 基于分类目标的预训练卷积神经网络
基于分类目标的预训练卷积神经网络

自人类文明诞生以来,高达90%的数据是在过去两年中产生的!
随着社交媒体和物联网(IoT)等数字技术以及5G等速度更快的无线通信技术的普及,数据创建速度不断提高。然而,创建的大多数新数据都是“非结构化的”,例如文本、图像、音频和视频[来源]。
非结构化数据之所以得名,是因为它不像由行和列组成的表那样具有固有的结构。相反,非结构化数据包含多种可能格式之一的信息。例如,电子商务图像、客户评论、社交媒体帖子、监控视频、语音命令等都是不遵循传统表格数据格式的丰富信息源。
人工智能(AI)和机器学习(ML)技术的最新进展创造了一种通过使用“嵌入”以可伸缩的方式从非结构化数据源中提取有用信息的方法,这种方法将非结构化数据转换为嵌入式数据并将其存储在向量数据库(如Milvus)上,实现了几年前难以想象的几个优秀应用程序。
一些示例应用程序包括视觉图像搜索、语义文本搜索、推荐引擎、打击误报、药物发现等!
在这篇文章中,我们将讨论以下内容。
什么是嵌入
使用Kaggle API加载一些数据
展平原始像素值
基于分类目标的预训练卷积神经网络
基于度量学习目标的预训练卷积神经网络
基于度量学习目标的预训练图文多模态神经网络
结论
在这篇文章中,我们将使用Kaggle提供的Digikala产品颜色分类数据集来构建一个简单的基于电子商务图像的类似产品搜索服务。该数据集是根据GPL 2许可证授权的。
什么是嵌入
我们的计算机无法像人类那样直接理解图像或文本。然而,计算机很擅长理解数字!
因此,为了帮助我们的计算机理解图像或文本的内容,我们需要将它们转换为数字表示。例如,如果我们考虑图像用例,我们本质上是将图像的上下文和场景“编码”或“嵌入”到向量形式的一系列数字中。
“嵌入”向量是图像数据的数字表示,以便计算机能够理解图像的上下文和场景。
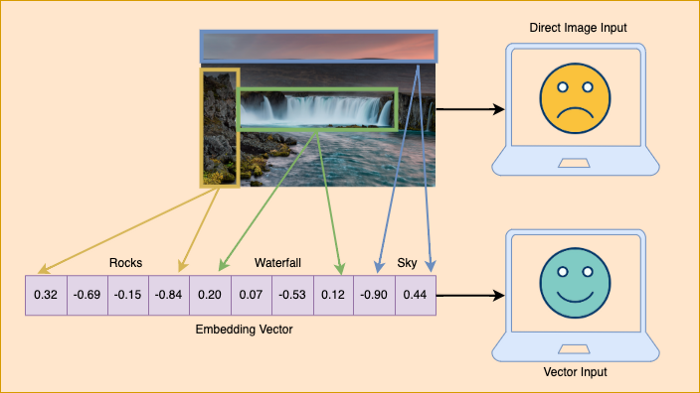
几个Python库允许我们从图像生成嵌入。通常,我们可以将这些库分为两大类。
提供带有预训练模型的现成API的库:对于许多涉及日常对象图像的真实问题,我们可能不需要训练任何模型。相反,我们可以依赖世界各地研究人员开放的许多高质量的预训练模型。研究人员已经训练这些模型来识别和聚类ImageNet数据集中的对象。
允许我们训练和微调模型的库:顾名思义,对于这些模型,我们可以从头开始提供数据和训练模型,或者专门针对我们的用例微调预训练的模型。如果预训练好的模型还没有为我们的问题域提供良好的嵌入,那么我们只需要沿着这条路走下去。
让我们看看这篇文章中的几个库。
但首先,让我们加载一些图像数据,以定性地评估相似性搜索应用程序中的嵌入。
加载一些数据
我们首先需要加载一些图像数据来测试各种嵌入策略。在这篇文章中,我们使用Kaggle提供的Digikala产品颜色分类数据集。该数据集包含超过6K个电子商务产品的图像,非常适合测试基于电子商务图像的类似产品搜索服务。
步骤1:设置Kaggle环境
在kaggle上创建帐户
单击你的个人资料图片,然后从下拉菜单中单击“帐户”。
向下滚动至“API”部分。
单击下图所示的“创建新API令牌”按钮,下载一个新的令牌,作为一个JSON文件,其中包含用户名和API密钥。
如果你使用的是macOS或Linux,请将JSON文件复制到~/.kaggle/目录。在Windows系统上,转到根目录,然后转到.kaggle文件夹,并将下载的文件复制到此文件夹。如果.kaggle目录不存在,请创建它并将JSON文件复制到其中。

步骤2:从Kaggle下载数据
我们将使用Anaconda来管理此项目的虚拟环境。你可以从这里安装Anaconda。下载并安装Anaconda后,我们可以建立一个名为semantic_similarity的新环境,安装必要的库,如kaggle和pandas,并从kaggle下载整个数据集。如果不想使用Anaconda,还可以使用python的venv为该项目创建和管理虚拟环境。
#Createadirectoryfornotebooksandanothertodownloaddata mkdir-psemantic_similarity/notebookssemantic_similarity/data/cv #CDintothedatadirectory cdsemantic_similarity/data/cv #Createandactivateacondaenvironment condacreate-nsemantic_similaritypython=3.8 condaactivatesemantic_similarity ##CreateVirtualEnvironmentusingvenvifnotusingconda #python-mvenvsemantic_similarity #sourcesemantic_similarity/bin/activate #Pipinstallthenecessarylibraries pipinstalljupyterlabkagglepandasmatplotlibscikit-learntqdmipywidgets #DownloaddatausingthekaggleAPI kaggledatasetsdownload-dmasouduut94/digikala-color-classification #Unzipthedataintoafashion/directory unzipdigikala-color-classification.zip-d./fashion #DeletetheZipfile rmdigikala-color-classification.zip
该数据包含超过6K张各种电子商务产品的图像。我们可以在下图中看到数据集中的一些示例图像。正如你所注意到的,该数据集包括各种时尚产品,如男装、女装、包、珠宝、手表等。

步骤3:将所有图像从每个文件夹移动到父文件夹
让我们在semantic_similarity/notebooks目录中创建一个新的jupyter笔记本,以测试各种嵌入策略。首先,让我们导入必要的库。
frommatplotlibimportpyplotasplt importnumpyasnp importos importpandasaspd fromPILimportImage fromrandomimportrandint importshutil fromsklearn.metrics.pairwiseimportcosine_similarity importsys fromtqdmimporttqdm tqdm.pandas()
下载的图像位于多个子文件夹中。让我们将它们全部移动到主父目录中,以便轻松获取它们的所有路径。
defmove_to_root_folder(root_path,cur_path): #Codefromhttps://stackoverflow.com/questions/8428954/move-child-folder-contents-to-parent-folder-in-python forfilenameinos.listdir(cur_path): ifos.path.isfile(os.path.join(cur_path,filename)): shutil.move(os.path.join(cur_path,filename),os.path.join(root_path,filename)) elifos.path.isdir(os.path.join(cur_path,filename)): move_to_root_folder(root_path,os.path.join(cur_path,filename)) else: sys.exit("Shouldneverreachhere.") #removeemptyfolders ifcur_path!=root_path: os.rmdir(cur_path) move_to_root_folder(root_path='../data/cv/fashion',cur_path='../data/cv/fashion')
步骤4:将图像路径加载到pandas数据帧中
接下来,让我们将所有图像文件路径的列表加载到pandas数据帧中。
#Pathtoallthedownloadedimages img_path='../data/cv/fashion' #Findlistofallfilesinthepath images=[ f'../data/cv/fashion/{f}' forfinos.listdir(img_path) ifos.path.isfile(os.path.join(img_path,f)) ] #Loadthefilenamestoadataframe image_df=pd.DataFrame(images,columns=['img_path']) print(image_df.shape) image_df.head()
生成嵌入的策略
计算机视觉技术的最新进展开辟了许多将图像转换为数字嵌入的方法。让我们看看其中的一些。
展平原始像素值
基于分类目标的卷积神经网络预训练
基于度量学习目标的卷积神经网络预训练
基于度量学习目标的图文多模态神经网络预训练
展平原始像素值
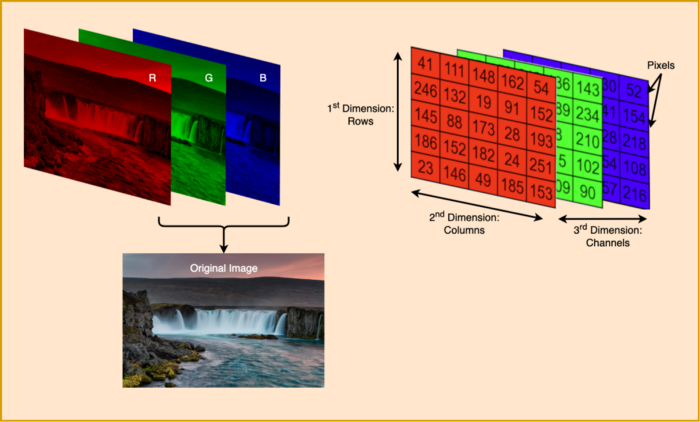
彩色图像由三维像素阵列组成。第一个维度是图像的高度,第二个维度是图像的宽度,最后的第三个维度是颜色通道,统称为RGB,包含红色、绿色和蓝色,如下图所示。每个像素的值是0到255之间的整数,255是可能的最高强度。
因此,(0,0,0)的RGB值是完全黑暗或纯黑色像素,并且(255,255,255)是完全饱和的纯白色像素。我们图像中可见的所有其他颜色都是由这三个基本RGB值的各种组合组成的。
RapidTables网站上的RGB颜色代码图表允许你选择任何颜色来查看其RGB值,可以点击以下链接进行尝试:
https://www.rapidtables.com/web/color/RGB_Color.html
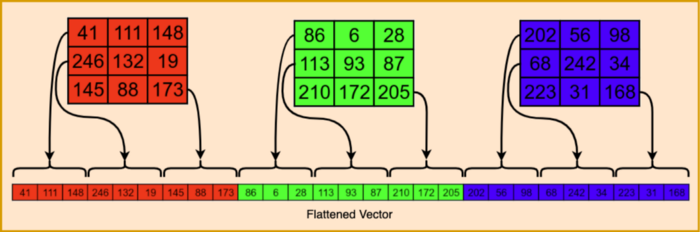
如果图像是三维数组格式的一系列数字,则使用重塑操作将其转换为一维向量非常简单,如下图所示。我们还可以通过将每个像素的值除以255来规范化。我们将在代码中执行此操作。
defflatten_pixels(img_path): #Loadtheimageontopython img=Image.open(img_path).convert('RGB') #Reshapetheimageto1Dandnormalizethevalues flattened_pixels=np.array(img).reshape(-1)/255. returnflattened_pixels #Applythetransformationtothedataframe #Warning!Runningonlyonasubset1Krowsofthedata, #Yourcomputermightcrashifyourunontheentiredataset! #Betterdon’trunit.Wehavemuchbetterwaystogenerateembeddings! pixels_df=image_df.sample(1_000).reset_index(drop=True).copy() pixels_df['flattened_pixels']=pixels_df['img_path'].progress_apply(flatten_pixels)
此方法的问题
虽然这种方法易于理解和实现,但这种将图像“嵌入”到向量中的方法存在一些严重的缺点。
巨大的向量:我们从Kaggle下载的图像非常小[224 x 224 x 3],对应于[Height x Width x Channels],将此3D阵列转换为1D向量将得到大小为150528的向量!对于如此小的图像,这是一个巨大的向量!在整个数据集上生成此向量时,我的计算机崩溃了好几次。最后我只在一个较小的子集(1K行)上运行它来说明这个方法。
具有大量白色的稀疏向量:在视觉上检查时装数据集中的图像时,我们会注意到图片中有很大的白色区域。因此,这个150528元素向量的许多元素是值255(对于白色),并且没有添加任何与图像中的对象相关的信息。换句话说,这种“嵌入”方案不能有效地对图像对象进行编码,而是包含大量无用的空白。
缺乏局部结构:最后,直接展平图像会丢失图片的所有局部结构。例如,我们通过眼睛、耳朵、鼻子和嘴巴的相对位置来识别人脸图像。这些是各种各样的“特征”级别的信息,如果我们一次只看一行像素,就会完全忽略这些信息。这种损失的影响是,一张倒置的脸与一张右侧朝上的脸有着非常不同的嵌入,即使这两张脸都是同一张人脸的照片!
随着基于卷积神经网络CNN和Transformer结构的新型神经网络结构的出现,我们基本上克服了这些问题。这篇文章的其余部分将深入探讨如何使用这些神经网络将我们的图像转换为嵌入。
基于分类目标的卷积神经网络预训练
也许最著名的计算机视觉任务之一就是将图像分为不同的类别。通常,对于这项任务,我们将使用CNN模型(如ResNet)作为编码器,将图像转换为向量,然后将该向量通过多层感知器(MLP)模型来确定图像的类别,如下图所示。
研究人员将使用交叉熵损失对CNN+MLP模型进行训练,以准确分类图像类别。
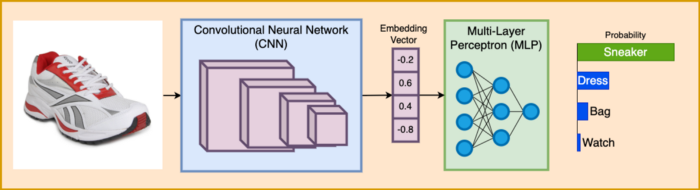
这种方法提供了最先进的精确度,甚至超过了大多数人的能力。在训练这样一个模型后,我们可以去掉MLP层,直接将CNN编码器的输出作为每个输入图像的嵌入向量。
事实上,我们不需要为许多现实世界的问题从头开始训练我们自己的CNN模型。相反,我们直接下载并使用已经训练过的模型来识别日常对象,例如ImageNet数据集中的类别。
Towhee是一个python库,它可以使用这些预训练好的模型快速生成嵌入。让我们看看如何做到这一点。
Towhee管道
Towhee是一个python库,提供了非常易于使用的嵌入生成管道。我们可以使用towhee将图像转换为嵌入,代码不到五行!首先,让我们在终端窗口中使用pip安装towhee。
#Activatethecondaenvironmentifnotalreadydoneso #condaactivatesemantic_similarity pipinstalltowheetorchtorchvision
接下来,在Jupyter笔记本单元中,让我们导入库并实例化一个管道对象。
fromtowheeimportpipeline embedding_pipeline=pipeline('image-embedding')
接下来,让我们在一行代码中使用管道将图像转换为嵌入!嵌入管道的输出有一些额外的维度,我们可以使用np.squeeze去除这些维度。
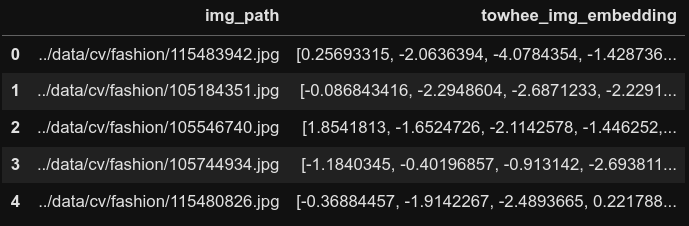
image_df['towhee_img_embedding']=image_df['img_path'].progress_apply(lambdax:np.squeeze(embedding_pipeline(x))) image_df.head()
在继续之前,让我们创建一个helper函数,该函数接受嵌入列的名称、用作查询图像的数据帧索引以及要搜索的类似图像的k个数。
该函数计算查询图像的嵌入与数据帧中所有其他图像的嵌入之间的余弦相似度,以找到前k个最相似的图像并显示它们。
defplot_similar(df,embedding_col,query_index,k_neighbors=5): '''Helperfunctiontotakeadataframeindexasinputqueryanddisplaytheknearestneighbors ''' #Calculatepairwisecosinesimilaritiesbetweenqueryandallrows similarities=cosine_similarity([df[embedding_col][query_index]],df[embedding_col].values.tolist())[0] #Findnearestneighborindices k=k_neighbors+1 nearest_indices=np.argpartition(similarities,-k)[-k:] nearest_indices=nearest_indices[nearest_indices!=query_index] #Plotinputimage img=Image.open(df['img_path'][query_index]).convert('RGB') plt.imshow(img) plt.title(f'QueryProduct. Index:{query_index}') #Plotnearestneighborsimages fig=plt.figure(figsize=(20,4)) plt.suptitle('SimilarProducts') foridx,neighborinenumerate(nearest_indices): plt.subplot(1,len(nearest_indices),idx+1) img=Image.open(df['img_path'][neighbor]).convert('RGB') plt.imshow(img) plt.title(f'CosineSim:{similarities[neighbor]:.3f}') plt.tight_layout()
我们现在可以通过查询数据帧中的随机图像并使用上述辅助函数显示k个最相似的图像来测试towhee嵌入的质量。
如下图所示,towhee嵌入非常准确,我们每次查询都会从包含多个不同产品(如连衣裙、手表、包和配件)的整套图像中找到类似的图片!
考虑到我们仅用三行代码就生成了这些嵌入,这更令人印象深刻!
plot_similar(df=image_df, embedding_col='towhee_img_embedding', query_index=randint(0,len(image_df)),#Queryarandomimage k_neighbors=5)
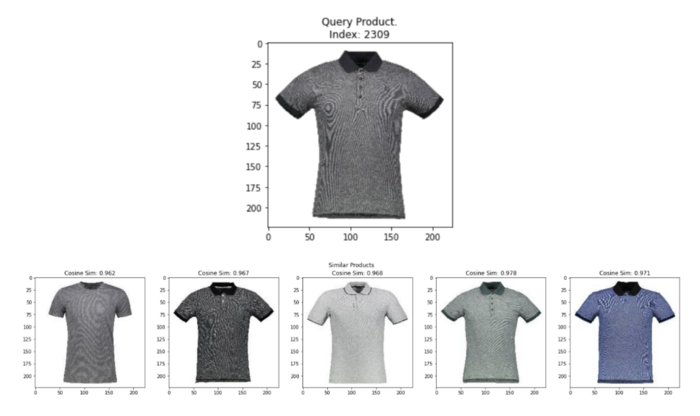
从结果中,我们可以得出结论,towhee是快速生成相似性搜索应用程序嵌入的良好起点。
然而,我们没有明确地训练这些模型,以确保相似的图像具有彼此相同的嵌入。因此,在相似性搜索的上下文中,来自此类模型的嵌入对于所有用例可能都不是最准确的。
你现在可能会问的一个自然问题是,“是否有一种方法可以训练模型,使相似的图像具有彼此相似的嵌入?”谢天谢地,有!
基于度量学习目标的卷积神经网络预训练
进入度量学习,这是生成嵌入的最有希望的方法之一,特别是对于相似性搜索应用程序。在度量学习的最基本层面上,
我们使用神经网络(如CNN或Transformer网络)将图像转换为嵌入。
我们构造这些嵌入,以便语义相似的图像彼此靠近,而不同的图像则相距更远。
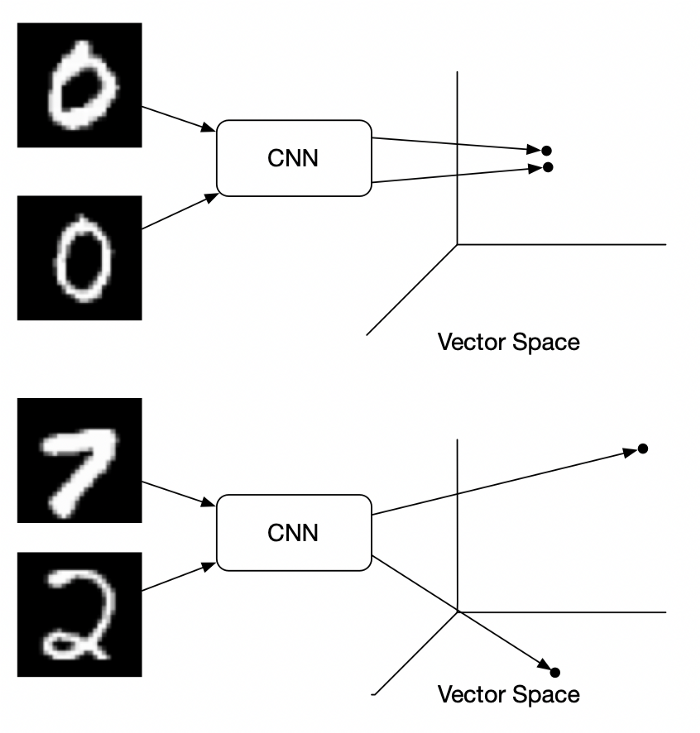
训练度量学习模型需要在数据处理方式和模型训练方式方面进行创新。
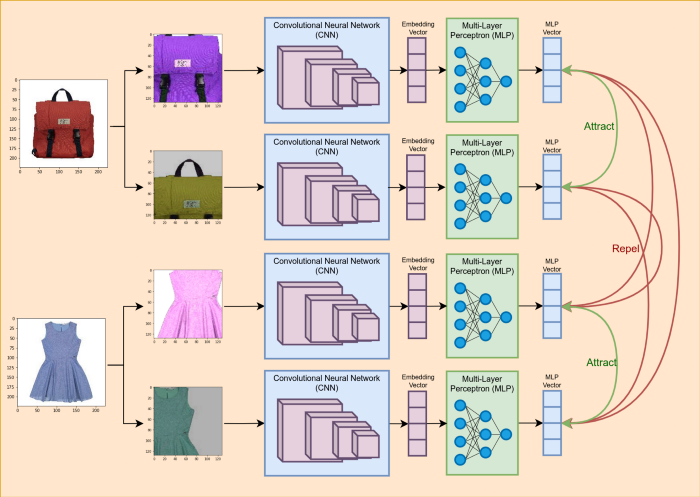
数据:在度量学习中,对于每个称为“锚点”图像的源图像,我们需要至少一个称为“正样本”的类似图像我们还需要第三个图像,称为“负样本”,以改进嵌入表示。在最近针对每个源图像的度量学习方法中,我们使用各种数据增强综合生成“锚点”和“正样本”图像,如下图所示。
模型:度量学习模型大多具有暹罗网络体系结构。锚点图像、正图像和负图像依次通过相同的模型生成嵌入,然后使用特殊的损失函数进行比较。其中一个损失函数称为对比损失,该模型的目标是将锚点图像和正面图像的嵌入移动得更近,使它们之间的距离接近0。相反,该模型旨在将锚点和负样本移动得更远,以便它们之间的距离更大。

在用这种方法训练模型后,我们可以通过数学计算嵌入向量之间的距离来发现任意两幅图像之间的相似性,这些距离可以使用余弦距离等度量。正如这篇中型博客文章所示,存在几种距离度量,余弦距离常用于比较嵌入。
SimCLR:简单对比学习
SimCLR代表视觉表征对比学习的简单框架。它是使用一种称为对比学习的度量学习方法生成图像嵌入的常用方法之一。在对比学习中,对比损失函数比较两个嵌入是相似的(0)还是不同的(1)。
SimCLR的优点在于它是一种简单的自监督算法(图像类不需要任何标签!)这实现了与一些受监督方法相当的性能,如下图所示!
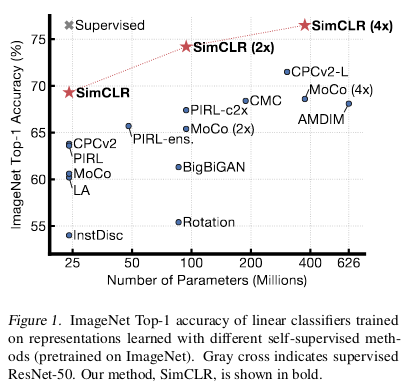

SimCLR的基本思想如下。
给定一个图像,创建同一图像的两个增强版本。这些增强可以是裁剪和调整大小、颜色失真、旋转、添加噪声等。上图显示了一些增强的示例。
批处理中所有图像的增强版本通过CNN编码器,该编码器将图像转换为嵌入。然后,这些CNN嵌入通过一个简单的多层感知器(MLP)将其转换为另一个空间,该感知器只有一个隐藏层。
最后,使用余弦距离比较MLP输出处的嵌入。该模型期望来自同一图像的增强的余弦距离为0,而来自不同图像的增强的余弦距离为1。然后,损失函数更新CNN和MLP的参数,以便嵌入更接近我们的期望。
一旦训练完成,我们就不再需要MLP,直接使用CNN编码器的输出作为嵌入。
下图从概念上解释了整个过程。有关更多详细信息,请查看这篇谷歌博客文章。
https://ai.googleblog.com/2020/04/advancing-self-supervised-and-semi.html
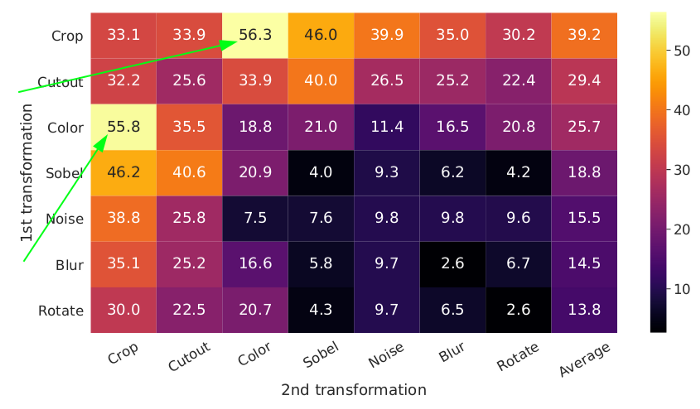
作者进行了几次实验,确定随机裁剪和颜色失真是增强的最佳组合,如下所示。
与towhee一样,我们使用其他研究人员在ImageNet上预先训练的模型直接提取SimCLR嵌入。然而,在撰写本文时,为了获得SimCLR预训练过的嵌入,我们需要使用Pytorch Lightning Bolts库编写几行代码。我从官方lightning文档中改编了以下内容。首先,在终端窗口中使用pip安装必要的库。
#Activatethecondaenvironmentifnotalreadydoneso #condaactivatesemantic_similarity pipinstalllightning-bolts
接下来,在Jupyter笔记本单元中,我们导入必要的库,并根据你的计算机是否有GPU将设备设置为cuda或cpu。
frompl_bolts.models.self_supervisedimportSimCLR importtorch fromtorch.utils.dataimportDataset,DataLoader fromtorchvisionimportio,transforms #UseGPUifitisavailable device=torch.device('cuda'iftorch.cuda.is_available()else'cpu')
接下来,让我们加载在ImageNet上预先训练的SimCLR模型,并将其设置为评估模式,因为我们只想从模型中获得嵌入,而不想再训练它。
#loadresnet50pre-trainedusingSimCLRonimagenet weight_path='https://pl-bolts-weights.s3.us-east-2.amazonaws.com/simclr/bolts_simclr_imagenet/simclr_imagenet.ckpt' simclr=SimCLR.load_from_checkpoint(weight_path,strict=False,batch_size=32) #SendtheSimCLRencodertothedeviceandsetittoeval simclr_resnet50=simclr.encoder.to(device) simclr_resnet50.eval();
以下两个步骤针对Pytorch;用于实现模型的基础库。我们首先创建一个数据集,该数据集可以接受我们的数据帧作为输入,从img_path列读取图像,应用一些转换,最后创建一批图像,我们可以将其输入到模型中。
#CreateadatasetforPytorch classFashionImageDataset(Dataset): def__init__(self,df,transform=None): self.df=df self.transform=transform def__len__(self): returnlen(self.df) def__getitem__(self,idx): #LoadtheImage img_path=self.df.loc[idx,'img_path'] image=io.read_image(img_path,mode=io.image.ImageReadMode.RGB)/255. #ApplyTransformations ifself.transform: image=self.transform(image) returnimage #Transforms ##NormalizetransformtoensuretheimageshavesimilarintensitydistributionsasImageNet ##Resizetransformtoensureallimagesinabatchhavethesamesize transformations=transforms.Compose([ transforms.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225)), transforms.Resize(size=(64,64)) ]) #CreatetheDataLoadertoloadimagesinbatches emb_dataset=FashionImageDataset(df=image_df,transform=transformations) emb_dataloader=DataLoader(emb_dataset,batch_size=32)
最后,我们可以在dataloader中迭代批处理,为所有图像生成嵌入,并将它们作为列存储回dataframe中。
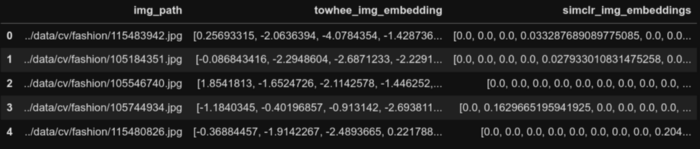
#Createembeddings embeddings=[] forbatchintqdm(emb_dataloader): batch=batch.to(device) embeddings+=simclr_resnet50(batch)[0].tolist() #Assignembeddingstoacolumninthedataframe image_df['simclr_img_embeddings']=embeddings image_df.head()
现在是有趣的部分!我们可以使用相同的helper函数测试SimCLR嵌入的质量。
我们从数据帧中查询随机图像,并显示k个最相似的图像。如下所示,SimCLR嵌入也非常适合为我们运行的每个查询找到类似的图像!
plot_similar(df=image_df, embedding_col='simclr_img_embeddings', query_index=randint(0,len(image_df)), k_neighbors=5)

用度量学习目标预训练的图像-文本多模态神经网络
最后,将图像和文本嵌入到统一嵌入空间的模型有了巨大的改进,这开辟了几个优秀的应用程序,如 Image-To-Text 和 Text-To - 图像相似度搜索。这种范式中最流行的模型之一是CLIP(对比语言图像预训练)。
CLIP是一种基于度量学习框架的神经网络。CLIP使用图像作为锚点,相应的文本描述作为正样本来构建图像-文本对。我们可以在多个应用程序中使用CLIP,包括文本到图像、图像到文本、图像到图像和文本到文本的相似性搜索。
图像通过ResNet或ViT编码器生成图像嵌入。文本描述通过基于Transformer的编码器提供,以生成文本嵌入。CLIP联合训练图像和文本编码器,以便在一批N个图像-文本对中,第i个图像的嵌入与第i个文本的嵌入具有最高的点积,如下图所示。
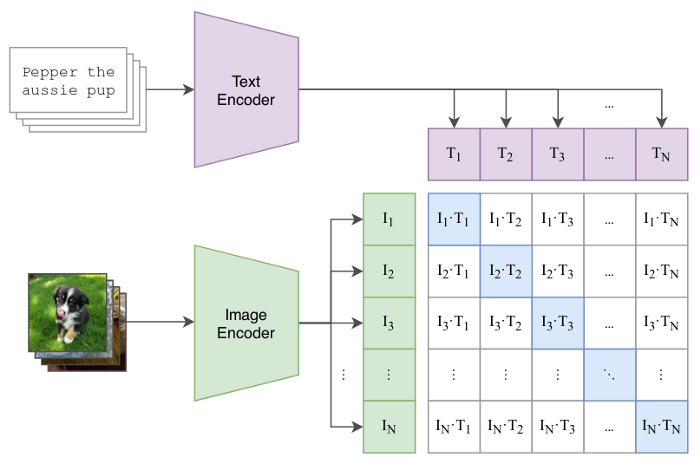
训练完成后,我们可以通过将两者转换为各自的嵌入并使用点积或余弦距离进行比较,找到与查询图像最相似的文本行,如下图所示。
相反,我们也可以以相同的方式搜索给定查询文本的最相似图像。让我们看看如何在示例问题上实现这一点。
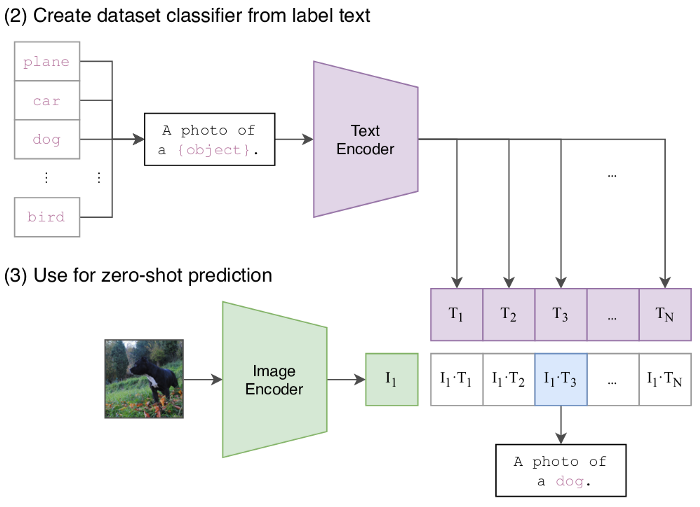
Sentence Transformers
使用优秀的句子Transformer库,在我们的数据上生成CLIP嵌入非常简单。然而,由于操作系统对一次可以打开的文件数量的限制,在处理成千上万的图像时,我们需要编写几行样板代码。首先,在终端窗口中使用pip安装必要的库。
#Activatethecondaenvironmentifnotalreadydoneso #condaactivatesemantic_similarity pipinstallsentence_transformersftfy
接下来,在Jupyter笔记本单元中,让我们导入库并实例化片段模型。
fromsentence_transformersimportSentenceTransformer model=SentenceTransformer('clip-ViT-B-32')
接下来,我们需要迭代10K个图像,以绕过操作系统对一次可以打开的文件数量的限制。我们在每次迭代期间加载所有图像并生成CLIP嵌入。
#Initializeanemptylisttocollectembeddings clip_embeddings=[] #Generateembeddingsfor10_000imagesoneachiteration step=10_000 foridxinrange(0,len(image_df),step): #Loadthe`step`numberofimages images=[ Image.open(img_path).convert('RGB') forimg_pathinimage_df['img_path'].iloc[idx:idx+step] ] #GenerateCLIPembeddingsfortheloadedimages clip_embeddings.extend(model.encode(images,show_progress_bar=True).tolist()) #Assigntheembeddingsbacktothedataframe image_df['clip_img_embedding']=clip_embeddings image_df.head()
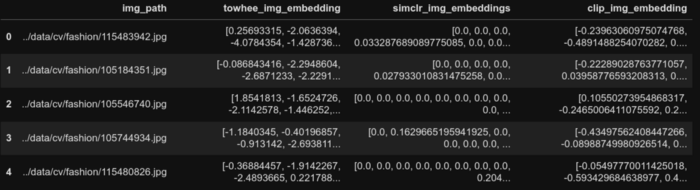
现在我们有了所有图像的CLIP嵌入,我们可以使用相同的辅助函数来测试嵌入的质量。
我们从数据帧中查询随机图像,并显示k个最相似的图像。如下图所示,CLIP嵌入也非常准确,可以为我们运行的每个查询找到相似的图像!
plot_similar(df=image_df, embedding_col='clip_img_embedding', query_index=randint(0,len(image_df)), k_neighbors=5)
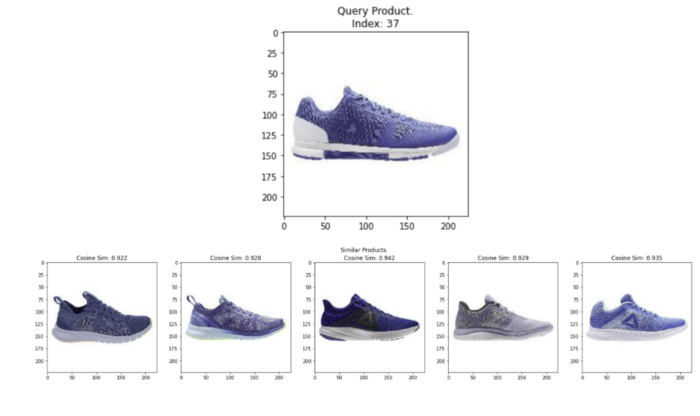
虽然我们必须编写一些额外的代码来生成CLIP嵌入,但它提供的一个显著优势是文本到图像搜索。换句话说,我们可以搜索与给定文本描述匹配的所有图像。让我们看看下面的内容。
由于我们已经将图像转换为CLIP嵌入,现在只需要将文本查询转换为CLIP嵌入。然后,我们可以利用文本嵌入和数据帧中所有图像嵌入之间的余弦相似度来搜索相似的产品。我们将编写一个简单的助手函数来为我们完成这一切,如下所示。最后,我们将绘制所有类似的k个产品图像。
deftext_image_search(text_query,df,img_emb_col,k=5): '''Helperfunctiontotakeatextqueryasinputanddisplaytheknearestneighborimages ''' #Calculatethetextembeddings text_emb=model.encode(text_query).tolist() #Calculatethepairwisecosinesimilaritiesbetweentextqueryandimagesfromallrows similarities=cosine_similarity([text_emb],df[img_emb_col].values.tolist())[0] #Findnearestneighbors nearest_indices=np.argpartition(similarities,-k)[-k:] #PrintQueryText print(f'QueryText:{text_query}') #Plotnearestneighborsimages fig=plt.figure(figsize=(20,4)) plt.suptitle('SimilarProducts') foridx,neighborinenumerate(nearest_indices): plt.subplot(1,len(nearest_indices),idx+1) img=Image.open(df['img_path'][neighbor]).convert('RGB') plt.imshow(img) plt.title(f'CosineSim:{similarities[neighbor]:.3f}') plt.tight_layout()
现在,我们可以使用helper函数测试示例文本查询。如下图所示,如果我们的测试查询是“一件女装的照片”,那么最相似的产品都是女装!尽管每个产品的标题没有明确指定“连衣裙”一词,但CLIP模型能够仅从文本和图像嵌入推断出这些图像与查询“一张女装照片”最相关。
继续尝试其他查询!
text_query="aphotoofawomen'sdress" text_image_search(text_query, df=image_df, img_emb_col='clip_img_embedding', k=5)

结论
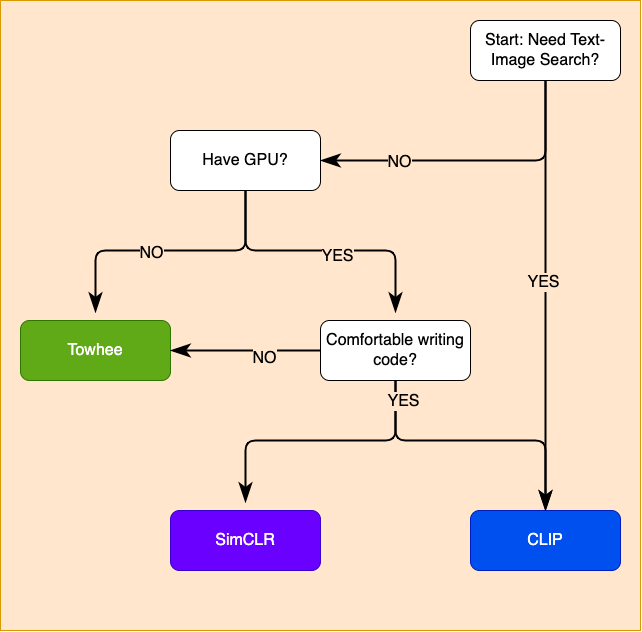
深度学习研究和开源代码库的最新技术为从图像和文本数据生成高质量嵌入提供了许多简单的方法。这些现成的嵌入是为许多实际问题构建原型的绝佳起点!下面的流程图有助于选择要使用的初始嵌入。但是,在将任何单个查询部署到生产环境之前,请不断评估一些复杂示例查询上嵌入模型的准确性!
说到生产,我们在这里使用的数据集是一个只有6K个图像的玩具数据集。在现实世界的应用程序中,例如电子商务商店,你将有数亿个产品图像需要在几秒钟内嵌入、存储和执行近邻搜索!问题的规模需要使用强大的向量搜索数据库,如Milvus!
-
嵌入式
+关注
关注
5209文章
20645浏览量
336910 -
神经网络
+关注
关注
42文章
4842浏览量
108152 -
计算机
+关注
关注
19文章
7839浏览量
93455 -
API
+关注
关注
2文章
2474浏览量
67004
原文标题:计算机视觉中的语义相似性搜索
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
在Ubuntu20.04系统中训练神经网络模型的一些经验
卷积神经网络如何使用
卷积神经网络简介:什么是机器学习?
python卷积神经网络cnn的训练算法
卷积神经网络模型训练步骤
卷积神经网络如何识别图像
什么是卷积神经网络?为什么需要卷积神经网络?
利用卷积神经网络实现SAR目标分类的研究




评论