 ImPosing:用于视觉定位的隐式姿态编码
ImPosing:用于视觉定位的隐式姿态编码

主要内容:
提出了一种新的基于学习的用于车辆上的视觉定位算法,该算法可以在城市规模的环境中实时运行。
算法设计了隐式姿态编码,通过2个独立的神经网络将图像和相机姿态嵌入到一个共同的潜在表示中来计算每个图像-姿态对的相似性得分。通过以分层的方式在潜在空间来评估候选者,相机位置和方向不是直接回归的,而是逐渐细化的。算法占的存储量非常紧凑且与参考数据库大小无关。
Pipeline:
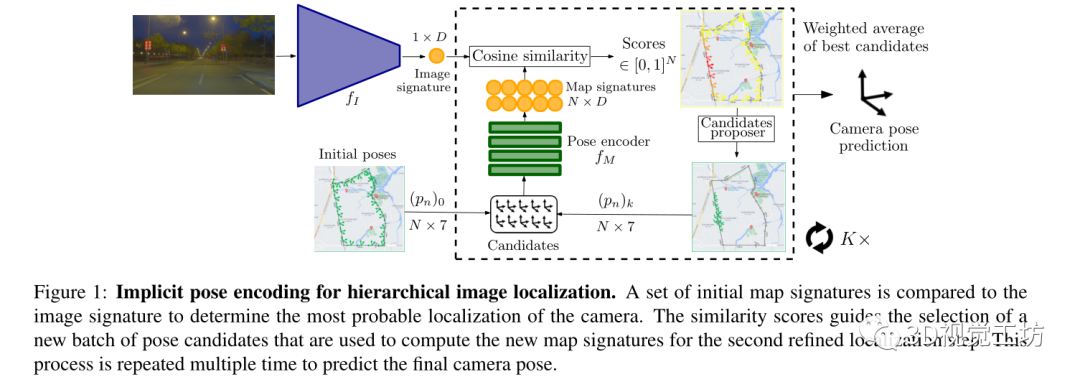
输入为查询图像
输出为查询图像的六自由度姿态(t,q)∈SE(3),t是平移向量,q是旋转四元数。
训练是在带有相机姿态label的数据库图像上进行训练,没有用额外的场景3D模型。
先通过图像编码器计算表示图像向量。然后通过评估分布在地图上的初始姿态候选来搜索相机姿态。姿态编码器对相机姿态进行处理以产生可以与图像向量相匹配的潜在表示,每个候选姿态都会有一个基于到相机姿态的距离的分数。高分提供了用于选择新候选者的粗略定位先验。通过多次重复这个过程使候选池收敛到实际的相机姿态。
论文技术点:
图像编码器:
使用图像编码器从输入的查询图像计算图像特征向量。
编码器架构包括一个预训练的CNN backbone,然后是全局平均池以及一个具有d个输出神经元的全连接层。
特征向量比图像检索中常用的全局图像描述符小一个数量级(使用d=256)以便在随后的步骤中将其与一大组姿态候选进行有效比较。
初始姿态候选:
起点是一组N个相机姿态,这是从参考姿态(=训练时相机姿态)中采样。通过这种初始选择为定位过程引入了先验,类似于选择锚点姿态。
姿态编码器:
姿态候选通过一个神经网络处理,输出潜在向量,这种隐式表示学习到了给定场景中的相机视点与图像编码器提供的特征向量之间的对应关系。
首先使用傅立叶特征将相机姿态的每个分量(tx,ty,tz,qx,qy,qz,qw)投影到更高维度:
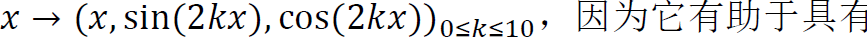 ,因为它有助于具有低维输入的网络拟合高频函数。然后使用具有4层256个神经元和隐藏层为ReLU激活的MLP。每一组候选姿态都是在一次batch的前向传递中计算出来的。
,因为它有助于具有低维输入的网络拟合高频函数。然后使用具有4层256个神经元和隐藏层为ReLU激活的MLP。每一组候选姿态都是在一次batch的前向传递中计算出来的。
相似性分数:
为每个图像-姿态对计算余弦相似性来获得相似性得分s。
在点积之后添加一个ReLU层,使得s∈[0,1]。
直观地说,其目标是学习与实际相机姿态接近的候选姿态的高分。
有了这个公式后可以评估关于相机姿态的假设,并搜索得分高的姿态候选者。
相似性分数定义为:
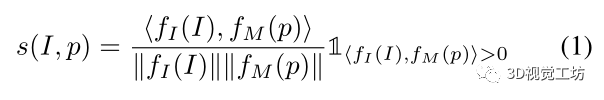
建议新的候选姿态:
基于在上一次迭代中使用的姿态候选获得的分数,为这一次迭代选择新的姿态候选。
首先选择得分最高的B=100的姿态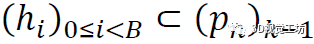
然后从(hi)中以高斯混合模型的方式对新的候选者进行采样:
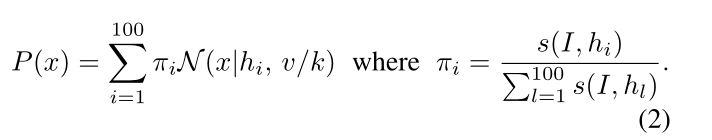
迭代姿态优化:
在每次迭代之后,将噪声向量除以2,使得新的候选者被采样为更接近先前的高分。
因此可以在千米级地图中收敛到精确的姿态估计,同时只评估有限的稀疏姿态集。在每个时间步长独立评估每个相机帧,但可以使用以前时间步长的定位先验来减少车辆导航场景中的迭代次数。
每次迭代时所选姿态的示例如图2所示。通过对初始姿态的N个候选进行采样,保留了一个恒定的记忆峰值。

姿态平均:
最终的相机姿态估计是256个得分较高的候选姿态的加权平均值,与直接选择得分最高的姿态相比,它具有更好的效果。使用分数作为加权系数,并实现3D旋转平均。
损失函数:
通过计算参考图像和以K种不同分辨率采样的姿态候选者之间的分数来训练网络,
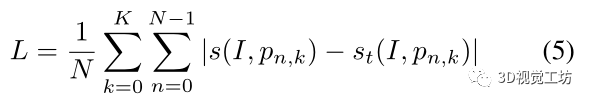
其中,st是基于相机姿态和候选姿态之间的平移和旋转距离来定义。
实验:
与最近的方法在几个数据集上进行了比较,这些数据集涵盖了大规模室外环境中的各种自动驾驶场景。
由于户外环境的动态部分(移动物体、照明、遮挡等),这项任务极具挑战性。
验证了其算法能够在9个不同的大型室外场景中进行精确定位。
然后展示了算法可以扩展到多地图场景
Baseline:
将ImPosing与基于学习的方法进行比较。使用CoordiNet报告了牛津数据集上绝对姿态回归结果作为基线。
将ImPosing与检索进行比较,使用了NetVLAD和GeM,使用全尺寸图像来计算全局图像描述符,然后使用余弦相似度进行特征比较,然后对前20个数据库图像的姿态进行姿态平均。
没有使用基于结构的方法进行实验,因为使用3D模型进行几何推理,这些方法比更准确,但由于存储限制使得嵌入式部署变得困难。
在Oxford RobotCar和Daoxiang Lake数据集上的定位误差比较
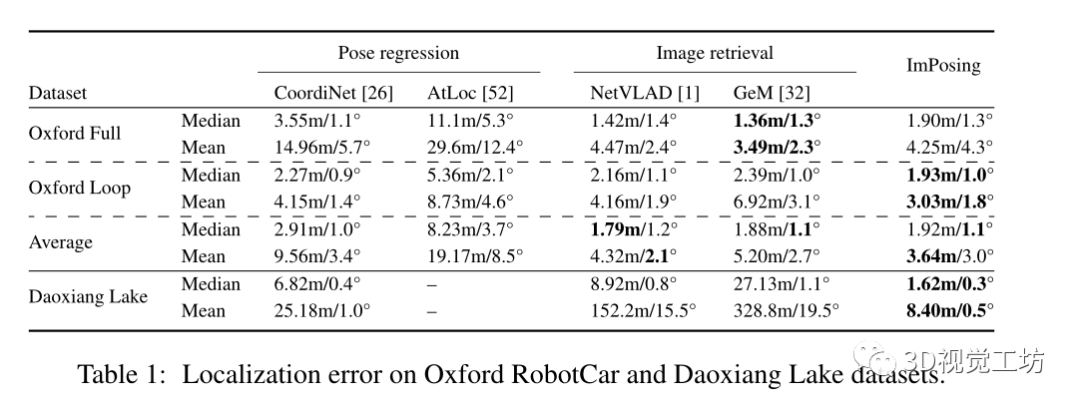
Daoxiang Lake是一个比Oxford RobotCar更具挑战性的数据集,因为它的重复区域几乎没有判别特征,环境也多种多样(城市、城郊、高速公路、自然等)。因此,图像检索的性能比姿态回归差。ImPosing要准确得多,并且显示出比竞争对手小4倍的中值误差。
在4Seasons数据集上的比较:
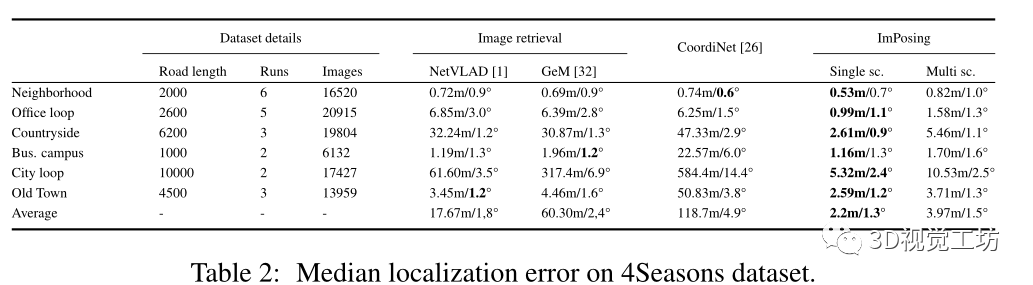
4Seasons数据集包含慕尼黑地区在不同季节条件下的各种场景(城市、居民区、乡村)中记录的数据。
因为是针对车辆部署的视觉定位算法,比较了各种算法的性能效率:
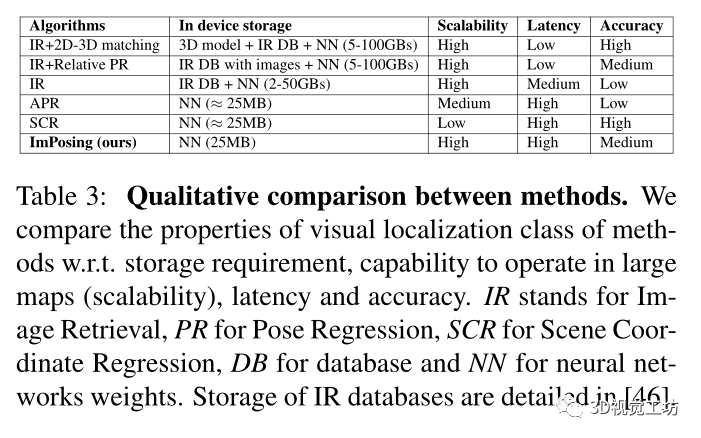
论文的算法只需要在设备中存储神经网络权重和初始姿态候选,其中图像编码器为23MB,姿态编码器小于1MB,初始姿态候选为1MB。
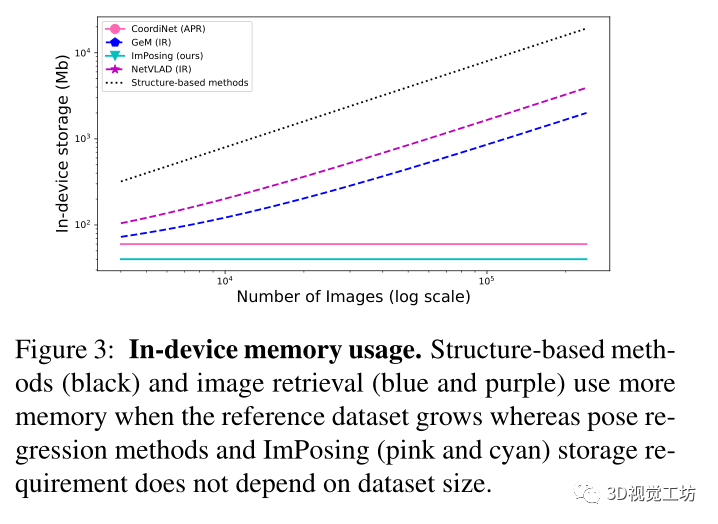
在图3中报告了不同类别视觉定位方法的内存占用相对于参考数据库大小的缩放规律。这是有大量数据可用的自动驾驶场景中的一个重要方面。对于给定的地图,基于学习的方法具有恒定的内存需求,因为地图信息嵌入在网络权重中。
总结:
提出了一种新的视觉定位范式,通过使用地图的隐式表示,将相机姿态和图像特征连接在一个非常适合定位的潜在高维流形中。
证明了通过一个简单的姿态候选采样过程,能够估计图像的绝对姿态。
通过提供一种高效准确的基于图像的定位算法,该算法可以实时大规模操作,使其可以直接应用于自动驾驶系统。
但是方法的准确性在很大程度上取决于可用的训练数据的数量。而且与回归的方法类似,其不会泛化到远离训练示例的相机位置。
提出的方法可以在许多方面进行改进,包括探索更好的姿态编码器架构;找到一种隐式表示3D模型的方法,将隐式地图表示扩展到局部特征,而不是全局图像特征。
审核编辑 :李倩
-
编码器
+关注
关注
45文章
4011浏览量
143373 -
神经网络
+关注
关注
42文章
4842浏览量
108184 -
算法
+关注
关注
23文章
4807浏览量
98569
原文标题:WACV 2023 | ImPosing:用于视觉定位的隐式姿态编码
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

【芯灵思A83T试用申请】嵌入式视觉--远距离物体跟踪与定位
嵌入式姿态测量系统的姿态参数怎么计算?
基于三元Golay隐写码的快速隐写算法
TPMS外置编码存储器式轮胎定位技术设计方案
面向AAV压缩域的通用隐写分析方法
网络编码姿态监控体域网的容错性
医疗器械视觉定位应用
关于3D视觉定位技术详细解析
STM32操作增量式编码器(二)----使用编码器接口实现定位

机器视觉检测与机器视觉定位的区别与应用
一种基于RGB-D图像序列的协同隐式神经同步定位与建图(SLAM)系统
一种将NeRFs应用于视觉定位任务的新方法




评论