 TensorRT LLM加速Gemma!NVIDIA与谷歌牵手,RTX助推AI聊天
TensorRT LLM加速Gemma!NVIDIA与谷歌牵手,RTX助推AI聊天

NVIDIA今天在其官方博客中表示,今天与谷歌合作,在所有NVIDIA AI平台上为Gemma推出了优化。Gemma是谷歌最先进的新轻量级2B(20亿)和7B(70亿)参数开放语言模型,可以在任何地方运行,降低了成本,加快了特定领域用例的创新工作。
这两家公司的团队密切合作,主要是使用NVIDIA TensorRT LLM加速谷歌Gemma开源模型的性能。开源模型Gemma采用与Gemini模型相同的底层技术构建,而NVIDIA TensorRT LLM是一个开源库,用于在数据中心的NVIDIA GPU、云服务器以及带有NVIDIA RTX GPU的PC上运行时,可以极大优化大型语言模型推理。这也这使得开发人员能够完全利用全球超过1亿台数量的RTX GPU AI PC完成自己的工作。
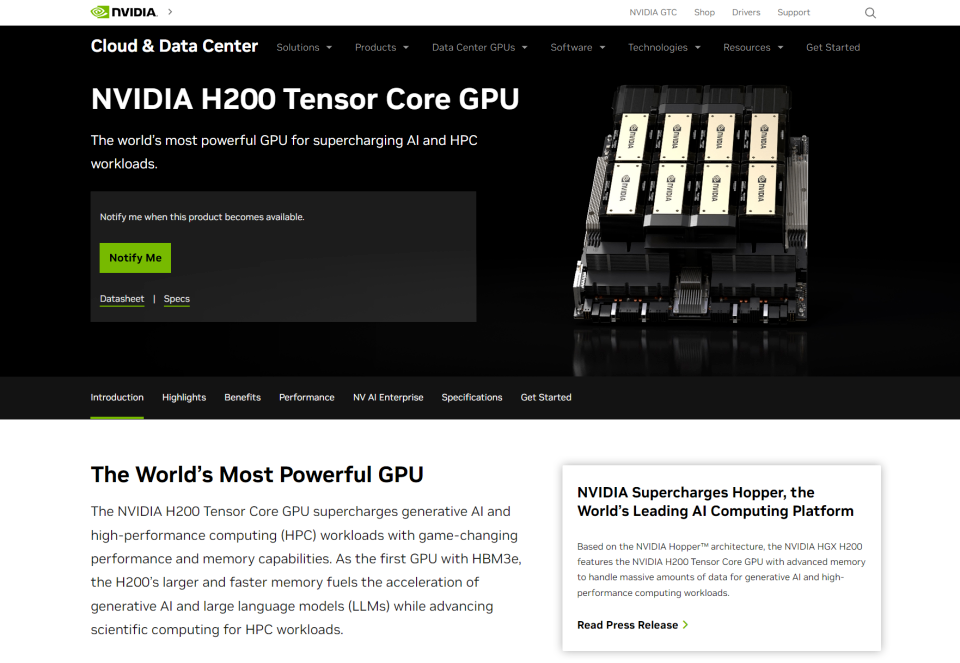
同时,开发人员还可以在云计算服务器中的NVIDIA GPU上运行Gemma,包括在谷歌云基于H100 Tensor Core GPU,以及很快谷歌将于今年部署的NVIDIA H200 TensorCore GPU——该GPU具有141GB的HBM3e内存,内存带宽可以达到4.8TB/s。
另外,企业开发人员还可以利用NVIDIA丰富的工具生态系统,包括具有NeMo框架的NVIDIA AI Enterprise和TensorRT LLM,对Gemma进行微调,并在其生产应用程序中部署优化模型。
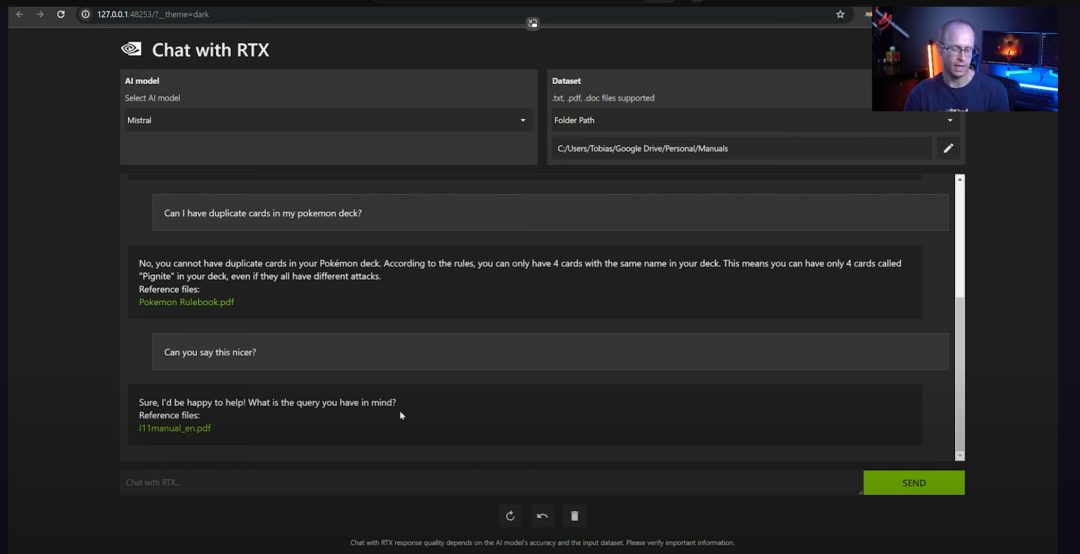
NVIDIA表示,先期上线支持Gemma的是Chat with RTX,这是一款NVIDIA技术演示应用,使用检索增强生成和TensorRT LLM扩展,在基于RTX GPU的本地Windows PC上为用户提供生成式AI应用的功能。通过RTX聊天,用户可以轻松地将PC上的本地文件连接到大型语言模型,从而使用自己的数据对聊天机器人进行个性化设置。
由于该模型在本地运行,因此可以快速提供结果,并且用户数据保留在设备上。与基于云的LLM服务不同,使用Chat with RTX聊天可以让用户在本地PC上处理敏感数据,而无需与第三方共享或连接互联网。
审核编辑:刘清
-
NVIDIA
+关注
关注
14文章
5689浏览量
110118 -
GPU芯片
+关注
关注
1文章
307浏览量
6554 -
LLM
+关注
关注
1文章
350浏览量
1394 -
生成式AI
+关注
关注
0文章
538浏览量
1133
原文标题:TensorRT LLM加速Gemma!NVIDIA与谷歌牵手,RTX助推AI聊天
文章出处:【微信号:Microcomputer,微信公众号:Microcomputer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
谷歌正式发布Gemma Scope 2模型
NVIDIA RTX PRO 5000 Blackwell GPU的深度评测

NVIDIA RTX PRO 2000 Blackwell GPU性能测试

NVIDIA TensorRT LLM 1.0推理框架正式上线
TensorRT-LLM的大规模专家并行架构设计

谷歌推出AI模型Gemma 3 270M
DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

TensorRT-LLM中的分离式服务

Votee AI借助NVIDIA技术加速方言小语种LLM开发
NVIDIA RTX AI加速FLUX.1 Kontext现已开放下载
NVIDIA RTX AI PC为AnythingLLM加速本地AI工作流
如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
谷歌Gemma 3n预览版全新发布
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践

LM Studio使用NVIDIA技术加速LLM性能



评论