 为AI推理打造高达24Gb/s的GDDR6 PHY,Rambus全面支持中国市场的AI升级
为AI推理打造高达24Gb/s的GDDR6 PHY,Rambus全面支持中国市场的AI升级

人工智能在通过大量的数据进行训练之后,神经网络打造的完整模型将被集成在边缘或实际应用场之中,往往大量的AI正是应用在于边缘AI推理。与AI训练需要大量的数据和算力不同,AI推理对算力的需求大幅下降,但对成本和功耗更为敏感。
在AI推理应用越来越多的趋势下,Rambus率先研判与推出GDDR6 IP产品组合。Rambus IP核产品营销高级总监Frank Ferro先生表示,作为更加理想的方案,GDDR6有着高带宽以及低时延的特性,能够帮助边缘端更好地处理数据。
Rambus GDDR6 PHY以及控制器的配套产品,已经达到了业界领先的24Gb/s的数据传输速率,这也是全新的一个行业标杆,可以为AI推理等应用场景带来巨大性能优势和收益。
除性能之外,另一大优势是对功耗的管理。因为当设备在高速和高带宽环境下运行时,良好的功耗管理非常重要。
还有系统层面的设计。如果要确保系统在24Gb/s环境下运行,需要良好的系统级信号完整性。Rambus信号完整性的工程师,也会与客户进行非常紧密的从设计初期开始的合作,能够确保客户运行系统的时候达到最高的性能。
另外,Rambus提供的产品已经实现了PHY以及控制器的完整集成。在客户收到产品之后,可以直接对这些子系统进行定制化应用。
GDDR6内存接口子系统的结构
下图的结构包括PHY物理层、控制器、DRAM以及客户端的ASIC。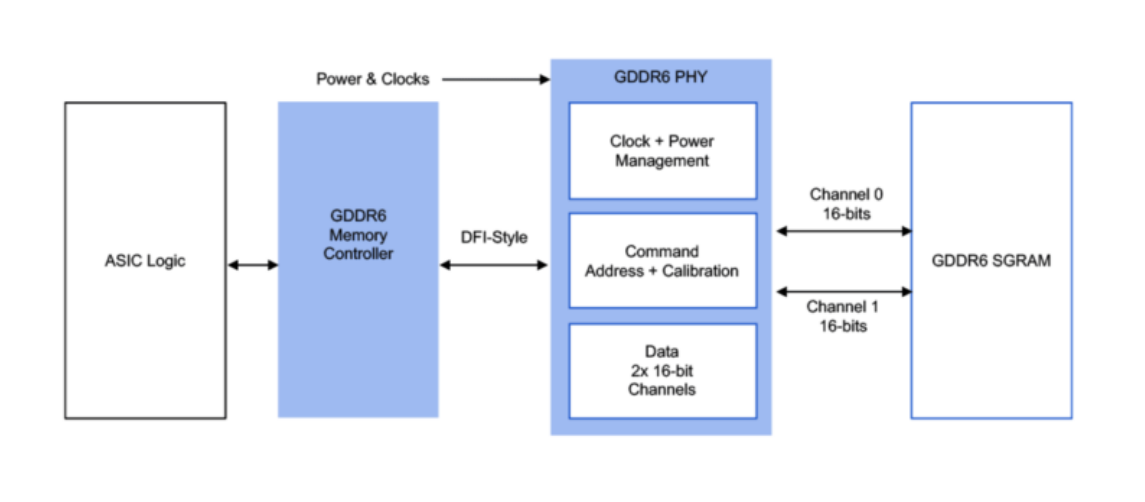
Frank Ferro解析,PHY的物理层与DRAM进行直接连接,这个接口是由两个16位的插槽所组成,加起来是32位。
另外一侧是DFI接口与内存的控制器进行连接,控制器直接接入到整个系统的逻辑控制。Rambus提供的是中间标蓝的两个非常重要的环节,也就是完整的子系统,Rambus会根据客户具体应用场景和实际的诉求对子系统来进行优化,并将其作为完整的子系统来交付给客户。
GDDR的“G”代表的是graphic (图形),因此它可以用于图形处理,同时也可以用于人工智能以及机器学习算法中,以及网络应用等。
在GDDR6拥有的诸多特点中,值得一提的是clamshell模式,具体指的是每个信道可以支持两个GDDR6的设备。换句话说,在clamshell模式之下整个容量是直接翻倍乘以2的。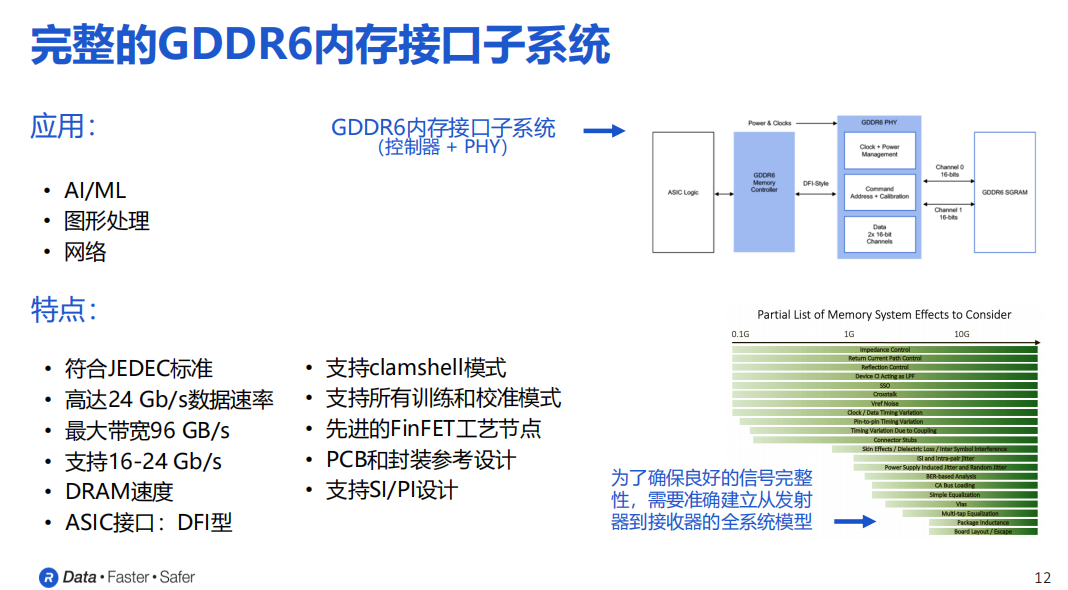
另外,GDDR6现在已经支持比较先进的FinFET工艺节点,实际上从2019年开始Rambus就已经支持非常先进的制程工艺。
同时,也会针对PCB以及封装提供相关的参考设计。在内部有专门的信号完整度和边缘完整性的专家,来帮助客户去完成整个的设计工作。
Frank Ferro表示,Rambus的GDDR6接口子系统可以实现高达24Gb/s的卓越性能,可以为每个GDDR6内存设备提供最高达到96Gb/s的带宽。GDDR6是在AI应用场景下比较合理的产品和选择,因为可以在成本和性能之间达成不错的平衡。
边缘AI推理,GDDR6是更合适的选择
实际上内存的形式有很多种,DDR、LPDDR、GDDR以及HBM等,那么边缘AI推理用哪种内存最合适,在Frank Ferro看来GDDR6将是脱颖而出的那一个。
他说,GDDR6有着优秀的数据传输速率,可适用于很多AI推理场景。尤其在一些网络应用中,GDDR6能具有重要作用。“现在非常多的具体网络应用场景都已经开始在边缘端实现了。尤其是有的应用要求所有传入的数据必须在本地进行实时处理,这种需求的增加对本身产品架构的要求会很高。因此传统的DDR方案已经远远不能满足要求,因为需要有很多的DDR设备。而部署GDDR6在边缘设备,能够大幅度降低网络边缘设备对DDR数量的需求。”
一般来说,AI推理对带宽的需求在200到500Gb/s的范围之间。而每一个GDDR6设备的带宽可以达到96Gb/s,通过将4-5个GDDR6设备组合,就可以轻松满足500Gb/s及以下的带宽需求。
以DDR4为例,它的速度可能最高能达到3.2Gb/s。虽然它的成本相对较低,但是速度是一大劣势。GDDR技术在几年前就能够实现16Gb/s的带宽,已经超过DDR技术的三到四倍之多。当然,DDR、GDDR和LPDDR这些不同的产品都是以标准的DRAM为基础,LPDDR更关注低功耗管理,DDR本身的数据存储密度会更高一点,而GDDR是更关注于速度。
此外,如果用到一个HBM3设备就能够达到接近800Gb的带宽,但它会使得成本增加3至4倍。因此,对于对带宽和低延迟有很高要求的AI训练场景,HBM可能是更好的选择。而对于需要更大容量、更高带宽的AI推理场景,则GDDR6是更合适的选择。
全面的产品组合,满足中国客户不同的AI需求
Rambus作为一家业界领先的半导体IP和芯片供应商,技术实力强劲,拥有3000多项技术专利,企业使命是让数据传输更快、更安全。经过三十多年的发展和创新,Rambus现在的主要业务包含基础专利授权、芯片IP授权和内存接口芯片。Rambus的技术和产品面向的市场是数据密集型市场,包括数据中心、5G、物联网IoT、汽车等细分市场。其产品组合,与AIGC应用对数据传输的需求十分契合。

以ChatGPT为代表的AIGC应用热潮袭卷到中国,我们可以看到中国不少互联网大厂都发布了自己的AI大模型。那么Rambus如何支持中国客户的AI数据传输需求呢?
Rambus大中华区总经理苏雷先生长期投身中国市场,他表示Rambus在和芯片厂商的沟通中发现更多厂商聚焦于AI训练,因此他们的方案更多需求在于HBM;在与云厂商的沟通中,他们更多是关注数据中心推出的一系列产品,即中国式ChatGPT产品,他们需要更多的算力。在内存产品上,Rambus有非常好的接口芯片,向云厂商提供我们的服务和产品。

还有一类客户是中国的OEM和ODM厂商,他们把目光转向了当前非常新的技术CXL。因为CXL可以带来更多内存带宽和内存容量,所以我们正在紧密合作提供方案,以加大整个系统内存的带宽,帮助他们的产品推向市场。
苏雷说,Rambus China立足于中国市场,愿意更多、更紧密地支持中国公司在ChatGPT产业的发展,以最好的技术、最快的响应和最好的技术支持来服务中国市场,给广大客户保驾护航。
-
Rambus
+关注
关注
0文章
67浏览量
19344 -
PHY
+关注
关注
2文章
341浏览量
54327 -
GDDR6
+关注
关注
0文章
52浏览量
11625
发布评论请先 登录
高通挑战英伟达,发布768GB内存AI推理芯片,“出征”AI数据中心

高通挑战英伟达!发布768GB内存AI推理芯片,“出征”AI数据中心

华为星河AI园区网络登顶2025年中国市场榜首
弥合带宽缺口,高性能AI推理如何受益于GDDR7?

边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
OrangePi RV2 深度技术评测:RISC-V AI融合架构的先行者
使用NORDIC AI的好处
R480-X8面向下一代AI集群的高密度算力模块:技术架构与应用分析

昆仑芯R200 AI加速卡技术规格解析




评论