 深入解读Grace CPU芯片架构
深入解读Grace CPU芯片架构

NVIDIA Grace CPU是 NVIDIA 开发的第一款数据中心 CPU。通过将 NVIDIA 专业知识与 Arm 处理器、片上结构、片上系统 (SoC) 设计和弹性高带宽低功耗内存技术相结合。参考内容“NVIDIA GraceCPU处理器合集”。
NVIDIA Grace CPU 从头开始构建,以创建世界上第一个用于计算的超级芯片(super chip)。超级芯片的核心是NVLink Chip-2-Chip (C2C),它允许 NVIDIA Grace CPU 以 900 GB/s 的双向带宽与超级芯片中的另一个 NVIDIA Grace CPU 或NVIDIA Hopper GPU进行通信。
NVIDIA Grace Hopper Superchip将节能、高带宽的 NVIDIA Grace CPU 与功能强大的 NVIDIA H100 Hopper GPU 结合使用 NVLink-C2C,以最大限度地提高强大的高性能计算 (HPC) 和巨型 AI 工作负载的能力。 NVIDIA Grace CPU 超级芯片是使用两个通过 NVLink-C2C 连接的 Grace CPU 构建的。该超级芯片建立在现有 Arm 生态系统的基础上,为 HPC、要求苛刻的云工作负载以及高性能和高能效的密集基础设施创建了首个毫不妥协的 Arm CPU。 在本文中,您将了解 NVIDIA Grace CPU 超级芯片以及提供 NVIDIA Grace CPU 性能和能效的技术。有关详细信息。
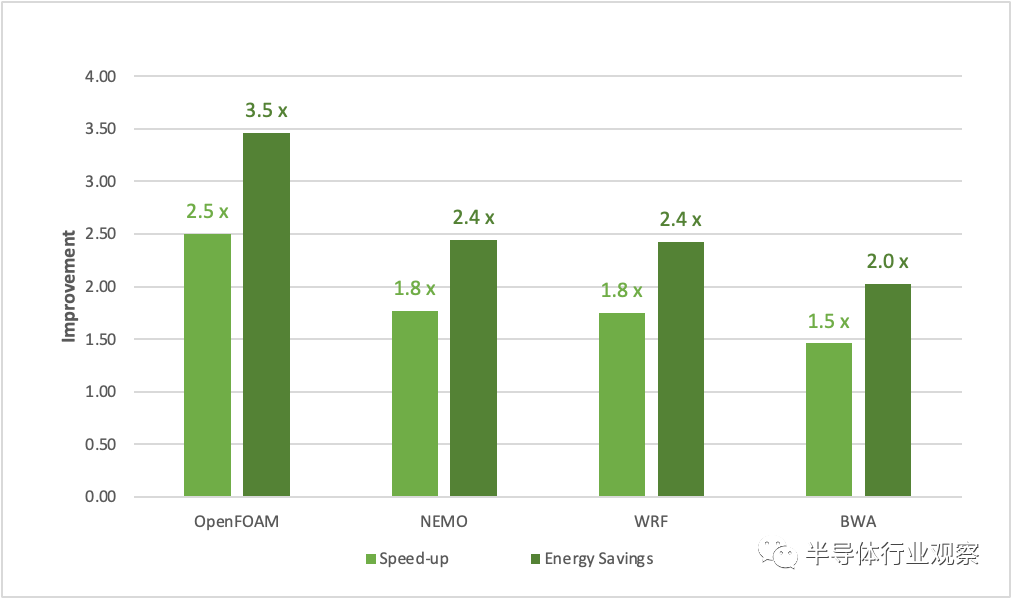
图 1. 与双插槽 Milan 7763 CPU 相比,NVIDIA Grace CPU Superchip 上应用程序的性能和节能效果
专为 HPC 和 AI 工作负载打造的超级芯片
NVIDIA Grace CPU 超级芯片通过将旗舰双路 x86-64 服务器或工作站平台提供的性能水平集成到单个超级芯片中,代表了计算平台设计的一场革命。高效的设计可在较低的功率范围内实现 2 倍的计算密度。

NVIDIA Grace CPU 旨在提供高单线程性能、高内存带宽和出色的数据移动能力,每瓦性能领先。NVIDIA Grace CPU Superchip 结合了两个连接超过 900 GB/s 双向带宽 NVLink-C2C 的 NVIDIA Grace CPU,提供 144 个高性能 Arm Neoverse V2 内核和高达 1 TB/s 带宽的数据中心级 LPDDR5X 内存,带纠错码( ECC)内存。
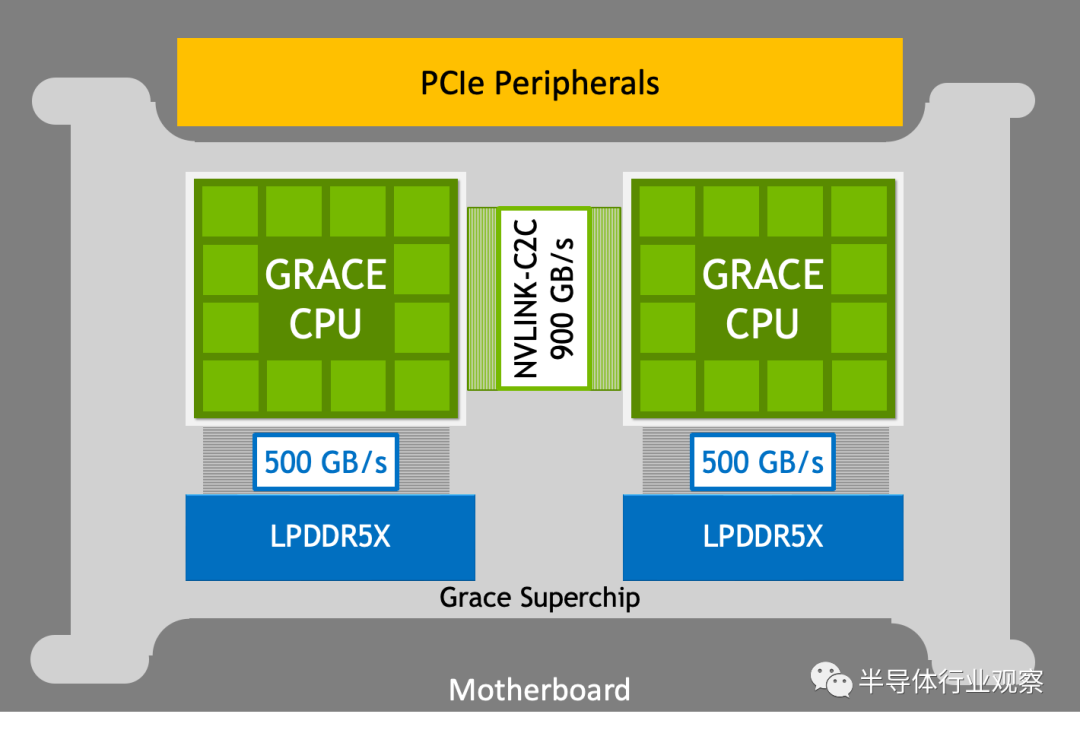
图2. 具有 900 GB/s NVLink-C2C 的 NVIDIA Grace CPU 超级芯片
使用 NVLink-C2C 互连缓解瓶颈
为了扩展到 144 个 Arm Neoverse V2 内核并在两个 CPU 之间移动数据,NVIDIA Grace CPU Superchip 需要在 CPU 之间建立高带宽连接。NVLink C2C 互连在两个 NVIDIA Grace CPU 之间提供高带宽直接连接,以创建 NVIDIA Grace CPU 超级芯片。
使用 NVIDIA Scalable Coherency Fabric 扩展内核和带宽
现代 CPU 工作负载需要快速的数据移动。由 NVIDIA 设计的可扩展一致性结构 (SCF) 是一种网状结构和分布式缓存架构,旨在扩展内核和带宽(图 3)。SCF 提供超过 3.2 TB/s 的总二分带宽,以保持数据在 CPU 内核、NVLink-C2C、内存和系统 IO 之间流动。 CPU 核心和 SCF 缓存分区分布在整个网格中,而缓存交换节点通过结构路由数据并充当 CPU、缓存内存和系统 IO 之间的接口。NVIDIA Grace CPU 超级芯片在两个芯片上具有 234 MB 的分布式三级缓存。
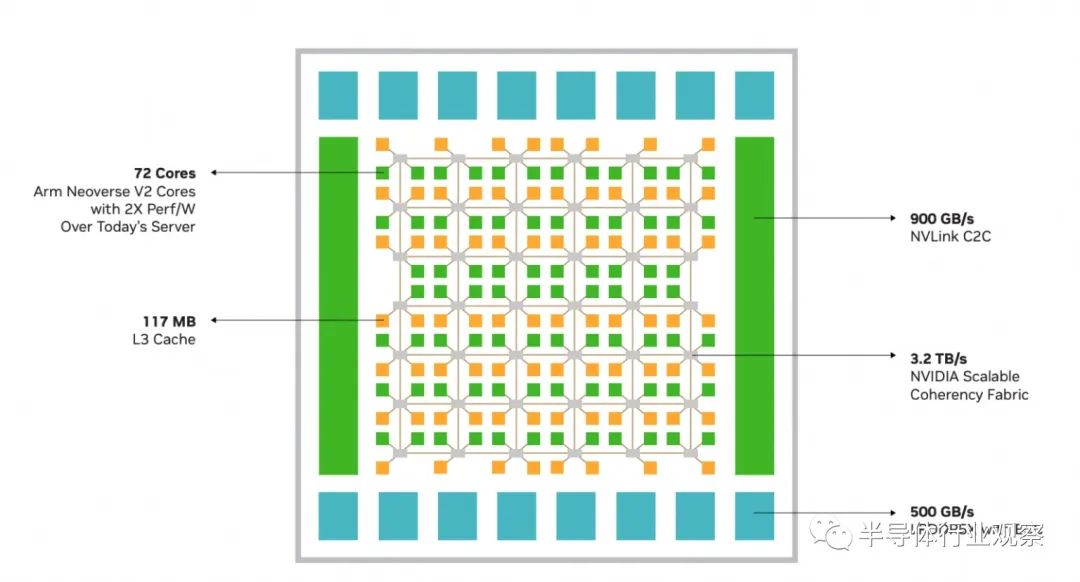
图3. NVIDIA Grace CPU 和可扩展一致性结构
LPDDR5X
能效和内存带宽都是数据中心 CPU 的关键组成部分。NVIDIA Grace CPU Superchip 使用高达 960 GB 的服务器级低功耗 DDR5X (LPDDR5X) 内存和 ECC。此设计为大规模 AI 和 HPC 工作负载实现了带宽、能效、容量和成本的最佳平衡。 与八通道 DDR5 设计相比,NVIDIA Grace CPU LPDDR5X 内存子系统以每千兆字节每秒八分之一的功率提供高达 53% 的带宽,同时成本相似。HBM2e 内存子系统本可以提供大量内存带宽和良好的能效,但每 GB 成本是其 3 倍多,并且仅为 LPDDR5X 可用最大容量的八分之一。 LPDDR5X 较低的功耗降低了整体系统功率要求,并使更多资源能够用于 CPU 内核。紧凑的外形使基于 DIMM 的典型设计的密度提高了 2 倍。
NVIDIA Grace CPU I/O
NVIDIA Grace CPU Superchip 支持多达 128 条用于 IO 连接的 PCIe Gen 5 通道。8 个 PCIe Gen 5 x16 链路中的每一个都支持高达 128 GB/s 的双向带宽,并且可以分为 2x8 个以提供额外的连接,并且可以支持各种 PCIe 插槽形状因数,开箱即用地支持NVIDIA GPU和NVIDIA DPU、NVIDIA ConnectX SmartNIC、E1.S 和 M.2 NVMe 设备、模块化 BMC 选项等。
NVIDIA Grace CPU 核心架构
为了实现最大的工作负载加速,快速高效的 CPU 是系统设计的重要组成部分。Grace CPU 的核心是 Arm Neoverse V2 CPU 内核。Neoverse V2 是 Arm V 系列基础架构 CPU 内核中的最新产品,经过优化可提供领先的每线程性能,同时与传统 CPU 相比提供领先的能效。

图4. NVIDIA Grace CPU 的 Arm Neoverse V2 内核
Arm架构
NVIDIA Grace CPU Neoverse V2 核心实现了 Armv9-A 架构,它将 Armv8-A 架构中定义的架构扩展到 Armv8.5-A。为 Armv8.5-A 之前的 Armv8 架构构建的任何应用程序二进制文件都将在 NVIDIA Grace CPU 上执行。这包括针对 Ampere Altra、AWS Graviton2 和AWS Graviton3等 CPU 的二进制文件。
SIMD指令
Neoverse V2 在 4×128 位配置中实现了两个单指令多数据 (SIMD) 向量指令集:可扩展向量扩展版本 2 (SVE2) 和高级 SIMD (NEON)。四个 128 位功能单元中的每一个都可以退出 SVE2 或 NEON 指令。这种设计使更多代码能够充分利用 SIMD 性能。SVE2 通过高级指令进一步扩展了 SVE ISA,这些指令可以加速机器学习、基因组学和密码学等关键 HPC 应用程序。
原子操作(Atomic operation)
NVIDIA Grace CPU 支持在 Armv8.1 中首次引入的大型系统扩展 (LSE)。LSE 提供低成本的原子操作,可以提高 CPU 到 CPU 通信、锁和互斥锁的系统吞吐量。这些指令可以对整数数据进行操作。所有支持 NVIDIA Grace CPU 的编译器都将在同步函数中自动使用这些指令,例如 GNU 编译器集合__atomic内置函数和std::atomic. 当使用 LSE 原子而不是加载/存储独占时,改进可以达到一个数量级。
Armv9 附加功能
NVIDIA Grace CPU实现了Armv9 产品组合的多项关键功能,可在通用数据中心 CPU 中提供实用程序,包括但不限于加密加速、可扩展分析扩展、虚拟化扩展、全内存加密、安全启动等。
NVIDIA Grace CPU 软件
NVIDIA Grace CPU Superchip 旨在为软件开发人员提供符合标准的平台。 NVIDIA Grace CPU 符合 Arm 服务器基础系统架构 (SBSA),以支持符合标准的硬件和软件接口。此外,为了在基于 Grace CPU 的系统上启用标准引导流程,Grace CPU 被设计为支持 Arm 服务器基本引导要求 (SBBR)。所有主要的 Linux 发行版,以及它们提供的大量软件包,都可以在 NVIDIA Grace CPU 上完美运行,无需修改。 编译器、库、工具、分析器、系统管理实用程序以及用于容器化和虚拟化的框架现已上市,并且可以像在任何其他数据中心 CPU 上一样轻松地在 NVIDIA Grace CPU 上安装和使用。 此外,整个 NVIDIA 软件堆栈都可用于 NVIDIA Grace CPU。NVIDIA HPC SDK 和每个 CUDA 组件都有 Arm 原生安装程序和容器。NVIDIA GPU Cloud (NGC) 还提供深度学习、机器学习和针对 Arm 优化的 HPC 容器。NVIDIA Grace CPU 遵循主流 CPU 设计原则,并且与任何其他服务器 CPU 一样进行编程。
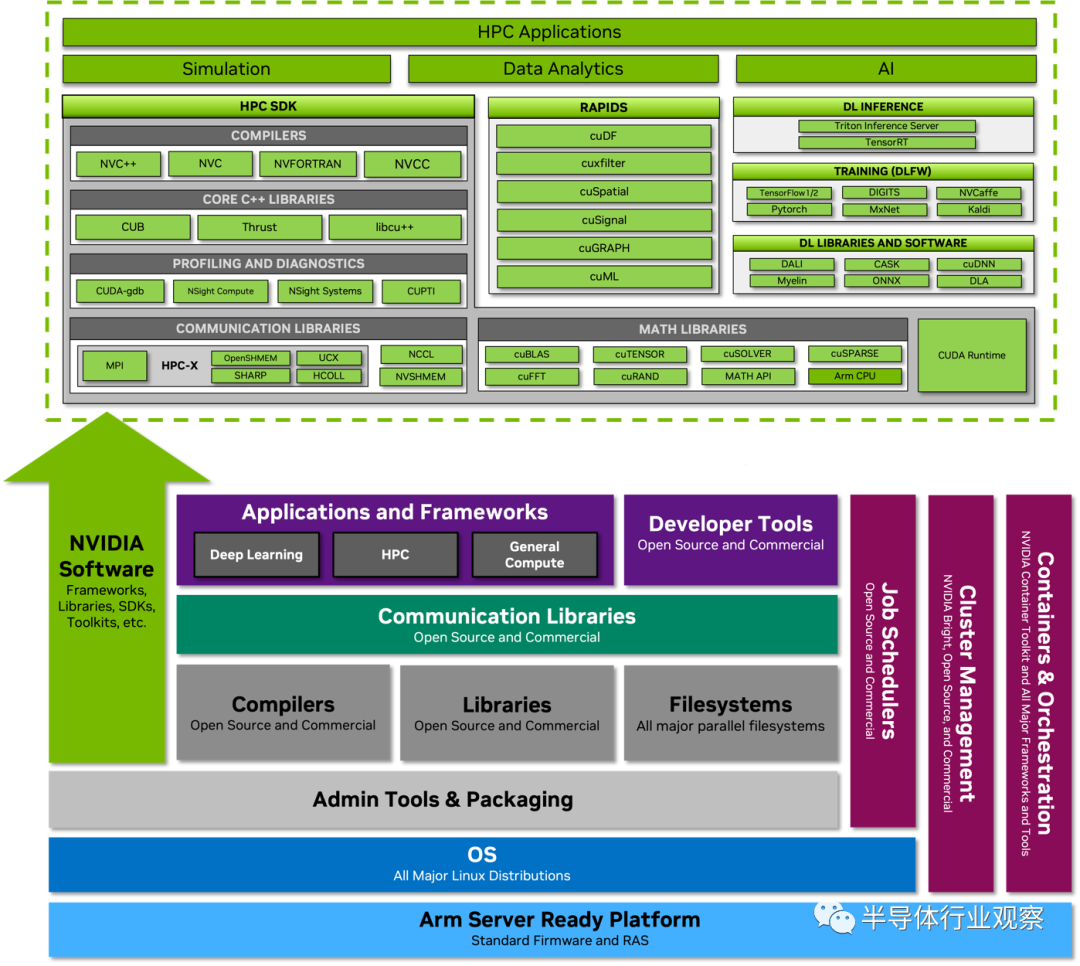
图 5. NVIDIA Grace CPU 软件生态系统将用于 CPU、GPU 和 DPU 的全套 NVIDIA 软件与完整的 Arm 数据中心生态系统相结合
审核编辑 :李倩
-
处理器
+关注
关注
68文章
20395浏览量
255745 -
cpu
+关注
关注
68文章
11382浏览量
226559 -
NVIDIA
+关注
关注
14文章
5732浏览量
110361 -
芯片架构
+关注
关注
1文章
33浏览量
14916
原文标题:深入解读Grace CPU芯片架构
文章出处:【微信号:架构师技术联盟,微信公众号:架构师技术联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
深入解析MC9S08DZ128系列芯片:特性、数据手册变更及应用指南
TLE8262 - 2E通用系统基础芯片HERMES数据手册解读
深入解析MAX17410:IMVP6+ CPU核心电源的理想控制器
全球首创!RISC-V+AI架构高性能服务器CPU成功点亮
深入剖析LTC3541-3:高效电源管理芯片的多面解读
德州仪器(TI)解读汽车区域架构中的 TSN:启用以太网环形架构和 AVB 分布式音频
TE Connectivity 2.0mm信号GRACE INERTIA连接器技术解析
Imagination亮相汽车芯片产业大会 深入解读高安全GPU+AI融合计算架构

深入剖析RabbitMQ高可用架构设计
探索CPU架构的奥秘,揭秘高性能计算的隐形引擎
GB10超级芯片开卖!正式杀入AI PC
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理
RISC-V架构CPU的RAS解决方案

瑞萨365 深度解读



评论