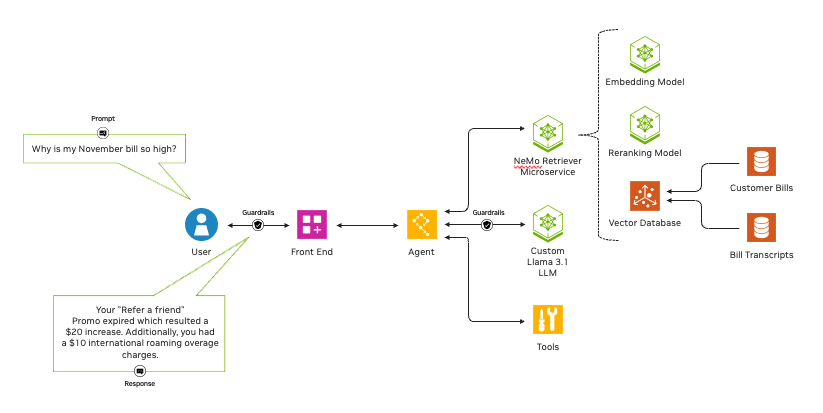
RAG 管线示例:使用了适用于 Llama 3.1 的 NVIDIA NIM 微服务以及适用于客服 AI 聊天机器人应用的 NeMo Retriever 向量化和重排序 NIM 微服务
向量化模型在将文本、图像、图表和视频等各种数据转化为数字向量,并存储在向量数据库中的同时,获取其含义和细微差别。与传统的大语言模型(LLM)相比,向量化模型速度更快且计算成本更低。
重排序模型可获取数据和查询,随后根据数据与查询的相关性对数据进行评分。与向量化模型相比,这类模型虽然计算复杂且速度较慢,但能大幅提高准确性。
NeMo Retriever 提供了两全其美的解决方案。开发者可以充分利用 NeMo Retriever 建立一个能够给企业提供最有用、最准确结果的流程。该流程先通过向量化 NIM 检索巨大的数据网,然后使用重排序 NIM 筛选结果的相关性。
通过 NeMo Retriever,开发者能够使用先进的开源商业模型,构建极为精准的文本问答检索管线。与其他模型相比,NeMo Retriever NIM 微服务在企业问答中提供的不准确答案减少了 30%。
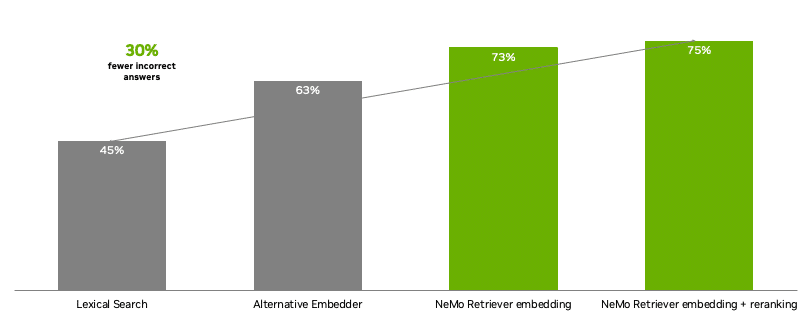
NeMo Retriever 向量化 NIM 和向量化 + 重排序 NIM 微服务性能与词法搜索和替代向量的对比。
热门用例
无论是 RAG 和 AI 智能体解决方案,还是数据驱动的分析,NeMo Retriever 都能够为各种 AI 应用提供助力。
这套微服务可用于创建能够作出准确、情境感知响应的智能聊天机器人、帮助分析海量数据以识别安全漏洞、从复杂的供应链信息中提取洞察等。它们还能胜任许多其他任务,比如帮助 AI 赋能的零售业购物顾问提供自然、个性化的购物体验。
针对这些用例的 NVIDIA AI 工作流为开发生成式 AI 赋能的技术提供了一个简单且能够获得支持的起点。
数十家 NVIDIA 数据平台合作伙伴正在使用 NeMo Retriever NIM 微服务提高其 AI 模型的准确性和吞吐量。
DataStax 在其 Astra DB 和超融合平台中集成了 NeMo Retriever 向量化 NIM 微服务,使企业能够为客户提供准确的、经过生成式 AI 增强的 RAG 功能,并加快产品上市时间。
Cohesity 将在其 AI 产品 Cohesity Gaia 中集成 NVIDIA NeMo Retriever 微服务,以便帮助客户通过 RAG 将自己的数据用于驱动富有洞察力和变革性的生成式 AI 应用。
Kinetica 将使用 NVIDIA NeMo Retriever 开发 LLM 智能体。这些智能体能够通过自然语言与复杂的网络进行交互,从而对中断或漏洞作出更快的响应,将洞察转化为即时行动。
NetApp 正在与 NVIDIA 合作,将 NeMo Retriever 微服务连接到其智能数据基础设施上的 EB 级数据。所有 NetApp ONTAP 客户都将能够“与他们的数据无缝对话”,在不影响数据安全或隐私的情况下获得专属的业务洞察。
NVIDIA 全球系统集成商合作伙伴包括埃森哲、德勤、Infosys、LTTS、Tata Consultancy Services、Tech Mahindra 和 Wipro 等,以及服务交付合作伙伴 Data Monsters、EXLService (爱尔兰) Limited、Latentview、Quantiphi、Slalom、SoftServe 和 Tredence 正在开发各种服务,帮助企业将 NeMo Retriever NIM 微服务添加到他们的 AI 管线中。
与其他 NIM 微服务一起使用
NeMo Retriever NIM 微服务可与 NVIDIA Riva NIM 微服务一起使用。后者为各行各业的语音 AI 应用提供强大助力,增强了客户服务并且让数字人变得栩栩如生。
即将以 Riva NIM 微服务形式推出的新模型包括:适用于文本转语音应用的 FastPitch 和 HiFi-GAN;适用于多语言神经机器翻译的 Megatron;以及适用于自动语音识别的破纪录 NVIDIA Parakeet 系列模型。
NVIDIA NIM 微服务既可以组合使用,也可以单独使用,为开发者提供构建 AI 应用的模块化方法。这些微服务还可以在云端、本地或混合环境中与社区模型、NVIDIA 模型或用户自定义模型集成,为开发者带来了更大的灵活性。
NVIDIA NIM 微服务现在可在 ai.nvidia.com 上获取。企业可通过 NVIDIA AI Enterprise 软件平台使用 NIM 将 AI 应用部署到生产中。
NIM 微服务可在客户首选的加速基础设施上运行,包括亚马逊云科技、谷歌云、Microsoft Azure 和 Oracle Cloud Infrastructure 的云实例,以及思科、戴尔科技、慧与、联想和 Supermicro 等全球服务器制造合作伙伴的 NVIDIA 认证系统。
NVIDIA 开发者计划会员很快将能够免费使用 NIM,以在他们首选的基础设施上进行研究、开发和测试。
-
机器人
+关注
关注
213文章
31514浏览量
223914 -
NVIDIA
+关注
关注
14文章
5696浏览量
110150 -
AI
+关注
关注
91文章
41432浏览量
302779 -
LLM
+关注
关注
1文章
350浏览量
1398
原文标题:上吧,AI!全新 NVIDIA NeMo Retriever 微服务大幅提升 LLM 的准确性和吞吐量
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
欧洲快递行业巨头部署全新Matrix 830/930系统以应对高吞吐量业务
用“分区”来面对超大数据集和超大吞吐量
确保X光设备检测的有效性和准确性的关键技巧
NVIDIA推出全新BlueField-4 DPU
电能质量在线监测装置定位谐波源的准确性有多高?
使用罗德与施瓦茨CMX500的吞吐量应用层测试方案

TensorRT-LLM中的分离式服务

Votee AI借助NVIDIA技术加速方言小语种LLM开发
如何在NVIDIA Blackwell GPU上优化DeepSeek R1吞吐量
测缝计测量数据的准确性和校准方法解析

使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践




评论