 关于转码系统优化原理与实践
关于转码系统优化原理与实践

编者按
转码主要有三个目的:提高码流的兼容性、改善画质和降码率省带宽。转码系统对公司的带宽和体验是非常重要的,尤其在降本增效大背景下。LiveVideoStackCon 2023 深圳站邀请到哔哩哔哩公司蔡春磊老师讲解B站降低码率相关的原理和实践。
文/蔡春磊
大家好,我是蔡春磊。今天和大家分享一些关于转码系统优化原理的思考。我毕业后加入哔哩哔哩,主要从事传统实用转码系统的设计和优化。同时我对深度学习编码也有过研究,我经常思考它们之间本质上的联系,今天和大家探讨一下。
01
广义转码框架
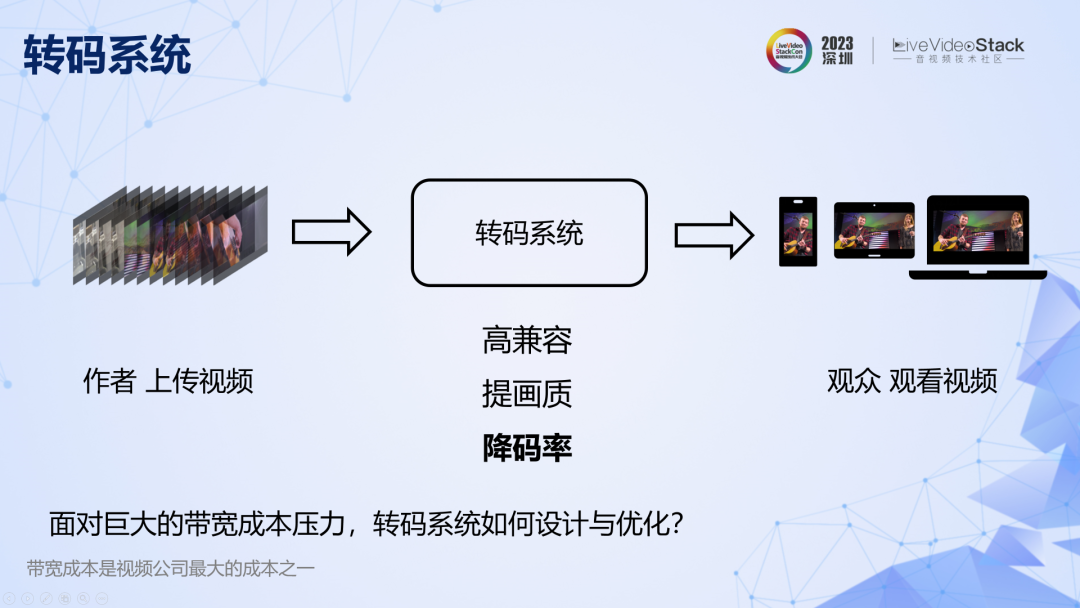
我们从转码系统切入。转码主要有三个目的:提高码流的兼容性、改善画质和降码率省带宽。今天主要探讨降低码率相关的原理和实践,因为带宽成本是视频公司最沉重的负担之一。
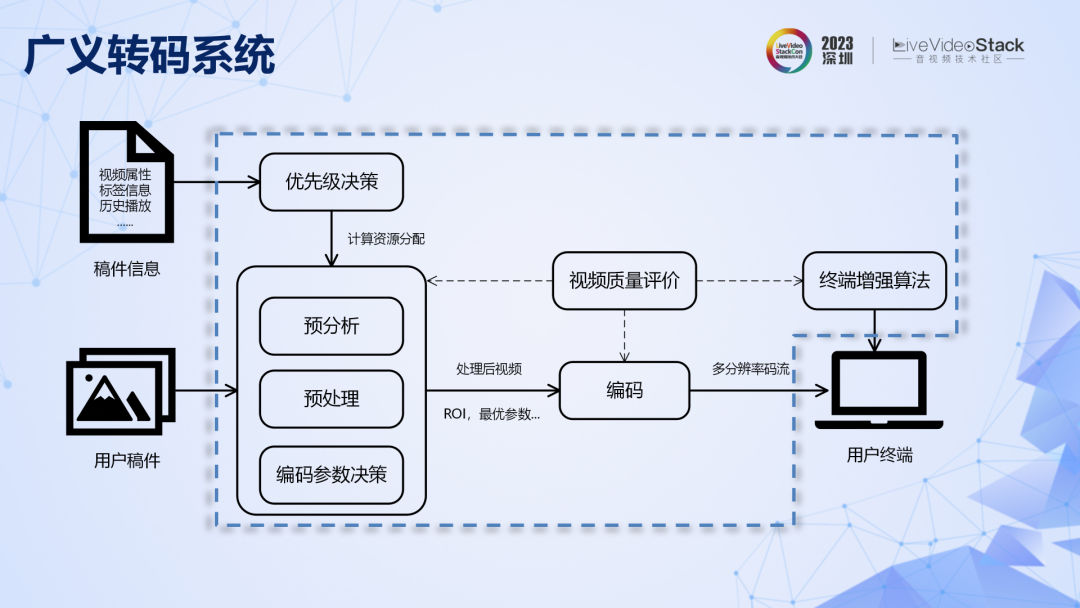
现在的转码系统不仅仅是简单的解码再编码,而是包括了预分析、前处理、参数决策、终端增强和质量评价等模块的庞大系统。其基本原理是在更大的系统尺度上,对压缩率进行联合优化,用更多算力换取更高的压缩率,可以称之为广义转码系统。

广义转码系统具体表现形式非常多,不同公司的实现方法不同,叫法也不同。例如,内容自适应转码系统、窄带高清转码系统等。上面列出了全球部分代表性公司对转码系统各个模块的投入,从投入力度上可以发现,转码系统对公司的带宽和体验是非常重要的,在降本增效的大背景下更是如此。

B站在转码系统优化上起步较晚,那我们该如何做才能迅速追赶行业先进水平呢?首先,不能着急投入到具体的技术实践当中,因为不同的应用场景对转码系统的要求截然不同,比如适合 OGV 内容为主的转码系统不适合直接用在 UGV 为主的应用中,反之亦然。我们首先要做的是找到底层的优化原理。

具体来讲,就是要先思考上述这些技术点,有没有共同的优化原则。
02
压缩的信息论原理
我先尝试构建一套基于信息论的优化理论框架,然后对其合理性进行验证。
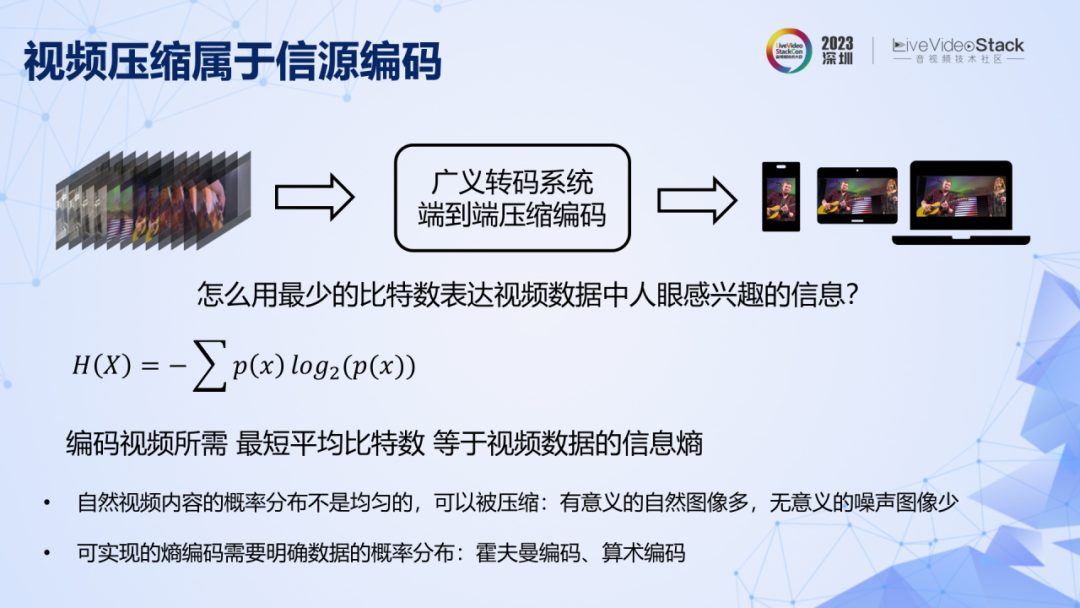
先忽略转码系统复杂多变的表现形式。转码本质是一个信源编码系统,目的是用最少的比特数表达视频数据中人眼感兴趣的信息,最短平均比特数等于视频数据的信息熵。在实际应用中,有意义的自然视频多,无意义的噪声视频少,概率分布不均匀,所以信息熵小于像素数据无损表示所需要的比特数,因此视频数据可以被压缩。计算信息熵,前提是要明确视频中所有像素取值的联合概率分布。我们先用信息熵的概念作为基座,再看两条定理,它们构成了理论框架的支柱。
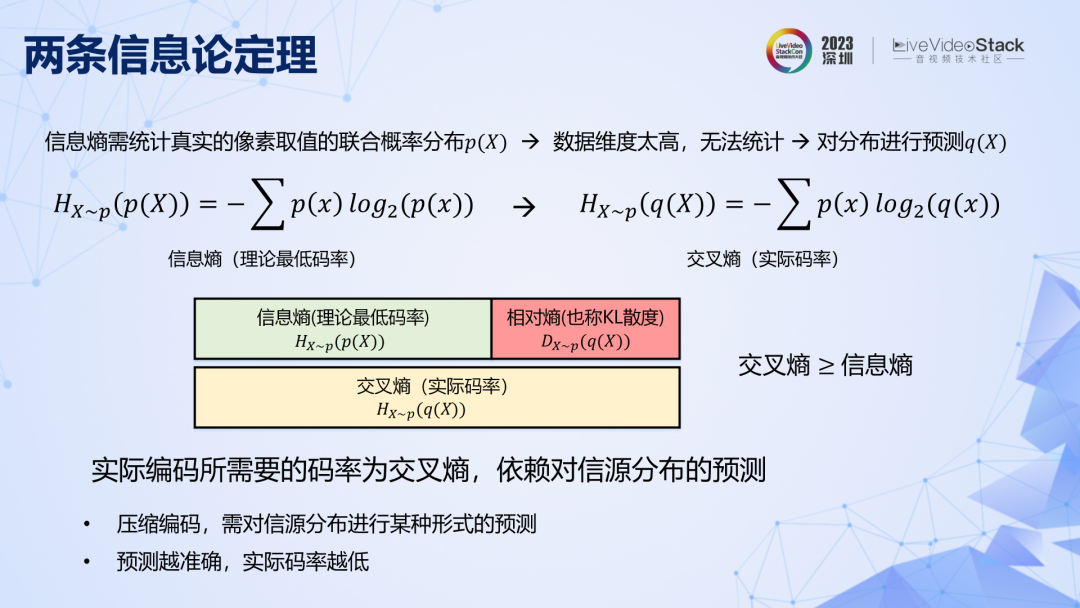
第一条定理是说,真实视频的像素联合取值空间非常大,其概率分布不可能通过统计得到。所以在实际编码时,是基于对概率分布的预测,由此进行实际熵编码得到的码率叫做交叉熵,可以证明交叉熵≥信息熵。对分布预测得越准确,所能达到的实际码率越低。
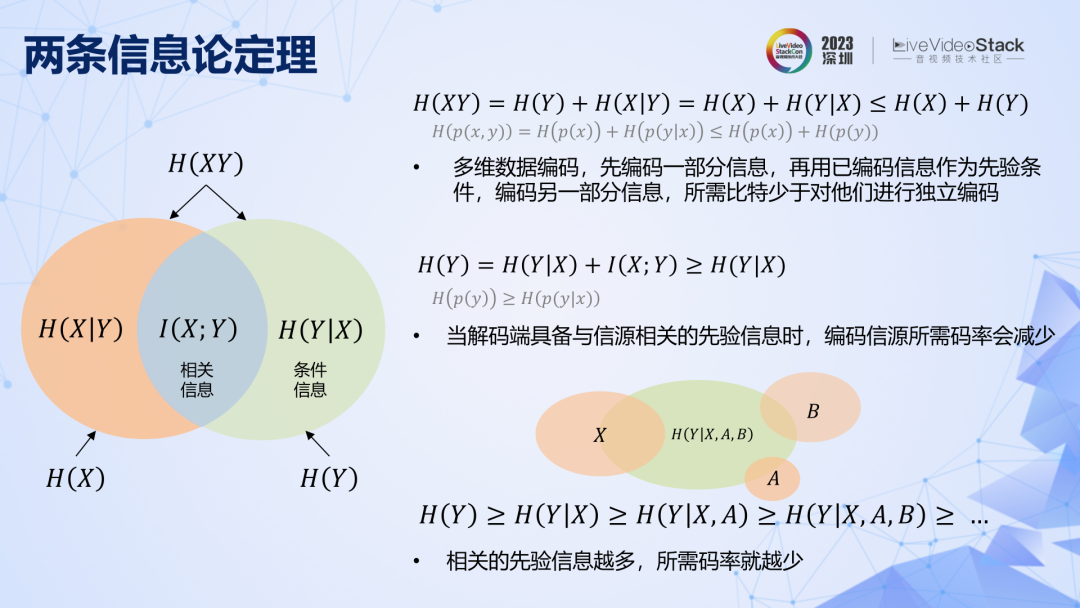
第二条定理可以用以上图直观表示,它有多种理解方式:1. 编码多维数据,可以先编码一部分信息,再用已编码信息作为先验条件来编码另一部分信息,这样所需比特数要少于对他们进行独立编码。2. 当解码端事先已具备与信源相关的先验信息(相关信息)时,编码信源所需码率(条件信息)可以减少。3. 相关的先验信息越多,所需码率越少。

这就是一套关于转码优化的理论框架了,非常简洁:一条信息熵的基本概念、两条信息论定理。检验此框架的合理性,可以用此来解释转码系统中各个模块的设计原理以及优化路径,如果能解释明白,那就可以认为此框架是合理的。

我们先以传统编码的发展为例。如果从技术角度来理解我们所熟悉的变换和预测混合编码方法,门槛是很高的,因为里面涉及了太多的模块。现在我尝试从理论角度出发,对传统编码框架的设计原理和优化路径进行重新梳理。
对视频像素数据进行压缩,前提是要明确像素取值的联合概率分布,但视频由时域上很多帧组成,其像素数量极其庞大,数据间联合取值的范围几乎无穷。所以首先对数据进行降维处理,也就是一帧一帧地去编码。上面的公式表明,为了保持理论上的最低码率,在编码时要充分利用已经编码帧给未编码帧提供相关信息。但在实际标准中,由于复杂度问题,采用的都是有限数量的参考帧结构,这是传统编码中帧间编码的概念。原理上帧间参考信息越多,码率越低,所以随着标准的发展,逐渐出现了 P 帧、B 帧,同时封闭式的 GOP 结构向开放式 GOP 结构发展。

现在我们将问题拆解成对一帧进行编码。但是,一帧 1080P 图像就有百万数量级的像素,它们之间的联合取值范围也近乎无穷大。继续降低维度,把图像拆成一个一个块进行编码,原理上在编码时为了保证尽可能低的码率,要充分利用已编码图像块,给未编码块提供相关信息来降低码率。但由于复杂度原因,在实际发展过程中首先出现的是诸如 H.264 中 16×16 的小块,且仅参考相邻域图像块的边缘像素。从公式可以轻松推导出,当 LCU 越大的时候,对具体的 CU,能参考的信息就越多,理论上码率就会越低。所以编码标准一定是朝着编码块越来越大的方向去发展,同时还会引入更多的邻域相关信息,比如多行参考。
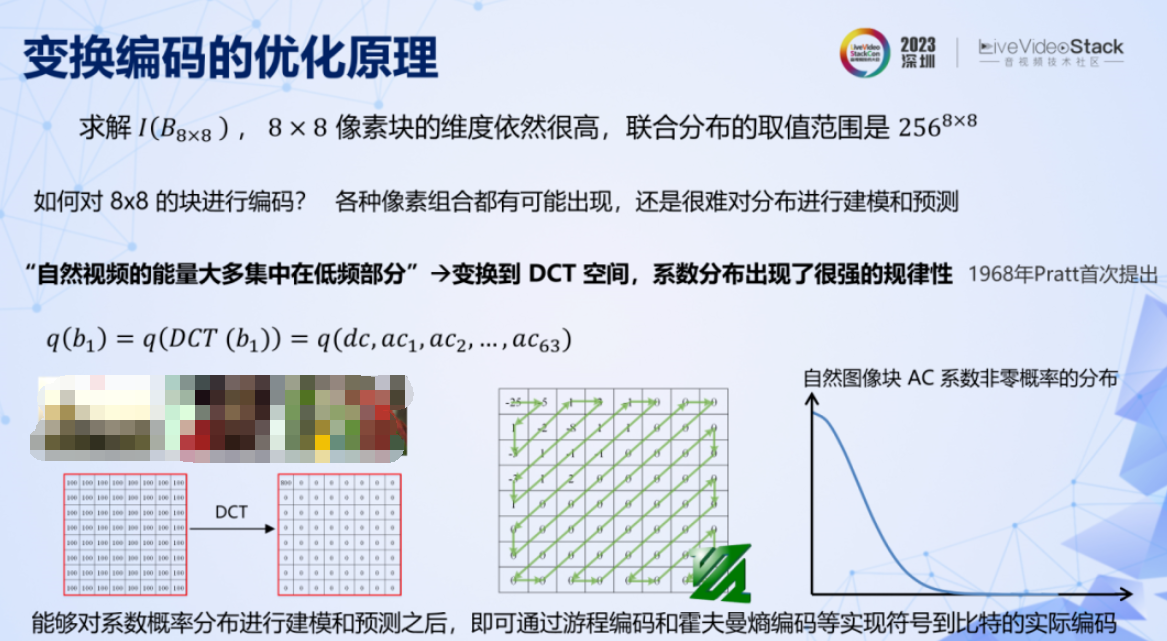
假设已经将图像拆成了 8×8 的像素块,但是其维度依然很高,联合分布的取值范围仍然极大。而且其取值非常分散,很难对其分布进行建模预测。对像素数据的分布进行预测,换句话说,其实是在问,自然图像块有没有共同规律?
其实这个规律早在 1968 年就被发现了:自然视频能量大多集中在低频部分,图像块经过 DCT 变换后,系数会呈现很强的规律性,非零系数不多,且集中在低频部分。根据这个规律,就可以对系数的分布进行建模预测,如右边曲线所示。同时由于这个规律性很强,也就是说预测可以很准确,所以交叉熵就会很低,编码所需码率就低。再结合 zigzag、熵编码等工具就能实现压缩的目的。DCT 变换编码这个天才般的发明,直到现在依然是传统编码中最核心的模块。而 zigzag 则成了 FFmpeg 的 logo。
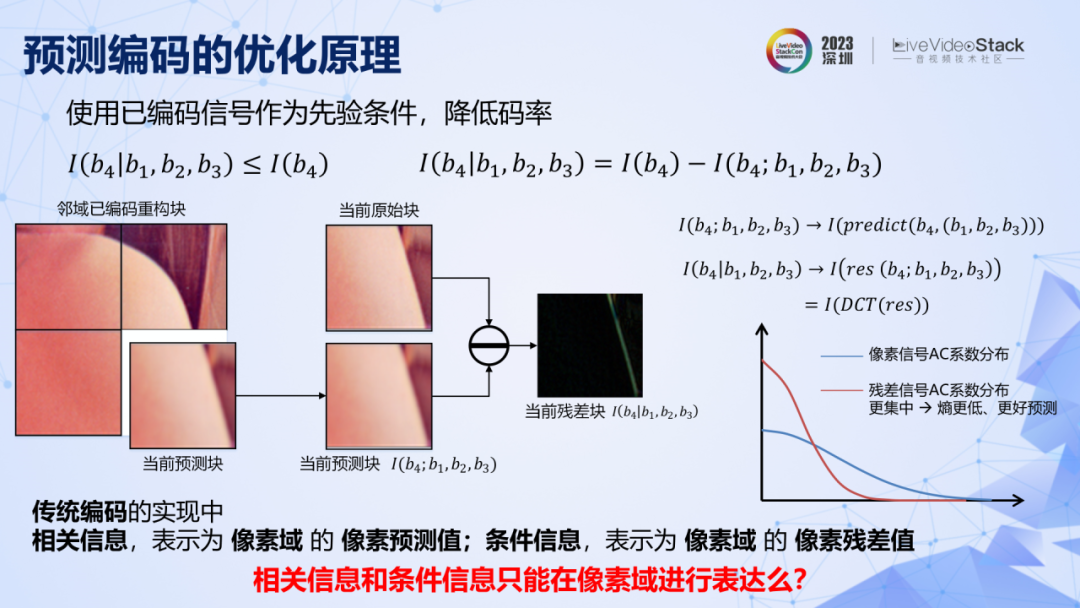
分块加变换编码,就构成了 JPEG 的基本框架。想要进一步降低码率,原理表明,可以用相邻的图像块给当前图像块提供先验的相关信息,那么当前块所需要编码的就剩下了条件信息,而条件信息比自信息低,所以码率就低。
在传统编码中,相对信息的表达方式是周围图像块对当前图像块在像素域上的预测值。条件信息的表达方式是当前块的像素预测残差。而条件信息比自信息更低,则表现为预测残差经过 DCT 变换之后,其系数会变得更加集中,非零系数更少,对其进行概率预测,所取得的交叉熵会更低,实际码率也就更低。这就是传统编码中另一个核心技术:预测编码。
在这里先抛出一个问题,在传统编码中,相关信息和条件信息都是在像素域进行表达的,那么它们是否只能在像素域进行表达呢?
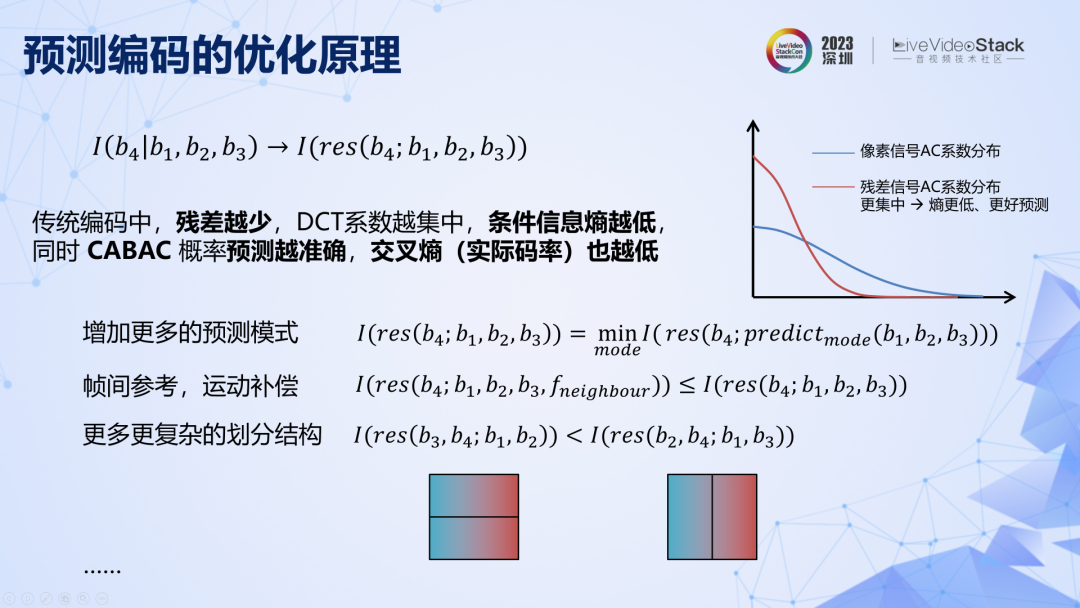
在传统编码中,预测残差越少,DCT 系数越集中,交叉熵越低。所以传统编码中一个重要的优化方向是不断引入更多的相关信息来提高对当前图像块的预测准确率,降低残差,从而降低码率。从这个角度看,就可以对很多传统编码工具的设计和发展路径进行解释,例如帧间参考的原理就是在参考当前帧图像块的基础上增加相邻帧图像的参考,本质是引入更多相关信息从而减少条件信息,可以降低码率。至此,我们已经从原理出发,重新推导了传统的基于变换与预测的混合编码框架,以及各个模块的优化路径。

编码模式信息同样不可忽视,上图第一行公式成立的前提是解码器提前知道划分模式,但是通用解码器预先是不知道具体编码模式的,所以模式信息也要编码,也要消耗码率。同样,模式信息也是可以引入更多先验条件来降低码率的。实际编码时,不同模式的概率预测难度不同,其实际码率也不同,且无法提前得知,所以需要尝试不同模式并计算各自的码率,从而搜索到码率最低的模式,这就是模式搜索的概念。

上述都是无损编码,但实际用的大多是有损编码。有损编码的原理可以解释为:为编码提供了一个先验条件,即允许在编码过程中对部分像素数据进行丢弃。在这个条件之下,编码可以减少数据量来降低码率。率失真优化 RDO 就是综合考虑了失真和码率的模式搜索,在实际标准发展过程中,编码模式及其之间的组合急剧增加,模式搜索的空间不断增大,因此实用编码必须要引入一门重要的技术——快速算法。

传统编码的原理解释先到这里,希望能为大家带来一些启发。接下来,继续用此框架来梳理深度学习编码的发展历程。
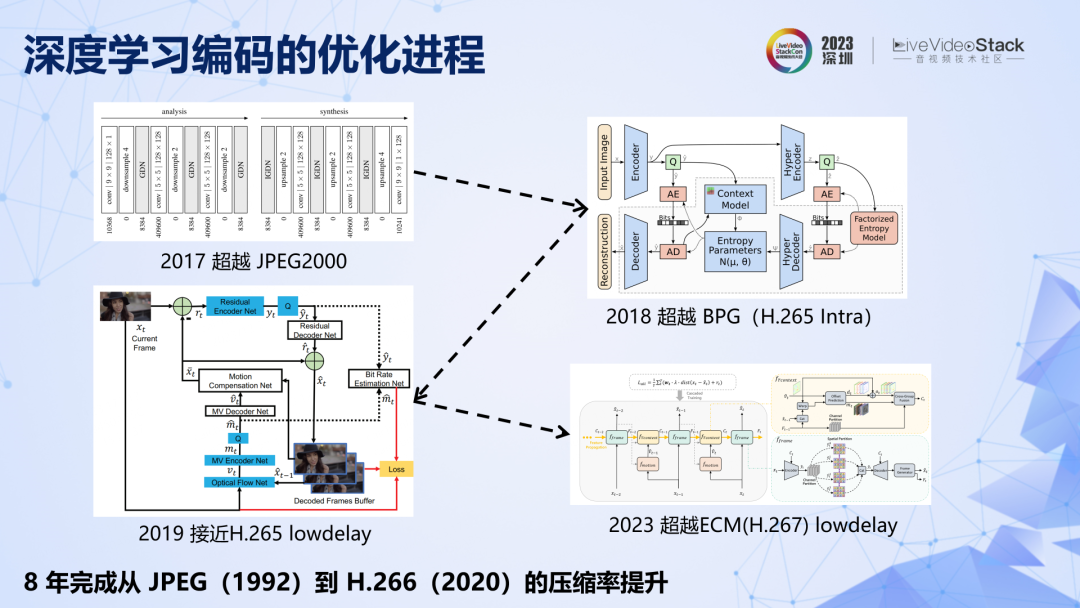
介绍一下深度学习的发展背景。约翰内斯巴莱最早提出了基于 CNN 的端到端图像编码,该方法具有开创性,为编码领域开辟了一条全新的赛道,并掀起了全球对深度学习编码的研究热潮。深度学习编码性能快速发展,如果对标传统标准,8 年时间就从 JPEG 发展到 H.266,甚至下一代标准的水平,走完了传统编码约 30 年的性能提升之路。
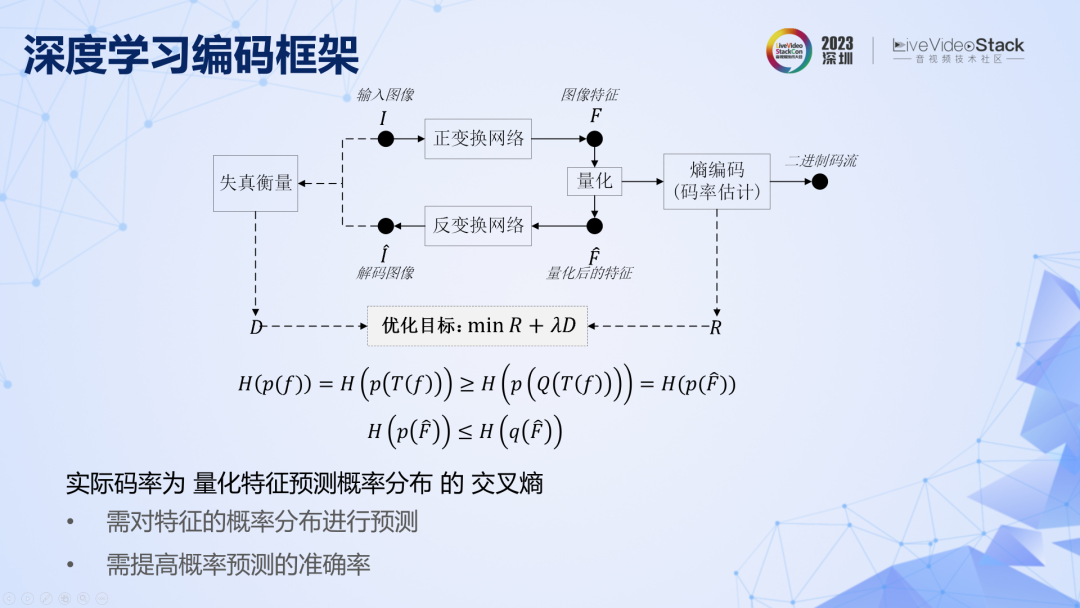
回顾一下深度学习图像编码的基本框架,和传统编码遇到的问题一样,对像素域的分布预测很难,也要变换到分布更加有规律的特征域,以进行更加准确的预测。
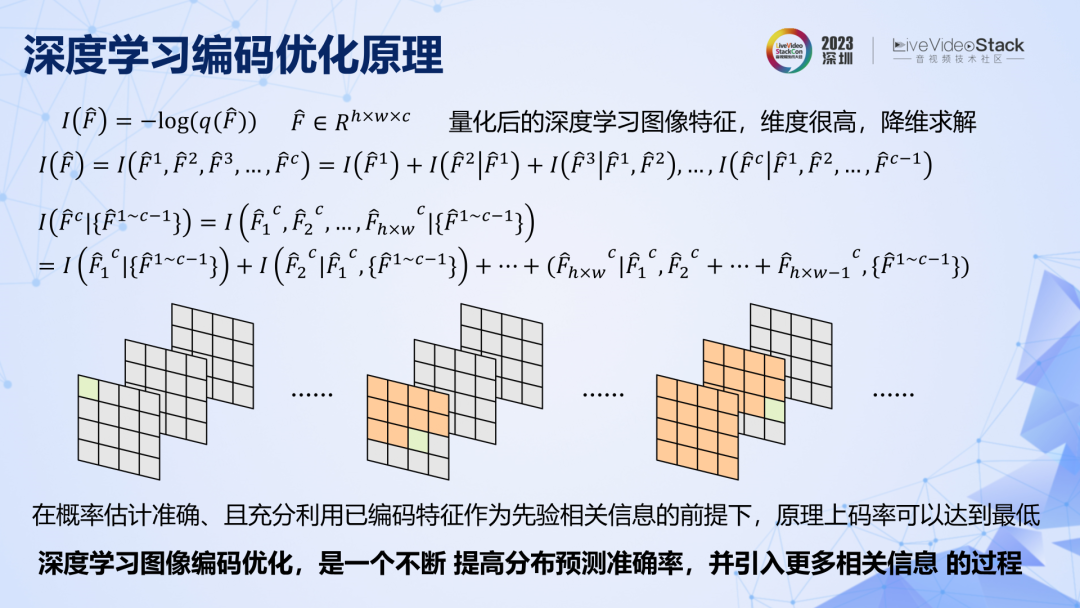
问题转变成了对特征进行编码,特征的联合概率分布空间依然很大,也需要先降维,拆解成一个一个通道,一个一个特征去编码。原理上要想取得尽可能低的码率,需要充分利用已编码的特征给未编码特征提供相关信息。接下来要回顾的深度学习图像编码,其实就是一个不断提高特征预测准确率,同时引入更多相关信息的过程。
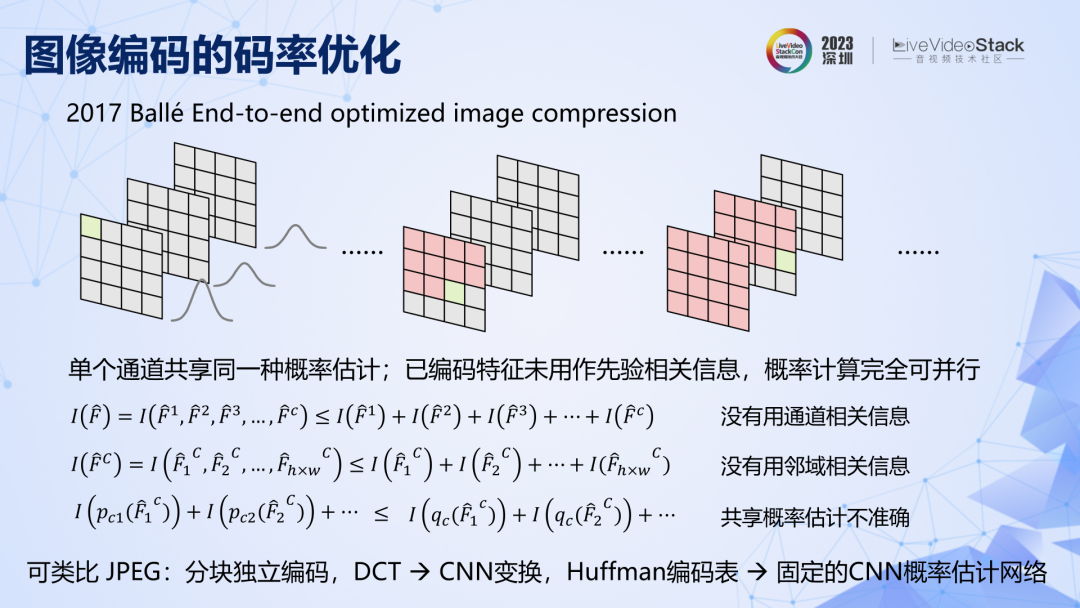
看几个关键节点,2017 年第一个 CNN 图像编码,有两个关键点,一是相同通道内的特征共享同一个固定的概率分布表,二是已编码特征没有用来给未编码特征做参考。由于这两个特点,在公式上很容易证明,该方法的压缩率是有限的,概率预测准确率不高,相关信息利用不够充分,码率就不可能很低。原理上有二个优化方向,一是提高特征分布的预测准确率,二是利用已编码特征提供相关信息。

2018 年,他们实现了这两个优化。具体来说,从通道级固定概率表发展到元素级可变的概率估计,同时空间相邻元素之间有参考。这两点改进使压缩率从 JPEG2000一下子就发展到了 2013 年 HEVC。如果继续梳理,站在原理框架的视角去看,接下来的发展脉络其实非常清晰,就是不断引入更多已编码特征提供相关信息的过程。不过在实践中,利用的相关信息越多,复杂度就越高,并行性越弱,速度和压缩率之间需要有取舍。
有一点需要注意,在深度学习图像编码中,相关信息和条件信息的表达已经不在像素域,而在特征域了,这些方法都在特征域进行元素间的参考预测和残差编码。所以,之前问题的答案,相关信息和条件信息,并不是只能在像素域进行表达。我认为这个本质的差别,决定了深度学习编码的性能天花板要比传统方法高得多。
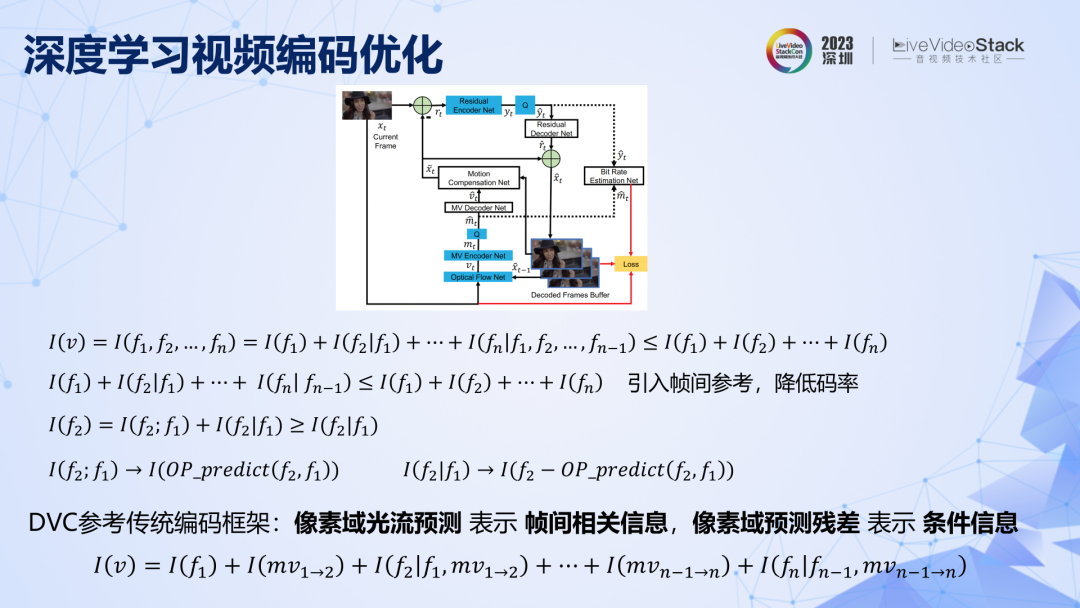
继续来到深度学习的视频编码,上面第一行公式,表明如果对视频进行一帧一帧编码是不高效的,需要引入帧间参考,提供相关信息来降低码率。第一个深度学习视频编码 DVC 在图像编码基础上,引入了前向帧间参考,完全遵循了传统的编码框架,用像素域光流预测表达帧间相关信息,用像素域预测残差表达条件信息。虽然用光流替代了传统运动估计,但这在原理上,DVC 和传统方法并没有本质差别,所以 DVC 框架的性能天花板其实是有限的。
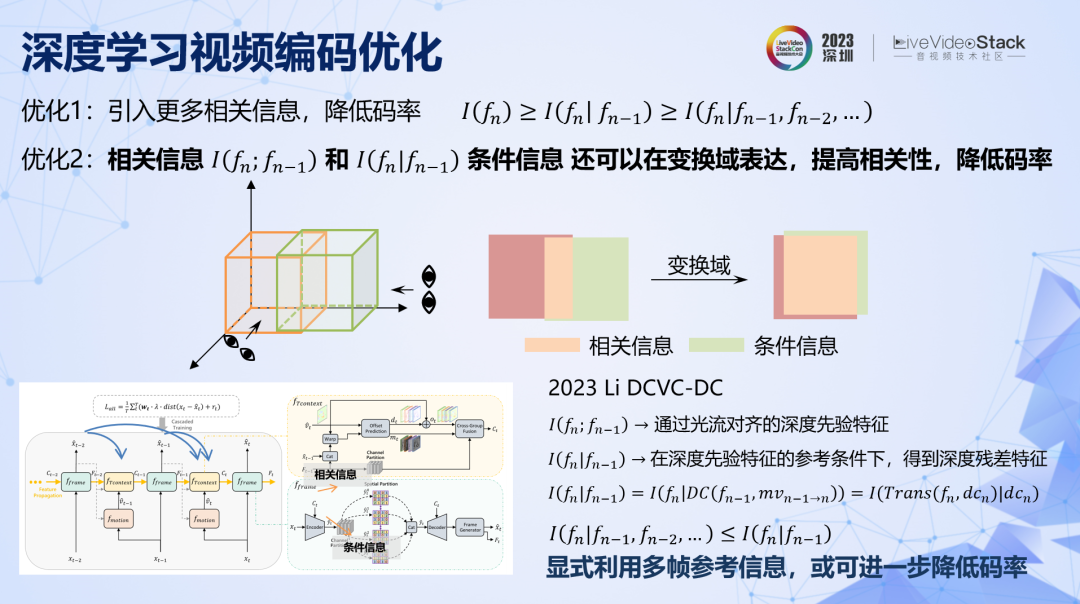
有两个优化方向:一是引入更多相关信息,降低码率。二是将相关信息和条件信息在更有效的变换域内进行表达。
第一条好理解,就是引入更多的参考帧。第二条用上面的示意图可以直观地解释,同样两组数据,可以从不同维度去观察它们的相关性,在不同空间内,他们之间的相关信息量是不一样的。所以总是存在更有效的空间,它们之间的相关信息更多,条件信息更少,那么在这个域上编码条件信息,码率就会更低。传统方法都是在像素域内表达相关信息和条件信息,这是最容易实现的,但未必是最优的,深度学习图像编码全面超越传统方法已经证明了这一点,那么深度学习视频编码同样可以这样去优化。
目前最新也是最好的方法 DCVC-DC,实现了这两点优化。具体来说,一是利用深度学习特征的传导,引入了前向多帧的相关信息。二是帧间参考信息和当前条件信息都是在特征域进行表达的,而不是在像素域。该方法比目前正在研发的下一代 ECM(可以认为 H.267)在相同 GOP 结构下的性能更好。该方法对于前向非相邻帧的参考还是比较隐蔽的,如果使用更加显式的方法,引入更多相关信息,或许可以进一步提升压缩率。
总结一下深度学习编码,原理是利用深度神经网络强大的优化能力和巨大的算力,对编码问题中概率预测的问题进行更加直接的求解,所以深度学习编码的性能发展速度远远快于传统编码。可以预见的是,在未来本就激烈的编码标准竞争格局中,深度学习编码必将以强势的姿态加入竞争,并取得重要的席位。

沿着编码发散一下,一是用大模型给解码端提供更多先验知识,二是相关信息和条件信息在内容语义层面进行更高效的表达。例如,英伟达提出在会议场景下的极低码率编码。原理是在解码端利用面部重建模型,提供了从关键点和共享纹理构造人脸的先验知识。同时该方法对帧间相关信息表达为共享的面部纹理和参考关键点,条件信息表达为当前帧人脸的关键点信息,所以只需要对人脸关键点信息进行编码,而关键点可以以极低的码率去表示。
还有最近比较火的“郭德纲说英文”的有趣应用,如果从转码角度去看这项技术,其实可以实现对同一视频内容的不同语言版本进行极其高效的压缩和传输,这能够在对视频内容进行全球化分发的业务中节省大量的成本。假设我们先用传统方法分发一个中文和英文版的视频,尽管只有嘴型不同,但是传统方法需要单独编码两个视频,码率成倍上升。
换个思路,如果提前给解码端几个大模型,如翻译模型、文字转语音模型、语音驱动嘴唇的模型。此时就只需要编码传输一个英文版本的视频,其他语言版本的视频可以通过解码端的大模型完全重构出来,此时对其他所有版本的视频编码所需要的比特数为零,这就实现了极其高效的压缩。

沿着编码继续发散,原理上解码端拥有相关信息越多,码率就越低。可以推测有两个发展方向,一是专用场景下的编码,这相当于提供了一个非常强的场景先验信息,比如英伟达的会议场景下的编码。专用编码目前还很难推广,是因为传统标准依赖专用解码芯片,不同标准无法共享高效的芯片核心,限制了解码的效率。但假设未来深度学习编码能够普及,那么各类专用编码器的差异可能就在于模型结构和参数的不同,而底层推理芯片是一样的,也就不存在解码效率差异的问题了,安装专用场景的硬件解码器只需要像安装软件一样,下发解码模型文件即可。
二是用世界大模型进行视频编码,其原理是用更庞大的算力和更海量的数据,对编码中的概率估计问题进行更加直接有效的求解,从而取得更低的交叉熵。此时,大模型会学习海量关于视频数据的先验信息,对视频的压缩表示会转变成视频在大模型中的概率表索引,这个索引可能就是我们所熟知的 prompt,对保真度的要求越高,prompt 就要越准确越具体,或者额外传输一些语义级别的残差信息。最近有学者认为大模型本质就是压缩模型,从我们的原理框架出发,也演绎出了类似的结论。

编码先说这么多。那么转码系统中其他模块的优化原理是什么呢?其他模块都可以归纳为一个范式:为转码系统提供和人眼视觉感知系统相关的先验信息,就可以减少编码人眼感知信息所需要的条件信息。这些先验信息包括人眼更关注人脸、人眼对复杂纹理的失真不敏感等,先验信息与人眼视觉系统越匹配,能够给转码系统赋予的相关信息就越多,剩余条件信息越少,码率越低。在实际系统中,前处理和 ROI、JND 等预分析的目的就是确保这些先验条件能够充分而准确的实现。
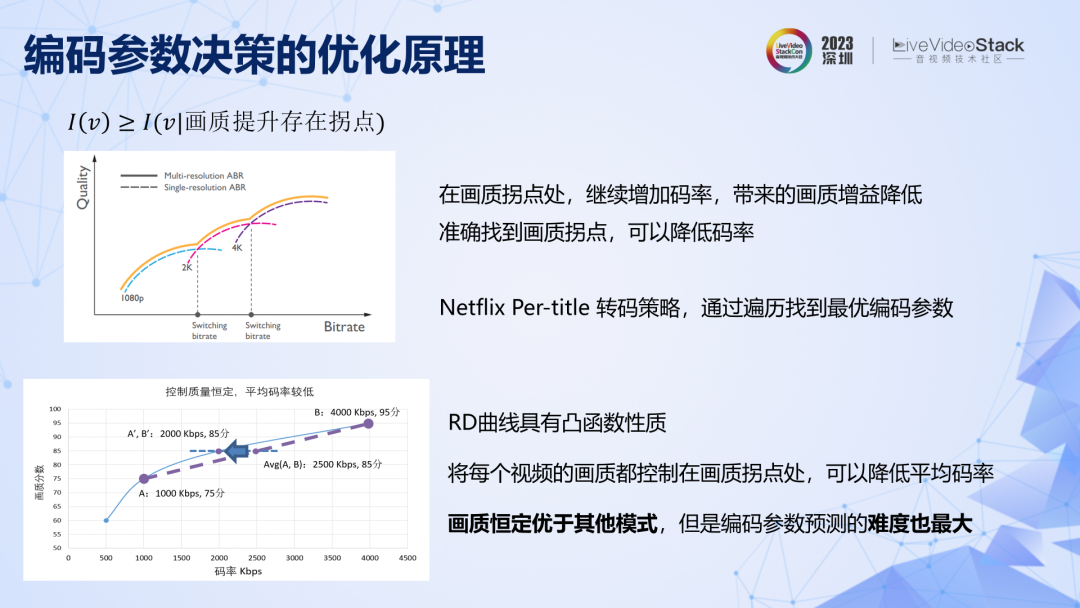
再看编码参数决策,其原理也是给转码过程提供了先验信息,比如人眼对画质存在拐点,画质达到一定水平后,再增加码率对主观画质提升是有限的。还有对一批视频进行编码时,如果能够保持每个视频的画质足够稳定,那么对用户体验的提升是有帮助的。参数决策的目的也是确保这些先验条件能够准确而充分的实现,比如通过参数决策保持视频编码后的画质恒定。
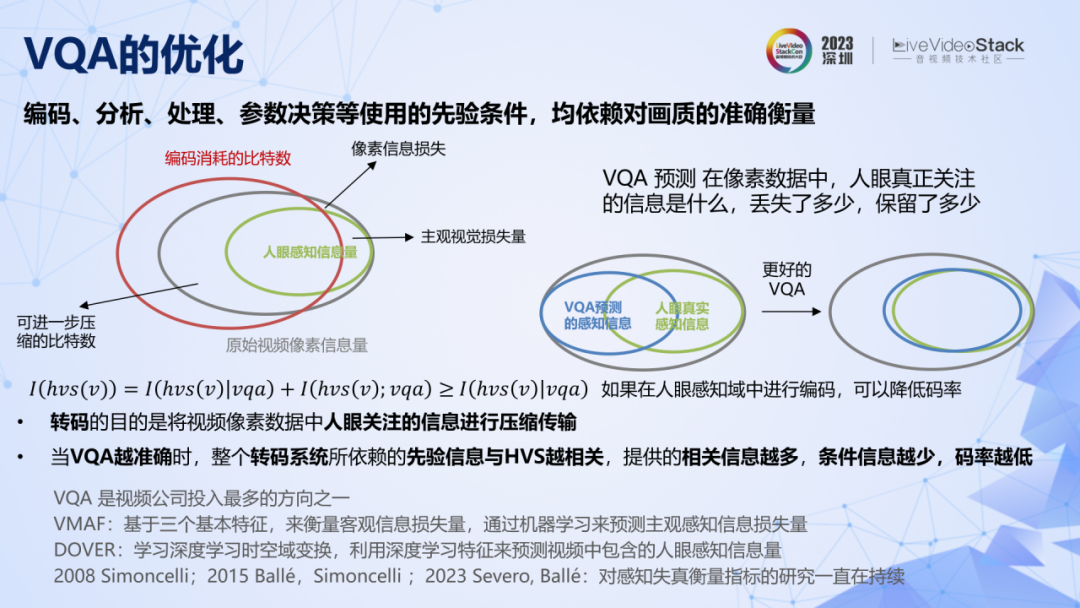
我们为转码系统提供的先验信息,具备有效性的前提是符合人眼视觉系统 HVS,那么视频质量评价 VQA 的目的,就是确保这个前提的成立。VQA 评价了一个视频中有多少人眼真正感兴趣的信息,或者相比于源视频丢失了多少人眼感知信息。当 VQA 越准确的时候,整个转码系统所依赖的先验信息就与 HVS 越相关,所能提供的相关信息就越多,条件信息越少,码率越低。
只要是从事过转码系统相关工作的人,应该都会发现,整个转码系统中的各个模块,对 VQA 都有很强的依赖。所以 VQA 是如此得重要,以至于 VQA 是整个视频行业投入最多的方向之一。但是 HVS 非常复杂,所以对 VQA 的研究也一直在持续。

我们对传统编码和深度学习编码以及其他模块的优化原理进行了重新梳理,目前看来,我们的原理框架是合理的。现在我们就可以用此框架来指导实际转码系统的设计。
03
B站转码优化实践
接下来,介绍一些B站转码优化的实践经验。
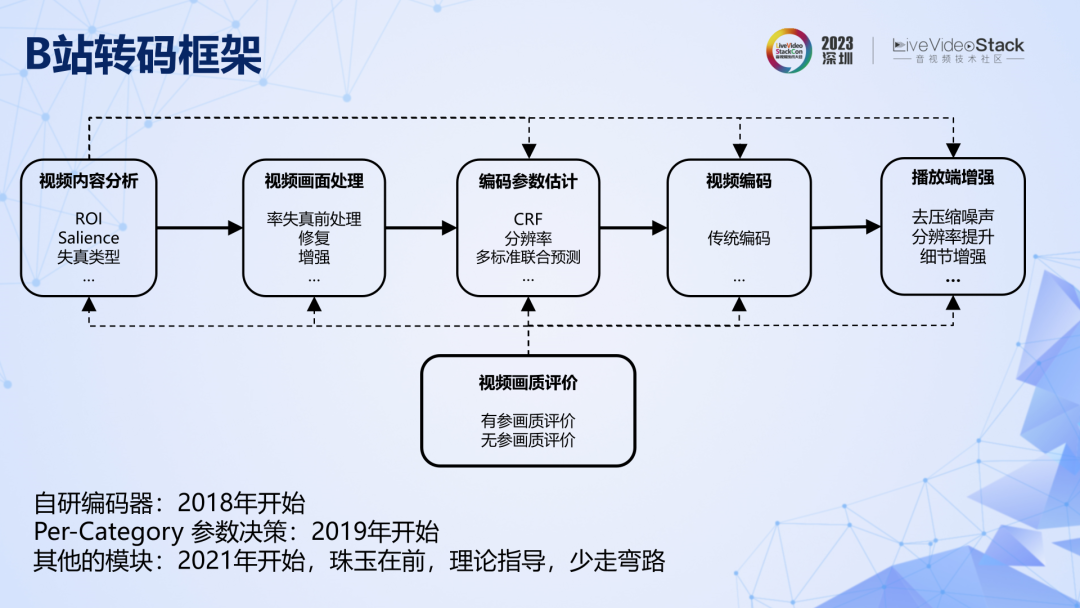
这是B站规划的广义转码系统的框架图,有些模块还在研发中。我们最开始投入的自研编码器,然后是 Per-Category 级别的参数决策。
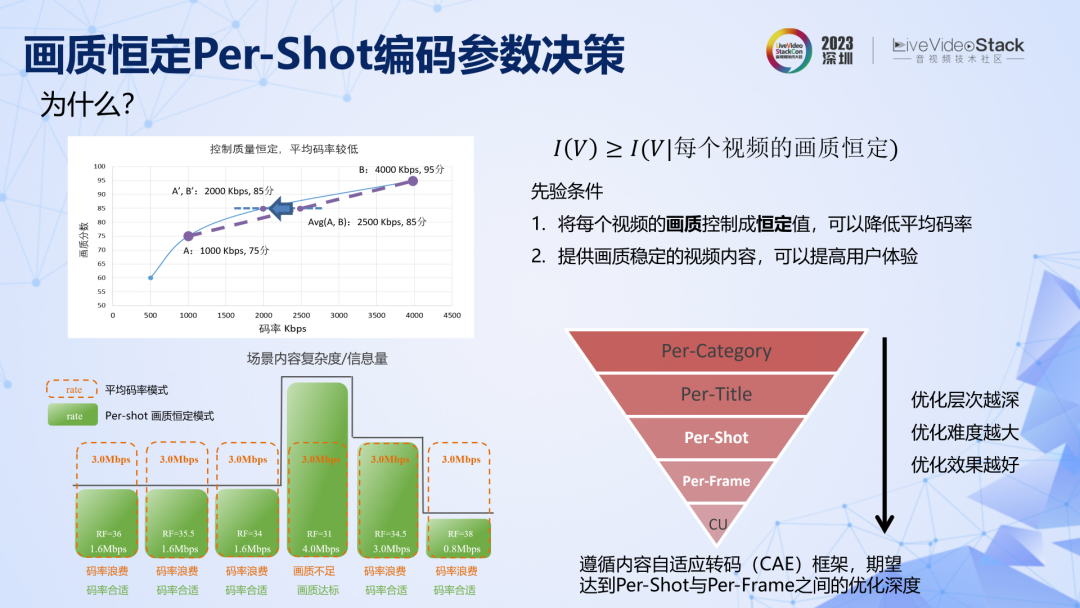
参数决策方面。我们提出了一种场景级别的画质恒定的转码方法,原理是利用了一个先验条件:如果能将每个视频的画质控制成恒定值,那么既可以避免码率浪费,同时画质稳定的视频内容,也有助于提高总体的用户体验。实际落地中,系统遵循了内容自适应转码(CAE)框架,期望达到 Per-Shot 与 Per-Frame 之间的优化层次,即在场景级别和帧级别实现画质控制。
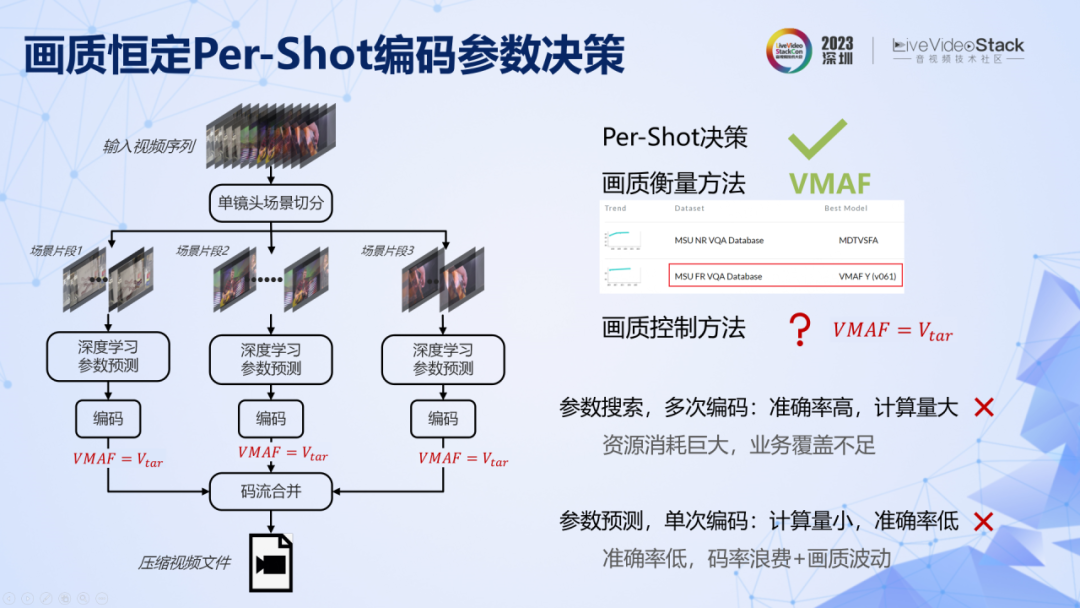
这是具体的实现框架。具体来说,需要解决三个问题:一是场景切换,我们直接调用了 x264 中的 scenecut 算法实现了高效的场景切分。二是如何对画质进行衡量,在转码应用中,我们发现 VMAF 依然是目前最准确最稳定的方法,此外还引入了另一个先验假设,即 VMAF 值一样情况下,我们认为画质是接近的。第三个问题,就是在这个假设之下,怎样保证编码之后的 VMAF 值等于统一的预设值,不能高也不能低。
有两个实现思路,一是进行参数搜索,多次编码,多次验证,搜索得到最优参数,这个方法准确率很高,但是算力很大,不适合 UGC 场景。第二种方法是单次参数预测,训练机器学习模型,将视频特征作为输入,直接预测满足 VMAF 的编码参数。这种方法计算简单,算力不高,但是准确率难以保证,而当准确率不高的时候,转码所依赖的先验信息就不准确,也就无法提供足够多的相关信息,码率也就不够低。
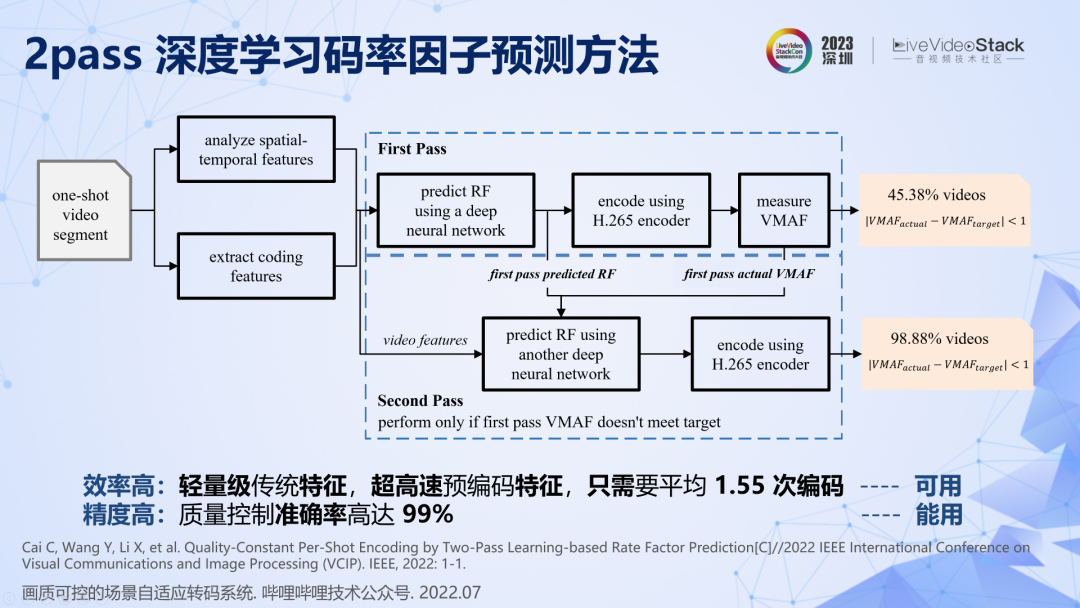
在有限复杂度的约束下,我们提出了一种基于深度学习的 2pass 码率因子预测方法。首先用简单高效的传统特征,训练一个非常简单的神经网络进行单次参数预测,首次能够达到 45%的准确率。然后对剩下 55%画质不达标的片段进行第二次预测,第二次预测引入第一次预测的结果作为锚定信息,此时会惊喜地发现能够达到 99% 的准确率。所以,该方法可以以平均 1.55 次编码和 1 次 VMAF 的复杂度实现 99% 准确率的场景级画质控制。
在该系统中,我们利用了一个先验条件:认为编码后 VMAF 恒定的情况下,画质是一样的。这个先验条件和人眼主观系统的匹配程度直接决定了转码系统的实际表现。在实践中,我们发现对于大部分视频,这个条件是成立的,但是对有一些动画、三明治、大背景小前景等视频类型,VMAF 不够准确,普遍虚高,这就造成了实际表现不及预期。
在没有找到更准确的画质评价方法之前,我们只能先打补丁,提高画质恒定这个先验条件的准确率。一种方法是 ROI 编码,其原理是利用了一个很强的先验:人眼对人脸和人体的失真非常敏感。编码之前先检测人脸、人体、背景三个部分,然后在码率分配时设置不同的优先级。在运用了很多类似的补丁之后,系统的画质稳定性得到了显著增强,率失真表现也得到了明显提升。
未来对参数决策的优化方向依然是不断提高先验条件的准确率,包括尝试再深入一层达到帧级别的质量控制、探索更合理的画质评价方法等,确保给系统提供更多更准确的先验信息。
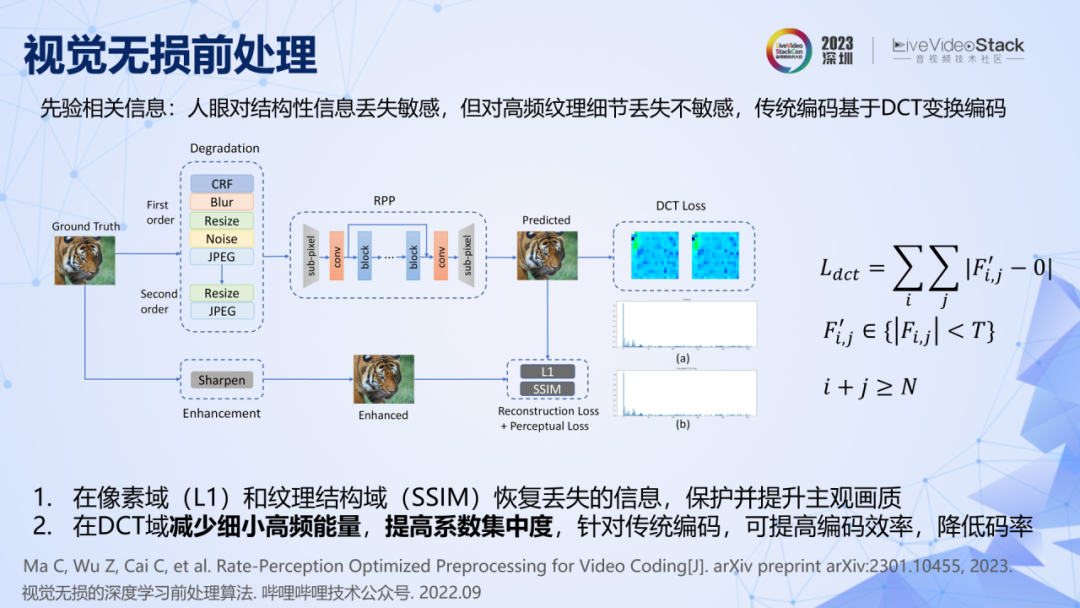
我们还利用了视觉无损前处理来进一步降低码率,其原理是利用了三个先验条件,一是人眼对结构性信息的丢失很敏感,例如编码后如果人脸、眼睛、鼻子等轮廓模糊,人眼能感知出来。二是人眼对高频纹理细节的丢失不敏感,例如对草地纹理失真是不敏感的。三是站在转码系统的尺度下,利用了编码器的一个先验信息,即传统编码都基于 DCT 变换编码,非零系数越少,零系数越多的时候,码率就会越低。
实际落地要做的就是找到一个方法将这三个条件充分准确地实现。我们设计了一种损失函数和训练策略,训练了一个简单的 CNN 网络来实现这三个条件。具体来说,用降质和增强的图像对,结合 L1 Loss 和 SSIM Loss ,让网络学会对结构信息进行恢复和保护。同时引入 DCT Loss,对处理后图像的 DCT 高频能量进行约束,使其尽可能出现更多的零系数,减少非零系数。这样做的目的之一是减少视觉不敏感的细碎纹理信息,二是适配传统的 DCT 变换编码器,从而降低码率。使用该方法训练好神经网络之后,可以直接运用在各类传统编码器之前,都能取得 15%的码率节省。

回顾一下这个过程,我们刚开始并没有在神经网络结构上做努力,因为从原理上还不能推导出神经网络的结构优化与降低码率之间的联系。但是原理告诉我们引入更多和系统相关的先验条件,一定可以降低码率,因此我们仅仅利用 Loss 函数和训练策略的设计就实现了码率的降低。
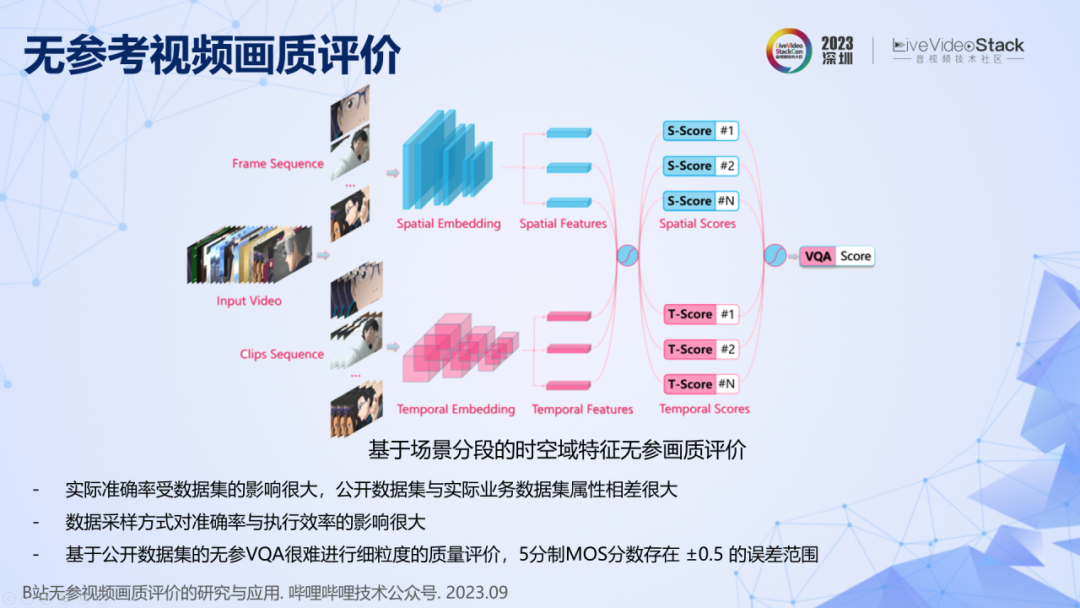
最后再介绍两个工作。无参考视频画质评价,已经上线了一个模型,用于检测大盘的视频画质,但我们发现用其来指导转码还存在一些问题。分享三个发现,一是无参 VQA 实际准确率受数据集的影响很大,公开数据集与实际业务数据集属性相差很大,直接将开源模型用在实际业务中,准确率不高。二是视频数据的时空域采样方式对准确率和执行效率的影响很大,在实际系统中,需要进行仔细的设计。三是基于公开数据集的无参 VQA 很难进行细粒度的质量评价,我理解这是因为人眼本身就存在不确定性,不同的人对同一个视频的评价不同,即使同一个人在不同时间对同一个视频的评价也会有差异,所以 5 分制 MOS 分数本身就存在超过±0.5 的误差。
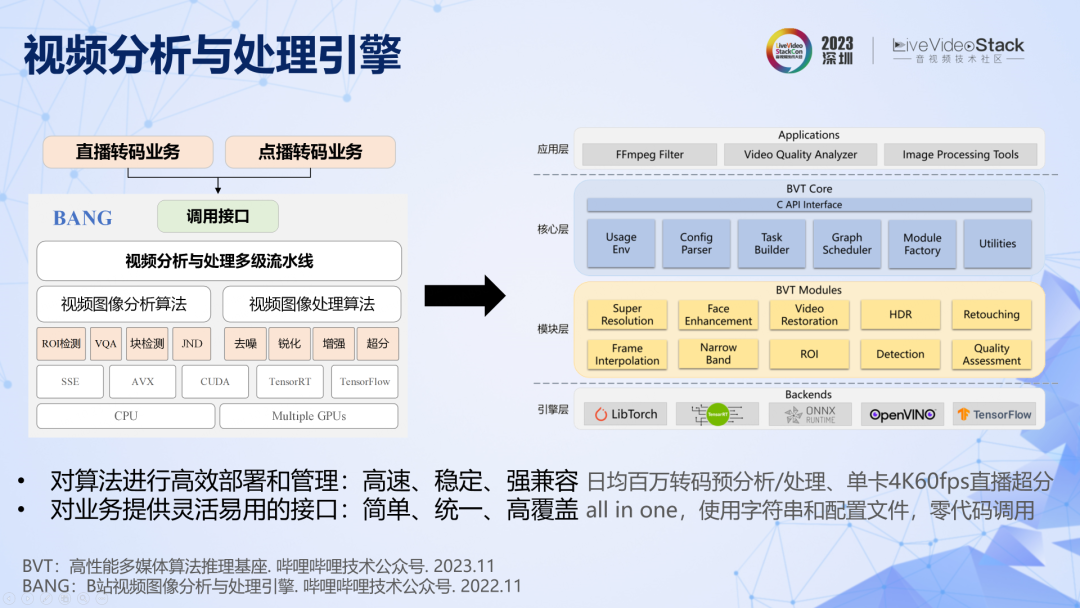
另外,为了让算法能够快速部署和高效执行,我们开发了一套强大的视频分析与处理引擎,最近已经升级到第二代了。
今天分享就到这里,感谢大家!
审核编辑:黄飞
-
视频编码
+关注
关注
2文章
116浏览量
21625 -
视频转码
+关注
关注
0文章
14浏览量
7714
原文标题:B站蔡春磊:转码系统究竟在优化什么?
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Altium Designer Cadence 格式转码
如何使用API提交转码任务?
【MPS最佳实践】媒体工作流转码
音视频转码技术指南:国内主流云转码服务提供商对比测评
如何在视频工程中使用转码技术?
视频转码技术与系统要求相匹配
阿里云视频点播转码多场景化最佳实践

转码技术在视频领域内的应用分析
linux系统支持硬件转码,真正告别GPU+CPU转码时代
如何在视频领域使用转码技术,有何优势
如何使用转码配合存储实现内容的分发?
车载DSP数字音频转码器数字界面光纤同轴板




评论