 采用OpenACC框架的FVCOM模型实现超百倍计算加速
采用OpenACC框架的FVCOM模型实现超百倍计算加速

华东师范大学河口海岸学国家重点实验室葛建忠教授团队作为国际先进海洋数值模型 FVCOM 开发团队核心成员,随着 FVCOM 的发展和应用越来越广泛,以及行业不断提升的对预报精度与时效性要求,算力需求剧增,借助 NVIDIA GPU 加速计算技术,不仅实现了传统动力学数值模型的百倍计算加速,造福了海洋预报、水利工程等具体应用领域,也为海洋模型系统向人工智能模型转型以及人工智能海洋学的发展提供了关键的基础数据生成工具和方法,是人工智能技术进一步应用于海洋领域的重要基石。
海洋预报数值模型计算负载剧增
随着自然灾害越来越频发,为灾害过程防御提供技术支撑的数值预报系统对“精确、及时、高效、稳定”有着越来越高的需求,特别是随着集合预报模型的研发和应用带来了数值模型计算量的急剧上升(比如在集合预报中计算量与集合样本数量成正比,是单个模型计算的数十倍),超大的计算负载给预报业务单位和超算中心带来了极大的压力,而预报系统又具有“高时效”的特点,要尽可能地控制计算量,从而提高预报时效。与此同时,河口生态、生物地球化学过程模型具有变量多、过程复杂的特点,其计算量一般是动力模型的 10 倍以上。潮滩湿地植被斑块及潮沟系统、近海工程、海上风电场等模型一般都要求小于 5 米的空间分辨率,这也造成了模型计算量显著增大。
面对计算量剧增的挑战,实验室目前的计算架构主要采取基于 CPU 的多核计算节点扩展方案为主,以增加核数、节点来应对,这对高性能集群的建设和运维提出了更高的要求,也进一步提高了数值模型应用和拓展的门槛。
采用 OpenACC 框架加速 FVCOM 模型
为了解决数值模型计算负载剧增这一难点问题,华东师范大学河口海岸学国家重点实验室葛建忠教授团队调研分析了目前的主要 GPU 加速计算技术,包括 CUDA、OpenACC、stdpar、Kokkos、OpenCL 等,并与 NVIDIA 技术团队进行了详细讨论和分析,结合 FVCOM 模型代码的复杂度,选择了 OpenACC 为主的技术路线,并于 2023 年初开始相关代码迁移工作,并在 2023 年 8 月参加了 NVIDIA 举办的武汉大学 GPU Hackthon 活动,得到了专业的技术支持,解决了多个关键技术难点,于 2023 年底完成了主要代码的迁移、测试和验证工作。
为降低大规模数值模型的使用门槛,模型代码的迁移和测试都在一台搭载 NVIDIA GeForce RTX 40 系列 GPU 的台式电脑上完成,并在 2023 年初完成部署的超算中心计算节点上采用 CPU 进行对比,该计算节点为 Intel Xeon Gold CPU,迁移后的模型支持正压、斜压、泥沙、植被等关键模型,并支持全部外部驱动包括风场、热通量、降雨、离线流场、嵌套文件的高效传输,也可进行单精度、双精度计算的自由切换。迁移后模型相关的输入、输出和控制文件未发生任何变化,可以适用于原有 FVCOM 的相关应用。
加速对比测试选择 10 万、35 万、100 万、150 万、200 万水平方向网格等模型,所有模型都在 RTX GPU 上进行单精度模式计算,并采用计算节点进行单线程运行相同模型。相对于 CPU 单线程计算速度,采用 OpenACC 技术的 FVCOM 模型分别达到了 88、181、194、195、198 倍的加速比(图 1)。在此基础上采用编译器控制选项可以在同一套代码上灵活切换 CPU 或者 GPU 模式,且经检验,CPU 和 GPU 加速模型都得到一致的模拟结果。在单精度 FVCOM 的前提下,一个 RTX GPU 的计算能力在不考虑网络交换的情况下相当于超算集群的 3.5 个 64 核计算节点,在考虑节点间网络交换延迟时可相当于 5 个节点。
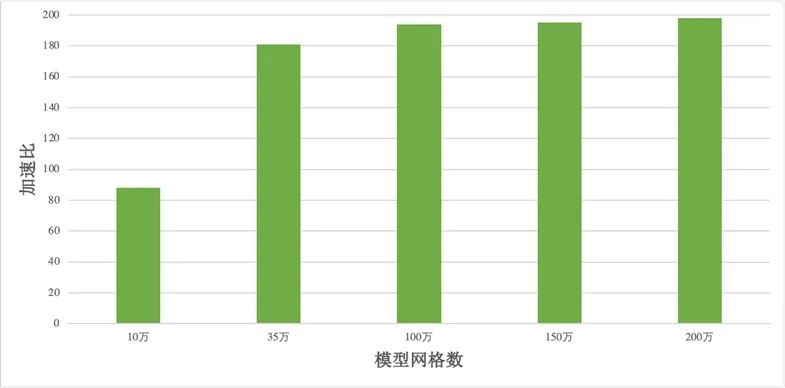
图 1:单精度 GPU-FVCOM 加速实验结果
该模型可在 NVIDIA 加速计算框架体系内高效扩展,将 10 万、35 万、100 万、150 万网格模型再调整为双精度模式,采用单个 NVIDIA Ampere Tensor Core GPU 进行加速计算,分别达到了 48、77、139 和 135 的加速比,显示了对双精度模式也有良好的加速效果。在多个 GPU 计算节点的情况下,也可采用 MPI+OpenACC 方式支持多 GPU 并行计算。
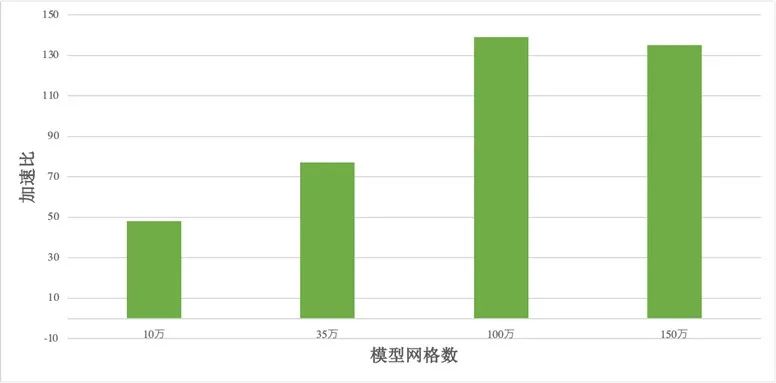
图 2:双精度 GPU-FVCOM 加速实验结果
超百倍计算加速造福海洋预报
目前,FVCOM 模型在海洋预报、海洋工程与作业等领域应用极为广泛。以国内外近海海洋预报业务为例,FVCOM 已经成为我国沿海省、市、区各级海洋预警预报部门开展业务化预报工作的主要模型选择。海洋预报业务的发展趋势是不断提升对预报精度与时效的要求,二者都意味着巨大的算力需求,而将 FVCOM 模型实现 GPU 加速是解决实际应用中剧增的算力需求的有效途径。
采用 GPU 加速的预报模型可以将预报时效从小时级别降低到分钟级,甚至秒级。显著的效率提升也释放了模型进一步采用更高网格分辨率从而提高模拟精度的潜力。
另一方面,业务部门对于台风风暴潮等事件的集合预报愈发重视。集合预报是指针对不同的初始条件或驱动要素(例如台风演化过程)的扰动,计算出多个可能的未来情形,以考虑预报中的不确定性。这就对模型的计算速度提出了更大的挑战,而 GPU 加速能够很好地加以应对。
在水利工程领域,FVCOM 模型也已广泛用于工程可行性分析与评估。尤其是在工程前期研究阶段,需要借助数值模型对多种施工建设方案的效果进行模拟评估,多工况计算对传统模型也造成了极大挑战。实现 GPU 加速从而更快地给出论证结果,则可以切实地提高工程推进效率,节省工期。
此外,本项目所实现的案例具有较高的启示意义与推广价值,例如 OpenACC 技术方案还可以应用在其他近海和海洋数值模型系统。在采用结构化网格的模型中(如ROMS、ECOM、POM 等),该方案甚至可能实现更好的加速效果。本次实践也证明,GPU 加速能够极大地降低河口、海岸、海洋研究和工程应用领域进行数值模拟所需的硬件门槛,为学科发展、业务应用都提供了巨大帮助。
目前,海洋数值模型正经历其发展历程中的最大转型,即从基于动力学机制与方程的传统海洋数值模型转型为基于机器学习(深度学习)等方法的人工智能模型。而人工智能模型对数据的需求与依赖巨大,其训练通常离不开海量的、可靠的数据。然而,海洋系统中的实测数据,相较于海洋巨大的空间尺度以及所关切问题的具体时间范围,总是稀缺的。数值模型则可以为人工智能模型提供大量的基础训练数据,也是当下保障数据范围与质量最有效的途径之一。例如,葛建忠教授团队已经用实现 GPU 加速的 FVCOM 模型系统计算了中国近海 1960 – 2023 年海洋流场和生态动力过程,用该三维高分辨率模型生成了超 20TB 容量的同化数据产品。随后,通过利用 NVIDIA 开发的基于 AFNO 架构的 FourCastNet 模型对该数据集开展训练,他们实现了对河口及近海动力学过程的快速推演与分析。此外,他们还采用实现 GPU 加速的 FVCOM 模型高效快速地计算了超过 1000 个台风风暴潮过程样本,用于训练一个基于深度学习方法的风暴潮预报模型。这两个数据集的构建,若采用传统的、未经加速的数值模型,所耗费的时间成本将高出百倍以上。
综上,采用 OpenACC 框架的 FVCOM 为传统动力学数值模型提供了超过百倍的计算加速。这样的效率提升不仅直接造福了海洋预报、水利工程等具体应用领域,也为海洋模型系统向人工智能模型转型以及人工智能海洋学的发展提供了关键的基础数据生成工具和方法,是人工智能技术进一步应用于海洋领域的重要基石。
团队介绍
华东师范大学河口海岸学国家重点实验室葛建忠教授团队长期致力于海洋数值模型的研发与应用,是国际先进海洋数值模型 FVCOM 开发团队核心成员,主持开发了其中导堤-丁坝、细颗粒粘性泥沙、浮泥、河流闸门、植被、藻类漂移生长等 FVCOM 核心模块,并参与开发了波流共同作用、FVCOM-ERSEM 生物地球化学等模块。此外,该团队也建立了中国海-长江口多空间尺度物理-生物地球化学耦合数值模拟系统。
葛建忠教授团队基于 FVCOM 框架,主要聚焦高浓度泥沙、物理-生物地球化学耦合过程、台风风暴潮等方面的研究,并针对长江河口、黄海、浙闽沿海、珠江口和北部湾等国内典型河口海岸区域进行了应用研究。在德国的易北河口、汉堡港、越南的岘港等区域,该团队也开展了相关合作和应用研究,其相关成果也为国家海洋与水利等部门的黄海浒苔防治、风暴潮预报、咸潮入侵防御等方面提供了多项技术支撑。
审核编辑:刘清
-
NVIDIA
+关注
关注
14文章
5687浏览量
110114 -
人工智能
+关注
关注
1820文章
50324浏览量
266927 -
机器学习
+关注
关注
67文章
8564浏览量
137221 -
深度学习
+关注
关注
73文章
5607浏览量
124625 -
GPU芯片
+关注
关注
1文章
307浏览量
6554
原文标题:造福海洋预报!采用 OpenACC 框架的 FVCOM 模型实现超百倍计算加速
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
国产光芯片大突破,算力超百倍,绕开EUV
FBX/glTF 模型渲染与动画技术解析 | 图扑 HT 框架

力争百万 Tokens 推理成本降低百倍:云天励飞发布未来三年大算力芯片战略,首曝 DeepVerse 路线图

中科曙光scaleX640超节点亮相2025世界计算大会
昆仑芯超节点亮相,单卡性能提升95%




评论