 【嵌入式AI简报20231117期】面对未来AI的三大挑战!
【嵌入式AI简报20231117期】面对未来AI的三大挑战!

AI 简报 20231117期
1.面对未来的AI:三大挑战
当AI如ChatGPT在2022年末突然崭露头角时,不仅展现了AI的惊人进步,还描绘出了一个充满可能性的未来,重新定义着我们的工作、学习和娱乐方式。尽管AI的潜力对许多人来说显而易见,但其中隐藏了一些棘手的伦理和风险问题。
应对这些风险就像解开一幅巨大的拼图,这幅拼图定义着我们的时代。因此,许多AI领域的专家正积极倡导制定一些基本规则,以确保AI的使用受到约束。毕竟,AI的应用不仅仅是口号,它已经变得至关重要。
我们正在深入究专家们的见解,解开围绕他们的道德困境,并研究如何影响人工智能和其他技术的未来。
“伦理与偏见
人工智能系统需要使用数据进行训练。但数据集往往是由有偏见或不准确的人制作的。因此,人工智能系统会使偏见长期存在。在招聘实践和刑事司法中尤其如此,管理这些偏见可能很困难。
IEEE高级会员Kayne McGladrey表示:“我们可以手动或自动审计软件代码中的隐私缺陷。同样,我们可以审计软件代码的安全缺陷。但是,我们目前无法审计软件代码是否存在道德缺陷或偏见,即将出台的大部分法规将对人工智能模型的结果进行歧视性筛选。”
“改变工作方式
随着生成人工智能的兴起,公司正在重新构想如何完成工作。虽然很少有人认为需要创造力和判断力的工作可以完全自动化,但人工智能可以提供帮助。例如,当作家陷入困境时,生成型人工智能可以提供对话想法。它不能充当你的律师,但一个好的律师可以利用生成人工智能来撰写动议的初稿,或进行研究。
IEEE会员Todd Richmond说:“我们需要共同弄清楚什么是“人类的努力”,我们愿意把什么交给算法,比如制作音乐、电影、行医等。”
在全球技术领袖的调查(https://transmitter.ieee.org/impact-of-technology-2024/)中,其中50%的受访者表示,将AI整合到现有工作流程中存在困难,是他们对于在2024年使用生成式AI的前三大担忧之一。
“准确性和过度依赖性
生成型人工智能可以”自信”地阐述事实,但问题是这些事实并不总是准确的。对于所有形式的人工智能,很难弄清楚该软件究竟是如何得出结论的。
在调查中,59%的受访者表示,“过度依赖人工智能和其潜在的不准确性”是他们组织中人工智能使用的首要问题。
部分问题在于训练数据本身可能不准确。
IEEE终身会士Paul Nikolich说:“验证训练数据很困难,因为来源不可用,且训练数据量巨大。”
人工智能可能越来越多地被用于关键任务、拯救生命的应用。
“在我们使用人工智能系统之前,我们必须相信这些人工智能系统将安全且按预期运行,”IEEE会士Houbing Song说。
在2024年及以后,预计将大力确保人工智能结果更加准确,用于训练人工智能模型的数据是干净的。
2. 李飞飞团队新作:脑控机器人做家务,让脑机接口具备少样本学习能力
原文:https://mp.weixin.qq.com/s/TwvfHMKZNBpsFirM2PuO-Q
未来也许只需动动念头,就能让机器人帮你做好家务。斯坦福大学的吴佳俊和李飞飞团队近日提出的 NOIR 系统能让用户通过非侵入式脑电图装置控制机器人完成日常任务。
NOIR 能将你的脑电图信号解码为机器人技能库。它现在已能完成例如烹饪寿喜烧、熨衣服、磨奶酪、玩井字游戏,甚至抚摸机器狗等任务。这个模块化的系统具备强大的学习能力,可以应对日常生活中复杂多变的任务。
大脑与机器人接口(BRI)堪称是人类艺术、科学和工程的集大成之作。我们已经在不胜枚举的科幻作品和创意艺术中见到它,比如《黑客帝国》和《阿凡达》;但真正实现 BRI 却非易事,需要突破性的科学研究,创造出能与人类完美协同运作的机器人系统。
对于这样的系统,一大关键组件是机器与人类通信的能力。在人机协作和机器人学习过程中,人类传达意图的方式包括动作、按按钮、注视、面部表情、语言等等。而通过神经信号直接与机器人通信则是最激动人心却也最具挑战性的前景。
近日,斯坦福大学吴佳俊和李飞飞领导的一个多学科联合团队提出了一种通用型的智能 BRI 系统 NOIR(Neural Signal Operated Intelligent Robots / 神经信号操控的智能机器人)。

论文地址:https://openreview.net/pdf?id=eyykI3UIHa
项目网站:https://noir-corl.github.io/
该系统基于非侵入式的脑电图(EEG)技术。据介绍,该系统依据的主要原理是分层式共享自治(hierarchical shared autonomy),即人类定义高层级目标,而机器人通过执行低层级运动指令来实现目标。该系统纳入了神经科学、机器人学和机器学习领域的新进展,取得了优于之前方法的进步。该团队总结了所做出的贡献。
首先,NOIR 是通用型的,可用于多样化的任务,也易于不同社区使用。研究表明,NOIR 可以完成多达 20 种日常活动;相较之下,之前的 BRI 系统通常是针对一项或少数几项任务设计的,或者就仅仅是模拟系统。此外,只需少量培训,普通人群也能使用 NOIR 系统。
其次,NOIR 中的 I 表示这个机器人系统是智能的(intelligent),具备自适应能力。该机器人配备了一个多样化的技能库,让其无需密集的人类监督也能执行低层级动作。使用参数化的技能原语,比如 Pick (obj-A) 或 MoveTo (x,y),机器人可以很自然地取得、解读和执行人类的行为目标。
此外,NOIR 系统还有能力在协作过程中学习人类想达成的目标。研究表明,通过利用基础模型的最新进展,该系统甚至能适应很有限的数据。这能显著提升系统的效率。
NOIR 的关键技术贡献包括一个模块化的解码神经信号以获知人类意图的工作流程。要知道,从神经信号解码出人类意图目标是极具挑战性的。为此,该团队的做法是将人类意图分解为三大组分:要操控的物体(What)、与该物体交互的方式(How)、交互的位置(Where)。他们的研究表明可以从不同类型的神经数据中解码出这些信号。这些分解后的信号可以自然地对应于参数化的机器人技能,并且可以有效地传达给机器人。
在 20 项涉及桌面或移动操作的家庭活动(包括制作寿喜烧、熨烫衣物、玩井字棋、摸机器狗狗等)中,三名人类受试者成功地使用了 NOIR 系统,即通过他们的大脑信号完成了这些任务!

实验表明,通过以人类为师进行少样本机器人学习,可以显著提升 NOIR 系统的效率。这种使用人脑信号协作来构建智能机器人系统的方法潜力巨大,可用于为人们(尤其是残障人士)开发至关重要的辅助技术,提升他们的生活品质。
NOIR 系统
这项研究力图解决的挑战包括:1. 如何构建适用于各种任务的通用 BRI 系统?2. 如何解码来自人脑的相关通信信号?3. 如何提升机器人的智能和适应能力,从而实现更高效的协作?图 2 给出了该系统的概况。
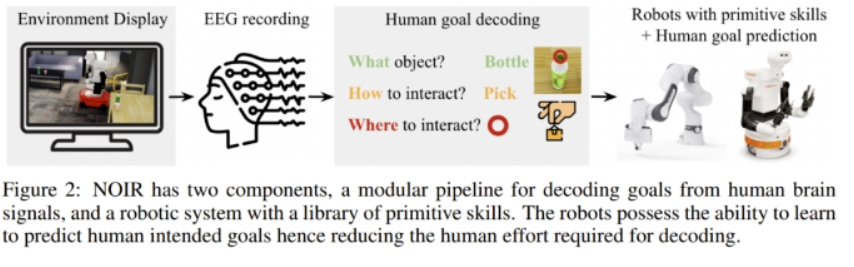
在这个系统中,人类作为规划智能体,做的是感知、规划以及向机器人传达行为目标;而机器人则要使用预定义的原语技能实现这些目标。
为了实现打造通用 BRI 系统的总体目标,需要将这两种设计协同集成到一起。为此,该团队提出了一种全新的大脑信号解码工作流程,并为机器人配备了一套参数化的原始技能库。最后,该团队使用少样本模仿学习技术让机器人具备了更高效的学习能力。
大脑:模块化的解码工作流程
如图 3 所示,人类意图会被分解成三个组分:要操控的物体(What)、与该物体交互的方式(How)、交互的位置(Where)。
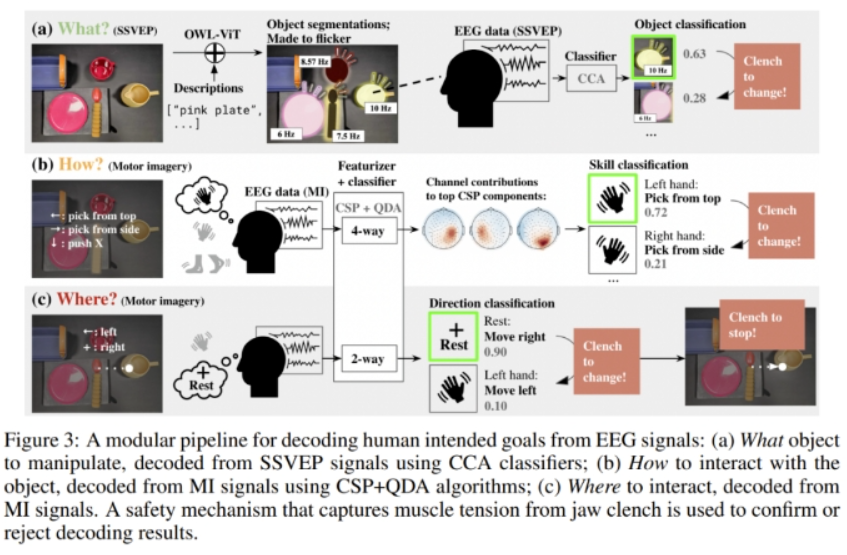
要从脑电图信号解码出具体的用户意图,难度可不小,但可以通过稳态视觉诱发电位(SSVEP)和运动意象(motor imagery)来完成。简单来说,这个过程包括:
-
选取具有稳态视觉诱发电位(SSVEP)的物体
-
通过运动意象(MI)选择技能和参数
-
通过肌肉收紧来选择确认或中断
机器人:参数化的原语技能
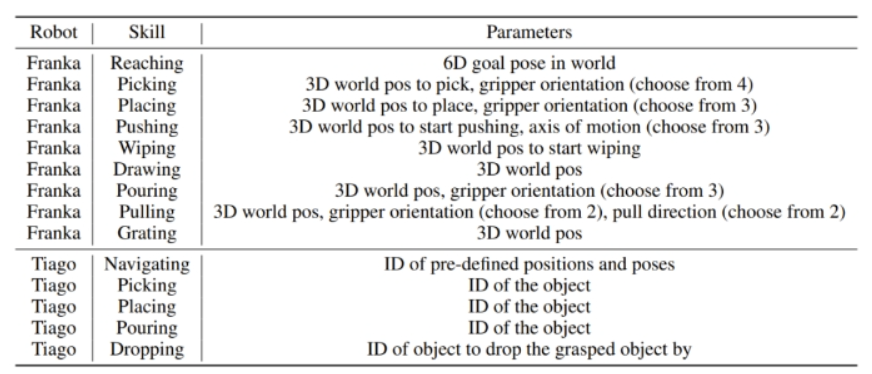
参数化的原语技能可以针对不同的任务进行组合和复用,从而实现复杂多样的操作。此外,对人类而言,这些技能非常直观。人类和智能体都无需了解这些技能的控制机制,因此人们可以通过任何方法实现这些技能,只要它们是稳健的且能适应多样化的任务。
该团队在实验中使用了两台机器人:一台是用于桌面操作任务的 Franka Emika Panda 机械臂,另一台是用于移动操作任务的 PAL Tiago 机器人。下表给出了这两台机器人的原语技能。
使用机器人学习实现高效的 BRI
上述的模块化解码工作流程和原语技能库为 NOIR 奠定了基础。但是,这种系统的效率还能进一步提升。机器人应当能在协作过程中学习用户的物品、技能和参数选择偏好,从而在未来能预测用户希望达成的目标,实现更好的自动化,也让解码更简单容易。由于每一次执行时,物品的位置、姿态、排列和实例可能会有所不同,因此就需要学习和泛化能力。另外,学习算法应当具有较高的样本效率,因为收集人类数据的成本很高。
该团队为此采用了两种方法:基于检索的少样本物品和技能选取、单样本技能参数学习。
基于检索的少样本物品和技能选取。该方法可以学习所观察状态的隐含表征。给定一个观察到的新状态,它会在隐藏空间中找到最相似的状态以及对应的动作。图 4 给出了该方法的概况。
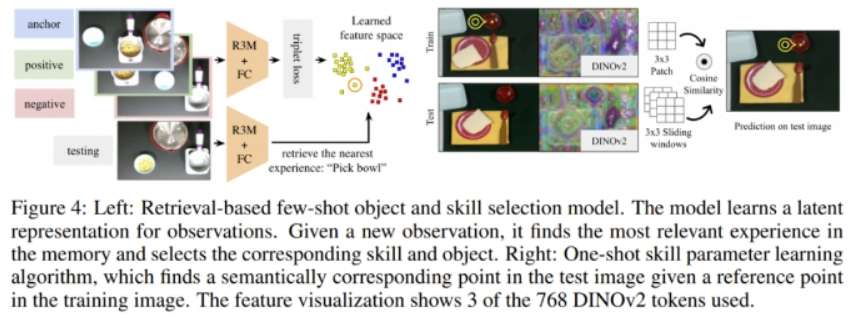
在任务执行期间,由图像和人类选择的「物品 - 技能」对构成的数据点会被记录下来。这些图像首先会被一个预训练的 R3M 模型编码,以提取出对机器人操控任务有用的特征,然后再让它们通过一些可训练的全连接层。这些层的训练使用了带三元组损失的对比学习,这会鼓励带有同样「物品 - 技能」标签的图像在隐藏空间中处于更相近的位置。所学习到的图像嵌入和「物品 - 技能」标签会被存储到内存中。
在测试期间,模型会检索隐藏空间中最近的数据点,然后将与该数据点关联的「物品 - 技能」对建议给人类。
单样本技能参数学习。参数选取需要人类大量参与,因为这个过程需要通过运动意象(MI)进行精准的光标操作。为了减少人类的工作量,该团队提出了一种学习算法,可以根据给定的用作光标控制起始点的「物品 - 技能」对来预测参数。假设用户已经成功定位了拿起一个杯子把手的精确关键点,那么未来还需要再次指定这个参数吗?最近 DINOv2 等基础模型取得了不少进展,已经可以找到相应的语义关键点,从而无需再次指定参数。
相比于之前的工作,这里提出的新算法是单样本的并且预测的是具体的 2D 点,而非语义片段。如图 4 所示,给定一张训练图像(360 × 240)和参数选择 (x, y),模型预测不同的测试图像中语义上对应的点。该团队具体使用的是预训练的 DINOv2 模型来获取语义特征。
实验和结果
任务。实验选取的任务来自 BEHAVIOR 和 Activities of Daily Living 基准,这两个基准能在一定程度上体现人类的日常需求。图 1 展示了实验任务,其中包含 16 个桌面任务和 4 个移动操作任务。
下面展示了制作三明治和护理新冠病人的实验过程示例。
实验流程。实验过程中,用户待在一个隔离房间中,保持静止,在屏幕上观看机器人,单纯依靠大脑信号与机器人沟通。
系统性能。表 1 总结了两个指标下的系统性能:成功之前的尝试次数和成功时完成任务的时间。
尽管这些任务跨度长,难度大,但 NOIR 还是得到了非常鼓舞人心的结果:平均而言,只需尝试 1.83 次就能完成任务。
解码准确度。解码大脑信号的准确度是 NOIR 系统成功的一大关键。表 2 总结了不同阶段的解码准确度。可以看到,基于 SSVEP 的 CCA(典型相关分析)能达到 81.2% 的高准确度,也就是说物品选取大体上是准确的。
物品和技能选取结果。那么,新提出的机器人学习算法能否提升 NOIR 的效率呢?研究者首先对物品和技能选取学习进行了评估。为此,他们为 MakePasta 任务收集了一个离线数据集,其中每一对「物品 - 技能」都有 15 个训练样本。给定一张图像,当同时预测出了正确的物品和技能时,就认为该预测是正确的。结果见表 3。使用 ResNet 的简单图像分类模型能实现 0.31 的平均准确度,而基于预训练 ResNet 骨干网络使用新方法时却能达到显著更高的 0.73,这凸显出了对比学习和基于检索的学习的重要性。
单样本参数学习的结果。研究者基于预先收集的数据集将新算法与多个基准进行了比较。表 4 给出了预测结果的 MSE 值。
他们还在 SetTable 任务上展现了参数学习算法在实际任务执行中的有效性。图 5 给出了控制光标移动方面所节省的人类工作量。
3. 微软深夜连甩三大炸弹!Bing Chat更名Copilot,自研芯片问世,还加入GPTs功能
原文:https://mp.weixin.qq.com/s/jZs_yHPVjo_OggzWClMXpQ
就在刚刚,微软正式对外重磅宣布:
从今天起,Bing Chat全线更名——Copilot。
和ChatGPT一样,现在的微软Copilot也拥有自己的专属网站。
但与之不同的是,像GPT-4、DALL·E 3这样的功能,在Copilot上统统都是免费的!
要想使用这一切,你只需要做的就是登录微软账号(而ChatGPT则需要订阅会员)。 a
就连OpenAI上周王炸推出的自定义GPT,也被微软塞了进来,并取名为——Copilot Studio。
而围绕新品牌Copilot,微软的大动作还不止于此。
例如流传已久的自研芯片,今天终于亮相了——2款高端定制芯片,Azure Maia 100和Azure Cobalt 100。
据外媒推测,尤其是像Maia 100这种AI芯片,很可能就是要用在Copilot品牌下的一些新功能。
除此之外,打工人最关心的Office,这次也是塞满了Copilot。
总而言之,纵观整场微软Ignite大会,“Copilot”可谓是贯穿了所有。
正如外媒的评价:
微软可以叫“Copilot公司”了。
一切皆可Copilot
对于Bing Chat更名为Copilot,微软CEO纳德拉在现场将此高度总结为:
Copilot无所不在。
现在,无论是在微软的Edge、谷歌的Chrome、苹果的Safari,亦或是移动端,均可使用Copilot。
不过需要强调的一点是,虽然Copilot只需要登录微软账号就可以免费使用,但像Microsoft 365等其它产品的Copilot依旧是付费的。
对于类似OpenAI GPTs的Copilot Studio,从微软的介绍来看,它还是有一点不同。
Copilot Studio的主要设计目的其实是扩展Microsoft 365 Copilot。
在该应用中,大伙可以用它自定义包含不同数据集、自动化流程的Copilot。
由此一来,我们就可以将这些自定义AI助手更专注地连接到公司的关键业务系统中(是的,主要面向企业用户),然后就像与人聊天一样方便地获取其中信息。
它可以是网站上帮助用户回答产品问题的Copilot,也可以是季度收益发布中的Copilot。
对于这项新功能,最重磅的一点还是:
OpenAI GPTs居然也被直接塞了进来,大伙在构建自定义Copilot时,也能用上它的功能
最后,Copilot系列除了以上这些,微软还发布了Copilot for Azure,一个专门通过聊天方式简化日常IT管理的AI。
首款5nm自研AI芯片
在围绕Copilot的一系列重磅炸弹放出之时,微软的自研芯片也终于来了。
一共两款。
Azure芯片部门副总裁透露,Maia 100已在其Bing和Office AI产品上测试。
以及划重点:OpenAI也在试用。这意味着ChatGPT等模型的云训练和推理都将可能基于该芯片。
第二款叫Cobalt 100,是一款64位、128计算核心的CPU,基于ARM指令集架构,对标英特尔和AMD同类处理器。
Cobalt 100也被设计为专门用于云计算,相比微软Azure一直在用的其他基于ARM的芯片,可带来40%功耗下降。
目前,它已开始为Microsoft Teams等应用提供支持。
微软介绍,这两款芯片全部由台积电生产,将在明年初在微软的几个数据中心首次公开亮相。
以及它们都还只是各自系列中的头阵产品,言外之意,后面还会继续研发上新。
现在,微软也终于在谷歌TPU和亚马逊Graviton之后,拥有了自研AI芯片——三大云巨头也“齐活”了。
Office更新:降价了
最最后,围绕微软Office一系列套件的AI产品Copilot for Microsoft 365也更新了n多功能(没在大会上宣布,直接官网通知)。
主要思想就是更加个性化、更强的数学和分析能力以及全面打通协作。
譬如在Word和PowerPoint中,我们可以设置更多写作格式、风格、语气的偏好,获得更为量身定制的文档和PPT,更像你本人(亲自创作的)。
在Excel中,则能用自然语言解锁更多复杂的数学分析。
在Team中,可以直接将大伙的头脑风暴转为可视化白板,如果你想专门看看某位同事说了什么,直接使用“Quote xx”命令即可呈现Copilot为你记录的全部发言。
当然,最最值得关注的更新还是降价了。
现在每月只需50美元即可享受企业服务,比之前少了20刀。
4. 中文最强开源大模型来了!130亿参数,0门槛商用,来自昆仑万维
原文:https://mp.weixin.qq.com/s/MKu6eusxyCXw3fLhgbcp0A
开源最彻底的大模型来了——130亿参数,无需申请即可商用。
不仅如此,它还附带着把全球最大之一的中文数据集也一并开源了出来:600G、1500亿tokens!
这就是来自昆仑万维的Skywork-13B系列,包含两大版本:
-
Skywork-13B-Base:该系列的基础模型,在多种基准评测中都拔得头筹的那种。
-
Skywork-13B-Math:该系列的数学模型,数学能力在GSM8K评测上得分第一。
在各大权威评测benchmark上,如C-Eval、MMLU、CMMLU、GSM8K,可以看到Skywork-13B在中文开源模型中处于前列,在同等参数规模下为最优水平。
而Skywork-13B系列之所以能取得如此亮眼的成绩,部分原因离不开刚才我们提到的数据集。
毕竟清洗好的中文数据对于大模型来说可谓是至关重要,几乎从某种程度上决定了其性能。
但昆仑万维能将如此“至宝”无偿地给奉献出来,不难看出它对于构建开源社区、服务开发者的满满诚意。
除此之外,昆仑万维Skywork-13B此次还配套了“轻量版”大模型,是在消费级显卡中就能部署和推理的那种!
Skywork-13B下载地址(Model Scope):
https://modelscope.cn/organization/skywork
Skywork-13B下载地址(Github):
https://github.com/SkyworkAI/Skywork
接下来,我们进一步来看下Skywork-13B系列更多的能力。
无需申请即可商用
Skywork-13B系列大模型拥有130亿参数、3.2万亿高质量多语言训练数据。
由此,模型在生成、创作、数学推理等任务上提升明显。
首先在中文语言建模困惑度评测中,Skywork-13B系列大模型超越了目前所有中文开源模型。
在科技、金融、政务、企业服务、文创、游戏等领域均表现出色。
另外,Skywork-13B-Math专长数学任务,进行过数学能力强化训练,在GSM8K等数据集中取得了同等规模模型最佳效果。
与此同时,昆仑万维还开源了数据集Skypile/Chinese-Web-Text-150B。其数据是通过精心过滤的数据处理流程从中文网页中筛选而来。
由此,开发者可以最大程度借鉴技术报告中大模型预训练的过程和经验,深度定制模型参数,进行针对性训练与优化 。
除此之外,Skywork-13B还公开了模型使用的评估方法、数据配比研究和训练基础设施调优方案等。
而Skywork-13B的一系列开源,无需申请即可商用!
用户在下载模型并同意遵守《Skywork模型社区许可协议》后,不用再次申请商业授权。
授权流程也取消了对行业、公司规模、用户数量等方面限制。
昆仑万维会如此彻底开源其实也并不意外。
昆仑万维董事长兼CEO方汉是最早参与到开源生态建设的老兵了,也是中文Linux开源最早的推动者之一。
在今年ChatGPT趋势刚刚兴起时,他就多次公开发声、强调开源的重要性:
代码开源可助力中国版ChatGPT弯道超车。
所以也就不难理解Skywork-13B系列大模型的推出了。
而在短短2个月后,昆仑万维又将最新的大模型、最新的数据集,一并发布且开源,可以说它的一切动作不仅在于快,更是在于敢。
那么接下来的问题是——为什么要这么做?
其实,对于AIGC这一板块,昆仑万维早在2020年便已经开始涉足,早早的准备和技术积累就是它能够在大热潮来临之际快速跟进的原因之一。
据了解,昆仑万维目前已形成AI大模型、AI搜索、AI游戏、AI音乐、AI动漫、AI社交六大AI业务矩阵。
至于不遗余力的将开源这事做好做大,一方面是源于企业的基因。
昆仑万维董事长兼CEO方汉是最早参与到开源生态建设的开源老兵,也是中文Linux开源最早的推动者之一,开源的精神和AIGC技术的发展早已在昆仑万维战略中完美融合。
正如方汉此前所言:
昆仑天工之所以选择开源,因为我们坚信开源是推动AIGC生态发展的土壤和重要力量。昆仑万维致力于在AIGC模型算法方面的技术创新和开拓,致力于推进开源AIGC算法和模型社区的发展壮大,致力于降低AIGC技术在各行各业的使用和学习门槛。
没错,降低门槛,便是其坚持开源的另一大原因。
从昆仑万维入局百模大战以来的种种动作中,也很容易看到它正在践行着让天工用起来更简单、更丝滑。
总而言之,昆仑万维目前已然是处于国产大模型的第一梯队,甚至说是立于金字塔尖都不足为过。
那么在更大力度的开源加持之下,天工大模型还将有怎样惊艳的表现,是值得期待一波了。
5. 最强大模型训练芯片H200发布!141G大内存,AI推理最高提升90%,还兼容H100
原文:https://mp.weixin.qq.com/s/IYPpzHgXuYHGrO-BRgyWhw
官网毫不客气就直说了,“世界最强GPU,专为AI和超算打造”。
听说所有AI公司都抱怨内存不够?这回直接141GB大内存,与H100的80GB相比直接提升76%。作为首款搭载HBM3e内存的GPU,内存带宽也从3.35TB/s提升至4.8TB/s,提升43%。
对于AI来说意味着什么?来看测试数据。在HBM3e加持下,H200让Llama-70B推理性能几乎翻倍,运行GPT3-175B也能提高60%。
最强AI芯片只能当半年
除内存大升级之外,H200与同属Hopper架构的H100相比其他方面基本一致。
台积电4nm工艺,800亿晶体管,NVLink 4每秒900GB的高速互联,都被完整继承下来。
甚至峰值算力也保持不变,数据一眼看过去,还是熟悉的FP64 Vector 33.5TFlops、FP64 Tensor 66.9TFlops。
对于内存为何是有零有整的141GB,AnandTech分析HBM3e内存本身的物理容量为144GB,由6个24GB的堆栈组成。
出于量产原因,英伟达保留了一小部分作为冗余,以提高良品率。
仅靠升级内存,与2020年发布的A100相比,H200就在GPT-3 175B的推理上加速足足18倍。
H200预计在2024年第2季度上市,但最强AI芯片的名号H200只能拥有半年。
同样在2024年的第4季度,基于下一代Blackwell架构的B100也将问世,具体性能还未知,图表暗示了会是指数级增长。
多家超算中心将部署GH200超算节点
除了H200芯片本身,英伟达此次还发布了由其组成的一系列集群产品。
首先是HGX H200平台,它是将8块H200搭载到HGX载板上,总显存达到了1.1TB,8位浮点运算速度超过32P(10^15) FLOPS,与H100数据一致。
HGX使用了英伟达的NVLink和NVSwitch高速互联技术,可以以最高性能运行各种应用负载,包括175B大模型的训练和推理。
HGX板的独立性质使其能够插入合适的主机系统,从而允许使用者定制其高端服务器的非GPU部分。

接下来是Quad GH200超算节点——它由4个GH200组成,而GH200是H200与Grace CPU组合而成的。
Quad GH200节点将提供288 Arm CPU内核和总计2.3TB的高速内存。
通过大量超算节点的组合,H200最终将构成庞大的超级计算机,一些超级计算中心已经宣布正在向其超算设备中集成GH200系统。
据英伟达官宣,德国尤利希超级计算中心将在Jupiter超级计算机使用GH200超级芯片,包含的GH200节点数量达到了24000块,功率为18.2兆瓦,相当于每小时消耗18000多度电。
该系统计划于2024年安装,一旦上线,Jupiter将成为迄今为止宣布的最大的基于Hopper的超级计算机。
Jupiter大约将拥有93(10^18) FLOPS的AI算力、1E FLOPS的FP64运算速率、1.2PB每秒的带宽,以及10.9PB的LPDDR5X和另外2.2PB的HBM3内存。
除了Jupiter,日本先进高性能计算联合中心、德克萨斯高级计算中心、伊利诺伊大学香槟分校国家超级计算应用中心等超算中心也纷纷宣布将使用GH200对其超算设备进行更新升级。
那么,AI从业者都有哪些尝鲜途径可以体验到GH200呢?
上线之后,GH200将可以通过Lambda、Vultr等特定云服务提供商进行抢先体验,Oracle和CoreWeave也宣布了明年提供GH200实例的计划,亚马逊、谷歌云、微软Azure同样也将成为首批部署GH200实例的云服务提供商。
英伟达自身,也会通过其NVIDIA LaunchPad平台提供对GH200的访问。
硬件制造商方面,华硕、技嘉等厂商计划将于今年年底开始销售搭载GH200的服务器设备。
6. 干货分享~最新Yolo系列模型的部署、精度对齐与int8量化加速
原文:https://mp.weixin.qq.com/s/f2nPgwX2g-H8-8M8TXd38w
分享下朋友的一系列关于YOLO部署的干货,纯白嫖,来源请看原文链接。
本文写于2023-11-02晚
若需转载请联系 haibintian@foxmail.com
大家好,我是海滨。写这篇文章的目的是为宣传我在23年初到现在完成的一项工作---Yolo系列模型在TensorRT上的部署与量化加速,目前以通过视频的形式在B站发布(不收费,只图一个一剑三连)。
麻雀虽小但五脏俱全,本项目系统介绍了YOLO系列模型在TensorRT上的量化方案,工程型较强,我们给出的工具可以实现不同量化方案在Yolo系列模型的量化部署,无论是工程实践还是学术实验,相信都会对你带来一定的帮助。
B站地址(求关注和三连):https://www.bilibili.com/video/BV1Ds4y1k7yr/
Github开源地址(求star):https://github.com/thb1314/mmyolo_tensorrt/
当时想做这个的目的是是为了总结一下目标检测模型的量化加速到底会遇到什么坑,只是没想到不量化坑都会很多。
比如即使是以FP32形式推理,由于TensorRT算子参数的一些限制和TRT和torch内部实现的不同,导致torch推理结果会和TensorRT推理结果天然的不统一,至于为什么不统一这里卖个关子大家感兴趣可以看下视频。
下面说一下我们这个项目做了哪些事情
-
YOLO系列模型在tensorrt上的部署与精度对齐
该项目详细介绍了Yolo系列模型在TensorRT上的FP32的精度部署,基于mmyolo框架导出各种yolo模型的onnx,在coco val数据集上对齐torch版本与TensorRT版本的精度。
在此过程中我们发现,由于TopK算子限制和NMS算子实现上的不同,我们无法完全对齐torch和yolo模型的精度,不过这种风险是可解释且可控的。
-
详解TensorRT量化的三种实现方式
TensorRT量化的三种实现方式包括trt7自带量化、dynamic range api,trt8引入的QDQ算子。
Dynamic range api会在采用基于MQbench框架做PTQ时讲解。
TensorRT引入的QDQ算子方式在针对Yolo模型的PTQ和QAT方式时都有详细的阐述,当然这个过程也没有那么顺利。
在基于PytorchQuantization导出的含有QDQ节点的onnx时,我们发现尽管量化版本的torch模型精度很高,但是在TensorRT部署时精度却很低,TRT部署收精度损失很严重,通过可视化其他量化形式的engine和问题engine进行对比,我们发现是一些层的int8量化会出问题,由此找出问题量化节点解决。
-
详解MQbench量化工具包在TensorRT上的应用
我们研究了基于MQbench框架的普通PTQ算法和包括Adaround高阶PTQ算法,且启发于Adaround高阶PTQ算法。
我们将torch版本中的HistogramObserver引入到MQBench中,activation采用HistogramObserver weight采用MinMaxObserver,在PTQ过程中,weight的校准前向传播一次,activation的校准需要多次 因此我们将weight的PTQ过程和activation的PTQ过程分开进行,加速PTQ量化。实践证明,我们采用上述配置的分离PTQ量化在yolov8上可以取得基本不掉点的int8量化精度。
-
针对YoloV6这种难量化模型,分别采用部分量化和QAT来弥补量化精度损失
在部分量化阶段,我们采用量化敏感层分析技术来判断哪些层最需要恢复原始精度,给出各种metric的量化敏感层实现。
在QAT阶段,不同于原始Yolov6论文中蒸馏+RepOPT的方式,我们直接采用上述部分量化后的模型做出初始模型进行finetune,结果发现finetune后的模型依然取得不错效果。
-
针对旋转目标检测,我们同样给出一种端到端方案,最后的输出就是NMS后的结果。通过将TensorRT中的EfficientNMS Plugin和mmcv中旋转框iou计算的cuda实现相结合,给出EfficientNMS for rotated box版本,经过简单验证我们的TRT版本与Torch版本模型输出基本对齐。
以上就是我们这个项目做的事情,欢迎各位看官关注b站和一剑三连。同时,如果各位有更好的想法也欢迎给我们的git仓库提PR。
7. 领域大模型落地的一些思考
原文:https://mp.weixin.qq.com/s/s-r-CL6qbrhnjdlcLYGrkw
一、常说通用模型的领域化可能是伪命题,那么领域大模型的通用化是否也是伪命题。
自训练模型开始,就一直再跟Leader Battle这个问题,领域大模型需不需要有通用化能力。就好比华为盘古大模型“只做事不作诗”的slogan,是不是训练的领域大模型可以解决固定的几个任务就可以了。
个人的一些拙见是,如果想快速的将领域大模型落地,最简单的是将系统中原有能力进行升级,即大模型在固定的某一个或某几个任务上的效果超过原有模型。
以Text2SQL任务举例,之前很多系统中的方法是通过抽取关键要素&拼接方式来解决,端到端解决的并不是很理想,那么现在完全可以用大模型SQL生成的能力来解决。在已有产品上做升级,是代价最小的落地方式。就拿我司做的大模型来说,在解决某领域SQL任务上效果可以达到90%+,同比现有开源模型&开放API高了不少。
当然还有很多其他任务可以升级,例如:D2QA、D2SPO、Searh2Sum等等等。
二、领域大模型落地,任务场景要比模型能力更重要。
虽说在有产品上做升级,是代价最小的落地方式,但GPT4、AutoGPT已经把人们胃口调的很高,所有人都希望直接提出一个诉求,大模型直接解决。但这对现有领域模型是十分困难的,所以在哪些场景上来用大模型是很关键的,并且如何将模型进行包装,及时在模型能力不足的情况下,也可以让用户有一个很好的体验。
现在很多人的疑惑是,先不说有没有大模型,就算有了大模型都不知道在哪里使用,在私有领域都找不到一个Special场景。
所以最终大模型的落地,拼的不是模型效果本身,而是一整套行业解决方案,“Know How”成为了关键要素。
三、大多数企业最终落地的模型规格限制在了13B。
由于国情,大多数企业最终落地的方案应该是本地化部署,那么就会涉及硬件设备的问题。我并不绝的很有很多企业可以部署的起100B级别的模型,感觉真实部署限制在了10B级别。即使现在很多方法(例如:llama.cpp)可以对大模型进行加速,但100B级别的模型就算加速了,也是庞大资源消耗。
我之前说过“没有体验过33B模型的人,只会觉得13B就够”,更大的模型一定要搞,但不影响最后落地的是10B级别。
———————End———————
新生态,创未来 | 2023RT-Thread 开发者大会开启报名
邀请你参加 2023 RT-Thread 开发者大会的六大理由
1、刷新RT-Thread最新技术动态和产业服务能力
2、聆听行业大咖分享,洞察产业趋势
3、丰富的技术和产品展示,前沿技术发展和应用
4、绝佳的实践机会:AIOT、MPU、RISC-V...
5、精美伴手礼人手一份开发板盲盒和免费午餐
6、黑科技满点~滴水湖地铁口安排无人车接送至会场
立刻扫码报名吧

-
RT-Thread
+关注
关注
32文章
1657浏览量
45449
原文标题:【嵌入式AI简报20231117期】面对未来AI的三大挑战!
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
MathWorks携手EDGE AI Foundation:重塑嵌入式AI工程化落地新范式
MathWorks 加入 EDGE AI FOUNDATION,推进面向工程化系统的嵌入式 AI 发展
嵌入式AI开发必看:杜绝幻觉,才是工业级IDE的核心底气
使用瑞萨电子Reality AI Utilities工具加速嵌入式AI开发

还在手动拼接 AI 代码?你的 IDE 早就该升级了
2026年,嵌入式行业如何抢占AI红利?

嵌入式软件单元测试中AI自动化与人工检查的协同机制研究:基于专业工具的实证分析
重磅合作!Quintauris 联手 SiFive,加速 RISC-V 在嵌入式与 AI 领域落地
龙智解读:AI时代的嵌入式开发挑战以及Perforce QAC、Tessy等工具链的落地应用

嵌入式AI现在如何?




评论