 NVIDIA CUDA Tile的创新之处、工作原理以及使用方法
NVIDIA CUDA Tile的创新之处、工作原理以及使用方法

NVIDIA CUDA 13.1 推出 NVIDIA CUDA Tile,这是自 2006 年 NVIDIA CUDA 平台发明以来,最大的一次技术进步。这一令人振奋的创新引入了一套面向 Tile-based 并行编程的虚拟指令集,使开发者能够在更高层级编写算法,而无需关心底层专用硬件(如 Tensor Cores)的复杂细节。
本文将介绍 CUDA Tile 的创新之处、工作原理以及使用方法。
为什么在 GPU 上需要 Tile 编程?
CUDA 为开发者提供了一种单指令多线程(SIMT)的硬件与编程模型。这既要求也允许开发者对代码执行方式进行非常细致的控制,从而实现最大化的灵活性。然而,要让代码在各种不同的 GPU 架构上都表现良好,往往需要投入大量的调优工作。
NVIDIA CUDA-X、NVIDIA CUTLASS 等库为开发者提供了性能优化工具,而 CUDA Tile 则进一步提供了一种比传统 SIMT 更高层次的 GPU 编程方式。
随着计算任务的发展,尤其是 AI 领域中,Tensors 已经成为基础的数据类型。NVIDIA 也开发了面向 Tensors 运算的专用硬件,例如 NVIDIA Tensor Cores(TC)和 NVIDIA Tensor Memory Accelerators(TMA),并已成为所有新 GPU 架构的核心组件。
但硬件越复杂,软件就越需要承担抽象与封装的职责。CUDA Tile 对 Tensor Cores 及其编程模式进行了抽象,让使用 CUDA Tile 的代码天然兼容当前与未来的 Tensor Core 架构。
Tile-based 编程的方式是:你只需指定一块块数据,即Tiles,以及这些 Tiles 上要执行的运算即可。你不再需要在元素级别指定算法的执行方式,编译器和运行时(runtime )会自动处理。
图 1 展示了 CUDA Tile 引入的 Tile 模型,与传统 CUDA SIMT 模型之间的概念性差异。

图 1. Tile 模型(左)将数据划分为 Blocks,而编译器将其映射到 Threads。SIMT 模型(右)则将数据映射到 Blocks 和 Threads
这种编程模式在 Python 这样的语言中很常见,用户可以通过 NumPy 这样的库指定矩阵等数据类型,然后用简单的代码指定并执行批量操作。在底层,一切都会按正确的方式运行,而你的计算对你来说始终完全透明。
CUDA Tile IR:Tile 编程的基础
CUDA Tile 的基础是 CUDA Tile IR(中间表示)。CUDA Tile IR 引入了一套虚拟指令集,使得以 Tile Operations 的方式对硬件进行原生编程成为可能。开发者可以编写更高层级的代码,并且在多代 GPU 上仅需做极少的改动即可高效执行。
虽然 NVIDIA Parallel Thread Execution(PTX)为 SIMT 程序提供了可移植性,但 CUDA Tile IR 为 CUDA 平台扩展了对 Tile-based 程序的原生支持。开发者专注于将他们的数据并行程序划分为 Tiles 和 Tile Blocks,并让 CUDA Tile IR 来处理将其映射到诸如 Threads、内存层次结构以及 Tensor Cores 等硬件资源上。
通过提升抽象层级,CUDA Tile IR 使用户能够为 NVIDIA 硬件构建更高层次的、面向硬件的编译器、框架以及领域专用语言(DSLs)。用于 Tile 编程的 CUDA Tile IR 类似于用于 SIMT 编程的 PTX。
需要指出的一点是,这并不是一个非此即彼的选择。GPU 上的 Tile 编程是编写 GPU 代码的另一种方法,但你不必在 SIMT 和 Tile 编程之间做选择,它们是共存的。当你需要 SIMT 时,你依旧像以往一样编写你的 Kernels。当你希望使用 Tensor Cores 来执行运算时,你就编写 Tile Kernels。
图 2 展示了一个关于 CUDA Tile 如何嵌入典型软件栈的高层示意图,以及 Tile 路径如何作为一条独立但互补于现有 SIMT 路径的编译路径。
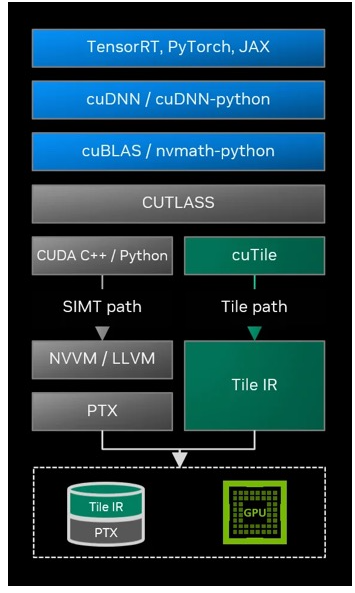
图 2. Tile 的编译路径嵌入完整的软件栈之中,并与 SIMT 路径并列存在
开发者应如何使用 CUDA Tile 编写 GPU 应用?
CUDA Tile IR 位于与绝大多数程序员交互的 Tile 编程的下一层级。除非你正在编写一个编译器或库,否则你大概不需要关心 CUDA Tile IR 软件的细节。
NVIDIA cuTile Python:大多数开发者将通过诸如 NVIDIA cuTile Python 这样的软件与 CUDA Tile 编程进行交互——这是一种由 NVIDIA 提供的 Python 实现,使用 CUDA Tile IR 作为后端。我们有一篇博客解释了如何使用 cuTile-python,并附上了示例代码和文档的链接。
CUDA Tile IR:对于希望构建自己 DSL 编译器或库的开发者而言,CUDA Tile IR 就是你与 CUDA Tile 交互的地方。CUDA Tile IR 文档和规范包含关于 CUDA Tile IR 编程抽象、语法和语义的信息。如果你正在编写一个当前以 PTX 为目标的工具/编译器/库,那么你可以调整你的软件以同时以 CUDA Tile IR 为目标。
如何获取 CUDA Tile 软件
CUDA Tile 随 CUDA 13.1 一同发布。开发者可以通过 CUDA Tile 页面,获取包括文档链接、GitHub 库以及示例代码等信息。
关于作者
Jonathan Bentz 领导 NVIDIA 的 CUDA 技术营销工程团队,其团队专注于创建和提供引人入胜的内容,并与 CUDA 开发者建立联系。Jonathan 拥有爱荷华州立大学化学博士学位和计算机科学硕士学位。
Tony Scudiero 是 CUDA 平台的技术营销工程师。他致力于将 CUDA 带给各种类型和能力的开发者。在 NVIDIA 任职期间,他曾使用过大型 HPC 系统和应用、实时声学模拟 (VRWorks Audio) 和 Omniverse RTX 渲染器。
-
NVIDIA
+关注
关注
14文章
5731浏览量
110318 -
硬件
+关注
关注
13文章
3681浏览量
69252 -
编程
+关注
关注
90文章
3729浏览量
97536
原文标题:专注于你的算法 – 让 NVIDIA CUDA Tile 来处理硬件细节
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何在NVIDIA CUDA Tile中编写高性能矩阵乘法

NVIDIA Grid SERIES K2卡兼容CUDA?
Grid K2 cuda下载位置是?
数码管的工作原理及使用方法
SRAM的工作原理及其使用方法了解
CUDA核心是什么?CUDA核心的工作原理

点焊机的工作原理及使用方法

在Python中借助NVIDIA CUDA Tile简化GPU编程




评论