 管理40/100G多核处理器的网络流量
管理40/100G多核处理器的网络流量

近年来,在消费者宽带、企业流量和基于 IP 的新型服务(如移动连接、远程云服务、IP 视频和 IPTV)的推动下,企业和运营商网络的流量呈爆炸式增长。
此外,虚拟化的出现和对更高性能(高达 100G)安全通信的需求给包括 I/O 子系统在内的通信系统设计带来了巨大压力。这些需求,再加上多核 x86 CPU 在嵌入式应用程序和数据中心中取得的成功,催生了对协处理器的需求,该协处理器可以处理数千万有状态流的数据包处理,并具有无缝、高性能、虚拟化接口x86 CPU 子系统。
数据包处理压力
如今,提供基于云的服务和企业数据中心的服务提供商能够随时随地通过有线和无线网络访问宝贵的资源。由此产生的流量增加使汇聚交换机/路由器和中间网络节点处于不断的压力之下,以满足越来越高的带宽需求。这些处理元素不只是简单地切换或路由流量;他们还必须执行一些功能,例如构建具有深度数据包检测 (DPI) 功能的防火墙,并为多租户云环境提供虚拟化支持。
底层传输控制协议 (TCP)、用户数据报协议 (UDP) 和实时传输协议 (RTP) 流量包括属于网络连接的许多数据包。网络边缘的交换机、路由器或网关等中间节点必须同时处理数百万个网络连接。
尝试单独处理连接中的每个数据包会阻止网络元素跟上不断增加的线路速率。由于需要对至少一部分流量执行 DPI,这进一步复杂化了。此外,位于网络深处的中间节点必须处理数亿个数据包。
每个数据包与任何其他数据包没有关联;也就是说,它们在空间或时间上不相关。通过将数据包分组为流,可以更好地服务于这种异步流量。流是属于同一网络会话的数据包的集合,通常在源-目标对之间。传入的数据包必须分类为流。然后处理器根据流状态表中的规则以相同的方式处理属于同一流的所有数据包。
有状态的流处理
所有网络元素都需要数百万个流的状态,尤其是在实施防火墙、入侵预防或检测系统以及应用程序级负载平衡器等安全处理时。由此产生的平台架构必须通过监视流中的数据包、更新 TCP 连接、创建和超时 UDP 连接以及跟踪虚拟专用网络 (VPN) 连接来支持流状态管理。还需要状态处理来支持 TCP 代理和 TCP 拼接。
因此,系统软件应维护支持数百万流的流状态表。硬件必须通过在流哈希表中执行复杂的哈希和查找来支持软件。软件负责分析流哈希结果并管理新流,更新哈希表并维护流状态。
100G 时的系统性能要求
为了满足 100G 的严格系统要求,处理和内存架构都必须满足在 64 字节数据包的最坏情况下一个数据包时间提供的时间预算,即低至 5 ns。
处理指令和内存预算
鉴于大多数网络继续使用以太网帧或数据包作为底层传输,了解这些帧的组成以及它们如何影响网络性能非常重要。
以太网帧
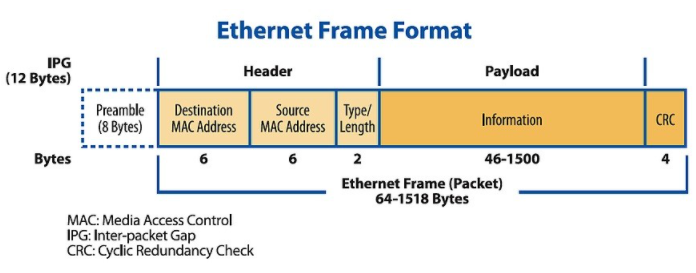
典型的以太网帧以 8 字节的前导码开始,随后是 12 字节的目标地址和源地址的寻址信息,2 字节的类型/长度字段指示使用的日期类型以及有效负载的长度。有效载荷数据可以低至 46 字节,高至 1,500 字节。计算 32 位(4 字节)循环冗余校验并将其附加在帧的末尾(图 1)。
图 1:在以太网帧格式中,64 字节的最小数据包大小在加上所示开销后实际上是 84 字节。
100 GbE 的性能计算
系统吞吐量计算通常以每秒数据包 (pps) 的形式表示。当所有以太网帧的长度为 64 字节或最小大小的帧时,计算最大数量。对于 10 GbE,这个数字是 148.81 亿 pps,或通常称为 15 Mpps。对于 100 GbE,这个数字大约为 150 Mpps。
较小的数据包在满足短时间预算方面存在挑战,而大数据包在满足最高线路速率方面存在挑战。处理 64 字节数据包所需的每个数据包时间预算仅为 6 ns。对于运行在 1 GHz 的处理器,指令周期时间为 1 ns。因此,一个 64 字节的数据包转换为 150 Mpps 的 6 周期预算。解决此限制的一种方法是使用具有多个内核和线程的并行处理。例如,一个 100 个内核/线程的处理器将把这个时间预算增加到 600 个周期——一个更易于管理的窗口。
100G 时的内存注意事项
不建议在网络设备中使用专用存储器。目前,DDR3 存储器是首选的外部存储器。DDR 存储器在较长的突发中运行良好;但是,高于 1,666 MHz 的时钟的事务速率达到了 64 位宽接口的最大速率。将一个 64 位通道换成两个 32 位内存通道可以在 2,133 MHz 或更高的时钟频率下提供更高的事务处理速率。
当前满足 100G 要求的方法
多核处理器
在 2000 年代初期,许多新老芯片供应商开始提供基于标准通用处理器的多核 CPU 产品,创建对称多处理 (SMP) Linux 结构。通过利用 SMP 操作系统 (OS) 相对简单的编程模型,网络供应商能够在更短的时间内将产品推向市场。但是,这种方法仅限于低于 10G 的性能水平。
这些处理器的性能受到限制,主要是因为传统的通用 CPU 依赖缓存来解决内存延迟问题。高速缓存未命中迫使 CPU 内核饿死内存访问,与高速缓存相比,主内存延迟太慢了。这种所谓的“内存墙效应”意味着处理器的 SMP 多核模型无法扩展到灵活处理 100 Gbps 解决方案所需的数百个处理器内核。通过分支预测和推测执行技术来最小化缓存未命中的尝试未能解决相对较低的缓存命中率问题。
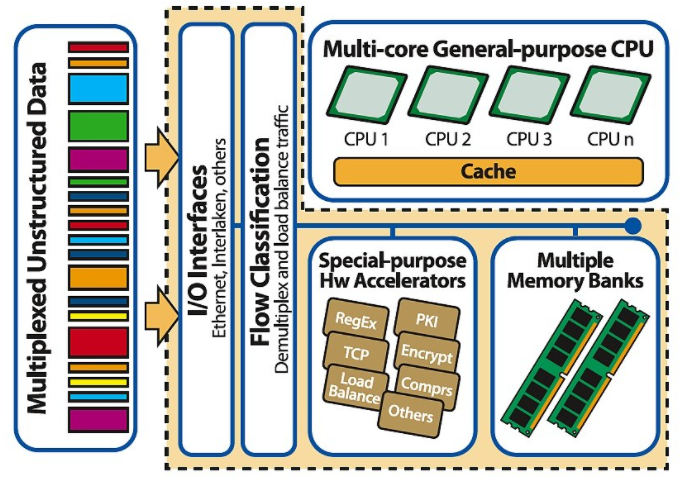
为了绕过性能瓶颈,供应商开始将硬件加速器嵌入到多核处理器中,以处理常见的性能密集型功能,例如安全性和 DPI(参见图 2)。由此产生的单芯片异构多核处理器已经让位于对操作系统不友好的专有架构,并打破了拥有简单、易于编程的多核处理器的初衷。
图 2:多核通用处理器需要借助硬件加速功能来处理 100G 的数百万流。
网络处理器
网络处理器是一类专注于优化 L2-L4 数据包性能的处理器。通常,它们包含较小的内核,可以很好地扩展并且可以提供 100 Gbps 的性能。内存性能通过流水线架构来解决,在某些情况下,超长指令字 (VLIW) 架构。
由于复杂的编程和专注于数据包转发的固定内部结构,网络处理器的灵活性和智能处理受到阻碍。此外,当流量包含多个隧道和/或需要更深的隧道时,流水线网络处理器的性能会受到影响。
以太网交换机
这类芯片通常包括带有内部查找引擎的小型流水线,并且不支持外部存储器。在企业以太网配线间交换机中很常见。随着架顶式交换机的使用模型变得越来越复杂,灵活性要求也变得更加明显。以太网交换机现在需要更大的查找表和更高的性能水平,以及支持数据中心多层虚拟化所需的几个深层隧道。
尽管一些以太网交换芯片可以访问外部三元内容寻址存储器以进行快速表查找,但典型的以太网交换机无法访问外部 DDR 存储器,因此难以满足需要支持数百万流的网络应用。
以太网控制器
此类产品用于服务器和客户端环境,通过 PCI Express 接口将多个以太网接口连接到主机 x86 CPU。这些设备无法通过编程来执行复杂的网络任务,例如交换或在线安全。它们无法访问外部存储器,因此无法支持数百万个流。
既然已经确定了处理 100G 网络流量的挑战,那么讨论应对这些挑战所需的内容就很重要。本系列的第 2 部分将在 2 月份的《嵌入式计算设计》杂志上发表,将重点介绍能够应对 100G 网络流量带来的挑战的协处理器的需求。此外,第二篇文章将讨论新的协处理器如何管理诸如智能 L2/L3 交换、流分类、在线安全处理、虚拟化以及 x86 CPU 内核和虚拟机的负载平衡等功能。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
20391浏览量
255676 -
控制器
+关注
关注
114文章
17928浏览量
195908 -
以太网
+关注
关注
41文章
6310浏览量
181972
发布评论请先 登录
动态流量池数据资源交付技术:破解网络流量调度的核心难题

深入解析NXP S32G3:高性能汽车网络处理器的技术洞察
100G 光模块单纤 VS 双纤

【TES818 】青翼凌云科技基于 VU13P FPGA+ZYNQ SOC 的 8 路 100G 光纤通道处理平台

mpo预端接光缆可以支持100G或400G 光网络吗
100G 单纤光模块:高带宽传输新选择,选型与应用全解析
创新驱动未来:睿海光电领跑100G光模块技术,赋能AI时代智算网络

引领长距传输革命:睿海光电100G QSFP28 ER4光模块赋能AI时代高速互联
创新驱动智算互联:睿海光电以100G光模块技术引领未来网络发展
赋能AI互联新纪元:睿海光电100G QSFP28 ER4光模块引领超长距传输
100G光模块:解码未来网络的高效引擎,睿海光电以创新领跑行业
100G 高速线缆:睿海光电以技术突破构筑智算互联的高效基石
100G 高速线缆:睿海光电以技术突破与极速响应赋能智算互联新时代
睿海光电:100G光模块技术创新与全球数字化赋能
【老法师】多核异构处理器中M核程序的启动、编写和仿真




评论