 FP8在大模型训练中的应用
FP8在大模型训练中的应用

越来越多的技术团队开始使用 FP8 进行大模型训练,这主要因为 FP8 有很多技术优势。比如在新一代的 GPU 上,FP8 相对于 BF16 对矩阵乘算子这样的计算密集型算子,NVIDIATensorCores能够提供两倍的峰值性能,相对于 TF32 能够提供四倍的加速,从而大大缩短计算密集型算子的计算时间。而对于访存密集型的算子,由于 FP8 所需的数据量更少,可以减轻访存压力,加速这些算子。如果在训练时使用 FP8 精度,可以更方便快速的将 FP8 部署到推理侧,使 FP8 训练可以更容易顺畅地与低精度推理相结合等。
同时,由于 FP8 的动态范围和精度相对于之前使用的 FP16/BF16/FP32 更小,如果使用 FP8 代替原来的数值精度进行训练,技术团队在模型和数据集上可能会遇到 FP8 精度的挑战。
FP8 训练的主要问题及解决思路
通过与很多技术团队交流,我们把 FP8 训练的主要问题分为以下三类,并且对可以考虑的解决思路做一个简单介绍。
Spike 问题,即 Loss Spike。其实这并不是 FP8 特有的问题,在 BF16 中也可能遇到。引起 Loss Spike 的原因比较多,比如可能与选择的算法有关,目前没有特定的解决方案。但如果 FP8 的 Spike 与 BF16 类似,我们大概率可以认为这是一个通用问题;但如果 FP8 的 Spike 更多且需要多次迭代才能恢复正常,则可能是 FP8 训练存在问题,需要进一步检查。
FP8 的 Loss 问题,可能会遇到 Loss 增加或发散的情况。我们又可以将其分为三种情况:
o 情况 1:训练开始时 Loss 就发散,这通常是软件问题,可能存在 Bug,建议使用 NVIDIA 最新的NeMo /Mcore (Megatron Core) /TE (Transformer Engine)版本来减少出错概率。
o 情况 2:检查训练配置,是否使用了新的优化点,如 CPU offloading、FP8 parameters 等新功能。可以尝试先关闭这些功能,看看是否是由此导致的问题。
o 情况 3:数值问题也可能导致 Loss 问题,可以尝试使用 BF16 进行 FP8 计算,输入为 FP8 tensor,但使用 BF16 的 GEMM。Loss 问题发生在训练中期,比如训练了几百个 token 后突然出现 Loss 上涨或发散,可以尝试其他 recipe,如 current scaling 或 fangrand scaling,或将某些层 fallback 到 BF16。最近的研究表明,因为首层和最后一层更敏感,将第一层和最后一层 fallback 到 BF16 效果提升明显。
Loss 没有问题,但下游任务指标与 BF16 有差距,也可以概括为两种情况。
o 情况 1:所有下游任务指标都有问题。建议检查下游任务指标的 inference 流程是否正确,如是否读取了正确的 scaling factor 和 weight。也可能是某些任务有问题,但其他任务可以与 BF16 对齐,这时可以尝试改变 FP8 训练的 recipe,尝试 current scaling 或部分层 fallback 到 BF16。
o 情况 2:inference 使用 BF16,但训练使用 FP8。由于模型已经是 FP8 训练的结果,使用 BF16 进行 inference 可能会引入更多误差。建议尝试使用 FP8 训练加 FP8 inference,看看下游任务打分是否恢复正常。
FP8 Debug 工具介绍
针对 FP8 训练过程中的 Debug 思路,可以参考“探索 FP8 训练中 Debug 思路与技巧”技术博客里面的总结:
https://developer.nvidia.com/zh-cn/blog/fp8-training-debug-tips/

图片来源于 NVIDIA FP8 debug 工具
FP8 的训练效果我们一般通过观察 Loss 曲线或下游任务的指标来进行评估。比如,会检查 Loss 是否发散,从而判断 FP8 是否有问题。同时我们也希望找到一些其他指标,能在训练过程中用于评估 FP8 的稳定性。此外,我们还希望通过一些指标来评估量化的误差,如果出现 FP8 训练问题,问题是发生在某个特定的层或张量上。通过这些深入的了解,我们可以帮助选择更好的训练方案,同时在训练过程中进行调整。
因此我们开发了一个 FP8 Debug 工具,这个工具中包含了一些指标,用于观察 FP8 训练的状态,包括MSE 和余弦相似性(用于 BF16 和 FP8 之间的量化误差),Tensor 的 Underflow 和 Overflow(用于查看是否因为 FP8 的动态范围比 BF16 小而导致过多的 Underflow 或 Overflow,进而引起的精度问题)。
其次,我们还记录了一些统计值,如对比 Delayed Scaling 的 Scaling Factor 与使用当前 Tensor 的 Current Scaling 的 Scaling Factor 之间的误差(这代表 Delayed Scaling 是否能准确表征当前 Tensor 的表现)。
除了这些指标外,我们还可以将这些 Tensor Dump 出来,并动态选择 Dump 哪些层,记录这些指标。
目前这个工具可以与 NVIDIA 任何版本的NeMo Megatron兼容,没有改动这些框架的内部代码,因此无论使用哪个版本的框架,都可以使用这个工具进行相应的分析。

在使用 Debug 工具进行分析的时候,我们会 Dump 一些 Tensor 并进行分析,可以看到:
包括了 Tensor 的名称和 Layer 的名称,即哪一层的哪一个 Tensor。例如,我们会 Dump Forward 的 Input,即 GEMM 的 Input 和 Weight,以及反向传播时的 Dy 的 Tensor。
可以周期性地打印不同 Step 的结果,观察整个过程中的变化,从而了解不同 Step 的情况。
可以观察不同的指标,如 AMin 和 AMax,以及 Current Scaling 和 Delay Scaling 这两种 Scaling 的区别。
通过打印出来的值,观察余弦相似性 MSE 这两种量化误差,以及 Underflow 和 Overflow 的比例来判断表现。
数据来源于 NVIDIAFP8 debug工具
工具也可以将对应的 FP8 Tensor 保存下来,以便后期进行更多的指标分析。
这些指标主要来自我们技术团队基于一些技术论文以及业务实践中的讨论和总结。
内部实验中观察到的案例:
数据来源于 NVIDIAFP8 debug工具
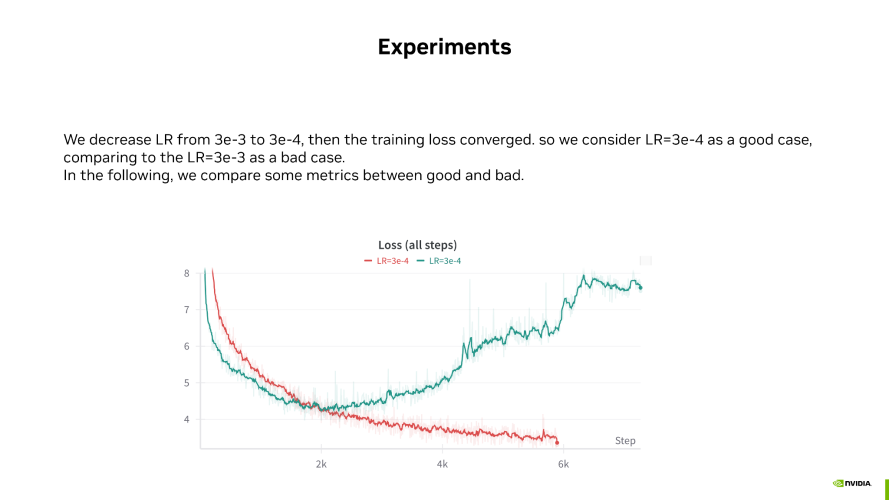
如上图所示,红色线条代表 FP8 正常收敛的 good case,没有出现 Loss 发散,Loss 在正常下降。而绿色线条则代表 FP8 的 bad case,训练到 2000 步后开始发散。这两个 case 是我们人为构造的,通过调整学习率来展示 good case 和 bad case。
以下是几个指标情况:
数据来源于 NVIDIA 内部实验
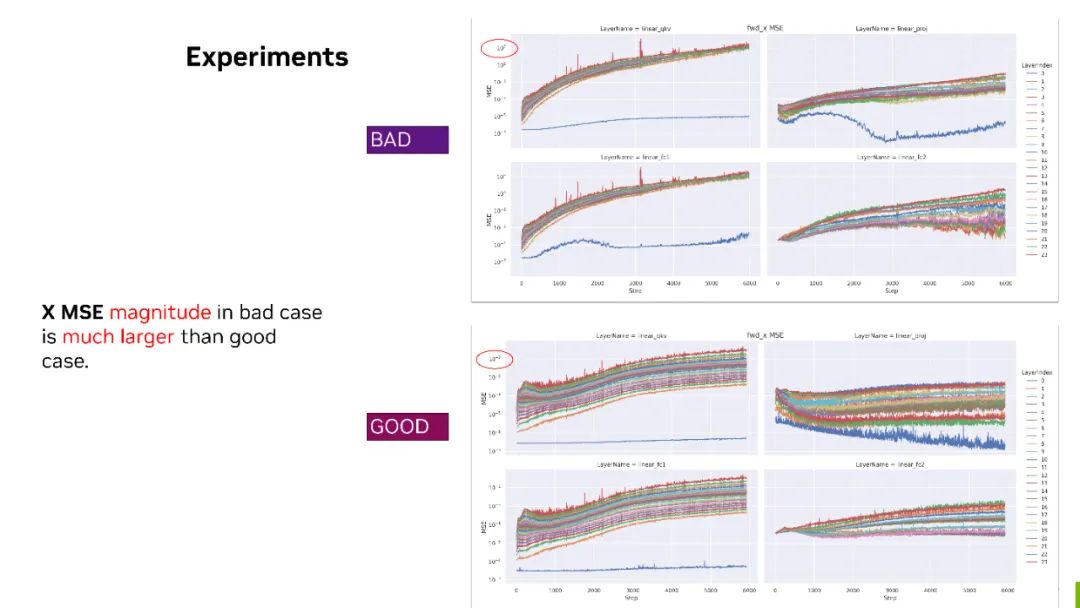
MSE - 这个指标上边的是 bad case,下边是 good case。我们把这两个放在一起,可以看到对于 forward X,bad case 下几个矩阵的 MSE 最大值都已经达到了 10 的三次方。也就是说 FP8 和 BF16 的量化误差已经到了 10 的三次方。但是对于 good case 来说,量化误差其实只有 10 的负二次方。通过这样的对比,我们可以看到对于 forward X 的 tensor 来说,它可能是有问题的。
数据来源于 NVIDIA 内部实验
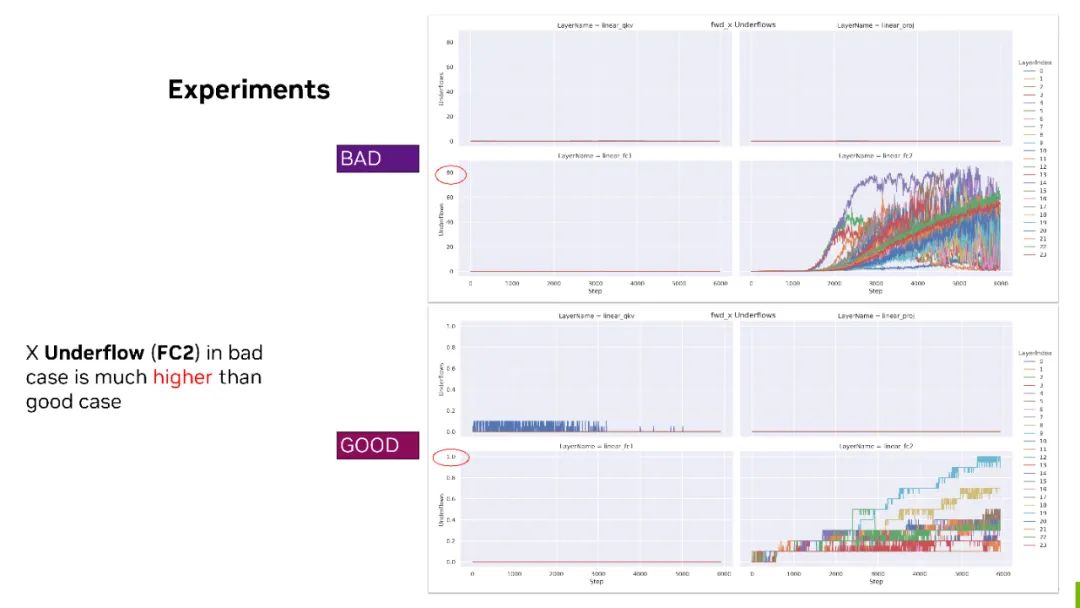
Underflow 对比 - bad case 上 FC2 的 forward X,有 80% 的最大 Underflow 比率。但对于下边 good case 来说,它最大的情况下也只有 1% 。
所以对于 forward 的 FC2 来说,X 可能需要格外关注并考虑,比如是否要 fallback 到 BF16?或者用一些其他的 scaling 策略来保证它的精度。
目前,FP8 Debug 工具还在内部测试阶段,如果希望了解或尝试该工具,可以联系您对接的 NVIDIA 技术团队,也欢迎您提供建议共同丰富这个工具的功能。
本文摘选自“NVIDIA AI加速精讲堂 —— FP8在大模型训练中的应用、挑战及实践”,可访问NVIDIA 官网观看完整在线演讲。
关于作者
黄雪
NVIDIA 解决方案架构师,硕士毕业于哈尔滨工业大学,主要负责深度学习训练方面工作,在深度学习框架、超大规模模型训练,分布式模型训练加速优化等技术方向有丰富的研究经验。
GTC 2025 将于2025 年 3 月 17 至 21 日在美国加州圣何塞及线上同步举行。
-
NVIDIA
+关注
关注
14文章
5731浏览量
110318 -
gpu
+关注
关注
28文章
5335浏览量
136237 -
大模型
+关注
关注
2文章
3877浏览量
5300
原文标题:FP8 在大模型训练中的应用、挑战及实践
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【大语言模型:原理与工程实践】大语言模型的预训练
在Ubuntu20.04系统中训练神经网络模型的一些经验
Pytorch模型训练实用PDF教程【中文】
分享一种用于神经网络处理的新8位浮点交换格式
【AI简报20231103期】ChatGPT参数揭秘,中文最强开源大模型来了!

FP8在NVIDIA GPU架构和软件系统中的应用

NVIDIA GPU架构下的FP8训练与推理

FP8模型训练中Debug优化思路

如何使用FP8新技术加速大模型训练
采用FP8混合精度,DeepSeek V3训练成本仅557.6万美元!
摩尔线程GPU原生FP8计算助力AI训练

摩尔线程发布Torch-MUSA v2.0.0版本 支持原生FP8和PyTorch 2.5.0
低精度浮点数定义——什么是 FP8、FP6、FP4?




评论