 【AI简报20230407期】 MLPref放榜!大模型时代算力领域“潜力股”浮出水面、CV或迎来GPT-3时刻
【AI简报20230407期】 MLPref放榜!大模型时代算力领域“潜力股”浮出水面、CV或迎来GPT-3时刻

嵌入式 AI
AI 简报 20230407 期
1. MLPref放榜!大模型时代算力领域“潜力股”浮出水面:梅开二度拿下世界第一,今年获双料冠军
原文:https://mp.weixin.qq.com/s/KJCIjhqClBzcqfi-qtJp-A
后ChatGPT时代下的大模型“算力难”问题,“快、好、省”的解法,又来了一个。
就在今天,享有“AI界奥运会”之称的全球权威AI基准评测MLPerf Inference v3.0,公布了最新结果——
来自中国的AI芯片公司,墨芯人工智能(下文简称“墨芯”),在最激烈的ResNet50模型比拼中夺冠!

而且在此成绩背后,墨芯给大模型时代下的智能算力问题,提供了一个非常具有价值的方向——
它夺冠所凭借的稀疏计算,堪称是大模型时代最不容忽视的算力“潜力股”。
不仅如此,墨芯此次还是斩获了开放任务分区“双料冠军”的那种:
-
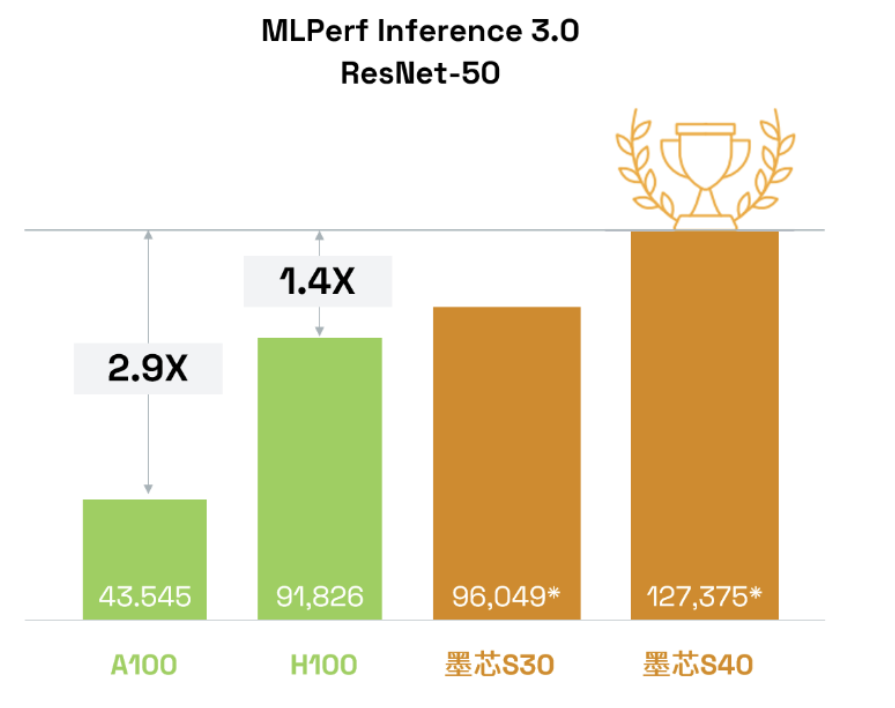
墨芯S40计算卡,以127,375 FPS,获得单卡算力全球第一;
-
墨芯S30计算卡,以383,520 FPS算力,获整机4卡算力全球第一。
而且墨芯靠着这套打法,在制程方面更是用首颗稀疏计算芯片12nm的AntoumⓇ打败了4nm。
不得不提的是,这次对于墨芯而言,还是“梅开二度”;因为它在上一届MLPerf,凭借S30同样是拿下了冠军。
在与GPT-3参数相当的开源LLM——1760亿参数的BLOOM上,4张墨芯S30计算卡在仅采用中低倍稀疏率的情况下,就能实现25 tokens/s的内容生成速度,超过8张A100。
那么稀疏计算为什么对大模型有这般良效?
算力纪录再度被刷新
我们不妨先来看下,墨芯所刷新的纪录到底是怎样的一个水平。
以墨芯S40为例,在MLPerf数据中心的图像任务主流模型ResNet-50上,且在相同数据集、相同精度条件下,算力达127,375 FPS。
这个“分数”是老牌玩家英伟达H100、A100的1.4倍和2.9倍!
为什么稀疏计算会成为正解?
简单理解,稀疏化就是一种聪明的数据处理和模型压缩方式,它让神经网络在计算时,能够仅启用所需的神经元。
而稀疏计算就是将原有AI计算的大量矩阵运算中,含有零元素或无效元素的部分剔除,以加快计算速度,由此也能进一步降低模型训练成本。
自从Transformers掀起大模型浪潮后,稀疏计算也成为了大厂关注的重点方向。
2021年,谷歌研究和OpenAI就罕见合作论文《Sparse is Enough in Scaling Transformers》,力证稀疏计算能为大模型带来数十倍加速。
而更早以前,2017年OpenAI就发布了稀疏计算内核,实现了在同等计算开销的情况下,能计算更深的神经网络。

谷歌这几年也密集发布了稀疏计算方面的多项工作,包括Pathways、PaLM、MoE、GLaM等。
其中Pathways架构是稀疏计算领域的一项重要工作。谷歌在当初发布时将其称为“下一代人工智能架构”,其技术博客由谷歌大脑负责人Jeff Dean亲自操刀撰写。
由此可见谷歌对Pathways架构及稀疏计算的重视。
其核心原理在于稀疏计算,即在执行任务时仅稀疏激活模型的特定部分,计算真正有用的元素。
并且在该架构发布没几天后,谷歌就跟进了稀疏计算领域的另一项重要工作:发布基于Pathways架构的5400亿参数大模型PaLM。
之后,谷歌还提出了首个多模态稀疏化模型LIMoE,它在降低模型计算量上的优势非常突出。
因为采用了稀疏计算,可以实现执行一次任务只调用模型中的一个子模型,那么这次任务的成本将会和标准Transformer差不多。比如LIMoE-H/14总共有5.6B参数,但是通过稀疏化,它只会使用每个token的675M参数。
就在今年ChatGPT大火后,稀疏化GPT方法也被提出,能够实现不降低模型效果的情况下,将大模型权重降低一半。
除了在算法架构方面以外,硬件计算侧对于稀疏化的关注也在提升。
比如英伟达就在其Ampere架构中首次支持2倍稀疏计算。
Ampere架构为英伟达A 100带来了第三代Tensor Core核心,使其可以充分利用网络权值下的细粒度稀疏化优势。
相较于稠密数学计算(dense math),能够在不牺牲深度学习矩阵乘法累加任务精度的情况下,将最大吞吐量提高了2倍。
以上大厂的动作,无疑都印证了稀疏计算会是大模型时代下AI计算的有效解之一。
由此也就不难理解,为什么墨芯会押中稀疏计算这一方向,并取得最新战绩。
一方面是很早洞察到了行业的发展趋势;另一方面也是自身快速准确做出了定位和判断。
墨芯创始人兼CEO王维表示,他们从2018、2019年就看到了稀疏计算给AI计算带来了数量级上的性能提升。
与此同时,Transformers开启了大模型时代,让AI从1.0时代步入2.0,推动了AI在应用场景、算力需求等方面的改变。
尤其是算力方面,王维认为已经产生了质变:
“小模型时代,用场景数据训练小模型,研发和部署周期短,对算力的需求主要是通用性、易用性。到了大模型时代,大模型主要基于Transformers模型架构,更追求计算速度和算力成本。”
而做稀疏计算,不只是墨芯一家想到了,前面提到英伟达也在推进这方面进展,不过王维表示,这对于GPU公司而言可能是“意外收获”,但如果专注稀疏计算的话,需要做的是十倍甚至百倍加速。
因此,墨芯选择的路线是从算法提升上升到软硬协同层面。
2022年,墨芯发布首颗高稀疏倍率芯片AntoumⓇ,能够支持32倍稀疏,大幅降低大模型所需的计算量。
墨芯在MLPerf中开放分区的提交结果刷新记录,也是对这一路线的进一步印证。
据透露,不仅在MLPerf上表现出色,墨芯的产品商业落地上也进展迅速。
墨芯AI计算卡发布数月就已实现量产,在互联网等领域成单落地。ChatGPT走红后墨芯也收到大量客户问询,了解稀疏计算在大模型上的算力优势与潜力。
如今,ChatGPT开启新一轮AI浪潮,大模型领域开启竞速赛、算力需求空前暴增。
如微软为训练ChatGPT打造了一台超算——由上万张英伟达A100芯片打造,甚至专门为此调整了服务器架构,只为给ChatGPT和新必应AI提供更好的算力。还在Azure的60多个数据中心部署了几十万张GPU,用于ChatGPT的推理。
毕竟,只有充足的算力支持,才能推动模型更快迭代升级。
怪不得行业内有声音说,这轮趋势,英伟达当属最大幕后赢家。
但与此同时,摩尔定律式微也是事实,单纯堆硬件已经无法满足当下算力需求,由此这也推动了算力行业迎来更新一轮机遇和变革。可以看到,近两年并行计算等加速方案愈发火热,这就是已经发生的变化。
而ChatGPT的火热,无疑加速了这一变革。在真实需求的推动下,算力领域硬件软件创新突破也会更快发生,模型会重新定义算法,算法会重新定义芯片。
2. CV不存在了?Meta发布「分割一切」AI 模型,CV或迎来GPT-3时刻
原文:https://mp.weixin.qq.com/s/-LWG3rOz60VWiwdYG3iaWQ
这下 CV 是真不存在了。< 快跑 >」这是知乎网友对于一篇 Meta 新论文的评价。
如标题所述,这篇论文只做了一件事情:(零样本)分割一切。类似 GPT-4 已经做到的「回答一切」。
除了2.0之外,还发布了一系列PyTorch域库的beta更新,包括那些在树中的库,以及包括 TorchAudio、TorchVision和TorchText在内的独立库。TorchX的更新也同时发布,可以提供社区支持模式。

Meta 表示,这是第一个致力于图像分割的基础模型。自此,CV 也走上了「做一个统一某个(某些?全部?)任务的全能模型」的道路。
在此之前,分割作为计算机视觉的核心任务,已经得到广泛应用。但是,为特定任务创建准确的分割模型通常需要技术专家进行高度专业化的工作,此外,该项任务还需要大量的领域标注数据,种种因素限制了图像分割的进一步发展。
Meta 在论文中发布的新模型名叫 Segment Anything Model (SAM) 。他们在博客中介绍说,「SAM 已经学会了关于物体的一般概念,并且它可以为任何图像或视频中的任何物体生成 mask,甚至包括在训练过程中没有遇到过的物体和图像类型。SAM 足够通用,可以涵盖广泛的用例,并且可以在新的图像『领域』上即开即用,无需额外的训练。」在深度学习领域,这种能力通常被称为零样本迁移,这也是 GPT-4 震惊世人的一大原因。

论文地址:https://arxiv.org/abs/2304.02643
项目地址:https://github.com/facebookresearch/segment-anything
Demo 地址:https://segment-anything.com/
除了模型,Meta 还发布了一个图像注释数据集 Segment Anything 1-Billion (SA-1B),据称这是有史以来最大的分割数据集。该数据集可用于研究目的,并且 Segment Anything Model 在开放许可 (Apache 2.0) 下可用。
我们先来看看效果。如下面动图所示,SAM 能很好的自动分割图像中的所有内容:
英伟达人工智能科学家 Jim Fan 表示:「对于 Meta 的这项研究,我认为是计算机视觉领域的 GPT-3 时刻之一。它已经了解了物体的一般概念,即使对于未知对象、不熟悉的场景(例如水下图像)和模棱两可的情况下也能进行很好的图像分割。最重要的是,模型和数据都是开源的。恕我直言,Segment-Anything 已经把所有事情(分割)都做的很好了。」
方法介绍
此前解决分割问题大致有两种方法。第一种是交互式分割,该方法允许分割任何类别的对象,但需要一个人通过迭代细化掩码来指导该方法。第二种,自动分割,允许分割提前定义的特定对象类别(例如,猫或椅子),但需要大量的手动注释对象来训练(例如,数千甚至数万个分割猫的例子)。这两种方法都没有提供通用的、全自动的分割方法。
SAM 很好的概括了这两种方法。它是一个单一的模型,可以轻松地执行交互式分割和自动分割。该模型的可提示界面允许用户以灵活的方式使用它,只需为模型设计正确的提示(点击、boxes、文本等),就可以完成范围广泛的分割任务。
总而言之,这些功能使 SAM 能够泛化到新任务和新领域。这种灵活性在图像分割领域尚属首创。
Meta 表示,他们受到语言模型中提示的启发,因而其训练完成的 SAM 可以为任何提示返回有效的分割掩码,其中提示可以是前景、背景点、粗框或掩码、自由格式文本,或者说能指示图像中要分割内容的任何信息。而有效掩码的要求仅仅意味着即使提示不明确并且可能指代多个对象(例如,衬衫上的一个点可能表示衬衫或穿着它的人),输出也应该是一个合理的掩码(就如上面动图「SAM 还能为为不明确的提示生成多个有效掩码」所示)。此任务用于预训练模型并通过提示解决一般的下游分割任务。
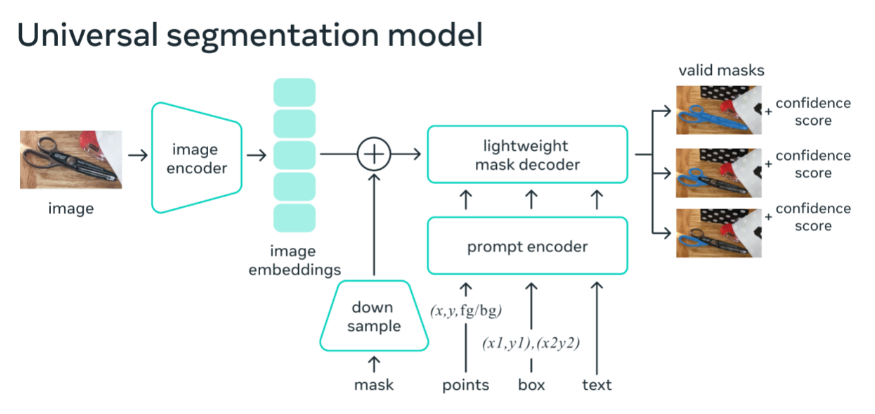
如下图所示 ,图像编码器为图像生成一次性嵌入,而轻量级编码器将提示实时转换为嵌入向量。然后将这两个信息源组合在一个预测分割掩码的轻量级解码器中。在计算图像嵌入后,SAM 可以在 50 毫秒内根据网络浏览器中的任何提示生成一个分割。
1100 万张图片,1B+ 掩码
数据集是使用 SAM 收集的。标注者使用 SAM 交互地注释图像,之后新注释的数据又反过来更新 SAM,可谓是相互促进。
使用该方法,交互式地注释一个掩码只需大约 14 秒。与之前的大规模分割数据收集工作相比,Meta 的方法比 COCO 完全手动基于多边形的掩码注释快 6.5 倍,比之前最大的数据注释工作快 2 倍,这是因为有了 SAM 模型辅助的结果。
最终的数据集超过 11 亿个分割掩码,在大约 1100 万张经过许可和隐私保护图像上收集而来。SA-1B 的掩码比任何现有的分割数据集多 400 倍,并且经人工评估研究证实,这些掩码具有高质量和多样性,在某些情况下甚至在质量上可与之前更小、完全手动注释的数据集的掩码相媲美 。
未来展望
通过研究和数据集共享,Meta 希望进一步加速对图像分割以及更通用图像与视频理解的研究。可提示的分割模型可以充当更大系统中的一个组件,执行分割任务。作为一种强大的工具,组合(Composition)允许以可扩展的方式使用单个模型,并有可能完成模型设计时未知的任务。
Meta 预计,与专门为一组固定任务训练的系统相比,基于 prompt 工程等技术的可组合系统设计将支持更广泛的应用。SAM 可以成为 AR、VR、内容创建、科学领域和更通用 AI 系统的强大组件。比如 SAM 可以通过 AR 眼镜识别日常物品,为用户提供提示。
3. 谷歌TPU超算,大模型性能超英伟达,已部署数十台:图灵奖得主新作
原文:https://mp.weixin.qq.com/s/uEAlKdpzutOpnPGmg5dOjw
我们还没有看到能与 ChatGPT 相匹敌的 AI 大模型,但在算力基础上,领先的可能并不是微软和 OpenAI。
本周二,谷歌公布了其训练语言大模型的超级计算机的细节,基于 TPU 的超算系统已经可以比英伟达的同类更加快速、节能。
谷歌张量处理器(tensor processing unit,TPU)是该公司为机器学习定制的专用芯片(ASIC),第一代发布于 2016 年,成为了 AlphaGo 背后的算力。与 GPU 相比,TPU 采用低精度计算,在几乎不影响深度学习处理效果的前提下大幅降低了功耗、加快运算速度。同时,TPU 使用了脉动阵列等设计来优化矩阵乘法与卷积运算。
当前,谷歌 90% 以上的人工智能训练工作都在使用这些芯片,TPU 支撑了包括搜索的谷歌主要业务。作为图灵奖得主、计算机架构巨擘,大卫・帕特森(David Patterson)在 2016 年从 UC Berkeley 退休后,以杰出工程师的身份加入了谷歌大脑团队,为几代 TPU 的研发做出了卓越贡献。

如今 TPU 已经发展到了第四代,谷歌本周二由 Norman Jouppi、大卫・帕特森等人发表的论文《 TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings 》详细介绍了自研的光通信器件是如何将 4000 多块芯片并联成为超级计算机,以提升整体效率的。

论文链接:
https://arxiv.org/ftp/arxiv/papers/2304/2304.01433.pdf
TPU v4 的性能比 TPU v3 高 2.1 倍,性能功耗比提高 2.7 倍。基于 TPU v4 的超级计算机拥有 4096 块芯片,整体速度提高了约 10 倍。对于类似大小的系统,谷歌能做到比 Graphcore IPU Bow 快 4.3-4.5 倍,比 Nvidia A100 快 1.2-1.7 倍,功耗低 1.3-1.9 倍。
除了芯片本身的算力,芯片间互联已成为构建 AI 超算的公司之间竞争的关键点,最近一段时间,谷歌的 Bard、OpenAI 的 ChatGPT 这样的大语言模型(LLM)规模正在爆炸式增长,算力已经成为明显的瓶颈。
由于大模型动辄千亿的参数量,它们必须由数千块芯片共同分担,并持续数周或更长时间进行训练。谷歌的 PaLM 模型 —— 其迄今为止最大的公开披露的语言模型 —— 在训练时被拆分到了两个拥有 4000 块 TPU 芯片的超级计算机上,用时 50 天。
谷歌表示,通过光电路交换机(OCS),其超级计算机可以轻松地动态重新配置芯片之间的连接,有助于避免出现问题并实时调整以提高性能。
下图展示了 TPU v4 4×3 方式 6 个「面」的链接。每个面有 16 条链路,每个块总共有 96 条光链路连接到 OCS 上。要提供 3D 环面的环绕链接,相对侧的链接必须连接到相同的 OCS。因此,每个 4×3 块 TPU 连接到 6 × 16 ÷ 2 = 48 个 OCS 上。Palomar OCS 为 136×136(128 个端口加上 8 个用于链路测试和修复的备用端口),因此 48 个 OCS 连接来自 64 个 4×3 块(每个 64 个芯片)的 48 对电缆,总共并联 4096 个 TPU v4 芯片。
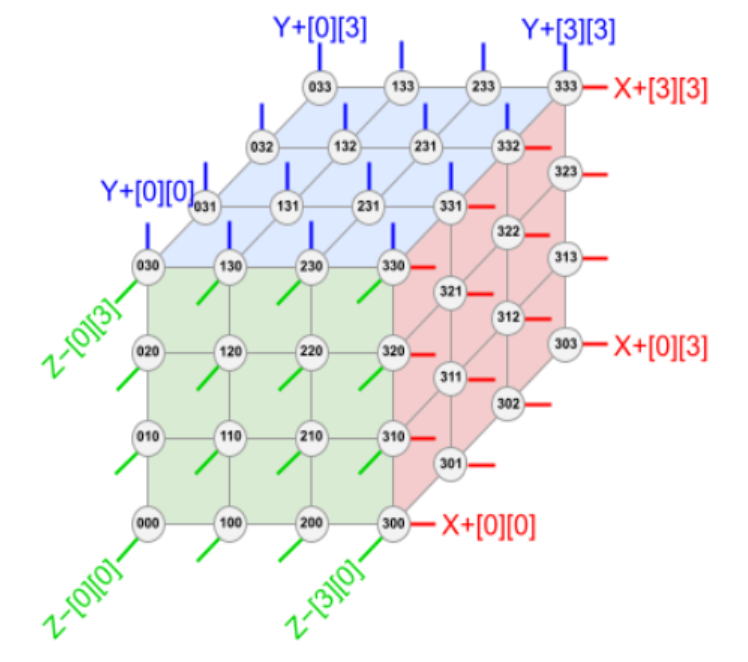
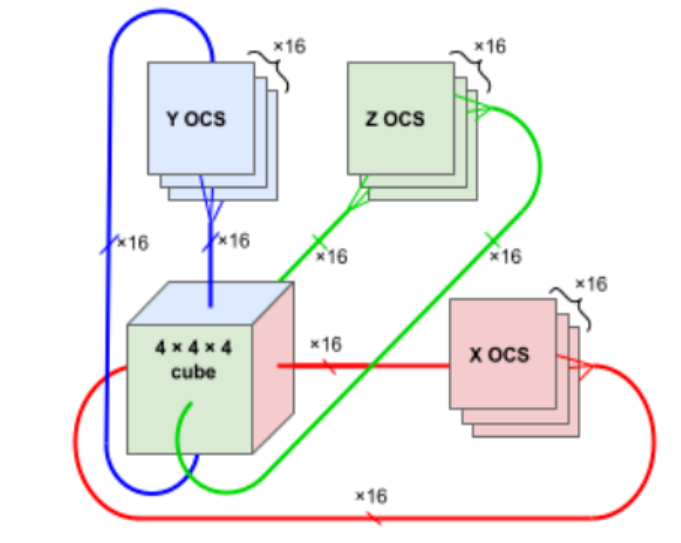
根据这样的排布,TPU v4(中间的 ASIC 加上 4 个 HBM 堆栈)和带有 4 个液冷封装的印刷电路板 (PCB)。该板的前面板有 4 个顶部 PCIe 连接器和 16 个底部 OSFP 连接器,用于托盘间 ICI 链接。
与超级计算机一样,工作负载由不同规模的算力承担,称为切片:64 芯片、128 芯片、256 芯片等。下图显示了当主机可用性从 99.0% 到 99.9% 不等有,及没有 OCS 时切片大小的「有效输出」。如果没有 OCS,主机可用性必须达到 99.9% 才能提供合理的切片吞吐量。对于大多数切片大小,OCS 也有 99.0% 和 99.5% 的良好输出。
与 Infiniband 相比,OCS 的成本更低、功耗更低、速度更快,成本不到系统成本的 5%,功率不到系统功率的 3%。每个 TPU v4 都包含 SparseCores 数据流处理器,可将依赖嵌入的模型加速 5 至 7 倍,但仅使用 5% 的裸片面积和功耗。
「这种切换机制使得绕过故障组件变得容易,」谷歌研究员 Norm Jouppi 和谷歌杰出工程师大卫・帕特森在一篇关于该系统的博客文章中写道。「这种灵活性甚至允许我们改变超级计算机互连的拓扑结构,以加速机器学习模型的性能。」
在新论文上,谷歌着重介绍了稀疏核(SparseCore,SC)的设计。在大模型的训练阶段,embedding 可以放在 TensorCore 或超级计算机的主机 CPU 上处理。TensorCore 具有宽 VPU 和矩阵单元,并针对密集操作进行了优化。由于小的聚集 / 分散内存访问和可变长度数据交换,在 TensorCore 上放置嵌入其实并不是最佳选择。在超级计算机的主机 CPU 上放置嵌入会在 CPU DRAM 接口上引发阿姆达尔定律瓶颈,并通过 4:1 TPU v4 与 CPU 主机比率放大。数据中心网络的尾部延迟和带宽限制将进一步限制训练系统。
对此,谷歌认为可以使用 TPU 超算的总 HBM 容量优化性能,加入专用 ICI 网络,并提供快速收集 / 分散内存访问支持。这导致了 SparseCore 的协同设计。
SC 是一种用于嵌入训练的特定领域架构,从 TPU v2 开始,后来在 TPU v3 和 TPU v4 中得到改进。SC 相对划算,只有芯片面积的约 5% 和功率的 5% 左右。SC 结合超算规模的 HBM 和 ICI 来创建一个平坦的、全局可寻址的内存空间(TPU v4 中为 128 TiB)。与密集训练中大参数张量的全部归约相比,较小嵌入向量的全部传输使用 HBM 和 ICI 以及更细粒度的分散 / 聚集访问模式。
作为独立的核心,SC 允许跨密集计算、SC 和 ICI 通信进行并行化。下图显示了 SC 框图,谷歌将其视为「数据流」架构(dataflow),因为数据从内存流向各种直接连接的专用计算单元。
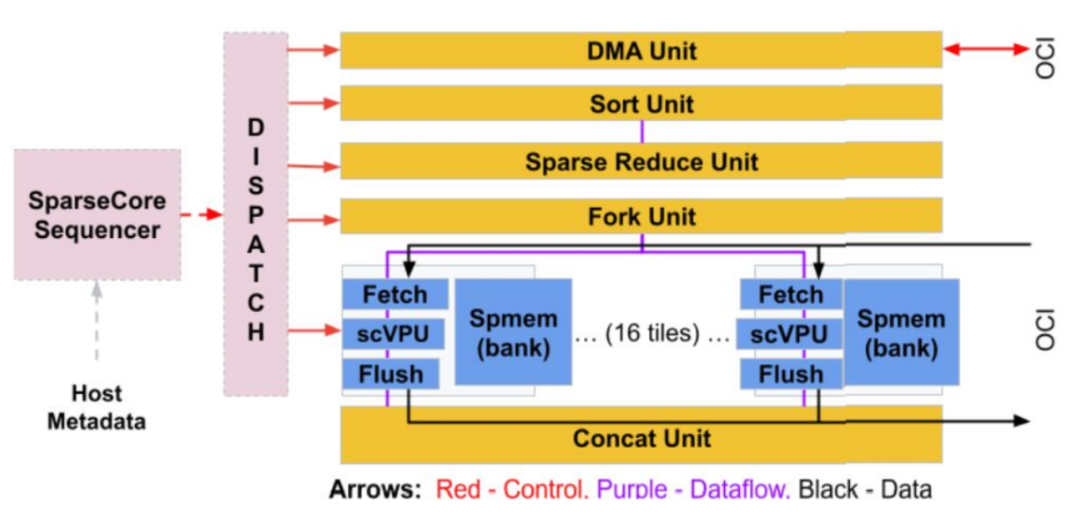
TPU v4 比当代 DSA 芯片速度更快、功耗更低,如果考虑到互连技术,功率边缘可能会更大。通过使用具有 3D 环面拓扑的 3K TPU v4 切片,与 TPU v3 相比,谷歌的超算也能让 LLM 的训练时间大大减少。
性能、可扩展性和可用性使 TPU v4 超级计算机成为 LaMDA、MUM 和 PaLM 等大型语言模型 (LLM) 的主要算力。这些功能使 5400 亿参数的 PaLM 模型在 TPU v4 超算上进行训练时,能够在 50 天内维持 57.8% 的峰值硬件浮点性能。
谷歌表示,其已经部署了数十台 TPU v4 超级计算机,供内部使用和外部通过谷歌云使用。
4. 130亿参数,8个A100训练,UC伯克利发布对话模型Koala
原文:https://mp.weixin.qq.com/s/uI5-sUOY2vdr1ekX-bh_WQ
自从 Meta 发布并开源了 LLaMA 系列模型,来自斯坦福大学、UC 伯克利等机构的研究者们纷纷在 LLaMA 的基础上进行「二创」,先后推出了 Alpaca、Vicuna 等多个「羊驼」大模型。
羊驼已然成为开源社区的新晋顶流。由于「二创」过于丰富,生物学羊驼属的英文单词都快不够用了,但是用其他动物的名字给大模型命名也是可以的。
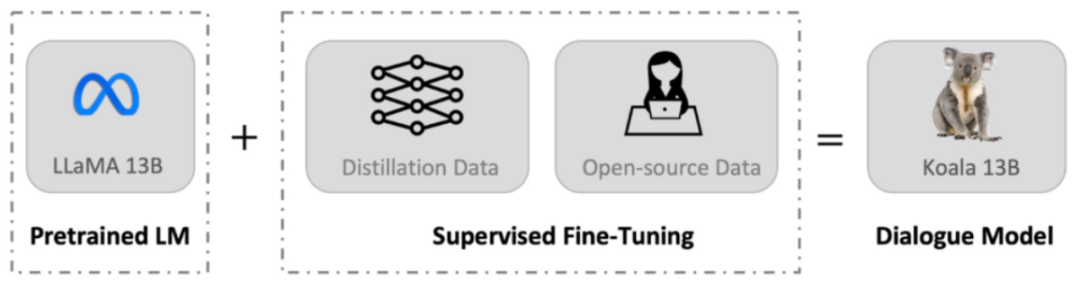
最近,UC 伯克利的伯克利人工智能研究院(BAIR)发布了一个可以在消费级 GPU 上运行的对话模型 Koala(直译为考拉)。Koala 使用从网络收集的对话数据对 LLaMA 模型进行微调。
项目地址:
https://bair.berkeley.edu/blog/2023/04/03/koala/
Demo 地址:
https://chat.lmsys.org/?model=koala-13b
开源地址:
https://github.com/young-geng/EasyLM
Koala 概述
与 Vicuna 类似,Koala 也使用从网络收集的对话数据对 LLaMA 模型进行微调,其中重点关注与 ChatGPT 等闭源大模型对话的公开数据。
研究团队表示,Koala 模型在 EasyLM 中使用 JAX/Flax 实现,并在配备 8 个 A100 GPU 的单个 Nvidia DGX 服务器上训练 Koala 模型。完成 2 个 epoch 的训练需要 6 个小时。在公共云计算平台上,进行此类训练的成本通常低于 100 美元。
研究团队将 Koala 与 ChatGPT 和斯坦福大学的 Alpaca 进行了实验比较,结果表明:具有 130 亿参数的 Koala-13B 可以有效地响应各种用户查询,生成的响应通常优于 Alpaca,并且在超过一半的情况下与 ChatGPT 性能相当。
Koala 最重要的意义是它表明:在质量较高的数据集上进行训练,那么小到可以在本地运行的模型也可以获得类似大模型的优秀性能。这意味着开源社区应该更加努力地管理高质量数据集,因为这可能比简单地增加现有系统的规模更能实现安全、真实和强大的模型。从这个角度看,Koala 是 ChatGPT 一种小而精的平替。
不过,Koala 还只是一个研究原型,在内容、安全性和可靠性方面仍然存在重大缺陷,也不应用于研究之外的任何用途。
数据集和训练
构建对话模型的主要障碍是管理训练数据。ChatGPT、Bard、Bing Chat 和 Claude 等大型对话模型都使用带有大量人工注释的专有数据集。为了构建 Koala 的训练数据集,研究团队从网络和公共数据集中收集对话数据并整理,其中包含用户公开分享的与大型语言模型(例如 ChatGPT)对话的数据。
不同于其他模型尽可能多地抓取网络数据来最大化数据集,Koala 是专注于收集小型高质量数据集,包括公共数据集中的问答部分、人类反馈(正面和负面)以及与现有语言模型的对话。具体而言,Koala 的训练数据集包括如下几个部分:
ChatGPT 蒸馏数据:
-
公开可用的与 ChatGPT 对话数据(ShareGPT);
-
Human ChatGPT 比较语料库 (HC3),其中同时使用来自 HC3 数据集的人类和 ChatGPT 响应。
开源数据:
-
Open Instruction Generalist (OIG);
-
斯坦福 Alpaca 模型使用的数据集;
-
Anthropic HH;
-
OpenAI WebGPT;
-
OpenAI Summarization。
实验与评估
该研究进行了一项人工评估,将 Koala-All 与 Koala-Distill、Alpaca 和 ChatGPT 几个模型的生成结果进行比较,结果如下图所示。其中,使用两个不同的数据集进行测试,一个是斯坦福的 Alpaca 测试集,其中包括 180 个测试查询(Alpaca Test Set),另一个是 Koala Test Set。
总的来说,Koala 模型足以展示 LLM 的许多功能,同时又足够小,方便进行微调或在计算资源有限的情况下使用。研究团队希望 Koala 模型成为未来大型语言模型学术研究的有用平台,潜在的研究应用方向可能包括:
-
安全性和对齐:Koala 允许进一步研究语言模型的安全性并更好地与人类意图保持一致。
-
模型偏差:Koala 使我们能够更好地理解大型语言模型的偏差,深入研究对话数据集的质量问题,最终有助于改进大型语言模型的性能。
-
理解大型语言模型:由于 Koala 模型可以在相对便宜的消费级 GPU 上运行,并且执行多种任务,因此 Koala 使我们能够更好地检查和理解对话语言模型的内部结构,使语言模型更具可解释性。
5. 这款编译器能让Python和C++一样快:最高提速百倍,MIT出品
原文:https://mp.weixin.qq.com/s/EOfsFCZa_IaqIsmsrxSujQ
自深度学习兴起以来,Python 一直是最热门的编程语言之一,它在数据科学和机器学习领域占主导地位,甚至是科学和数学计算领域的主角。如今你能想象到的任何项目,几乎都可以找到一个相应的 Python 包。
然而,尽管高级语言的简化语法使其易于学习和使用,但和 C 或 C++ 等低级语言相比,它的速度更慢。
麻省理工学院计算机科学与人工智能实验室(CSAIL)的研究人员希望通过 Codon 来改变这一现状,Codon 是一种基于 Python 的编译器,允许用户编写与 C 或 C++ 程序一样高效运行的 Python 代码,同时可以定制和适应不同的需求和环境。
该研究的最新论文《Codon: A Compiler for High-Performance Pythonic Applications and DSLs》发表在了 2 月份的第 32 届 ACM SIGPLAN 编译器构建国际会议上。

项目链接:
https://github.com/exaloop/codon
论文:
https://dl.acm.org/doi/abs/10.1145/3578360.3580275
在开发工作中,人们需要使用编译器将源代码转换为可由计算机处理器执行的机器代码,Codon 能帮助开发者在 Python 中创建新的领域特定语言(DSL),同时仍然获得其他语言的性能优势。
「常规 Python 会被编译成所谓的字节码,该字节码在虚拟机中执行,这就会让速度慢上很多,」Codon 论文的主要作者 Ariya Shajii 表示,「通过 Codon,我们则进行本地编译,因此你可以直接在 CPU 上运行最终结果 —— 不经过中间虚拟机或解释器。」
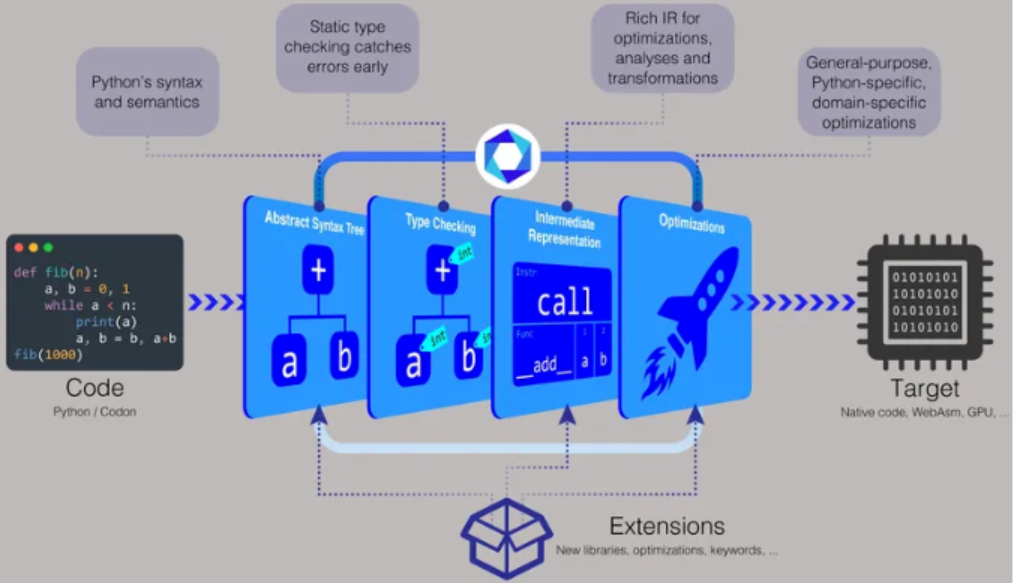
基于 Python 的编译器带有适用于 Linux 和 macOS 的预构建二进制文件,你还可以从源代码构建或生成可执行文件。「使用 Codon,你可以像 Python 一样分发源代码,或者你可以将它编译成二进制文件,」Shajii 说。「如果你想分发一个二进制文件,它将与像 C++ 这样的语言一样,例如一个 Linux 二进制文件或一个 Mac 二进制文件。」
为了让 Codon 更快,研究人员决定在编译时执行类型检查。类型检查涉及将数据类型(例如整数、字符串、字符或浮点数等)分配给值。例如数字 5 可以分配为整数,字母 c 可以分配为字符,单词 hello 可以分配为字符串,十进制数 3.14 可以分配为浮点数。
「在常规 Python 中,所有类型都给了 runtime,」Shajii 介绍道。「使用 Codon,我们在编译过程中进行类型检查,这让我们避免了在 runtime 进行所有昂贵的类型操作。」
MIT CSAIL 首席研究员 Saman Amarasinghe 补充说,「如果你有一种动态语言(比如 Python),每次你有一些数据时,你都需要在它周围保留很多额外的元数据,以确定 runtime 的类型。Codon 取消了这种元数据,因此代码速度更快,数据更小。」
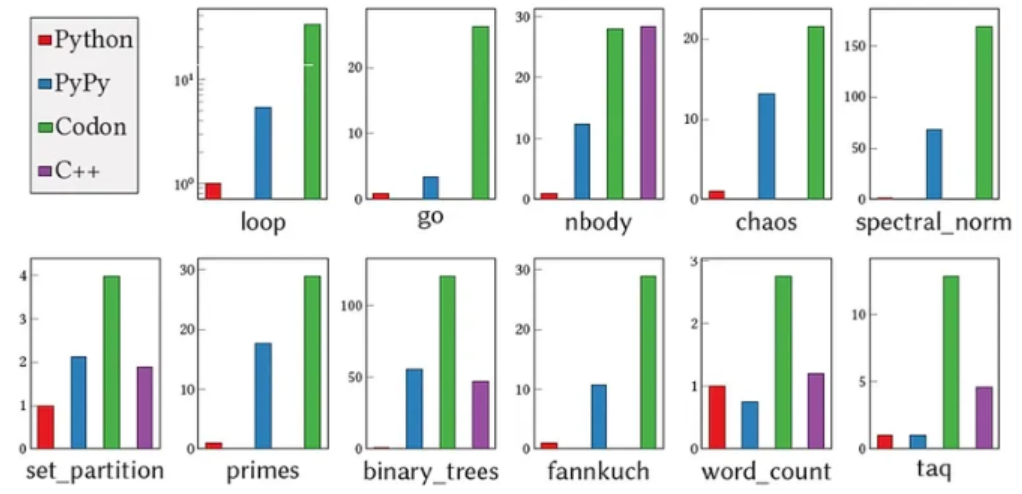
根据 Shajii 的说法,Codon 在运行时没有任何不必要的数据或类型检查,所以开销为零。在性能方面,「Codon 通常与 C++ 不相上下。与 Python 相比,我们通常看到的是 10 到 100 倍的速度改进。」
另一方面,Codon 的方法有其权衡。「我们进行这种静态类型检查,并且不允许使用 Python 的一些动态特性,比如在 runtime 动态更改类型,」Shajii 表示。
「还有一些 Python 库我们还没有实现。」Amarasinghe 补充说,「Python 已经过无数人的实际测试,而 Codon 还没有达到那样的水平,它需要运行更多的程序,获得更多的反馈,并加固更多。达到常规 Python 的稳定水平需要一些时间。」
Codon 最初设计用于基因组学和生物信息学的工作。研究人员尝试了大约 10 个用 Python 编写的常用基因组学应用程序,并使用 Codon 对其进行了编译,与最初的手动优化实现相比实现了 5 到 10 倍的加速。
「如今这些领域的数据集已变得非常大,而像 Python 和 R 这样的高级语言速度太慢,无法处理每组测序 TB 级的数据量,」Shajii 说道。「这就是我们想要填补的空白 —— 通过构建一种无需写 C 或 C++ 代码即可处理大数据的方法,从而为非计算机科学或专业开发者的领域专家提供帮助。」
除了基因组学,Codon 还可以应用于处理海量数据集的类似应用程序,以及基于 Python 的编译器支持的 GPU 编程和并行编程等领域。事实上,Codon 现在正通过初创公司 Exaloop 在生物信息学、深度学习和量化金融领域进行商业应用,Shajii 创立了该公司,旨在将 Codon 从学术项目转变为行业应用。
为了使 Codon 能够适应不同领域,该团队开发了一个插件系统。「它就像一个可扩展的编译器,」Shajii 说道。「你可以为基因组学或其他领域编写插件,这些插件可以有新的库和新的编译器优化。」
此外,公司和机构可以使用 Codon 来制作原型和开发自己的应用程序。「我们看到的一种模式是:人们使用 Python 进行原型设计和测试,因为它易于使用,但到了某些重要事项上,他们就不得不重写应用程序,或让其他人用 C 或 C++ 在更大的数据集上进行重写与测试,」Shajii 表示。「通过 Codon,你就可以完全使用 Python,并获得两全其美的好处。」
关于 Codon 的未来,Shajii 和他的团队目前正在研究广泛使用的 Python 库的本地实现,以及特定于库的优化,以帮助人们从这些库中获得更好的性能。他们还计划创建一个广受欢迎的功能:Codon 的 WebAssembly 后端,以支持在 Web 浏览器上运行代码。
6. Pytorch中模型的保存与迁移
https://mp.weixin.qq.com/s/c0QI44bmOp6hJLVWPXAgrw
1 引言
各位朋友大家好,今天要和大家介绍的内容是如何在Pytorch框架中对模型进行保存和载入、以及模型的迁移和再训练。
一般来说,最常见的场景就是模型完成训练后的推断过程。一个网络模型在完成训练后通常都需要对新样本进行预测,此时就只需要构建模型的前向传播过程,然后载入已训练好的参数初始化网络即可。
第2个场景就是模型的再训练过程。一个模型在一批数据上训练完成之后需要将其保存到本地,并且可能过了一段时间后又收集到了一批新的数据,因此这个时候就需要将之前的模型载入进行在新数据上进行增量训练(或者是在整个数据上进行全量训练)。
第3个应用场景就是模型的迁移学习。这个时候就是将别人已经训练好的预模型拿过来,作为你自己网络模型参数的一部分进行初始化。例如:你自己在Bert模型的基础上加了几个全连接层来做分类任务,那么你就需要将原始BERT模型中的参数载入并以此来初始化你的网络中的Bert部分的权重参数。
在接下来的这篇文章中,笔者就以上述3个场景为例来介绍如何利用Pytorch框架来完成上述过程。
2 模型的保存与复用
在Pytorch中,我们可以通过torch.save()和torch.load()来完成上述场景中的主要步骤。下面,笔者将以之前介绍的LeNet5网络模型为例来分别进行介绍。不过在这之前,我们先来看看Pytorch中模型参数的保存形式。
2.1 查看网络模型参数
(1)查看参数
首先定义好LeNet5的网络模型结构,如下代码所示:
1classLeNet5(nn.Module):
2def__init__(self,):
3super(LeNet5,self).__init__()
4self.conv=nn.Sequential(#[n,1,28,28]
5nn.Conv2d(1,6,5,padding=2),#in_channels,out_channels,kernel_size
6nn.ReLU(),#[n,6,24,24]
7nn.MaxPool2d(2,2),#kernel_size,stride[n,6,14,14]
8nn.Conv2d(6,16,5),#[n,16,10,10]
9nn.ReLU(),
10nn.MaxPool2d(2,2))#[n,16,5,5]
11self.fc=nn.Sequential(
12nn.Flatten(),
13nn.Linear(16*5*5,120),
14nn.ReLU(),
15nn.Linear(120,84),
16nn.ReLU(),
17nn.Linear(84,10))
18defforward(self,img):
19output=self.conv(img)
20output=self.fc(output)
21returnoutput
在定义好LeNet5这个网络结构的类之后,只要我们完成了这个类的实例化操作,那么网络中对应的权重参数也都完成了初始化的工作,即有了一个初始值。同时,我们可以通过如下方式来访问:
1#Printmodel'sstate_dict*
2print("Model'sstate_dict:")
3**for**param_tensor**in**model.state_dict():
4print(param_tensor," ",model.state_dict()[param_tensor].size())
其输出的结果为:
1conv.0.weighttorch.Size([6,1,5,5])
2conv.0.biastorch.Size([6])
3conv.3.weighttorch.Size([16,6,5,5])
4....
5....
可以发现,网络模型中的参数model.state_dict()其实是以字典的形式(实质上是collections模块中的OrderedDict)保存下来的:
1print(model.state_dict().keys())
2#odict_keys(['conv.0.weight','conv.0.bias','conv.3.weight',
3'conv.3.bias','fc.1.weight','fc.1.bias','fc.3.weight','fc.3.bias',
4'fc.5.weight','fc.5.bias'])
(2)自定义参数前缀
同时,这里值得注意的地方有两点:①参数名中的fc和conv前缀是根据你在上面定义nn.Sequential()时的名字所确定的;②参数名中的数字表示每个Sequential()中网络层所在的位置。例如将网络结构定义成如下形式:
1classLeNet5(nn.Module):
2def__init__(self,):
3super(LeNet5,self).__init__()
4self.moon=nn.Sequential(#[n,1,28,28]
5nn.Conv2d(1,6,5,padding=2),#in_channels,out_channels,kernel_size
6nn.ReLU(),#[n,6,24,24]
7nn.MaxPool2d(2,2),#kernel_size,stride[n,6,14,14]
8nn.Conv2d(6,16,5),#[n,16,10,10]
9nn.ReLU(),
10nn.MaxPool2d(2,2),
11nn.Flatten(),
12nn.Linear(16*5*5,120),
13nn.ReLU(),
14nn.Linear(120,84),
15nn.ReLU(),
16nn.Linear(84,10))
那么其参数名则为:
1print(model.state_dict().keys())
2odict_keys(['moon.0.weight','moon.0.bias','moon.3.weight',
3'moon.3.bias','moon.7.weight','moon.7.bias','moon.9.weight',
4'moon.9.bias','moon.11.weight','moon.11.bias'])
理解了这一点对于后续我们去解析和载入一些预训练模型很有帮助。
除此之外,对于中的优化器等,其同样有对应的state_dict()方法来获取对于的参数,例如:
1optimizer=torch.optim.SGD(model.parameters(),lr=0.001,momentum=0.9)
2print("Optimizer'sstate_dict:")
3forvar_nameinoptimizer.state_dict():
4print(var_name," ",optimizer.state_dict()[var_name])
5
6#
7Optimizer'sstate_dict:
8state{}
9param_groups[{'lr':0.001,'momentum':0.9,'dampening':0,
10'weight_decay':0,'nesterov':False,
11'params':[140239245300504,140239208339784,140239245311360,
12140239245310856,140239266942480,140239266942552,140239266942624,
13140239266942696,140239266942912,140239267041352]}]
14
在介绍完模型参数的查看方法后,就可以进入到模型复用阶段的内容介绍了。
2.2 载入模型进行推断
(1) 模型保存
在Pytorch中,对于模型的保存来说是非常简单的,通常来说通过如下两行代码便可以实现:
1model_save_path=os.path.join(model_save_dir,'model.pt')
2torch.save(model.state_dict(),model_save_path)
在指定保存的模型名称时Pytorch官方建议的后缀为.pt或者.pth(当然也不是强制的)。最后,只需要在合适的地方加入第2行代码即可完成模型的保存。
同时,如果想要在训练过程中保存某个条件下的最优模型,那么应该通过如下方式:
1best_model_state=deepcopy(model.state_dict())
2torch.save(best_model_state,model_save_path)
而不是:
1best_model_state=model.state_dict()
2torch.save(best_model_state,model_save_path)
因为后者best_model_state得到只是model.state_dict()的引用,它依旧会随着训练过程而发生改变。
(2)复用模型进行推断
在推断过程中,首先需要完成网络的初始化,然后再载入已有的模型参数来覆盖网络中的权重参数即可,示例代码如下:
1definference(data_iter,device,model_save_dir='./MODEL'):
2model=LeNet5()#初始化现有模型的权重参数
3model.to(device)
4model_save_path=os.path.join(model_save_dir,'model.pt')
5ifos.path.exists(model_save_path):
6loaded_paras=torch.load(model_save_path)
7model.load_state_dict(loaded_paras)#用本地已有模型来重新初始化网络权重参数
8model.eval()#注意不要忘记
9withtorch.no_grad():
10acc_sum,n=0.0,0
11forx,yindata_iter:
12x,y=x.to(device),y.to(device)
13logits=model(x)
14acc_sum+=(logits.argmax(1)==y).float().sum().item()
15n+=len(y)
16print("Accuracyintestdatais:",acc_sum/n)
在上述代码中,4-7行便是用来载入本地模型参数,并用其覆盖网络模型中原有的参数。这样,便可以进行后续的推断工作:
1Accuracyintestdatais:0.8851
2.3 载入模型进行训练
在介绍完模型的保存与复用之后,对于网络的追加训练就很简单了。最简便的一种方式就是在训练过程中只保存网络权重,然后在后续进行追加训练时只载入网络权重参数初始化网络进行训练即可,示例如下(完整代码参见[2]):
1deftrain(self):
2#......
3model_save_path=os.path.join(self.model_save_dir,'model.pt')
4ifos.path.exists(model_save_path):
5loaded_paras=torch.load(model_save_path)
6self.model.load_state_dict(loaded_paras)
7print("####成功载入已有模型,进行追加训练...")
8optimizer=torch.optim.Adam(self.model.parameters(),lr=self.learning_rate)#定义优化器
9#......
10forepochinrange(self.epochs):
11fori,(x,y)inenumerate(train_iter):
12x,y=x.to(device),y.to(device)
13logits=self.model(x)
14#......
15print("Epochs[{}/{}]--accontest{:.4}".format(epoch,self.epochs,
16self.evaluate(test_iter,self.model,device)))
17torch.save(self.model.state_dict(),model_save_path)
这样,便完成了模型的追加训练:
1####成功载入已有模型,进行追加训练...
2Epochs[0/5]---batch[938/0]---acc0.9062---loss0.2926
3Epochs[0/5]---batch[938/100]---acc0.9375---loss0.1598
4......
除此之外,你也可以在保存参数的时候,将优化器参数、损失值等一同保存下来,然后在恢复模型的时候连同其它参数一起恢复,示例如下:
1model_save_path=os.path.join(model_save_dir,'model.pt')
2torch.save({
3'epoch':epoch,
4'model_state_dict':model.state_dict(),
5'optimizer_state_dict':optimizer.state_dict(),
6'loss':loss,
7...
8},model_save_path)
载入方式如下:
1checkpoint=torch.load(model_save_path)
2model.load_state_dict(checkpoint['model_state_dict'])
3optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
4epoch=checkpoint['epoch']
5loss=checkpoint['loss']
2.4 载入模型进行迁移
(1)定义新模型
到目前为止,对于前面两种应用场景的介绍就算完成了,可以发现总体上并不复杂。但是对于第3中场景的应用来说就会略微复杂一点。
假设现在有一个LeNet6网络模型,它是在LeNet5的基础最后多加了一个全连接层,其定义如下:
1classLeNet6(nn.Module):
2def__init__(self,):
3super(LeNet6,self).__init__()
4self.conv=nn.Sequential(#[n,1,28,28]
5nn.Conv2d(1,6,5,padding=2),#in_channels,out_channels,kernel_size
6nn.ReLU(),#[n,6,24,24]
7nn.MaxPool2d(2,2),#kernel_size,stride[n,6,14,14]
8nn.Conv2d(6,16,5),#[n,16,10,10]
9nn.ReLU(),
10nn.MaxPool2d(2,2))#[n,16,5,5]
11self.fc=nn.Sequential(
12nn.Flatten(),
13nn.Linear(16*5*5,120),
14nn.ReLU(),
15nn.Linear(120,84),
16nn.ReLU(),
17nn.Linear(84,64),
18nn.ReLU(),
19nn.Linear(64,10))#新加入的全连接层
接下来,我们需要将在LeNet5上训练得到的权重参数迁移到LeNet6网络中去。从上面LeNet6的定义可以发现,此时尽管只是多加了一个全连接层,但是倒数第2层参数的维度也发生了变换。因此,对于LeNet6来说只能复用LeNet5网络前面4层的权重参数。
(2)查看模型参数
在拿到一个模型参数后,首先我们可以将其载入,然查看相关参数的信息:
1model_save_path=os.path.join('./MODEL','model.pt')
2loaded_paras=torch.load(model_save_path)
3forparam_tensorinloaded_paras:
4print(param_tensor," ",loaded_paras[param_tensor].size())
5
6#----可复用部分
7conv.0.weighttorch.Size([6,1,5,5])
8conv.0.biastorch.Size([6])
9conv.3.weighttorch.Size([16,6,5,5])
10conv.3.biastorch.Size([16])
11fc.1.weighttorch.Size([120,400])
12fc.1.biastorch.Size([120])
13fc.3.weighttorch.Size([84,120])
14fc.3.biastorch.Size([84])
15#-----不可复用部分
16fc.5.weighttorch.Size([10,84])
17fc.5.biastorch.Size([10])
同时,对于LeNet6网络的参数信息为:
1model=LeNet6()
2forparam_tensorinmodel.state_dict():
3print(param_tensor," ",model.state_dict()[param_tensor].size())
4#
5conv.0.weighttorch.Size([6,1,5,5])
6conv.0.biastorch.Size([6])
7conv.3.weighttorch.Size([16,6,5,5])
8conv.3.biastorch.Size([16])
9fc.1.weighttorch.Size([120,400])
10fc.1.biastorch.Size([120])
11fc.3.weighttorch.Size([84,120])
12fc.3.biastorch.Size([84])
13#------新加入部分
14fc.5.weighttorch.Size([64,84])
15fc.5.biastorch.Size([64])
16fc.7.weighttorch.Size([10,64])
17fc.7.biastorch.Size([10])
在理清楚了新旧模型的参数后,下面就可以将LeNet5中我们需要的参数给取出来,然后再换到LeNet6的网络中。
(3)模型迁移
虽然本地载入的模型参数(上面的loaded_paras)和模型初始化后的参数(上面的model.state_dict())都是一个字典的形式,但是我们并不能够直接改变model.state_dict()中的权重参数。这里需要先构造一个state_dict然后通过model.load_state_dict()方法来重新初始化网络中的参数。
同时,在这个过程中我们需要筛选掉本地模型中不可复用的部分,具体代码如下:
1defpara_state_dict(model,model_save_dir):
2state_dict=deepcopy(model.state_dict())
3model_save_path=os.path.join(model_save_dir,'model.pt')
4ifos.path.exists(model_save_path):
5loaded_paras=torch.load(model_save_path)
6forkeyinstate_dict:#在新的网络模型中遍历对应参数
7ifkeyinloaded_parasandstate_dict[key].size()==loaded_paras[key].size():
8print("成功初始化参数:",key)
9state_dict[key]=loaded_paras[key]
10returnstate_dict
在上述代码中,第2行的作用是先拷贝网络中(LeNet6)原有的参数;第6-9行则是用本地的模型参数(LeNet5)中可以复用的替换掉LeNet6中的对应部分,其中第7行就是判断可用的条件。同时需要注意的是在不同的情况下筛选的方式可能不一样,因此具体情况需要具体分析,但是整体逻辑是一样的。
最后,我们只需要在模型训练之前调用该函数,然后重新初始化LeNet6中的部分权重参数即可[2]:
1state_dict=para_state_dict(self.model,self.model_save_dir)
2self.model.load_state_dict(state_dict)
训练结果如下:
1成功初始化参数:conv.0.weight
2成功初始化参数:conv.0.bias
3成功初始化参数:conv.3.weight
4成功初始化参数:conv.3.bias
5成功初始化参数:fc.1.weight
6成功初始化参数:fc.1.bias
7成功初始化参数:fc.3.weight
8成功初始化参数:fc.3.bias
9####成功载入已有模型,进行追加训练...
10Epochs[0/5]---batch[938/0]---acc0.1094---loss2.512
11Epochs[0/5]---batch[938/100]---acc0.9375---loss0.2141
12Epochs[0/5]---batch[938/200]---acc0.9219---loss0.2729
13Epochs[0/5]---batch[938/300]---acc0.8906---loss0.2958
14......
15Epochs[0/5]---batch[938/900]---acc0.8906---loss0.2828
16Epochs[0/5]--accontest0.8808
可以发现,在大约100个batch之后,模型的准确率就提升上来了。
3 总结
在本篇文章中,笔者首先介绍了模型复用的几种典型场景;然后介绍了如何查看Pytorch模型中的相关参数信息;接着介绍了如何载入模型、如何进行追加训练以及进行模型的迁移学习等。
———————End———————
RT-Thread线下入门培训-4月场次 青岛、北京
1.免费2.动手实验+理论3.主办方免费提供开发板4.自行携带电脑,及插线板用于笔记本电脑充电5.参与者需要有C语言、单片机(ARM Cortex-M核)基础,请提前安装好RT-Thread Studio 开发环境

立即扫码报名
报名链接
https://jinshuju.net/f/UYxS2k
巡回城市:青岛、北京、西安、成都、武汉、郑州、杭州、深圳、上海、南京
你可以添加微信:rtthread2020 为好友,注明:公司+姓名,拉进RT-Thread官方微信交流群!
点击阅读原文,进入RT-ThreadXIFX赛事官网
原文标题:【AI简报20230407期】 MLPref放榜!大模型时代算力领域“潜力股”浮出水面、CV或迎来GPT-3时刻
-
RT-Thread
+关注
关注
32文章
1644浏览量
45279
原文标题:【AI简报20230407期】 MLPref放榜!大模型时代算力领域“潜力股”浮出水面、CV或迎来GPT-3时刻
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
算力上天!我国发射2800颗算力卫星,背后企业浮出水面
AI大模型微调企业项目实战课
算力尽头是电力!AI算力爆发下,储能产业链UPS电源核心机遇全解析

边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
中国算力芯片的拐点时刻

阿里自研AI芯片“真武”亮相 “通云哥”黄金三角浮出水面

亚太地区AI数据中心可持续发展面临重重挑战


安谋发布“周易”X3 NPU,破局AI算力,智绘未来蓝图







评论