 CPU程序几个优化程序性能的手段详解
CPU程序几个优化程序性能的手段详解

作者:MegEngine
一个程序首先要保证正确性,在保证正确性的基础上,性能也是一个重要的考量。要编写高性能的程序,第一,必须选择合适的算法和数据结构;第二,应该编写编译器能够有效优化以转换成高效可执行代码的源代码,要做到这一点,需要了解编译器的能力和限制;第三,要了解硬件的运行方式,针对硬件特性进行优化。本文着重展开第二点和第三点。
简单认识编译器
要写出高性能的代码,首先需要对编译器有基础的了解,原因在于现代编译器有很强的优化能力,但有些代码编译器不能进行优化。对编译器有了基础的了解,才能写出编译器友好型高性能代码。
编译器的优化选项
以GCC为例,GCC 支持以下优化级别:
-O
-Ofast,除了开启 -O3 的所有优化选项外,会额外打开 -ffast-math 和 -fallow-store-data-races。注意这两个选项可能会引起程序运行错误。
-ffast-math: Sets the options-fno-math-errno,-funsafe-math-optimizations,-ffinite-math-only,-fno-rounding-math,-fno-signaling-nans,-fcx-limited-rangeand-fexcess-precision=fast. It can result in incorrect output for programs that depend on an exact implementation of IEEE or ISO rules/specifications for math functions. It may, however, yield faster code for programs that do not require the guarantees of these specifications.
-fallow-store-data-races: Allow the compiler to perform optimizations that may introduce new data races on stores, without proving that the variable cannot be concurrently accessed by other threads. Does not affect optimization of local data. It is safe to use this option if it is known that global data will not be accessed by multiple threads.
-Og,调试代码时推荐使用的优化级别。
gcc -Q --help=optimizer -Ox 可查看各优化级别开启的优化选项。 参考链接:https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
编译器的限制
为了保证程序运行的正确性,编译器不会对代码的使用场景做任何假设,所以有些代码编译器不会进行优化。下面举两个比较隐晦的例子。 1、memory aliasing
void twiddle1(long *xp, long *yp) {
*xp += *yp;
*xp += *yp;
}
void twiddle2(long *xp, long *yp) {
*xp += 2 * *yp;
}
当xp和yp指向同样的内存(memory aliasing)时,twiddle1和twiddle2是两个完全不同的函数,所以编译器不会尝试将twiddle1优化为twiddle2。如果本意是希望实现twiddle2的功能,应该写成twiddle2而非twwidle1的形式,twiddle2只需要 2 次读 1 次写,而twiddle1需要 4 次读 2 次写。 可以显式使用__restrict修饰指针,表明不存在和被修饰的指针指向同一块内存的指针,此时编译器会将twiddle3优化为和twiddle2等效。可自行通过反汇编的方式观察汇编码进一步理解。
void twiddle3(long *__restrict xp, long *__restrict yp) {
*xp += *yp;
*xp += *yp;
}
2、side effect
long f();
long func1() {
return f() + f() + f() + f();
}
long func2() {
return 4 * f();
}
由于函数f的实现可能如下,存在side effect,所以编译器不会将func1优化为func2。如果本意希望实现func2版本,则应该直接写成func2的形式,可减少 3 次函数调用。
long counter = 0;
long f() {
return counter++;
}
程序性能优化
在介绍之前,我们先引入一个程序性能度量标准每元素的周期数(Cycles Per Element, CPE),即每处理一个元素需要花费的周期数,可以表示程序性能并指导性能优化。 下面通过一个例子介绍几个优化程序性能的手段。首先定义一个数据结构 vector 以及一些辅助函数,vector 使用一个连续存储的数组实现,可通过typedef来指定元素的数据类型data_t。
typedef struct {
long len;
data_t *data;
} vec_rec, *vec_ptr;
/* 创建vector */
vec_ptr new_vec(long len) {
vec_ptr result = (vec_ptr)malloc(sizeof(vec_rec));
if (!result)
return NULL;
data_t *data = NULL;
result->len = len;
if (len > 0) {
data = (data_t*)calloc(len, sizeof(data_t));
if (!data) {
free(result);
return NULL;
}
}
result->data = data;
return result;
}
/* 根据index获取vector元素 */
int get_vec_element(vec_ptr v, long index, data_t *dest) {
if (index < 0 || index >= v->len)
return 0;
*dest = v->data[index];
return 1;
}
/* 获取vector元素个数 */
long vec_length(vec_ptr v) {
return v->len;
}
下面的函数的功能是使用某种运算,将一个向量中所有的元素合并为一个元素。下面的IDENT和OP是宏定义,#define IDENT 0和#define OP +进行累加运算,#define IDENT 1和#define OP *则进行累乘运算。
void combine1(vec_ptr v, data_t *dest) {
long i;
*dest = IDENT;
for (i = 0; i < vec_length(v); i++) {
data_t val;
get_vec_element(v, i, &val);
*dest = *dest OP val;
}
}
对于上面的combine1,可以进行下面三个基础的优化。 1、对于多次执行返回同样结果的函数,使用临时变量保存 combine1的实现在循环测试条件中反复调用了函数vec_length,在此场景下,多次调用vec_length会返回同样的结果,所以可以改写为combine2的实现进行优化。在极端情况下,注意避免反复调用返回同样结果的函数是更有效的。例如,若在循环结束条件中调用测试一个字符串长度的函数,该函数时间复杂度通常是O(n),若明确字符串长度不会变化,反复调用会有很大的额外开销。
void combine2(vec_ptr v, data_t *dest) {
long i;
long length = vec_length(v);
*dest = IDENT;
for (i = 0; i < length; i++) {
data_t val;
get_vec_element(v, i, &val);
*dest = *dest OP val;
}
}
2、减少过程调用 过程(函数)调用会产生一定的开销,例如参数传递、clobber 寄存器保存恢复和转移控制等。所以可以新增一个函数get_vec_start返回指向数组的开头的指针,在循环中避免调用函数get_vec_element。这个优化存在一个 trade off,一方面可以一定程序提升程序性能,另一方面这个优化需要知道 vector 数据结构的实现细节,会破坏程序的抽象,一旦 vector 修改为不使用数组的方式存储数据,则同时需要修改combine3的实现。
data_t *get_vec_start(vec_ptr v) {
return v->data;
}
void combine3(vec_ptr v, data_t *dest) {
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
*dest = IDENT;
for (i = 0; i < length; i++) {
*dest = *dest OP data[i];
}
}
3、消除不必要的内存引用 在上面的实现中,循环中每次都会去读一次写一次dest,由于可能存在memory aliasing,编译器会谨慎地进行优化。下面分别是-O1和-O2优化级别时,combine3中for循环部分的汇编代码。可以看到,开启 -O2 优化时,编译器帮我们把中间结果存到了临时变量中(寄存器 % xmm0),而不是像 -O1 优化时每次从内存中读取;但是考虑到memory aliasing的情况,即使 -O2 优化,依然需要每次循环将中间结果保存到内存。
// combine3 -O1
.L1:
vmovsd (%rbx), %xmm0
vmulsd (%rdx), %xmm0, %xmm0
vmovsd %xmm0, (%rbx)
addq $8, %rdx
cmpq %rax, %rdx
jne .L1
// combine3 -O2
.L1
vmulsd (%rdx), %xmm0, %xmm0
addq $8, %rdx
cmpq %rax, %rdx
vmovsd %xmm0, (%rbx)
jne .L1
为了避免频繁进行内存读写,可以人为地使用一个临时变量保存中间结果,如combine4所示。
void combine4(vec_ptr v, data_t *dest) {
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
data_t acc = IDENT;
for (i = 0; i < length; i++) {
acc = acc OP data[i];
}
*dest = acc;
}
// combine4 -O1
.L1
vmulsd (%rdx), %xmm0, %xmm0
addq $8, %rdx
cmpq %rax, %rdx
jne .L1
以上优化方法的效果可以通过 CPE 来度量,在 Intel Core i7 Haswell 的测试结果如下。从测试结果来看:
combine1 版本不同编译优化级别,-O1 的性能是 -O0 的两倍,表明开启适当地编译优化级别是很有必要的。
combine2 将 vec_length 移出循环后,在同样的优化级别编译,相较 combine1 的性能有微小的提升。
但是 combine3 相比 combine2 并没有性能提升,原因是由于循环中的其它操作的耗时可以掩盖调用 get_vec_element 的耗时,之所以可以掩盖,得益于 CPU 支持分支预测和乱序执行,本文的后面会简单介绍这两个概念。
同样地,combine3 的 -O2 版本比 -O1 版本性能好很多,从汇编码可以看到,-O2 时比 -O1 每次循环减少了一次对 (% rbx) 的读,更重要的是消除了对 (% rbx) 写后读的访存依赖。
经过 combine4 将中间结果暂存到临时变量的优化,可以看到即使使用 -O1 的编译优化,也比 combine3 -O2 的编译优化性能更好,表明即使编译器有强大的优化能力,但是注意细节来编写高性能代码也是非常有必要的。
以下测试数据引用自《深入理解计算机系统》第五章。
| 函数 | 优化方法 | int + | int * | float + | float * |
|---|---|---|---|---|---|
| combine1 | -O0 | 22.68 | 20.02 | 19.98 | 20.18 |
| combine1 | -O1 | 10.12 | 10.12 | 10.17 | 11.14 |
| combine2 | 移动 vec_length -O1 | 7.02 | 9.03 | 9.02 | 11.03 |
| combine3 | 减少过程调用 -O1 | 7.17 | 9.02 | 9.02 | 11.03 |
| combine3 | 减少过程调用 -O2 | 1.60 | 3.01 | 3.01 | 5.01 |
| combine4 | 累积到临时变量 -O1 | 1.27 | 3.01 | 3.01 | 5.01 |
指令级并行
以上优化不依赖于目标机器的任何特性,只是简单地降低了过程调用的开销,以及消除一些 “妨碍优化的因素”,这些因素会给编译器优化带来困难。要进行进一步优化,需要了解一些硬件特性。下图是 Intel Core i7 Haswell 的硬件结构的后端部分: 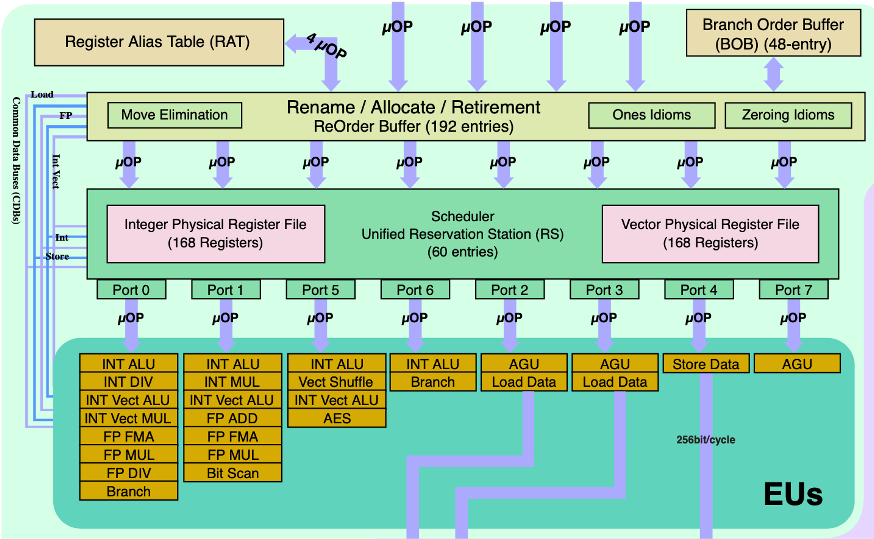
完整的 Intel Core i7 Haswell 的硬件结构见:https://en.wikichip.org/w/images/c/c7/haswell_block_diagram.svg
硬件性能
该 CPU 支持以下特性:
指令级并行:即通过指令流水线技术,支持同时对多条指令求值。
乱序执行:指令的执行顺序未必和其书写的顺序一致,可以使硬件达到更好的指令级并行度。主要是通过乱序执行、顺序提交的机制,使得能够获得和顺序执行一致的结果。
分支预测:当遇到分支时,硬件会预测分支的走向,如果预测成功则能够加快程序的运行,但是预测失败的话则需要把提前执行的结果丢弃,重新 load 正确指令执行,会带来比较大的预测错误惩罚。
上图中,主要关注执行单元 (EUs),执行单元由多个功能单元组成。功能单元的性能可以由延迟、发射时间和容量来度量。
延迟:执行完一条指令需要的时钟周期数。
发射时间:两个连续的同类型的运算之间需要的最小时钟周期数。
容量:某种执行单元的数量。从上图可以看出,在EUs中,有 4 个整数加法单元 (INT ALU)、1 个整数乘法单元 (INT MUL)、1 个浮点数加法单元 (FP ADD) 和 2 个浮点数乘法单元 (FP MUL)。
Intel Core i7 Haswell 的功能单元性能数据(单位为周期数)如下,引自《深入理解计算机系统》第五章:
| 运算 | 延迟 (int) | 发射时间 (int) | 容量 (int) | 延迟 (float) | 发射时间 (float) | 容量 (float) |
|---|---|---|---|---|---|---|
| 加法 | 1 | 1 | 4 | 3 | 1 | 1 |
| 乘法 | 3 | 1 | 1 | 5 | 1 | 2 |
这些算术运算的延迟、发射时间和容量会影响上述combine函数的性能,我们用 CPE 的两个界限来描述这种影响。吞吐界限是理论上的最优性能。
延迟界限:任何必须按照严格顺序完成combine运算的函数所需要的最小 CPE,等于功能单元的延迟。
吞吐界限:功能单元产生结果的最大速率,由容量/发射时间决定。若使用 CPE 度量,则等于容量/发射时间的倒数。
由于combine函数需要 load 数据,故要同时受到加载单元的限制。由于只有两个加载单元且其发射时间为 1 个周期,所以整数加法的吞吐界限在本例中只有 0.5 而非 0.25。
| 界限 | int + | int * | float + | float * |
|---|---|---|---|---|
| 延迟 | 1.0 | 3.0 | 3.0 | 5.0 |
| 吞吐 | 0.5 | 1.0 | 1.0 | 0.5 |
处理器操作的抽象模型
为了分析在现代处理器上执行的机器级程序的性能,我们引入数据流图,这是一种图形化表示方法,展现了不同操作之间的数据相关是如何限制它们的执行顺序的。这些限制形成了图中的关键路径,这是执行一组机器指令所需时钟周期的一个下界。 通常 for 循环会占据程序执行的大部分时间,下图是combine4的 for 循环对应的数据流图。其中箭头指示了数据的流向。可以将寄存器分为四类:
只读:这些寄存器只用作源值,在循环中不被修改,本例中的%rax。
只写:作为数据传送的目的。本例没有这样的寄存器。
局部:在循环内部被修改和使用,迭代与迭代之间不相关,比例中的条件码寄存器。
循环:这些寄存器既作为源值,又作为目的,一次迭代中产生的值会被下一次迭代用到,本例中的%rdx和%xmm0。由于两次迭代之间有数据依赖,所以对此类寄存器的操作通常是程序性能的限制因素。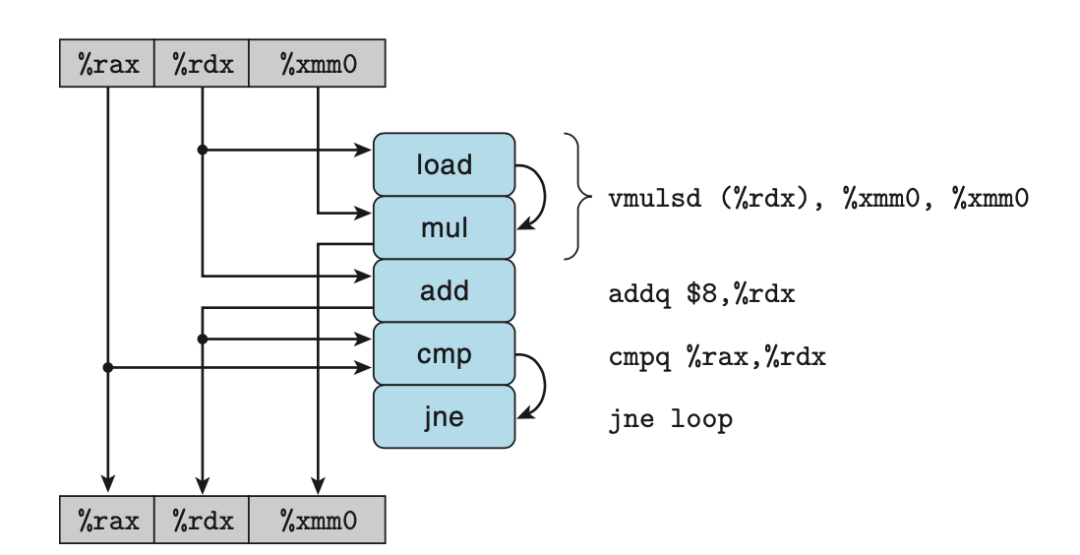
将上图重排,并只留下循环寄存器相关的路径,可得到简化的数据流图。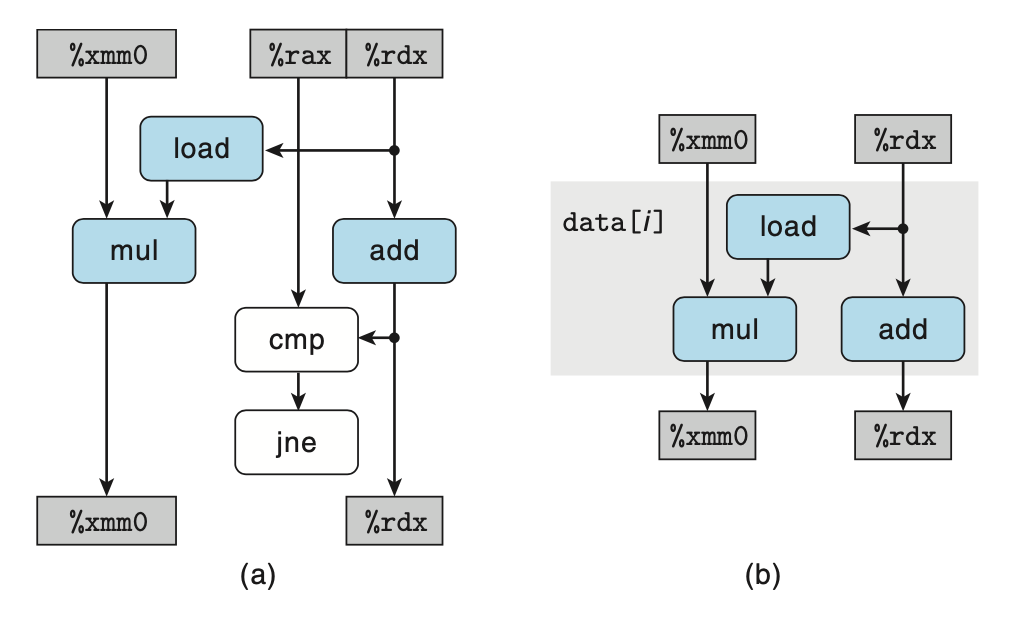 将简化完的数据流图进行简单地重复,可以得到关键路径,如下图。如果 combine4 中计算的是浮点数乘法,由于支持指令级并行,浮点数乘法的的延迟能够掩盖整数加法 (指针移动,图中右半边的路径) 的延迟,所以 combine4CPE 的理论下界就是浮点乘法的延迟 5.0,与上面给出的测试数据 5.01 基本一致。
将简化完的数据流图进行简单地重复,可以得到关键路径,如下图。如果 combine4 中计算的是浮点数乘法,由于支持指令级并行,浮点数乘法的的延迟能够掩盖整数加法 (指针移动,图中右半边的路径) 的延迟,所以 combine4CPE 的理论下界就是浮点乘法的延迟 5.0,与上面给出的测试数据 5.01 基本一致。 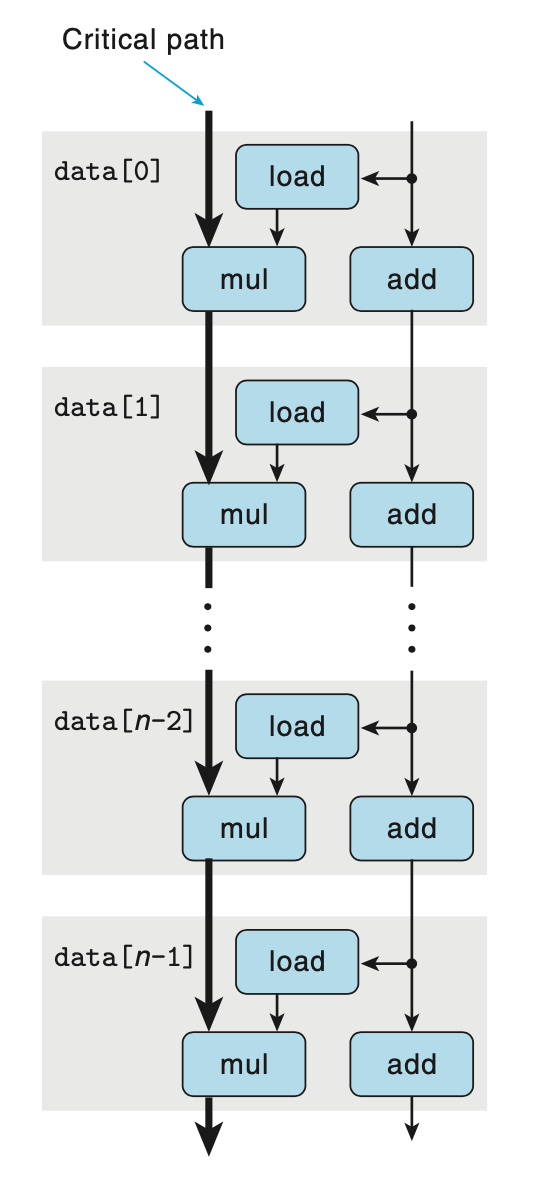
循环展开
目前为止,我们程序的性能只达到了延迟界限,这是因为下一次浮点乘法必须等上一次乘法结束后才开始,不能充分利用硬件的指令级并行。使用循环展开的技术,可以提高关键路径的指令并行度。
void combine5(vec_ptr v, data_t *dest) {
long i;
long length = vec_length(v);
long limit = length - 1;
data_t *data = get_vec_start(v);
data_t acc0 = IDENT;
data_t acc1 = IDENT;
for (i = 0; i < limit; i += 2) {
acc0 = acc0 OP data[i];
acc1 = acc1 OP data[i + 1];
}
for (; i < length; ++i) {
acc0 = acc0 OP data[i];
}
*dest = acc0 OP acc1;
}
combine5的关键路径的数据流图如下,图中有两条关键路径,但两条关键路径是可以指令级并行的,每条关键路径只包含n/2个操作,因此性能可以突破延迟界限,理论上浮点乘法的 CPE 约为5.0/2=2.5。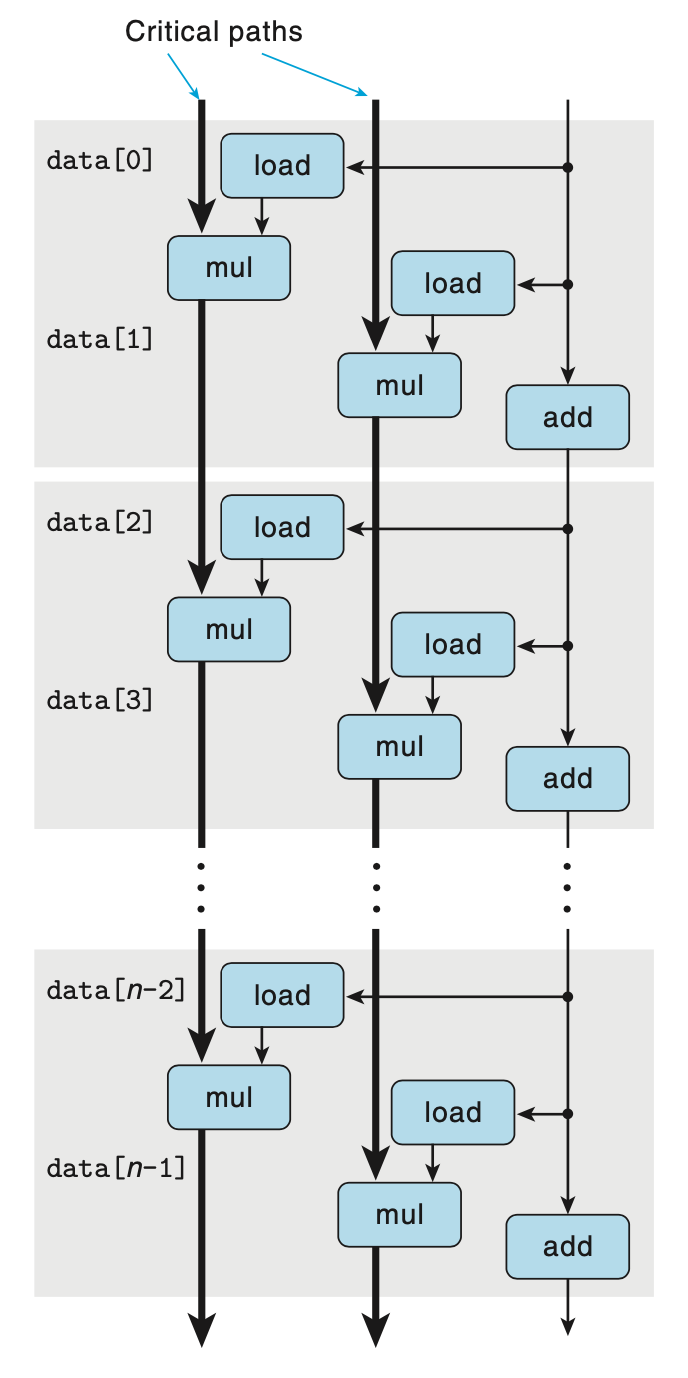 假如增加临时变量的个数进一步增加循环展开次数,理论上可以提高指令并行度,最终达到吞吐界限。但是不能无限制地增加循环展开次数,一是由于硬件的功能单元有限,CPE 的下界由吞吐界限限制,达到一定程度后继续增加也不能提高指令并行度;二是由于寄存器资源有限,增加循环展开次数会增加寄存器的使用,使用的寄存器个数超过硬件提供的寄存器资源之后,则会发生寄存器溢出,可能会需要将寄存器的内存临时保存到内存,使用时再从内存恢复到寄存器,反而导致性能的下降,如下表中循环展开 20 次相较展开 10 次性能反而略有下降。幸运的是,大多数硬件在寄存器溢出之前已经达到了吞吐界限。
假如增加临时变量的个数进一步增加循环展开次数,理论上可以提高指令并行度,最终达到吞吐界限。但是不能无限制地增加循环展开次数,一是由于硬件的功能单元有限,CPE 的下界由吞吐界限限制,达到一定程度后继续增加也不能提高指令并行度;二是由于寄存器资源有限,增加循环展开次数会增加寄存器的使用,使用的寄存器个数超过硬件提供的寄存器资源之后,则会发生寄存器溢出,可能会需要将寄存器的内存临时保存到内存,使用时再从内存恢复到寄存器,反而导致性能的下降,如下表中循环展开 20 次相较展开 10 次性能反而略有下降。幸运的是,大多数硬件在寄存器溢出之前已经达到了吞吐界限。
| 函数 | 展开次数 | int + | int * | float + | float * |
|---|---|---|---|---|---|
| combine5 | 2 | 0.81 | 1.51 | 1.51 | 2.51 |
| combine5 | 10 | 0.55 | 1.00 | 1.01 | 0.52 |
| combine5 | 20 | 0.83 | 1.03 | 1.02 | 0.68 |
| 延迟界限 | / | 1.00 | 3.00 | 3.00 | 5.00 |
| 吞吐界限 | / | 0.50 | 1.00 | 1.00 | 0.50 |
SIMD(single instruction multi data)
SIMD是另外一种行之有效的性能优化手段,不同于指令级并行,其采用数据级并行。SIMD 即单指令多数据,一条指令操作一批向量数据,需要硬件提供支持。X86 架构的 CPU 支持 AVX 指令集,ARM CPU 支持 NEON 指令集。在我们开发的一款深度学习编译器 MegCC 中,就广泛使用了 SIMD 技术。MegCC 是旷视天元团队开发的深度学习编译器,其接受 MegEngine 格式的模型为输入,输出运行该模型所需的所有 kernel,方便模型部署,具有高性能和轻量化的特点。为了方便用户将其它格式的模型转换为 MegEngine 格式模型,旷视天元团队同时提供了模型转换工具 MgeConvert,您可以将模型转换为onnx,然后使用 MgeConvert 转换为 MegEngine 格式模型。同时如果您想测试您设备上某条指令的吞吐和延迟,以指导您的优化,可以使用 MegPeak。 MegCC 中实现了许多高性能的深度学习算子,卷积和矩阵乘法是典型的计算密集型的算子,同时卷积也可以借助矩阵乘法来实现 (im2col/winograd 算法等)。 MegCC 在 ARM 平台支持了 NEON DOT 和 I8MM 指令实现的矩阵乘和卷积。一条DOT指令可完成 32 次乘加运算 (16 次乘法和 16 次加法运算);一条I8MM指令可完成 64 次乘加运算 (32 次乘法和 32 次加法运算)。这就是 SIMD 技术能够加速计算的原理。
编辑:黄飞
-
处理器
+关注
关注
68文章
20339浏览量
255248 -
寄存器
+关注
关注
31文章
5620浏览量
130444 -
cpu
+关注
关注
68文章
11332浏览量
225952 -
函数
+关注
关注
3文章
4422浏览量
67863 -
编译器
+关注
关注
1文章
1673浏览量
51941
原文标题:CPU程序性能优化
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
《现代CPU性能分析与优化》--读书心得笔记
XScale 应用程序性能的优化策略
快速识别应用程序性能瓶颈
DVFS对程序性能影响模型
7个好习惯快速提升Python程序性能

了解 LabVIEW 程序运行性能的关键因素
了解CPI对分析程序性能的意义
LabVIEW应用程序中性能瓶颈的解决
第6代光纤通道:加速全闪存数据中心的数据访问和应用程序性能

使用Brocade Gen 7 SAN确保应用程序性能和可靠性



评论