 在检索任务中训练数据在推理时也大有用处
在检索任务中训练数据在推理时也大有用处

从大规模数据中检索通常比较耗时,仅从训练数据中也能有巨大收益。具体做法是检索与输入文本最相似的训练样例,拼接后作为输入喂入模型,然后生成结果。结果在摘要、翻译、语言模型和QA上都取得了不错的效果。
论文:Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data[1]
Code:microsoft/REINA[2]
一句话概述:在检索任务中训练数据在推理时也大有用处。
文章上来就给我们呈现了整体的结构:
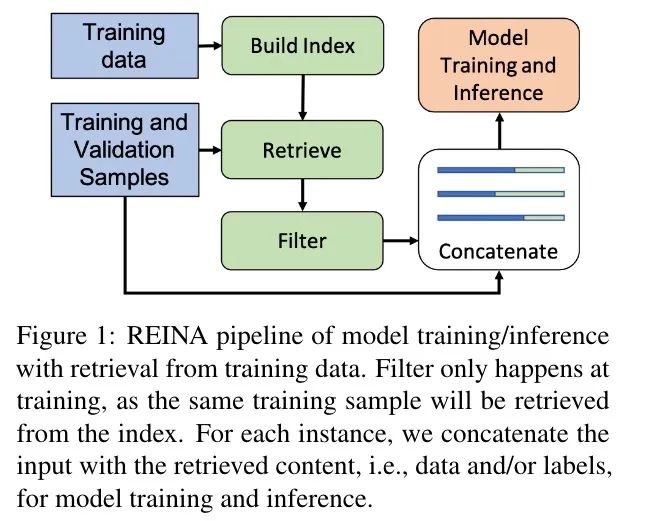
有点类似 Prompt 学习,但本文主要关注有监督学习的设置。结果不仅效果很好,而且很容易扩展(只要增加有标注训练数据就行),计算代价也小。我觉得本文相对最有意思的一个发现是文中所写:即便有成吨的参数,一个模型也不能记住训练数据中的所有模式。所以,重新捕获相关的训练数据作为一个手拉手提示器,就可以提供明确的信息来提高模型(推理)的性能。
整体架构如下图所示(REINA):
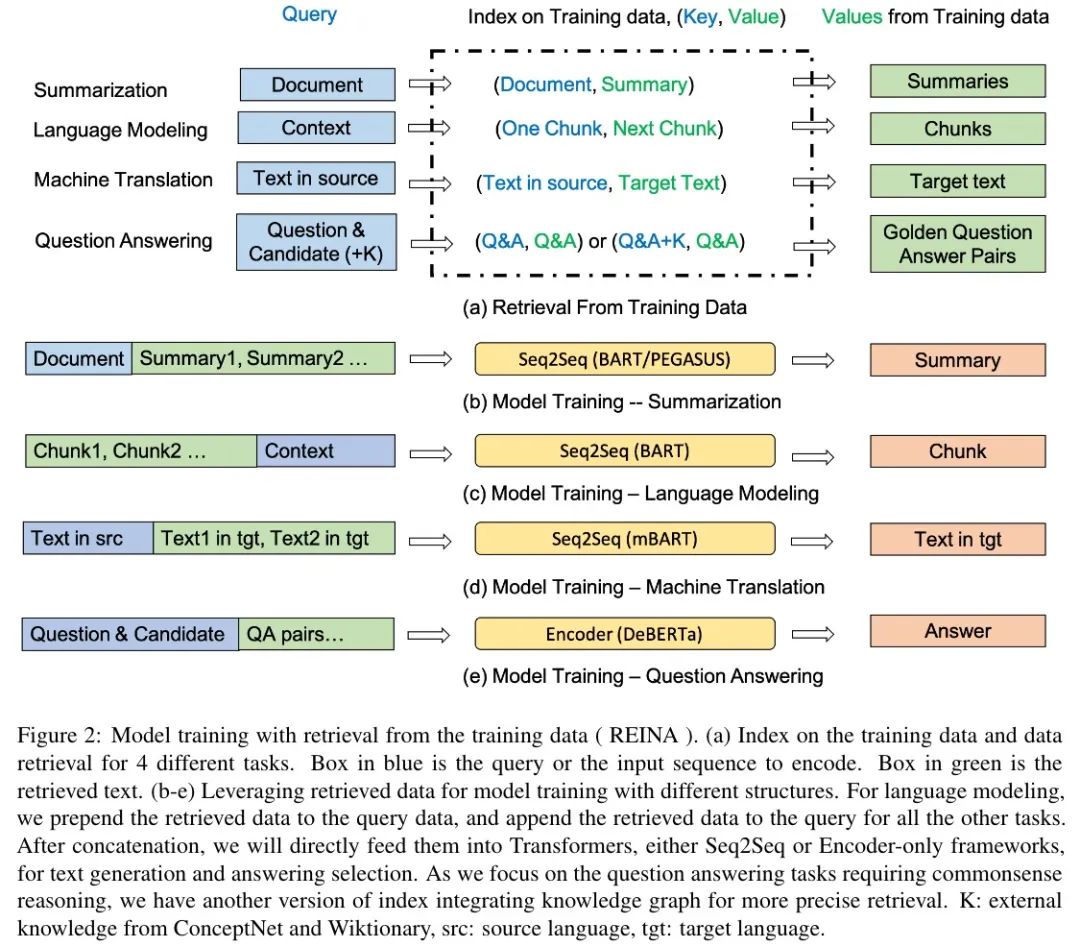
一张图其实已经很清楚地表达出意思了:对不同的任务构造不同的输入,但都会将训练数据拼接上后再喂入模型,得到最后的答案,这里的答案是通过语言模型生成的。检索算法使用 BM25。
形式化模型为:
其中,M 表示生成模型,x 是输入,大括号里的就是 top K 个检索到的最相似的训练数据。
对 QA 任务,将输入文本和每个选项拼接后作为 query,然后获取相关的训练数据。如果需要加入外部知识,则调整为:
其中,C 表示选项。拼接实体字典定义和关系 R,用来为一个 Q 构造知识 K。
Ex 表示与 Q 相关的实体,Ec 表示与 A 相关的实体。本文的相关指:在句子中出现。
用人话简单描述一下就是:给定 Q,在训练数据中找到相似的 QA 对,对每个 QA 对,找到其中所涉及的实体和关系,然后将实体的定义和关系也拼接进去,最后组成一长串文本作为模型输入。
相似检索使用 Lucene Index,模型训练使用 Transformers。实验结果(以文本摘要为例)如下:
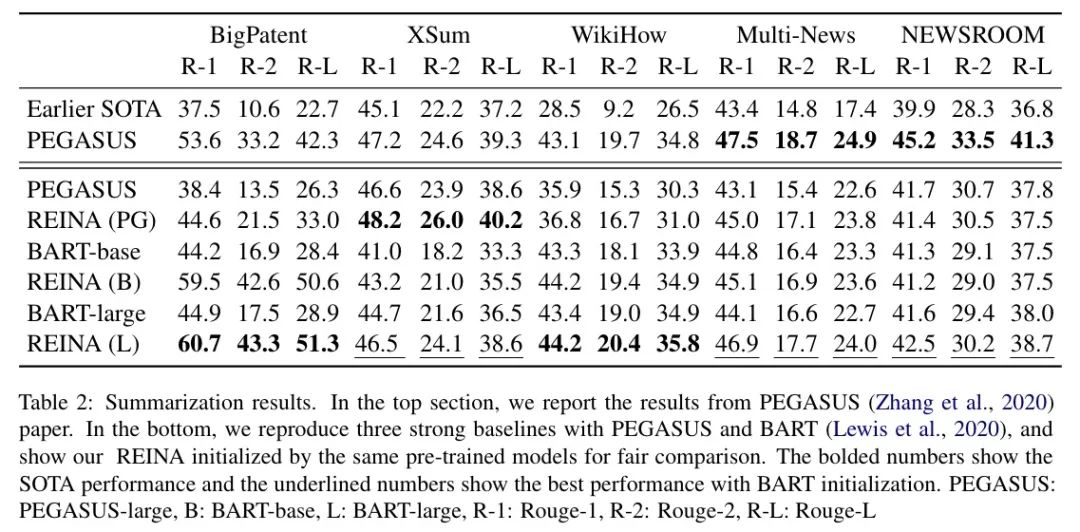
结果显示,REINA 可以显著提升(几乎所有数据集)使用不同预训练模型初始化的基线。在 case 分析时,作者发现 REINA 的数据和真实标签之间有很强的相关性。
总之,本文的思路非常简单,但效果却不错,在工业上可以一试,尤其是生成式文本摘要和 QA 任务。不过,感觉这好像也算是一种 prompt 吧,使用训练数据来「拉近」输入和真实标签之间的距离。
本文参考资料
[1]
Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data: https://arxiv.org/abs/2203.08773
[2]
microsoft/REINA: https://github.com/microsoft/REINA
审核编辑 :李倩
-
数据
+关注
关注
8文章
7348浏览量
95020 -
检索
+关注
关注
0文章
27浏览量
13432
原文标题:ACL2022 | 微软:永远不要低估你的训练数据!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【瑞萨AI挑战赛】手写数字识别模型在RA8P1 Titan Board上的部署
RAG(检索增强生成)原理与实践
从训练到推理:大模型算力需求的新拐点已至

AI推理芯片需求爆发,OpenAI欲寻求新合作伙伴
数据传输拖慢训练?三维一体调度让AI任务提速40%
使用NVIDIA Grove简化Kubernetes上的复杂AI推理
在Ubuntu20.04系统中训练神经网络模型的一些经验
一文看懂AI训练、推理与训推一体的底层关系

PCIe协议分析仪能测试哪些设备?
【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
信而泰×DeepSeek:AI推理引擎驱动网络智能诊断迈向 “自愈”时代
Aux-Think打破视觉语言导航任务的常规推理范式



评论