 机器学习模型调优3大策略
机器学习模型调优3大策略

无论是 Kaggle 竞赛还是工业部署,机器学习模型在搭建起来之后都面临着无尽的调优需求。在这个过程中我们要遵循怎样的思路呢?
如果准确性不够,机器学习模型在真实世界就没有什么实用性了。对于开发者们来说,如何提高性能是非常重要的工作,本文将介绍一些常用策略,包括选择最佳算法、调整模型设置和特征工程。 如果你学习过正确的教程,很快就能训练起自己的第一个机器学习模型。然而想要在第一个模型上跑出很好的效果是极难的。在模型训练完后,我们需要花费大量时间进行调整以提高性能。不同类型的模型有不同的调优策略,在本文中,我们将介绍模型调优的常用策略。 模型好不好? 在模型调优之前,我们首先需要知道现在的模型性能是好是坏。如果你不知道如何衡量模型的性能,可以参考:
https://www.mage.ai/blog/definitive-guide-to-accuracy-precision-recall-for-product-developers
https://www.mage.ai/blog/product-developers-guide-to-ml-regression-model-metrics
每个模型都有基线指标。我们可以使用「模式类别」作为分类模型的基线指标。如果你的模型优于基准线,那么恭喜你,这是一个好的开始。如果模型能力还没有达到基准水平,这说明你的模型还没有从数据中获得有价值的见解(insight)。为了提高性能,还有很多事情要做。 当然还有一个情况就是模型的表现「太过优秀」了,比如 99% 的准确率和 99% 的召回率。这并不是什么好事,可能表示你的模型存在一定的问题。一个可能的原因是「数据泄露」,我们将在「消除数据泄漏功能」部分讨论如何解决此问题。 改进模型的策略 一般来说,模型调优有 3 个方向:选择更好的算法,调优模型参数,改进数据。 比较不同算法 比较多个算法是提高模型性能的一个简单的想法,不同的算法适合不同类型的数据集,我们可以一起训练它们,找到表现最好的那个。例如对于分类模型,我们可以尝试逻辑回归、支持向量机、XGBoost、神经网络等。
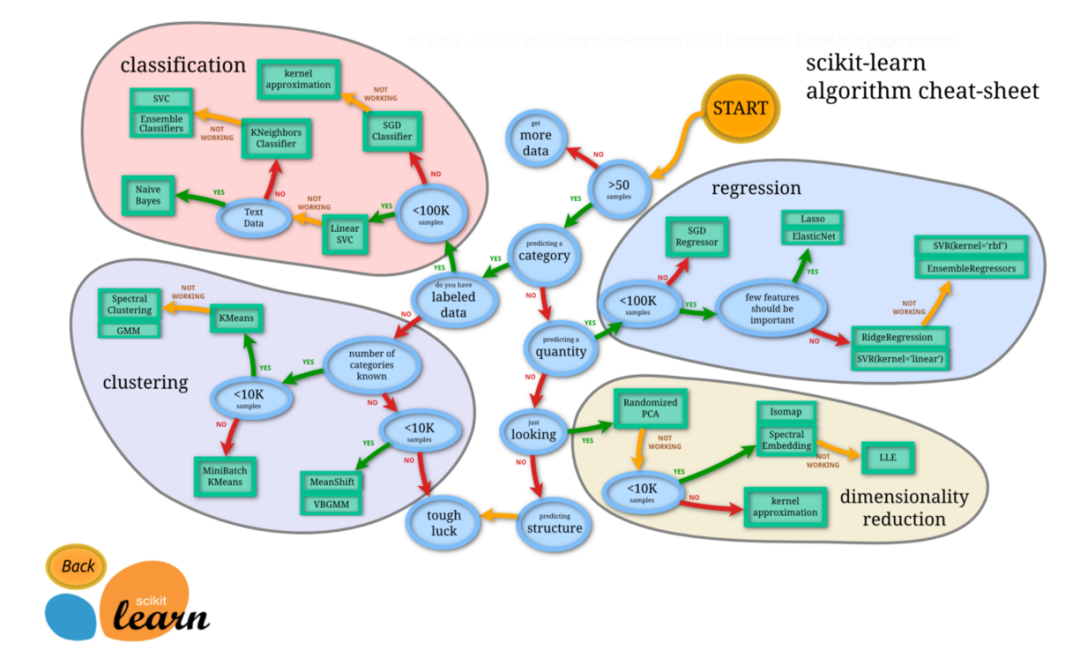
图源:https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html 超参数调优 超参数调优是一种常用的模型调优方法。在机器学习模型中,学习过程开始之前需要选择的一些参数被称为超参数。比如决策树允许的最大深度,以及随机森林中包含的树的数量。超参数明显影响学习过程的结果。调整超参数可以让我们在学习过程中很快获得最佳结果。
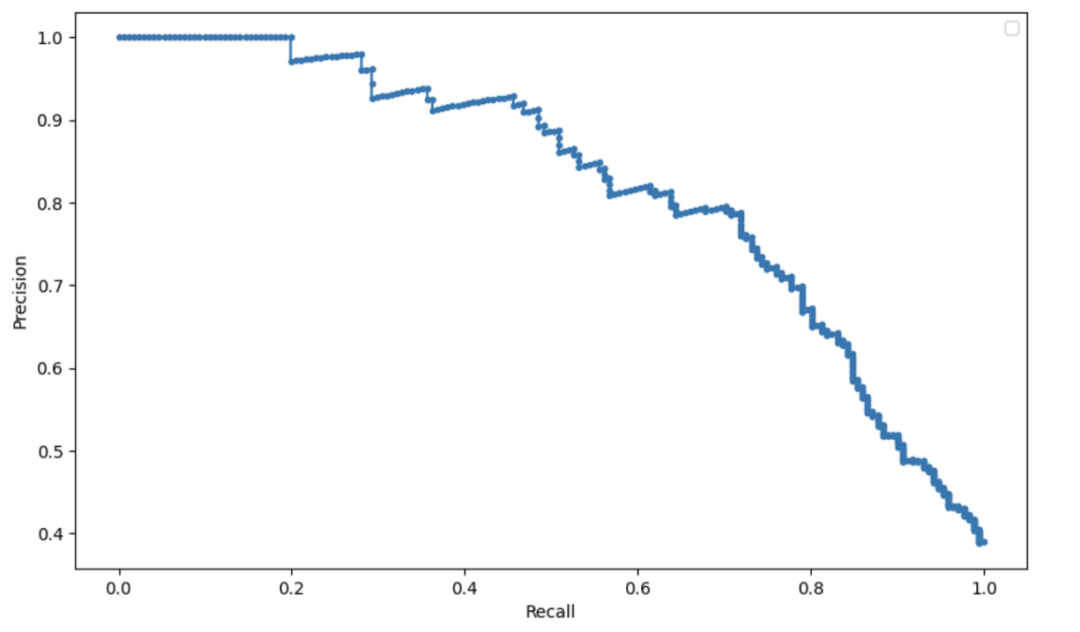
我们非常建议使用公开可用的库帮助进行超参数调整,例如 optuna。 用召回率换精度 对于分类模型,我们通常用 2 个指标来衡量模型的性能:精度和召回率。根据问题的不同,你可能需要优化召回率或精度中的一个。有一种快速的方法来调整模型以在两个指标之间进行权衡。分类模型预测标签类别的概率,因此我们可以简单地修改概率阈值来修改召回率和精度。 例如,如果我们建立一个模型来预测乘客在泰坦尼克号沉船事故中是否生还,该模型可以预测乘客生还或死亡的概率。果概率高于 50%,模型将预测乘客会幸存,反之乘客死亡。如果我们想要更高的精度,我们可以增加概率阈值。然后,该模型将预测较少的乘客幸存,但会更精确。
特征工程 除了选择最佳算法和调优参数外,我们还可以从现有数据中生成更多特征,这被称为特征工程。 创建新的特征 构建新的特征需要一定的领域知识和创造力。这是一个构建新特征的例子:
创建一个功能来计算文本中的字母数。
创建一个功能来计算文本中的单词数。
创建一个理解文本含义的特征(例如词嵌入)。
过去 7 天、30 天或 90 天的聚合用户事件计数。
从日期或时间戳特征中提取「日」、「月」、「年」和「假期后的天数」等特征。
使用公共数据集来增加训练数据 当你穷尽从现有数据集中生成新特征的想法时,另一个想法是从公共数据集中获取特征。假如你正在构建一个用来预测用户是否会转换为会员的模型,可用的数据集中却没有太多的用户信息,只有「电子邮件」和「公司」属性。那么你就可以从第三方获取用户和公司以外的数据,如用户地址、用户年龄、公司规模等等,这些数据可以用于丰富你的训练数据。
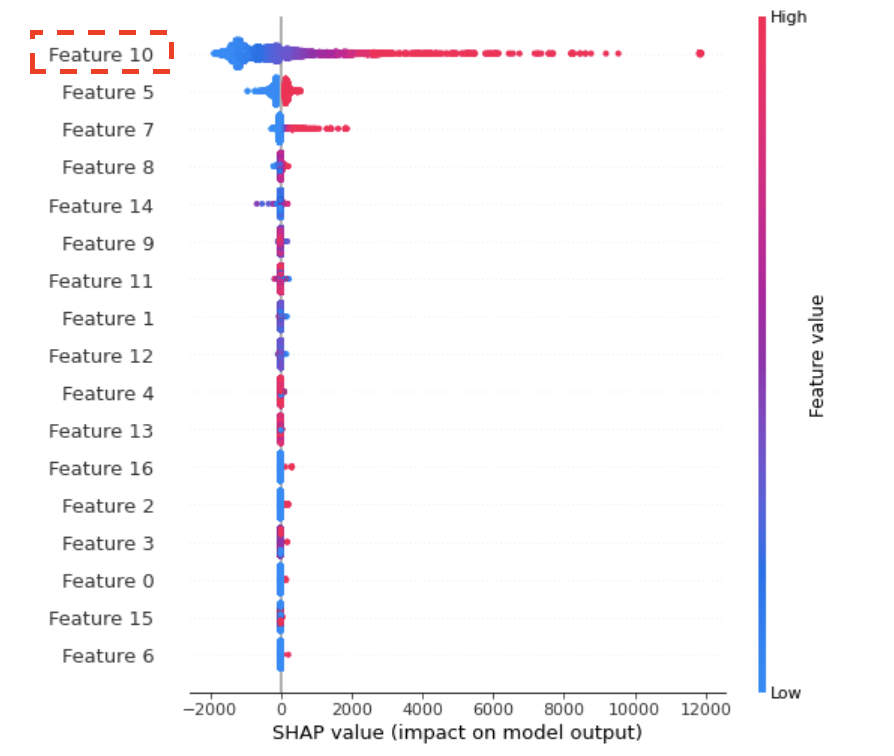
特征选择 添加更多特征并不总是好的。去除不相关和嘈杂的特征有助于减少模型训练时间并提高模型性能。scikit-learn 中有多种特征选择方法可以用来去除不相关的特征。 删除数据泄露(data leakage)特征 正如上文提到的,一种场景是模型的性能「非常好」。但是在部署模型并在生产中使用这些模型时,性能会变得很差。造成这个问题的原因可能是「数据泄露」,这是模型训练的一个常见陷阱。数据泄露是指使用一些发生在目标变量之后的特征,并包含目标变量的信息。然而现实生活中的预测不会有那些数据泄露特征。 例如想要预测用户是否会打开电子邮件,特征可能就包括用户是否点击了电子邮件。模型一旦看到用户点击了它,那么就预测用户 100% 会打开它。然而在现实生活中,我们无法知道是否有人在打开电子邮件之前没有点击它。 我们可以使用 SHAP 值 debug 数据泄露问题,用 SHAP 库绘制图表可以显示出影响最大的特征以及它们如何定向影响模型的输出。如果特征与目标变量高度相关并且权重非常高,那么它们可能是数据泄露特征,我们可以将它们从训练数据中删除。
更多数据 获取更多训练数据是提高模型性能一种明显而有效的方法。更多的训练数据能够让模型找到更多见解,并获得更高的准确率。
那么,什么时候该停止调优了? 你需要知道如何开始,也需要知道在何时停止,很多时候怎样才算足够是一个难以回答的问题。模型的提升仿佛是无限的,没有终点:总会有新想法带来新数据、创建新功能或算法的新调整。首先,最低限度的标准是模型性能至少应优于基线指标。一旦满足了最低标准,我们应该采用以下流程来改进模型并判断何时停止:
尝试所有改进模型的策略。
将模型性能与你必须验证的其他一些指标进行比较,以验证模型是否有意义。
在进行了几轮模型调整后,评估一下继续修改和性能提升百分点之间的性价比。
如果模型表现良好,并且在尝试了一些想法后几乎没有继续改进,请将模型部署到生产过程中并测量实际性能。
如果真实条件下的性能和测试环境中类似,那你的模型就算可以用了。如果生产性能比训练中的性能差,则说明训练中存在一些问题,这可能是因为过拟合或者数据泄露。这意味着还需要重新调整模型。
结论 模型调优是一个漫长而复杂的过程,包含模型的重新训练、新想法的试验、效果评估和指标对比。通过本文介绍的思路,希望你可以将自己的机器学习技术提升到更高的水平。
审核编辑 :李倩
-
算法
+关注
关注
23文章
4817浏览量
98863 -
模型
+关注
关注
1文章
3880浏览量
52364 -
机器学习
+关注
关注
67文章
8571浏览量
137447
原文标题:收藏 | 机器学习模型调优3大策略
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
2026年MySQL性能调优实战:用Gemini镜像站诊断慢查询与索引优化(国内直访教程)

Nginx高并发连接调优实战手册
直流固态变压器控制策略仿真解决方案
Linux系统内核参数调优实战指南
性能测试调优实战与探索(存储模型优化+调用链路分析)

实战RK3568性能调优:如何利用迅为资料压榨NPU潜能-在Android系统中使用NPU




评论