 NIO的自动驾驶AI推理工作流
NIO的自动驾驶AI推理工作流

自动驾驶汽车必须能够快速准确地检测物体,以确保其驾驶员和道路上其他驾驶员的安全。由于自动驾驶( AD )和视觉检查用例中对实时处理的需求,具有预处理和后处理逻辑的多个 AI 模型 组合在流水线中,并用于 机器学习( ML )推理。
流水线的每一步都需要加速,以确保低延迟工作流。延迟是获取推理响应所需的时间。更快地处理 AD 数据将能够更有效地分析和使用信息,创造更安全的驾驶环境。任何一个方面的延迟都会降低整个管道的速度。
为了实现低延迟推理工作流,电动汽车制造商 NIO 将 NVIDIA Triton 推理服务器集成到其 AD 推理管道中。 NVIDIA Triton 推理服务器是一个开源的多帧推理服务软件。
这篇文章解释了 NIO 如何在 GPU 上使用 NVIDIA Triton 协调其图像预处理、后处理和 AI 模型的管道。它还展示了 NIO 如何减少网络传输,以成功加快 AD 用例的 AI 推理工作流。
用于实时响应的更快 AI 推理
NIO 设计、开发、联合制造和销售高级智能电动汽车,推动自动驾驶、数字技术、电动动力系统和电池等新一代技术的创新。 NIO 自动驾驶开发平台( NADP )是一个致力于 NIO 核心自动驾驶服务的研发平台。
NIO 选择 NVIDIA Triton Inference Server 是因为几个关键的技术和操作原因,包括:
NVIDIA Triton 支持基于 DAG 的多种模型编排,以及预处理或后处理模块
NVIDIA Triton 的云原生部署实现了多 GPU 、多节点的轻量级扩展
高质量的文档和学习资源有助于轻松迁移到 NVIDIA Triton
NVIDIA Triton 的稳定性和强大功能是 AD 用例所必需的
NIO 的自动驾驶 AI 推理工作流
数百个人工智能模型用于从自动驾驶汽车中挖掘数据。在自动驾驶这样的用例中,推理工作流由多个 AI 模型组成,其中预处理和后处理逻辑在流水线中拼接在一起。
NIO 将管道的预处理和后处理从运行在 CPU 上的客户端移动到运行在 GPU 上的 NVIDIA Triton 。 NVIDIA Triton 的业务逻辑脚本( BLS )功能用于协调管道,以优化 AD 使用。
通过将预处理从 CPU 移动到 GPU 并利用高效的管道编排, NIO 在一些核心管道中实现了 6 倍的延迟减少,将总吞吐量提高了 5 倍。
工作流管道之前和之后如图 1 所示。
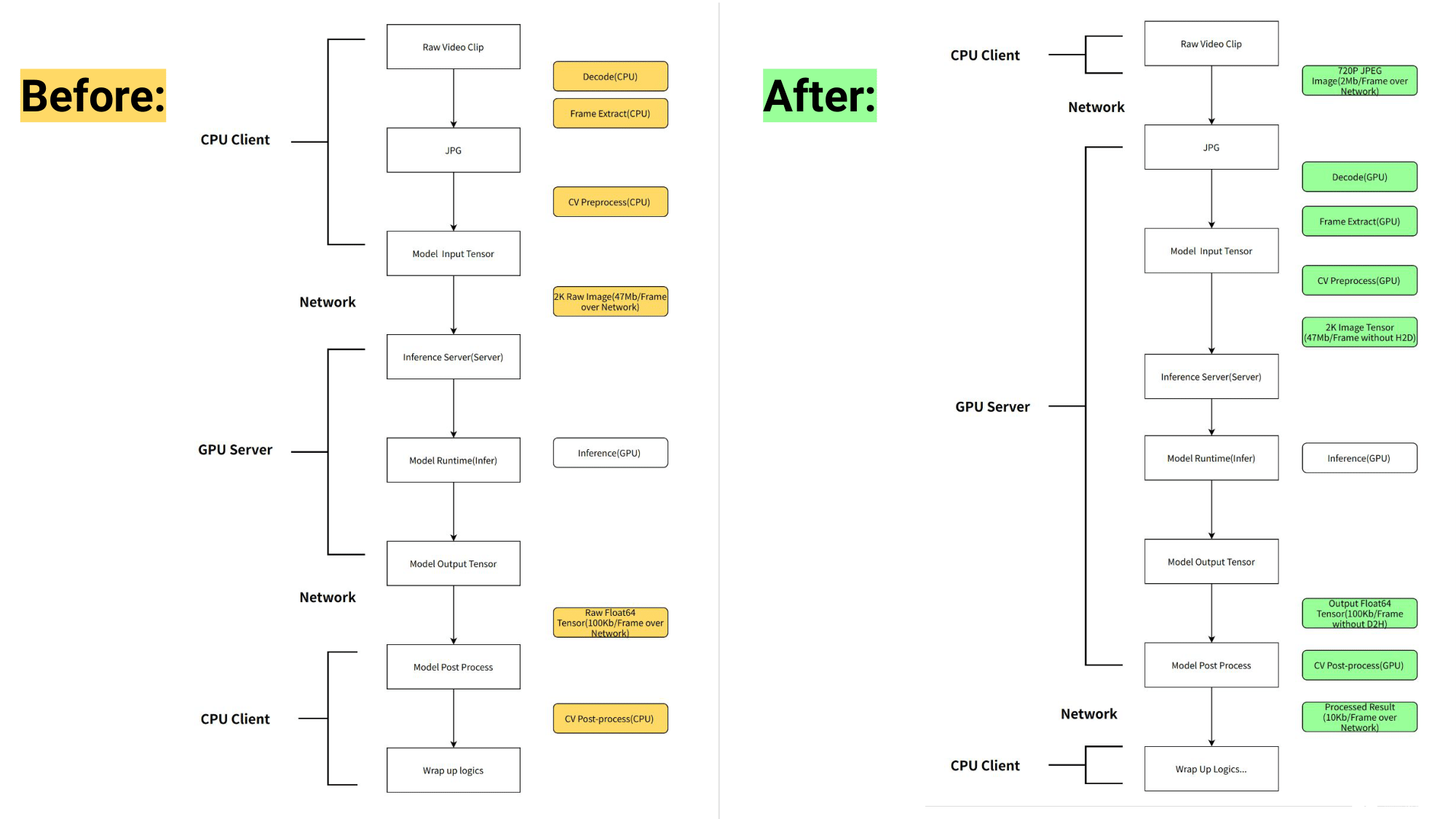
图 1. NVIDIA Triton 推理服务器推出之前(左)和之后(右) NIO AI 推理工作流的比较
NVIDIA Triton 的模型管道编排优势
本节探讨了 NIO 通过集成 NVIDIA Triton 实现的每一项好处。
GPU 加速预处理
NVIDIA Triton 使用 nvJPEG 和 NVIDIA DALI 在 GPU 上加速了解码、调整大小和换位等预处理任务。这显著减轻了客户端 CPU 的计算工作量,并减少了预处理延迟。
升级模型而无需修改客户端应用程序
通过将模型的预处理和后处理移至 NVIDIA Triton ,每次升级模型时,客户端不需要任何修改。这实质上加快了模型的推出,帮助其更快地达到生产。
使用单个 GPU 节点减少网络数据传输开销
统一的预处理使输入的多个副本能够与多个后端识别模型共享。该过程在服务器端使用 GPU 共享内存,无需数据传输开销。
图 2 显示了该管道可以使用 NVIDIA Triton 业务逻辑脚本功能连接多达九个模型。
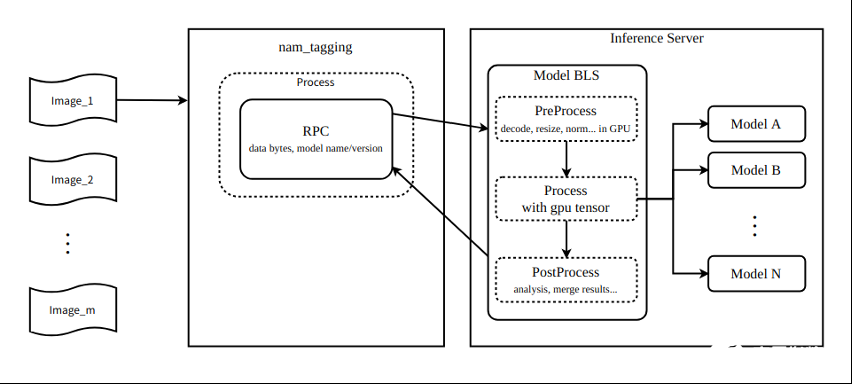
图 2. NVIDIA Triton 业务逻辑脚本的模型管道编排
对于 2K 分辨率的输入图像,每帧的大小为 1920 x 1080 x 3 x 8 = 47 Mb 。假设全帧速率为 60 fps ,每秒输入的数据量为 1920 x 1080 x 3 x 8 x 60 = 2847 Mb 。在前一个工作流中,每个图像通过网络依次发送给九个模型。每秒传输的数据为 1920 x 1080 x 3 x 8 x 60 x 9 = 25 Gb = 3 Gb 。
在新的工作流程中,九个模型与 NVIDIA Triton 业务逻辑脚本配合。这意味着模型可以访问 GPU 共享存储器中的图像,并且图像不必通过网络发送。假设 PCIe 带宽为 160 Gb =每秒 20 Gb ,理论上,如果通过 PCIe 传输数据,每秒生成的数据可以节省 150 毫秒的数据传输时间。
假设可用带宽为 16 Gb =每秒 2 Gb ,理论上,如果数据通过网络传输,每秒生成的数据可以节省 1500 毫秒的数据传输时间。所有这些都会加快工作流程。
使用图像压缩节省网络传输
为了进行准确的模型预测,输入图像必须为 1920 x 1080 x 3 x 8 字节,并且必须通过网络传输。在引入服务器端预处理之后,可以在允许的精度损失范围内将原始图像更改为压缩的三通道 720 像素图像( 1280 x 720 x 3 )。
因此,只需几百 KB 即可传输压缩图像的字节,并在服务器上以最小的精度损失将大小调整为 1920 x 1080 x 3 x 8 字节。这导致了额外的网络传输节省,加快了工作流程。
NADP 推理平台中的易集成性
NIO 目前基于 NVIDIA Triton 的推理平台是其自动驾驶开发平台( NADP )的关键组件,用于其自动驾驶解决方案。
由于 NIO 平台构建在 Kubernetes ( K8s )上, NVIDIA Triton 必须与 Kubernete 良好集成。工作流程的组件围绕 NVIDIA Triton 实现为 K8s CRD (本地和自定义)。
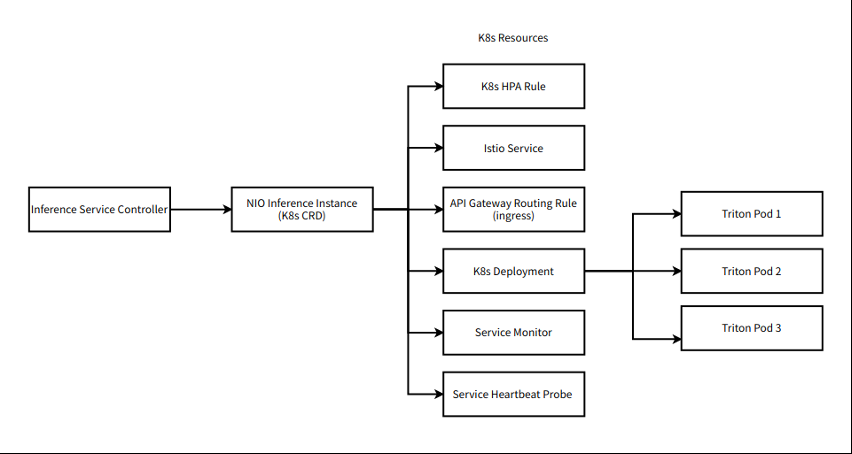
图 3.NIO 在 Kubernetes 中的机器学习工作流
持续集成/持续交付( CI / CD )
Argo 是 Kubernetes 中用于协调工作流的引擎。它有助于开发、量化、访问、云部署、压力测试和发布中涉及的所有组件的 CI / CD 。 NVIDIA Triton 通过在加载模型时触发工作流中的下一步来帮助 CI / CD 。
此外, NVIDIA Triton Docker 容器的使用有助于在开发、测试和部署环境中实现一致的功能。
将 Jupyter 环境无缝集成到 NVIDIA Triton 图像中。 Jupyter 为需要在线调试或离线复制的复杂问题提供了一个方便的开发环境。
易用 Istio 部署
NVIDIA Triton 本机支持与应用程序通信的 gRPC 协议。然而,由于 Kubernetes 本地服务无法为 gRPC 提供有效的请求级负载平衡, NVIDIA Triton 与 Istio 服务网格集成。 Istio 用于对 NVIDIA Triton 推理服务器的流量进行负载平衡,并通过 NVIDIA Triton 的活跃度/就绪性探针监测服务的运行状况。
阿波罗配置管理易于使用
阿波罗配置中心用于基于模型名称的服务发现。用户可以访问模型,而不知道模型部署的特定域名。结合 NVIDIA Triton 模型存储库,用户可以直接触发模型的部署。
普罗米修斯和格拉法纳的指标
NVIDIA Triton 基于模型维度提供了一整套模型服务指标。例如, NVIDIA Triton 可以区分推理请求排队时间和 GPU 计算时间,从而实现在线模型服务性能的细粒度诊断和分析,而无需进入调试模式。
由于 NVIDIA Triton 支持云原生主流 Prometheus / Grafana ,用户可以轻松配置每个维度的仪表板和警报,为高服务可用性提供指标支持。
关键要点
NIO 的优化工作流程集成了 NVIDIA Triton 推理服务器,使一些核心管道的延迟减少了 6 倍。这将总吞吐量提高了 5 倍。
通过使用 NVIDIA Triton 管道编排功能将预处理逻辑移至 GPU , NIO 实现了:
更快的图像处理
释放 CPU 容量
减少网络传输开销
更高的推理吞吐量
NIO 使用 NVIDIA Triton 推理服务器实现了 AI 推理工作流加速。 NVIDIA Triton 也很容易集成到基于 Kubernetes 的强大可扩展解决方案中。
-
NVIDIA
+关注
关注
14文章
5496浏览量
109110 -
AI
+关注
关注
89文章
38162浏览量
296857 -
自动驾驶
+关注
关注
791文章
14673浏览量
176634
发布评论请先 登录





 工商网监
工商网监
评论