 用非参数方法提高强化学习的样本效率
用非参数方法提高强化学习的样本效率

人工智能和自主学习的最新发展表明,在棋盘游戏和电脑游戏等任务中取得了令人印象深刻的成果。然而,学习技术的适用性主要局限于模拟环境。
这种不适用于实际场景的主要原因之一是样本效率低下,无法保证最先进的强化学习的安全运行。在强化学习理论中,你想根据一个特定的指标来改善一个代理的行为。为了改进这个度量,代理可以与环境交互,从中收集观察结果和奖励。可以用两种不同的方式进行改进: 论政策 和 非保险单 。
在政策性案例中,必须通过代理人与环境的直接互动来实现改进。这种改进在数学上很简单,但由于不允许重复使用样本,因此阻碍了样本效率。当代理行为得到改善时,代理必须与环境重新交互以生成新的 on 策略样本。例如,在学习的早期阶段, agentMIG 不适合与物理环境直接交互,因为它的行为是随机的。在模拟任务中,样本的可用性是无限的,有害行为的应用没有危险。然而,对于实际应用,这些问题是严重的。
在关闭策略的情况下,可以通过与其他代理完成的环境的交互来改进代理的行为。这允许样本重用和更安全的交互,因为与环境交互的代理可以是专家。例如,人类可以通过移动机械臂来采集样本。
政策外改善的缺点是难以获得可靠的估计。在目前的技术状况下,所提出的技术要么具有高偏差,要么具有高方差。此外,有些技术对必须如何与环境进行交互有着具体而强烈的要求。
在这篇文章中,我讨论了非参数非政策梯度( NOPG ),它具有更好的偏差方差权衡,并且对如何生成非政策样本没有什么要求。 NOPG 是由 Darmstadt 的智能自治系统实验室开发的,已经被证明可以有效地解决一些经典的控制问题,并克服了目前最先进的非策略梯度估计中存在的一些问题。有关详细信息,请参见 非参数的政策外政策梯度 。
强化学习与政策外梯度
强化学习是机器学习的一个子领域,其中一个代理(我在这篇文章中称之为策略)与环境交互并观察环境的状态和奖励信号。代理人的目标是使累计折扣报酬最大化,如下式所示:

代理通常由一组参数来参数化使得它能够利用梯度优化使强化学习目标最大化。坡度关于策略参数通常是未知的,并且很难以分析形式获得。因此,你不得不用样本来近似它。利用非策略样本估计梯度主要有两种方法:半梯度法和重要性抽样法。
半梯度
这些方法在梯度展开中减少了一个项,这导致了估计量的偏差。理论上,这个偏差项仍然足够低,足以保证梯度收敛到正确的解。然而,当引入其他近似源(例如有限样本或临界近似)时,不能保证收敛到最优策略。在实践中,经常会观察到性能不佳。
重要性抽样
这些方法都是基于重要性抽样校正的。这种估计通常会受到高方差的影响,并且这种方差在强化学习环境中会被放大,因为它会随着情节的长度而倍增。涉及重要性抽样的技术需要已知的随机策略和基于轨迹的数据(与环境的顺序交互)。因此,在这种情况下,不允许不完整的数据或基于人的交互。
非参数非政策梯度估计
强化学习理论的一个重要组成部分是 Bellman 方程。 Bellman 方程递归地定义了以下值函数:

求梯度的一种方法是用非参数技术近似 Bellman 方程,并进行解析求解。具体来说,可以构造一个非参数的报酬函数和转移函数模型。
通过增加采样数和减少内核带宽,您将向右收敛到无偏解。更准确地说,当方差缩小到零时,这个估计量是一致的。
非参数 Bellman 方程的求解涉及到一组线性方程组的求解,该方程组可以通过矩阵反演或共轭梯度等近似迭代方法获得。这两种方法都是重线性代数运算,因此适合与 GPUs 并行计算。
求解非参数 Bellman 方程后,梯度的计算变得非常简单,可以使用自动微分工具,如 TensorFlow 或 PyTorch 来获得。这些工具具有易于使用的 GPU 支持,与以前仅使用 CPU 的实现相比,这些工具已经被证明实现了相当大的加速。
特别是, IASL 团队在配备了四个 NVIDIA V100 GPUs 的 NVIDIA DGX 站 上测试了 TensorFlow 和 PyTorch 两种算法。由于 NVIDIA DGX 站提供的 20 个 NVIDIA 核有助于利用多处理技术进行多次评估,因此该机器非常适合于实证评估。有关实现代码的更多信息,请参见 非参数政策外政策梯度 。
实证分析
为了评估 NOPG 相对于经典的非政策梯度方法的性能,例如深度确定性策略梯度,或具有重要抽样校正的 G-POMDP ,团队选择了一些经典的低维控制任务:
线性二次型调节器
OpenAI 健身房秋千
手推车和电杆( Quanser 平台)
OpenAI 健身山地车
我的团队的分析表明,与最先进的技术相比,这种方法更具优势。在表示为 NOPG-S 和 NOPG-D 的图中,我们分别展示了随机策略和确定性策略的算法:
PWIS (路径重要性抽样)
DPG ( deterministicpolicy gradient ),一种半梯度方法
DDPG ( deep deterministicy policy gradient ),在其经典的在线和离线模式下
该团队使用 OpenAI 基线 对在线版本的 DDPG 进行编码。
坡度的质量
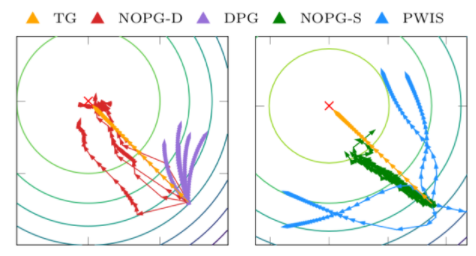
图 1 LQR 任务中的梯度方向。与 DPG 技术相比,方差是有利的。
图 1 描述了参数空间中的渐变方向。真梯度( TG )是理想的梯度方向。当 PWIS 的方差较大时, DPG 表现出较大的偏差,两种方法都无法优化策略。相反,这种同时具有随机和确定性策略的方法显示出更好的偏差/方差权衡,并允许更好和一致的策略改进。
学习曲线
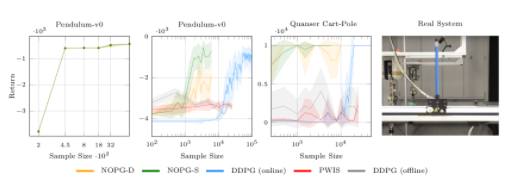
图 2 该算法( NOPG-D , NOPG-S )比其他基线具有更好的采样效率。在实际系统上,验证了所学习策略对车辆稳定性的有效性。
图 2 描述了算法关于一些经典基线的学习曲线。该算法使用较少的样本,取得了较好的效果。 cartpole 的最终策略已经在一个真实的 cartpole 上进行了测试,如右图所示。
从人类示范中学习
该算法可以处理基于人类的数据,而重要性抽样技术并不直接适用。在这个实验中,研究小组提供了次优的,人类演示的山地车任务轨迹。
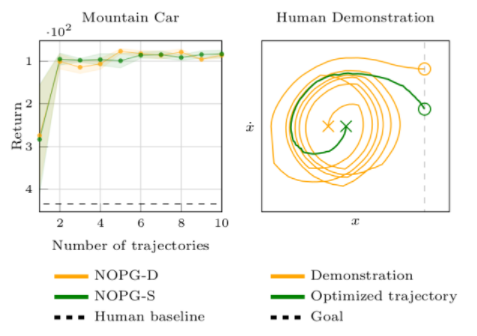
图3 在左边,提供了关于演示次数的算法学习曲线。该图附有 95% 的置信区间。右边是一个人类演示和随后的政策在空间状态下的表现的例子。
左边的图 3 显示, NOPG 可以在只有两个次优的演示或轨迹的情况下获得一个有效的策略。然而,更大的数字有助于它学习稍微好一点的政策。右边是一个人类演示的例子(橙色)和策略优化的结果(绿色)。人体在位置和速度空间的演示是次优的,因为它需要更多的步骤来达到目标位置。即使人类的演示是次优的,算法也能找到一个接近最优的策略。
今后的工作
博世人工智能中心 的一个应用是节流阀控制器。节流阀是用来调节流体或气体流量的技术装置。由于其复杂的动力学和物理约束,该装置的控制具有挑战性。
由于参数设置困难,设计最先进的控制器(如 PID 控制器)非常耗时。强化学习似乎特别适合这种应用。然而,政策外数据的可用性加上系统的低维性(系统可以用襟翼的角度和角速度来描述),使得它特别适合于 NOPG 方法。
结论
在这篇文章中,您研究了非政策梯度估计的问题。最先进的技术,如半梯度法和重要性抽样法,往往不能提供一个可靠的估计。我讨论了 NOPG ,它是在达姆施塔特的 智能自治系统( IAS ) 实验室开发的。
在经典和低维任务(如 LQR 、摆起摆锤和 cartopole )上, NOPG 方法是样本有效的,与基线相比安全(也就是说,它可以向人类专家学习)。虽然重要性抽样不适用,但该方法也能从次优的人类演示数据中学习。然而,由于非参数方法不适用于高维问题,该算法仅限于低维任务。您可以研究深度学习技术的适用性,以允许降维,以及 Bellman 方程的不同近似值的使用,从而克服非参数技术的问题。
关于作者
Samuele Tosatto 是达姆施塔特理工大学的博士生。他的主要研究方向是将强化学习应用于现实世界的机器人技术。他认为,获得更有效的学习算法对于缩短强化学习与实际机器人技术之间的差距至关重要。
审核编辑:郭婷
-
控制器
+关注
关注
114文章
17877浏览量
195141 -
机器人
+关注
关注
213文章
31444浏览量
223669 -
深度学习
+关注
关注
73文章
5608浏览量
124635
发布评论请先 登录
上汽奥迪E5 Sportback车型升级搭载全新Momenta强化学习大模型
上汽大众ID. ERA 9X全球首发搭载Momenta R7强化学习世界模型
Momenta R6强化学习大模型上车东风日产NX8
Momenta强化学习大模型助力别克至境世家纯电版正式上市
Momenta R7强化学习世界模型即将推出
自动驾驶中常提的离线强化学习是什么?

强化学习会让自动驾驶模型学习更快吗?

多智能体强化学习(MARL)核心概念与算法概览

上汽别克至境E7首发搭载Momenta R6强化学习大模型
提高系统效率几个误解解析
如何提高RCA清洗的效率
今日看点:智元推出真机强化学习;美国软件公司SAS退出中国市场
自动驾驶中常提的“强化学习”是个啥?

如何提高光刻胶残留清洗的效率

NVIDIA Isaac Lab可用环境与强化学习脚本使用指南




评论