 佰维存储研发突破,为AI高性能计算赋能
佰维存储研发突破,为AI高性能计算赋能

近日,佰维存储在接受调研时透露,公司近期成功研发并发布了支持CXL2.0规范的CXLDRAM内存扩展模块。这款产品具有支持内存容量和带宽扩展、内存池化共享、高带宽、低延迟、高可靠性等优势,特别适合于AI高性能计算的应用。
佰维存储一直致力于技术研发创新,这次的新产品再次证明了公司在技术研发上的实力。公司表示,未来将继续加大对技术研发的投入,不断推出创新产品,以满足市场不断变化的需求。
此外,佰维存储在IC芯片方面也取得了重大突破。公司透露,其第一颗主控芯片研发进展顺利,已经回片点亮,正在进行量产准备。这一进展对于佰维存储来说意义重大,标志着公司在IC芯片领域取得了重要突破,进一步提升了公司的核心竞争力。
随着AI技术的快速发展,高性能计算的需求也在不断增长。佰维存储的CXLDRAM内存扩展模块和IC芯片研发进展,将有助于满足这一市场需求,推动AI技术的进一步发展。
未来,佰维存储将继续发挥自身技术优势,积极应对市场挑战,不断推出创新产品。同时,公司也将积极寻求与各方的合作机会,共同推动半导体产业的繁荣发展。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
内存
+关注
关注
9文章
3234浏览量
76508 -
佰维存储
+关注
关注
1文章
157浏览量
9089 -
AI+
+关注
关注
0文章
27浏览量
3331
发布评论请先 登录
相关推荐
热点推荐
佰维存储全面赋能AI存储,强势布局AI眼镜、数据中心存储
的CFM|MemoryS2026闪存峰会期间,佰维存储也首次解读公司的AI存储发展战略以及新品规划。 在
沐曦曦索GPU产品赋能AI4S重塑材料研发新范式
2026年1月29日,“AI4Science 前沿:材料研发计算新范式——国产算力×深度学习框架技术沙龙·上海站”在张江百度飞桨人工智能产业赋能
3700MB/s 超高速读写!佰维 Mini SSD 缔造移动存储新标杆,生态布局提速
1月26日,由佰维存储携手英特尔(Intel)举办的“源起深圳,共创商机——Mini SSD生态应用研讨会”在深圳英特尔大湾区科技创新中心隆重召开。针对端侧AI、轻薄本、游戏掌机等多个

如何突破AI存储墙?深度解析ONFI 6.0高速接口与Chiplet解耦架构
1. 行业核心痛点:AI“存储墙”危机在大模型训练与推理场景中,算力演进速度远超存储带宽,计算与存储之间的
发表于 01-29 17:32
慧荣科技携手佰维存储重构AI终端存储新形态
2026年1月26日,由佰维存储(Biwin)携手英特尔(Intel)举办的“源起深圳,共创商机——Mini SSD生态应用研讨会”在深圳英特尔大湾区科技创新中心隆重召开。本次研讨会聚焦AI
强强联合!京东x佰维存储战略携手,共拓消费存储新蓝海
,致力于为消费者提供可靠、高速的数据存储解决方案。 此次合作标志着佰维在深化零售渠道布局、贴近终端用户方面迈出关键一步。佰
佰维存储Mini SSD荣登2025年度最佳发明榜单
近日,《时代》周刊(《TIME》)发布了2025年“Best Inventions of the Year”(年度最佳发明)榜单,佰维Mini SSD凭借技术突破与前瞻性设计成功入选,成为全球唯一上榜的
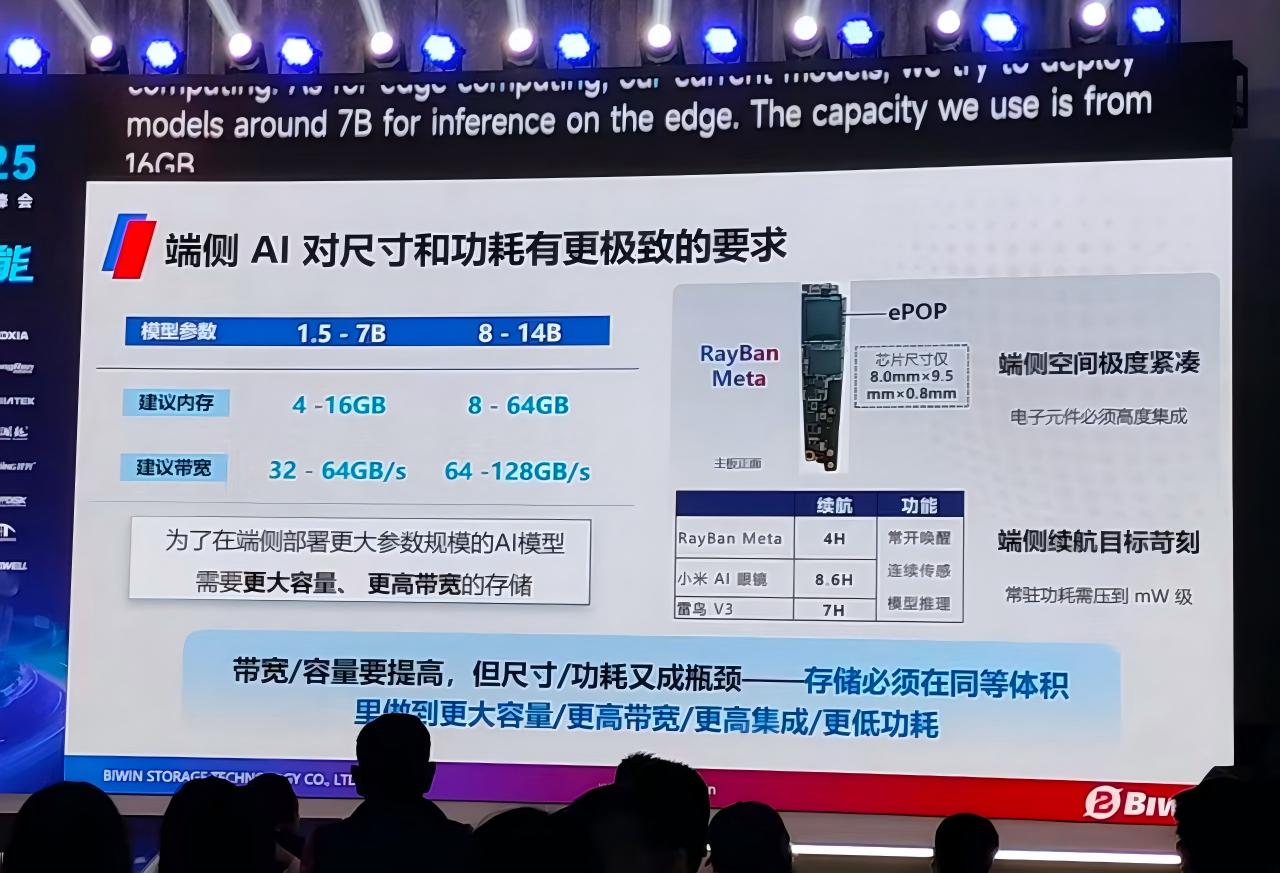
佰维存储:AI时代的存储解决方案
电子发烧友网报道(文/李弯弯)在GMIF2025大会上,佰维存储CEO何瀚表示,端侧AI对存储的尺寸和功耗有着更为极致的要求。随着在端侧部署
2025MWC上海|佰维全景呈现AI存储创新能力,赋能数智物联新生态
近日,2025年世界移动通信大会(MWC上海)在上海新国际博览中心圆满落幕。佰维携其前沿存储解决方案和全场景应用案例亮相展会,展示了其在智能时代下的技术实力与产业生态影响力。
高性能计算集群在AI领域的应用前景
随着人工智能技术的飞速发展,高性能计算集群(HPC)在AI领域的应用前景日益受到关注。HPC提供的计算能力与AI的智能分析能力相结合,

芯原可扩展的高性能GPGPU-AI计算IP赋能汽车与边缘服务器AI解决方案
芯原股份 (芯原,股票代码:688521.SH) 日前宣布其 高性能、可扩展的GPGPU-AI计算IP的最新进展,这些IP现已为新一代汽车电子和边缘服务器应用提供强劲赋
佰维存储亮相COMPUTEX 2025,全场景存储方案赋能“AI +”未来生态
时代的技术创新能力和全球化品牌运营实力。 多品类消费级存储 满足AI时代用户侧多样化使用场景 面向AI时代消费者在AIGC内容创作、电竞游戏、设计建模等多样化应用场景下对高速、高效存储

COMPUTEX 2025:德明利以全栈存储技术赋能“AI NEXT”产业落地
及全球化布局,展现存储技术的革新力量。端侧AI适配性能与能效的双重突破PART.01高性能

RAKsmart服务器如何赋能AI开发与部署
AI开发与部署的复杂性不仅体现在算法设计层面,更依赖于底层基础设施的支撑能力。RAKsmart服务器凭借其高性能硬件架构、灵活的资源调度能力以及面向AI场景的深度优化,正在成为企业突破



评论