 密集单目SLAM的概率体积融合概述
密集单目SLAM的概率体积融合概述

笔者简述: 这篇论文主要还是在于深度估计这块,深度估计由于硬件设备的不同是有很多方法的,双目,RGBD,激光雷达,单目,其中最难大概就是单目了。在该论文中作者利用BA导出的信息矩阵来估计深度和深度的不确定性,利用深度的不确定性对3D体积重建进行加权三维重建,在精度和实时性方面都得到了不错的结果,值得关注。
摘要
我们提出了一种利用深度密集单目 SLAM和快速不确定性传播从图像重建 3D 场景的新方法。所提出的方法能够密集、准确、实时地 3D 重建场景,同时对来自密集单目 SLAM 的极其嘈杂的深度估计具有鲁棒性。不同于以前的方法,要么使用临时深度过滤器,要么从 RGB-D 相机的传感器模型估计深度不确定性,我们的概率深度不确定性直接来自SLAM中底层BA问题的信息矩阵。
我们表明,由此产生的深度不确定性为体积融合的深度图加权提供了极好的信号。如果没有我们的深度不确定性,生成的网格就会很嘈杂并且带有伪影,而我们的方法会生成一个精确的 3D 网格,并且伪影要少得多。我们提供了具有挑战性的 Euroc 数据集的结果,并表明我们的方法比直接融合单目 SLAM 的深度提高了 92% 的准确性,与最佳竞争方法相比提高了 90%
1. 简介
单目图像的 3D 重建仍然是最困难的计算机视觉问题之一。仅从图像实时实现 3D 重建就可以实现机器人、测量和游戏中的许多应用,例如自动驾驶汽车、作物监测和增强现实。 虽
然许多 3D 重建解决方案基于 RGB-D 或激光雷达传感器,但单目图像的场景重建提供了更方便的解决方案。
RGB-D 相机在某些条件下可能会失效,例如在阳光下,激光雷达仍然比单目 RGB 相机更重、更昂贵。或者,立体相机将深度估计问题简化为一维视差搜索,但依赖于在实际操作中容易出现错误校准的相机的精确校准。相反,单目相机便宜、重量轻,代表了最简单的传感器配置来校准。
不幸的是,由于缺乏对场景几何形状的明确测量,单目 3D 重建是一个具有挑战性的问题。
尽管如此,最近通过利用深度学习方法在基于单眼的 3D 重建方面取得了很大进展。鉴于深度学习目前在光流 [23] 和深度 [29] 估计方面取得了最佳性能,因此大量工作已尝试将深度学习模块用于 SLAM。例如,使用来自单目图像 [22]、多幅图像的深度估计网络,如多视图立体 [10],或使用端到端神经网络 [3]。
然而,即使有了深度学习带来的改进,由此产生的重建也容易出现错误和伪影,因为深度图大部分时间都是嘈杂的并且有异常值。
在这项工作中,我们展示了如何从使用密集单目 SLAM 时估计的嘈杂深度图中大幅减少 3D 重建中的伪影和不准确性。为实现这一点,我们通过根据概率估计的不确定性对每个深度测量值进行加权来体积融合深度图。
与以前的方法不同,我们表明,在单目 SLAM 中使用从BA问题的信息矩阵导出的深度不确定性导致令人惊讶的准确 3D 网格重建。我们的方法在映射精度方面实现了高达 90% 的改进,同时保留了大部分场景几何。
贡献:我们展示了一种体积融合密集深度图的方法,该深度图由密集 SLAM 中的信息矩阵导出的不确定性加权。我们的方法使场景重建达到给定的最大可容忍不确定性水平。
与竞争方法相比,我们可以以更高的精度重建场景,同时实时运行,并且仅使用单目图像。我们在具有挑战性的 EuRoC 数据集中实现了最先进的 3D 重建性能。
图 1.(左)原始 3D 点云通过反向投影逆深度图从密集单眼 SLAM 生成,没有过滤或后处理。 (右)深度图的不确定性感知体积融合后估计的 3D 网格。
尽管深度图中有大量噪声,但使用我们提出的方法重建的 3D 网格是准确和完整的。
EuRoC V2 01 数据集。
2. 相关工作
我们回顾了两个不同工作领域的文献:密集 SLAM 和深度融合。
2.1.Dense SLAM
实现Dense SLAM 的主要挑战是(i)由于要估计的深度变量的剪切量导致的计算复杂性,以及(ii)处理模糊或缺失的信息以估计场景的深度,例如无纹理表面或混叠图像。 从历史上看,第一个问题已通过解耦姿态和深度估计而被绕过。
例如,DTAM [12] 通过使用与稀疏 PTAM [9] 相同的范例来实现Dense SLAM,它以解耦的方式首先跟踪相机姿势,然后跟踪深度。第二个问题通常也可以通过使用提供明确深度测量的 RGB-D 或激光雷达传感器或简化深度估计的立体相机来避免。
尽管如此,最近对Dense SLAM 的研究在这两个方面取得了令人瞩目的成果。为了减少深度变量的数量,CodeSLAM [3] 优化了从图像推断深度图的自动编码器的潜在变量。通过优化这些潜在变量,问题的维数显着降低,而生成的深度图仍然很密集。
Tandem [10] 能够通过在单眼深度估计上使用预训练的 MVSNet 式神经网络,然后通过执行帧到模型的光度跟踪来解耦姿态/深度问题,从而仅使用单眼图像重建 3D 场景。 Droid-SLAM [24] 表明,通过采用最先进的密集光流估计架构 [23] 来解决视觉里程计问题,有可能在各种情况下取得有竞争力的结果具有挑战性的数据集(例如 Euroc [4] 和 TartanAir [25] 数据集),即使它需要全局束调整以优于基于模型的方法。
Droid-SLAM 通过使用下采样深度图避免了维度问题,随后使用学习的上采样运算符对深度图进行上采样。最后,有无数的作品避免了上述的维度和歧义问题,但最近已经取得了改进的性能。例如,iMap [21] 和 Nice-SLAM [31] 可以通过解耦姿态和深度估计以及使用 RGB-D 图像来构建精确的 3D 重建,并通过使用神经辐射场 [11] 实现光度精确重建.鉴于这些工作,我们可以期待未来学习的Dense SLAM 变得更加准确和稳健。
不幸的是,我们还不能从随意的图像集合中获得像素完美的深度图,将这些深度图直接融合到体积表示中通常会导致伪影和不准确。我们的工作利用 Droid-SLAM [24] 来估计每个关键帧的极其密集(但非常嘈杂)的深度图(参见图 1 中的左侧点云),我们通过根据深度的不确定性对深度进行加权,成功地将其融合到体积表示中,估计为边际协方差。
2.2.深度融合
绝大多数 3D 重建算法都基于将深度传感器提供的深度图融合到体积图 [13、15、17] 中。因此,大多数使用体积表示的文献都专注于研究获得更好深度图的方法,例如后处理技术,或融合深度时要使用的加权函数 [5、13、14、28]。大多数文献,通过假设深度图来自传感器,专注于传感器建模。或者,在使用深度学习时,类似的方法是让神经网络学习权重。例如,RoutedFusion [26] 和 NeuralFusion [27] 学习从 RGB-D 扫描中去噪体积重建。
在我们的例子中,由于深度图是通过密集BA估计的,我们建议使用估计深度的边际协方差直接融合深度图。这在计算上很难做到,因为在Dense SLAM 中,每个关键帧的深度数可能与帧中的像素总数一样高 (≈ 105)。我们在下面展示了我们如何通过利用信息矩阵的块稀疏结构来实现这一点。
3. 方法
我们方法的主要思想是将由概率不确定性加权的极其密集但嘈杂的深度图融合到体积图中,然后提取具有给定最大不确定性界限的 3D 网格。为实现这一目标,我们利用 Droid-SLAM 的公式来生成姿态估计和密集深度图,并将其扩展为生成密集不确定性图。 我们将首先展示如何从基础BA问题的信息矩阵中有效地计算深度不确定性。然后,我们提出了我们的融合策略以生成概率合理的体积图。最后,我们展示了如何在给定的最大不确定性范围内从体积中提取网格。
3.1.密集单目 SLAM
其核心,经典的基于视觉的逆深度间接 SLAM 解决了束调整 (BA) 问题,其中 3D 几何被参数化为每个关键帧的一组(逆)深度。这种结构的参数化导致了一种解决密集 BA 问题的极其有效的方法,可以将其分解为熟悉的箭头状块稀疏矩阵,其中相机和深度按顺序排列: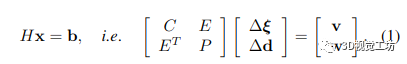
其中 H 是 Hessian 矩阵,C 是块相机矩阵,P 是对应于点的对角矩阵(每个关键帧每个像素一个逆深度)。我们用 Δξ 表示 SE(3) 中相机姿态的李代数的增量更新,而 Δd 是每像素逆深度的增量更新。
为了解决 BA 问题,首先计算 Hessian H 相对于 P 的 Schur 补码(表示为 H/P )以消除逆深度变量: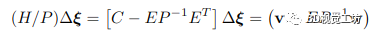
鉴于 P −1 包含可以并行执行的每个对角元素的逐元素求逆,可以快速计算 Schur 补码,因为 P 是一个大的对角矩阵 生成的矩阵 (H/P ) 称为缩减相机矩阵。方程式中的方程组。 (2) 仅取决于关键帧姿势。因此,我们首先使用 (H/P ) = LLT 的 Cholesky 分解求解姿势,使用前代然后后代。然后使用生成的姿态解 Δξ 来求解逆深度图 Δd,如下所示: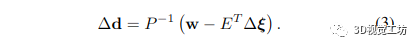
尽管如此,为了对实时 SLAM 进行足够快的推理,逆深度图的估计分辨率低于原始图像的 1/8,在我们的例子中为 69×44 像素(Euroc 数据集的原始分辨率为 752×480,这我们首先下采样到 512×384)。一旦解决了这个低分辨率深度图,学习的上采样操作(首先在 [23] 中显示用于光流估计,并在 Droid-SLAM 中使用)恢复全分辨率深度图。
这使我们能够有效地重建与输入图像具有相同分辨率的密集深度图 使用高分辨率深度图解决相同的 BA 问题对于实时 SLAM 来说是非常昂贵的,深度不确定性的计算进一步加剧了这个问题。
我们相信这就是为什么其他作者没有使用从 BA 导出的深度不确定性进行实时体积 3D 重建的原因:使用全深度 BA 的成本高得令人望而却步,而使用稀疏深度 BA 会导致深度图过于稀疏,无法进行体积重建重建。
替代方案一直是使用稀疏 BA 进行姿态估计和几何形状的第一次猜测,然后是与稀疏 BA 中的信息矩阵无关的致密化步骤 [20]。
这就是为什么其他作者建议对密集 SLAM 使用替代 3D 表示,例如 CodeSLAM [3] 中的潜在向量。我们的方法也可以应用于 CodeSLAM
3.2.逆深度不确定性估计
鉴于 Hessian 的稀疏模式,我们可以有效地提取每像素深度变量所需的边际协方差。逆深度图 Σd 的边际协方差由下式给出: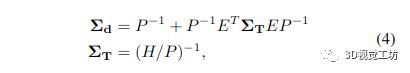
其中 ΣT 是姿态的边际协方差。不幸的是,H/P 的完全反演计算成本很高。然而,由于我们已经通过将 H/P 分解为其 Cholesky 因子来解决原始 BA 问题,我们可以通过以下方式重新使用它们,类似于 [8]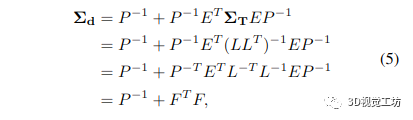
其中 F=L-1EP-1。因此,我们只需要反转下三角 Cholesky 因子 L,这是一个通过代入计算的快速操作。因此,我们可以有效地计算所有逆矩阵:P 的逆由每个对角线元素的逐元素逆给出,我们通过取反它的 Cholesky 因子来避免 (H/P ) 的完全逆。然后将矩阵相乘和相加就足够了: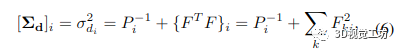
其中 di 是每个像素的逆深度之一。由于大多数操作都可以并行计算,因此我们利用了 GPU 的大规模并行性
3.3.深度上采样和不确定性传播
最后,由于我们想要一个与原始图像分辨率相同的深度图,我们使用 Raft [23] 中定义的凸上采样运算符对低分辨率深度图进行上采样,该运算符也在 Droid [24] 中使用.这种上采样操作通过采用低分辨率深度图中相邻深度值的凸组合来计算高分辨率深度图中每个像素的深度估计。通过以下方式为每个像素给出生成的深度估计: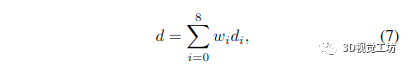
其中 wi 是学习的权重(更多细节可以在 Raft [23] 中找到),di 是我们正在计算深度的像素周围的低分辨率逆深度图中像素的逆深度(a 3 × 3 窗口用于采样相邻的深度值) 假设逆深度估计之间的独立性,得到的逆深度方差由下式给出: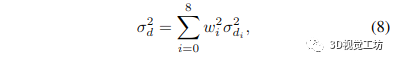
其中 wi 是用于方程式中的逆深度上采样的相同权重。 (7)式,为待计算像素周围低分辨率逆深度图中某个像素的逆深度方差。我们将逆深度和不确定性上采样 8 倍,从 69 × 44 分辨率到 512 × 384 分辨率。 到目前为止,我们一直在处理反深度,最后一步是将它们转换为实际深度和深度方差。我们可以使用非线性不确定性传播轻松计算深度方差: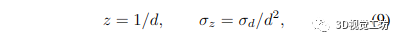
其中 z 是生成的深度,d 是反深度。
3.4.不确定性感知体积映射
鉴于每个关键帧可用的密集深度图,可以构建场景的密集 3D 网格。不幸的是,深度图由于它们的密度而非常嘈杂,因为即使是无纹理区域也会被赋予深度值。体积融合这些深度图降低了噪声,但重建仍然不准确并且被伪影破坏(参见图 4 中的“基线”,它是通过融合图 1 中所示的点云计算的) 虽然可以在深度图上手动设置过滤器(有关可能的深度过滤器示例,请参阅 PCL 的文档 [19])并且 Droid 实现了一个 ad-hoc 深度过滤器(参见图 4 中的 Droid),但我们建议改用估计的深度图的不确定性,这提供了一种稳健且数学上合理的方式来重建场景。
体积融合基于概率模型[7],其中假设每个深度测量是独立的和高斯分布的。在这个公式下,我们尝试估计的带符号距离函数 (SDF) φ 最大化了以下可能性: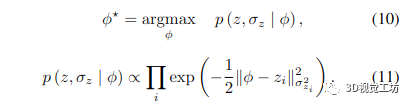
取负对数会导致加权最小二乘问题: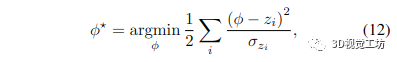
其解决方案是通过将梯度设置为零并求解 φ 获得的,从而导致所有深度测量的加权平均值:
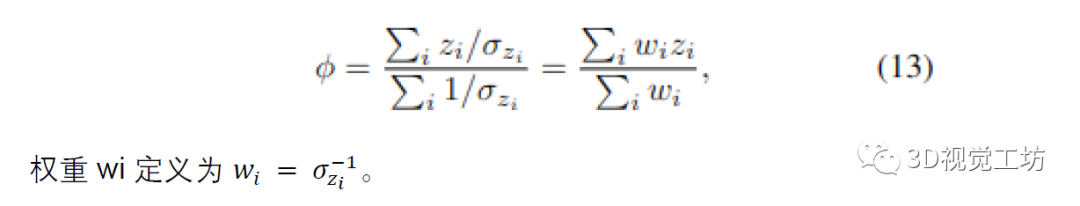
在实践中,通过使用运行平均值更新体积中的体素,为每个新的深度图增量计算加权平均值,从而得出熟悉的体积重建方程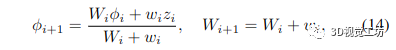
其中 Wi 是存储在每个体素中的权重。权重初始化为零,W0 = 0,TSDF 初始化为截断距离 τ,φ0 = τ(在我们的实验中,τ = 0.1m)。
上面的公式作为移动加权平均值,在使用的权重函数方面非常灵活。这种灵活性导致了融合深度图的许多不同方法,有时会偏离其概率公式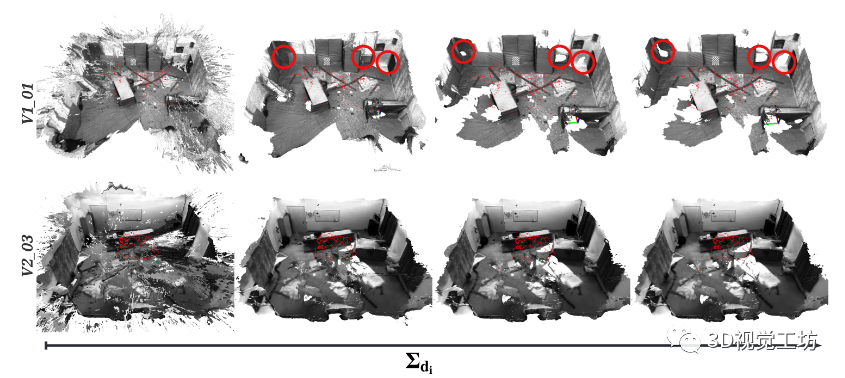
图 2. 给定最大允许网格不确定性 Σdi 的 3D 网格重建从无穷大上限(即最小权重 0.0,最左侧的 3D 网格)到 0.01(即最小权重 10,最右侧的 3D 网格)呈对数下降.由于高度不确定性,用红色圆圈突出显示的区域首先消失。这些对应于无纹理和混叠区域。两个最接近的红色圆圈对应于与图 3 中描绘的区域相同的区域。
大多数方法通过对所用深度传感器的误差分布进行建模来确定权重函数,无论是激光扫描仪、RGB-D 相机还是立体相机 [7、15、18]。例如,Nguyen 等人。 [14] 对来自 RGB-D 相机的残差进行建模,并确定深度方差由 z2 主导,z 是测量的深度。拜洛等人。 [5] 分析了各种权重函数,并得出结论,在表面后面线性递减的权重函数会导致最佳结果。
Voxblox [15] 将这两个工作组合成一个简化的公式,效果很好,它也被用于 Kimera [17] 在我们的例子中,不需要复杂的加权或传感器模型;深度不确定性是根据 SLAM 中固有的概率因子图公式计算的。具体来说,我们的权重与深度的边际协方差成反比,这是从方程式中的概率角度得出的。 (13).值得注意的是,这些权重来自数百个光流测量与神经网络估计的相关测量噪声的融合(GRU 在 Droid [24] 中的输出)。
3.5.不确定性界限的网格划分
鉴于我们的体素对带符号的距离函数具有概率合理的不确定性估计,我们可以提取不同级别的等值面以允许最大不确定性。我们使用行进立方体提取表面,只对那些不确定性估计低于最大允许不确定性的体素进行网格划分。生成的网格只有具有给定上限不确定性的几何体,而我们的体积包含所有深度图的信息 如果我们将不确定性边界设置为无穷大,即权重为 0,我们将恢复基线解决方案,该解决方案非常嘈杂。
通过逐渐减小边界,我们可以在更准确但更不完整的 3D 网格之间取得平衡,反之亦然。
在第 4 节中,我们展示了随着不确定性界限值的降低而获得的不同网格(图 2)。在我们的实验中,我们没有尝试为我们的方法找到特定的帕累托最优解,而是使用不确定性 0.1 的固定最大上限,这导致非常准确的 3D 网格,完整性略有损失(参见第 4 节进行定量评估)。请注意,在不固定比例的情况下,此不确定性界限是无单位的,可能需要根据估计的比例进行调整
3.6.实现细节
我们使用 CUDA 在 Pytorch 中执行所有计算,并使用 RTX 2080 Ti GPU 进行所有实验(11Gb 内存)。对于体积融合,我们使用 Open3D 的 [30] 库,它允许自定义体积集成。我们使用相同的GPU 用于 SLAM 并执行体积重建。我们使用来自 Droid-SLAM [24] 的预训练权重。最后,我们使用 Open3D 中实现的行进立方体算法来提取 3D 网格。
4. 结果
第 4.2 节和第 4.3 节展示了我们提出的 3D 网格重建算法的定性和定量评估,相对于基线和最先进的方法,在 EuRoC 数据集上,使用具有以下场景的子集真实点云 定性分析展示了我们方法的优缺点,并在感知质量和几何保真度方面与其他技术进行了比较。
对于定量部分,我们计算了准确性和完整性指标的 RMSE,以客观地评估性能我们的算法对竞争方法的影响。我们现在描述数据集和用于评估的不同方法
4.1.数据集和评估方法
为了评估我们的重建算法,我们使用了 EuRoC 数据集,该数据集由在室内空间飞行的无人机记录的图像组成。我们使用 EuRoC V1 和 V2 数据集中可用的地面实况点云来评估我们的方法生成的 3D 网格的质量。对于我们所有的实验,我们将最大允许网格不确定性设置为 0.1 我们将我们的方法与两种不同的开源最先进的学习和基于模型的密集 VO 算法进行比较:Tandem [10],一种学习的密集单目 VO 算法,它使用 MVSNet 风格的架构和光度学捆绑包 -调整和 Kimera [17],一种基于模型的密集立体 VIO 算法。
两者都使用体积融合来重建 3D 场景并输出环境的 3D 网格。我们还展示了在 Droid 的 ad-hoc 深度过滤器之后融合 Droid 的点云的结果,该过滤器通过计算在阈值(默认为 0.005)内重新投影的附近深度图的数量来计算深度值的支持。然后丢弃任何小于 2 个支持深度或小于平均深度一半的深度值。
Droid 的过滤器用于去除深度图上的异常值,而我们融合所有由不确定性加权的深度图。作为我们的基线,我们使用 Droid 估计的原始点云,并将它们直接融合到体积重建中
4.2.定性建图性能
图2显示了我们如何通过改变3D重建中允许的最大不确定性水平来权衡精确度的完整性。我们还可以看到不太确定的几何形状是如何逐渐消失的。最不确定的几何形状对应于漂浮在3D空间中的伪影,因为深度三角化不好,当反向投影时散落在3D射线中(图2中的第一列)。
然后,我们看到消失的后续几何形状对应于无纹理区域(每列中最左边和最右边的红色圆圈)。有趣的是,在无纹理区域之后移除的几何形状对应于高度锯齿的区域(图2中每列中的中间红色圆圈),例如加热器或房间中棋盘格的中心。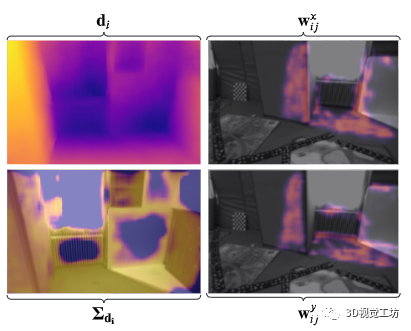
图 3.(左列)第 i 帧。 (右栏)第 j 帧。 (左上)第 i 帧的估计深度图。 (左下)帧 i 的估计深度图不确定性。 (右上)从第 i 帧到第 j 帧的光流 x 分量的光流测量权重。 (右下)y 分量的光流测量权重。请注意,流权重位于帧 i 在帧 j 中可见的位置。深度的不确定性来自多个光流测量的融合,而不是单个光流测量。
对于左列,低值显示为黄色,高值显示为蓝色。对于右列,低值显示为蓝色,高值显示为黄色。 EuRoC V1 01 数据集 仔细观察图 3 可以看出,估计的深度不确定性 Σd 不仅对于无纹理区域很大,而且对于具有强混叠的区域也很难解决基于光流的 SLAM 算法(中间的加热器)图片)。实际上,对于具有强混叠或无纹理区域的区域,光流权重(图 3 中的右栏)接近于 0。
这种新出现的行为是一个有趣的结果,可用于检测混叠几何,或指导孔填充重建方法。
图 4. Kimera [17]、Tandem [10]、我们的基线和 Droid 的深度过滤器 [24](使用默认阈值 0.005)重建的 3D 网格与我们使用最大容忍网格不确定性 0.1 的方法的比较。 EuRoC V2 01 数据集 图4定性地比较了Kimera[17]、Tan晚会[10]、基线方法、Droid[24]和我们的方法的3D重建。
我们可以看到,与我们的基线方法相比,我们在准确性和完整性方面都表现得更好。Kimera能够构建完整的3D重建,但与我们的方法相比,缺乏准确性和细节。Tandem是表现最好的竞争方案,并且比我们提议的方法产生了相似的重建结果。
从图4中,我们可以看到Tandem比我们的更完整(见我们重建中右下角缺失的地板条),同时稍微不太准确(见重建的左上角部分,在Tandem的网格中扭曲)。原则上,我们的方法也可以重建房间的底层(基线重建有这些信息)。
尽管如此,在机器人环境中,最好是意识到哪个区域是未知的,而不是做出不准确的第一次猜测,因为这可能会关闭机器人可能穿过的路径(DARPA SubT挑战赛[1]中的一个常见场景,机器人探索隧道和洞穴网络)。最后,Droid的深度过滤器缺少重要区域,并对重建精度产生负面影响。
表 1. 精度 RMSE [m]:对于我们的方法生成的 3D 网格,与 Kimera、Tandem、Droid 的过滤器和我们的基线相比,在具有地面实况点云的 EuRoC 数据集的子集上。请注意,如果一种方法仅估计几个准确的点(例如 Droid),则准确度可以达到 0。粗体为最佳方法,斜体为次优,- 表示未重建网格。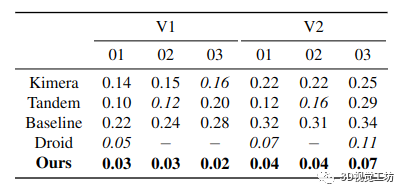
表 2. 完整性 RMSE [m]:对于我们的方法生成的 3D 网格,与 Kimera、Tandem 和我们的基线相比,在具有地面实况点云的 EuRoC 数据集的子集上。请注意,如果一种方法估计密集的点云(例如基线),则完整性可以达到 0。粗体为最佳方法,斜体为次优,- 表示未重建网格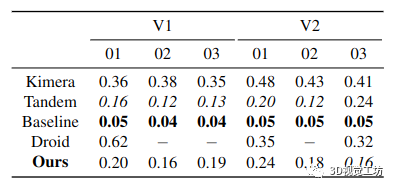
4.3.定量建图性能
我们使用精度和完整性度量根据地面实况评估每个网格,如[16,第4.3节]:(i)我们首先通过以104点/m2的均匀密度对重建的3D网格进行采样来计算点云,(ii)我们使用CloudCompare[6]将估计的和地面实况云注册到ICP[2],以及(iii)我们评估从地面实况点云到估计点云中最近邻居的平均距离(精度),反之亦然(完整性),具有0.5m最大差异 第 4.2 节和第 4.3 节提供了我们提出的方法、Droid 的过滤器和我们的基线之间的定量比较,以及与 Kimera [17] 和 Tandem [10] 在准确性和完整性方面的比较。
从表中可以看出,我们提出的方法在准确性方面表现最好,差距很大(与 Tandem 相比高达 90%,与 V1 03 的基线相比高达 92%),而 Tandem 达到了第二 -整体最佳准确度。在完整性方面,Tandem 实现了最佳性能(在基线方法之后),其次是我们的方法。 Droid 的过滤器以基本不完整的网格为代价实现了良好的精度。 图 6 显示了 Tandem(顶部)和我们的重建(底部)的估计云(V2 01)根据到地面真实云中最近点的距离(准确性)进行颜色编码。我们可以从这个图中看到我们的重建比 Tandem 的更准确。
特别是有趣的是,Tandem 倾向于生成膨胀的几何体,特别是在无纹理区域,例如 V2 01 数据集中的黑色窗帘(灰色几何体)。我们的方法具有更好的细节和更好的整体准确性。图。图 5 显示了 Tandem 和我们的方法重建的 3D 网格的特写视图。我们的重建往往不太完整并且存在出血边缘,但保留了大部分细节,而 Tandem 的重建缺乏整体细节和倾向于略微膨胀,但保持更完整。
4.4.实时性能
将 Euroc 图像下采样到 512×384 分辨率导致每秒 15 帧的跟踪速度。计算深度不确定性会使跟踪速度降低几帧/秒至 13 帧/秒。体积融合深度估计,有或没有深度不确定性,需要不到 20 毫秒。总的来说,我们的管道能够以每秒 13 帧的速度实时重建场景,通过并行摄像机跟踪和体积重建,并使用自定义 CUDA 内核
图 5. 仔细观察 Tandem 的 3D 重建与我们的之间的差异。
EuRoC V2 01 数据集
图 6. Tandem(上)和我们(下)的 3D 网格重建结果的精度评估。我们在 0.05m 处截断色标,并将其上方的任何内容可视化为灰色,最多 0.5m(超出此误差的几何图形将被丢弃)。请注意,我们的重建在 0.37m 处有最大误差,而 Tandem 的最大误差超出了 0.5m 的界限。
EuRoC V2 01 数据集。
5.结论
我们提出了一种使用密集的单目SLAM和快速深度不确定性计算和传播的3D重建场景的方法。我们表明,我们的深度图不确定性是准确和完整的3D体积重建的可靠信息来源,从而产生具有显著降低噪声和伪影的网格。
鉴于我们的方法提供的映射精度和概率不确定性估计,我们可以预见未来的研究将集中在地图中不确定区域的主动探索上,通过结合语义学来重建其几何形状之外的3D场景,如Kimera语义[18],或者通过使用神经体积隐式响应进行光度精确的3D重建,如Nice-SLAM。
审核编辑:刘清
-
RGB
+关注
关注
4文章
836浏览量
62232 -
SLAM
+关注
关注
24文章
459浏览量
33419 -
过滤器
+关注
关注
1文章
444浏览量
21044 -
计算机视觉
+关注
关注
9文章
1715浏览量
47722
原文标题:密集单目 SLAM 的概率体积融合
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
从基本原理到应用的SLAM技术深度解析
SLAM技术的应用及发展现状
单目视觉SLAM仿真系统的设计与实现
高仙SLAM具体的技术是什么?SLAM2.0有哪些优势?
视觉SLAM技术浅谈
视觉SLAM深度解读
基于概率运动统计特征匹配的单目视觉SLAM算法
辐射场的实时密集单眼SLAM简析
机器人移动过程中基于概率模型的SLAM方法

MG-SLAM:融合结构化线特征优化高斯SLAM算法

【AIBOX 应用案例】单目深度估计

一种基于点、线和消失点特征的单目SLAM系统设计

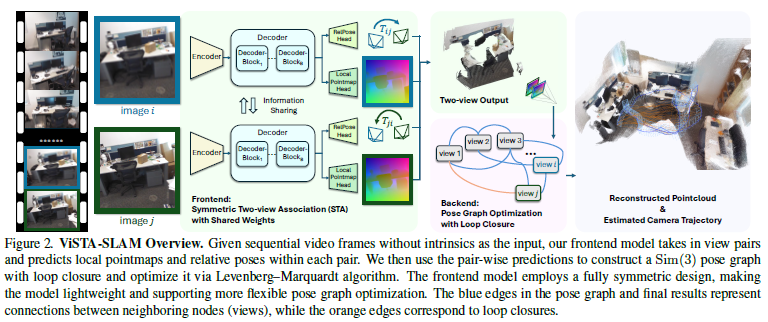
全新轻量级ViSTA-SLAM系统介绍



评论