 使用NVIDIA CUDA-Pointpillars检测点云中的对象
使用NVIDIA CUDA-Pointpillars检测点云中的对象

点云是坐标系中的点数据集。点包含丰富的信息,包括三维坐标(X、Y、Z)、颜色、分类值、强度值和时间等。点云主要来自于各种NVIDIA Jetson用例中常用的激光雷达,如自主机器、感知模块和3D建模。
其中一个关键应用是利用远程和高精度的数据集来实现3D对象的感知、映射和定位算法。
PointPillars是最常用于点云推理的模型之一。本文将探讨为Jetson开发者提供的NVIDIA CUDA加速PointPillars模型。马上下载CUDA-PointPillars模型。
什么是CUDA-Pointpillars
本文所介绍的CUDA-Pointpillars可以检测点云中的对象。其流程如下:
基本预处理:生成柱体。
预处理:生成BEV特征图(10个通道)。
用于TensorRT的ONNX模型:通过TensorRT实现的ONNX模式。
后处理:通过解析TensorRT引擎输出生成边界框。

图 1 。 CUDA 点柱管道。
基本预处理
基本预处理步骤将点云转换为基本特征图。基本特征图包含以下组成部分:
基本特征图。
柱体坐标:每根柱体的坐标。
参数:柱体数量。
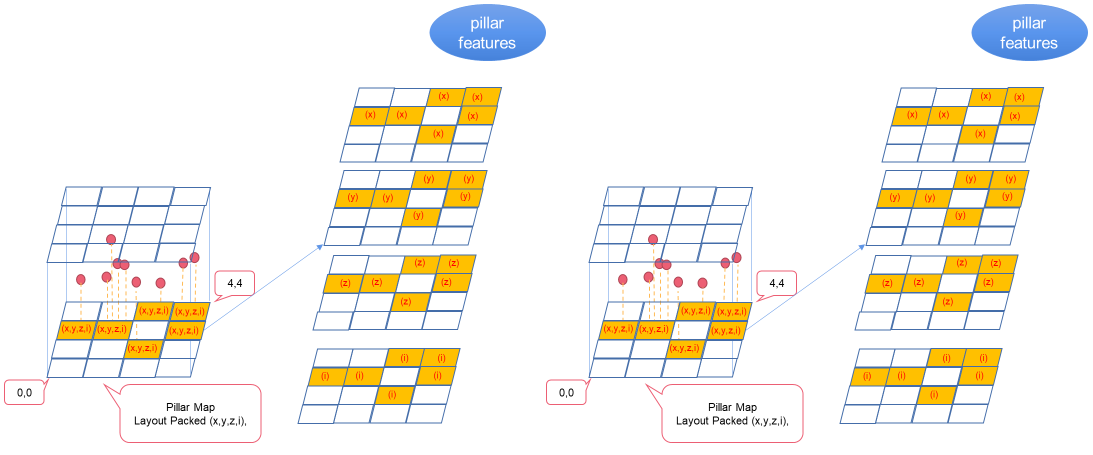
图 2 。将点云转换为基础要素地图
预处理
预处理步骤将基本特征图(4个通道)转换为 BEV 特征图(10个通道)。
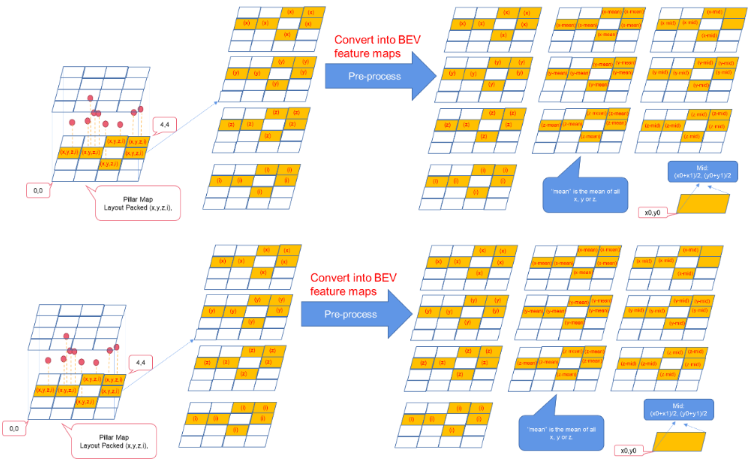
图 3 。将基本要素地图转换为 BEV 要素地图
用于TensorRT的ONNX模型
出于以下原因修改OpenPCDet的原生点柱:
小型操作过多,并且内存带宽低。
NonZero等一些TensorRT不支持的操作。
ScatterND等一些性能较低的操作。
使用“dict”作为输入和输出,因此无法导出ONNX文件。
为了从原生OpenPCDet导出ONNX,我们修改了该模型(图4)。
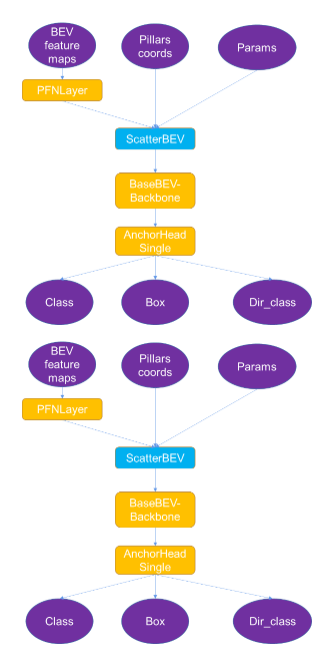
图 4 。 CUDA Pointpillars 中 ONNX 模型概述。
您可把整个ONNX文件分为以下几个部分:
输入:BEV特征图、柱体坐标、参数,均在预处理中生成。
输出:类、框、Dir_class,在后处理步骤中解析后生成一个边界框。
ScatterBEV:将点柱(一维)转换为二维图像,可作为TensorRT的插件。
其他:TensorRT支持的其他部分。
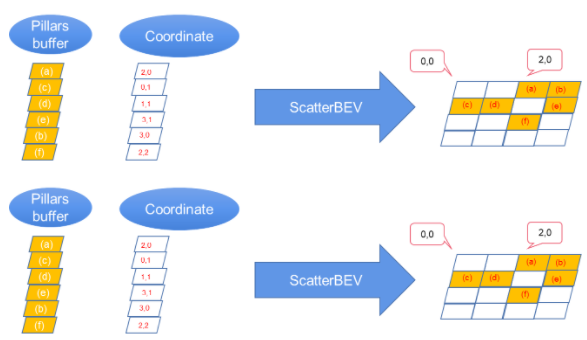
图 5 。将点支柱数据散射到二维主干的二维图像中。
后处理
在后处理步骤中解析TensorRT引擎的输出(class、box和dir_class)和输出边界框。图6所示的是示例参数。
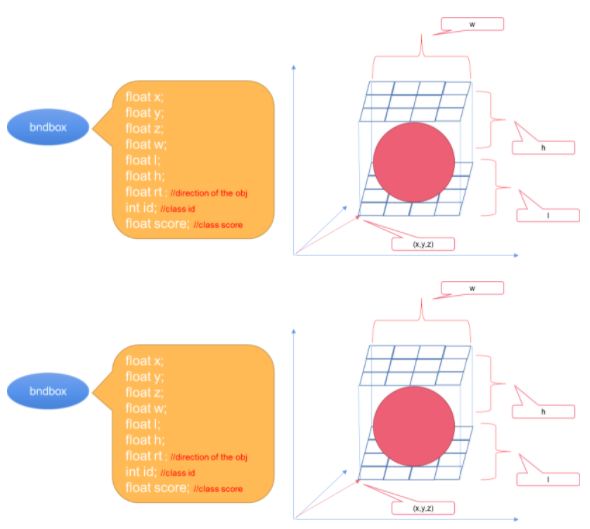
图 6 。边界框的参数。
使用 CUDA PointPillars
若要使用CUDA-PointPillars,需要提供点云的ONNX模式文件和数据缓存:
std::vectornms_pred; PointPillar pointpillar(ONNXModel_File, cuda_stream); pointpillar.doinfer(points_data, points_count, nms_pred);
将OpenPCDet训练的原生模型转换为CUDA-Pointpillars的ONNX文件
我们在项目中提供了一个Python脚本,可以将OpenPCDet训练的原生模型转换成CUDA-Pointpillars的ONNX文件。可在CUDA-Pointpillars的/tool 目录下找到exporter.py 脚本。
可在当前目录下运行以下命令获得pointpillar.onnx文件:
$ python exporter.py --ckpt ./*.pth
性能
下表显示了测试环境和性能。在测试之前提升CPU和GPU的性能。

表 1 测试平台与性能
开始使用 CUDA PointPillars
本文介绍了什么是CUDA-PointPillars以及如何使用它来检测点云中的对象。
由于原生OpenPCDet无法导出ONNX,而且对于TensorRT来说,性能较低的小型操作数量过多,因此我们开发了CUDA-PointPillars。该应用可以将OpenPCDet训练的原生模型导出为特殊的ONNX模型,并通过TensorRT推断ONNX模型。
关于作者
Lei Fan 是 NVIDIA 的高级 CUDA 软件工程师。他目前正与 TSE 中国团队合作,开发由 CUDA 优化软件性能的解决方案。
Lily Li 正在为 NVIDIA 的机器人团队处理开发人员关系。她目前正在 Jetson 生态系统中开发机器人技术解决方案,以帮助创建最佳实践。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5687浏览量
110115 -
数据集
+关注
关注
4文章
1240浏览量
26261
发布评论请先 登录
NVIDIA推出cuEST量子化学加速库
NVIDIA cuDF和cuVS获全球领先数据平台采用
NVIDIA携手全球工业软件巨头构建AI智能体加速设计与工程开发流程
借助NVIDIA CUDA Tile IR后端推进OpenAI Triton的GPU编程
如何在NVIDIA CUDA Tile中编写高性能矩阵乘法


NVIDIA RTX PRO 5000 Blackwell GPU的深度评测

如何解决激光雷达点云中“鬼影”和“膨胀”问题?
NVIDIA CUDA Tile的创新之处、工作原理以及使用方法

在Python中借助NVIDIA CUDA Tile简化GPU编程

NVIDIA CUDA 13.1版本的新增功能与改进
NVIDIA 与新思科技宣布建立战略合作伙伴关系,携手重塑工程与设计未来




评论