 使用NCCL 2.12将所有all2all性能翻倍
使用NCCL 2.12将所有all2all性能翻倍

集体通信是现代分布式人工智能培训工作(如推荐系统和自然语言处理)的一个关键性能组成部分。
NVIDIA Collective Communication Library ( NCCL )是一个 Magnum IO 库,可实现 GPU 加速的集体操作:
集合
全部减少
广播
减少
减少分散
点对点发送和接收
NCCL 具有拓扑意识,经过优化,可通过 PCIe 、 NVLink 、以太网和 InfiniBand 互连实现高带宽和低延迟。 NCCL GCP 插件 和 NCCL AWS 插件 通过自定义网络连接,在流行的云环境中实现高性能 NCCL 操作。
NCCL 版本一直致力于提高集体沟通绩效。这篇文章主要关注 NCCL 2.12 版本带来的改进。
结合 NVLink 和网络通信
NCCL 2.12 中引入的新功能称为 PXN ,称为 PCI × NVLink ,因为它使 GPU 能够通过 NVLink 然后通过 PCI 与节点上的 NIC 通信。这不是使用 QPI 或其他无法提供全部带宽的 CPU 协议通过 CPU 。这样,即使每个 GPU 仍然尽可能多地使用其本地 NIC ,但如果需要,它可以访问其他 NIC 。
GPU 在中间 GPU 上准备缓冲区,通过 NVLink 写入,而不是在其本地内存上准备缓冲区供本地 NIC 发送。然后,它通知管理该 NIC 的 CPU 代理数据已就绪,而不是通知其自己的 CPU 代理。 GPU- CPU 同步可能会稍微慢一点,因为它可能必须穿过 CPU 插槽,但数据本身只使用 NVLink 和 PCI 交换机,以保证最大带宽。
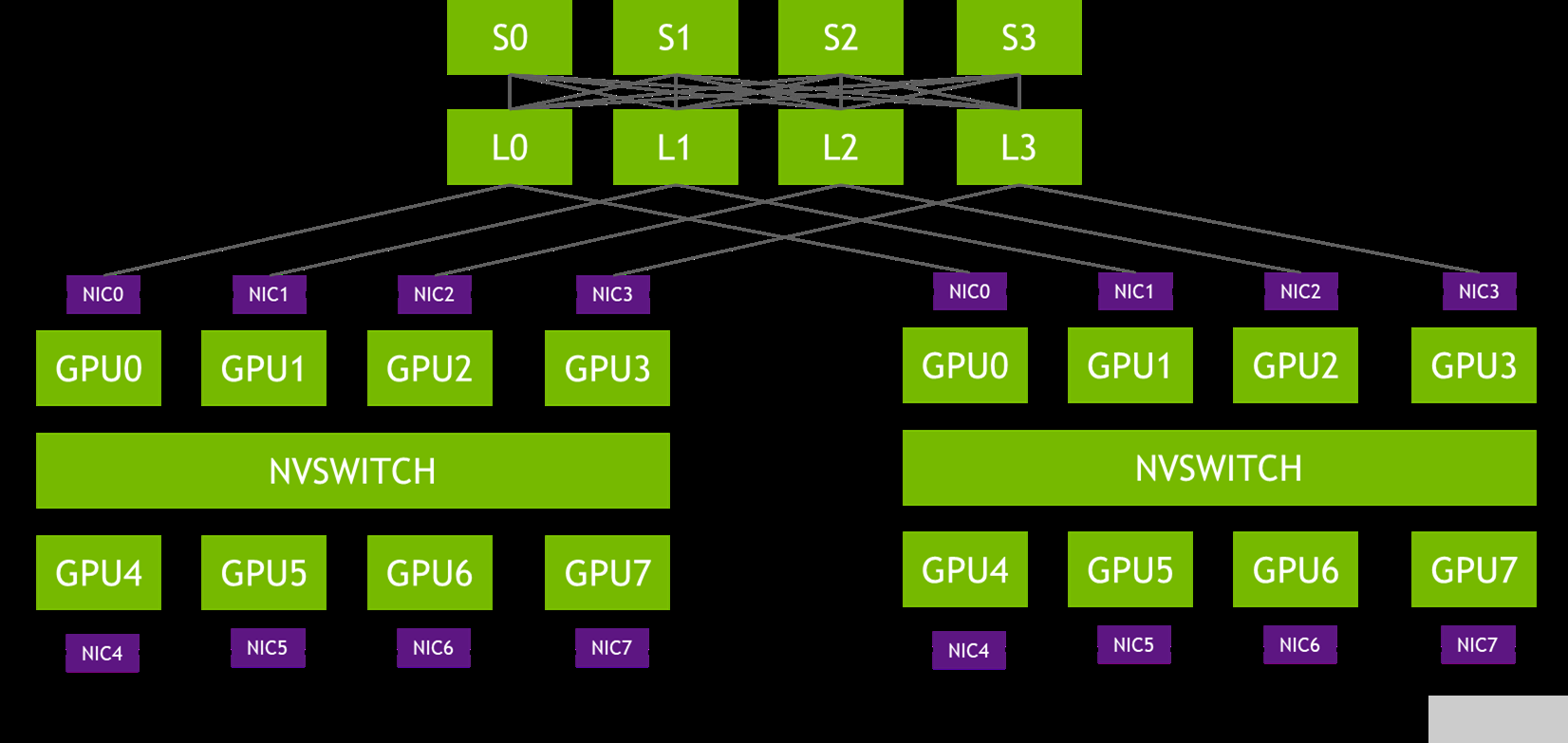
图 1 。轨道优化拓扑
在图 1 的拓扑中,每个 DGX 系统的 NIC-0 连接到同一个叶交换机( L0 ), NIC-1 连接到同一个叶交换机( L1 ),依此类推。这种设计通常被称为 rail-optimized 。铁路优化网络拓扑有助于最大限度地提高所有流量,降低性能,同时最大限度地减少流量之间的网络干扰。它还可以通过轻轨之间的连接来降低网络成本。
PXN 利用节点内 GPU 之间的 NVIDIA NVSwitch 连接,首先将 GPU 上的数据移动到与目的地相同的轨道上,然后在不跨越轨道的情况下将其发送到目的地。这可以实现消息聚合和网络流量优化。
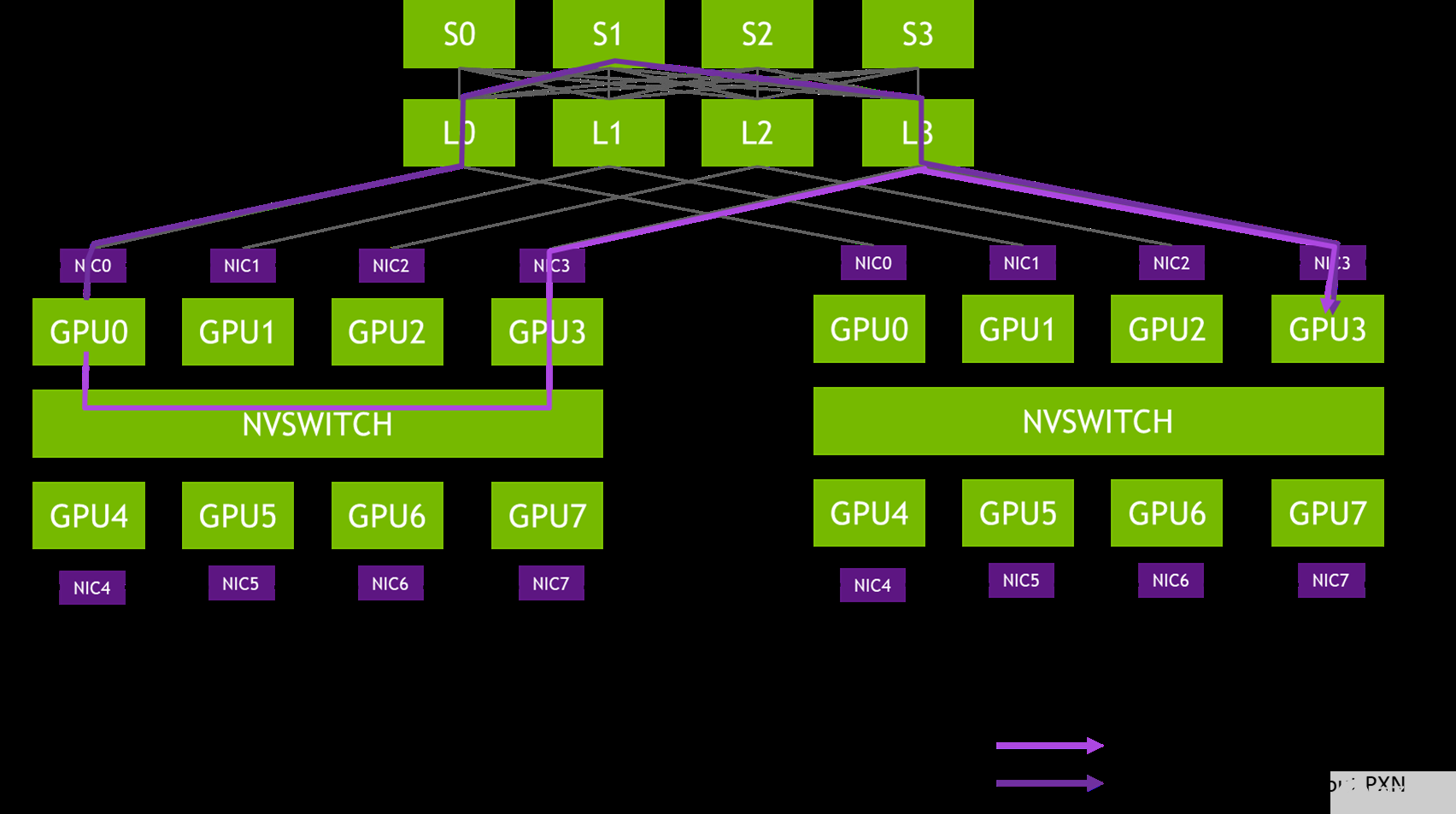
图 2 。从 DGX-A 中的 GPU0 到 DGX-B 中的 GPU3 的消息路径示例
在 NCCL 2.12 之前,图 X 中的消息会穿过网络交换机的三个跃点( L0 、 S1 和 L3 ),这可能会导致争用,并被其他流量减慢。在同一对 NIC 之间传递的消息被聚合,以最大限度地提高有效消息速率和网络带宽。
消息聚合
使用 PXN ,给定节点上的所有 GPU 将其数据移动到给定目的地的单个 GPU 上。这使得网络层能够通过实现新的多接收功能来聚合消息。该功能使远程 CPU 代理能够在所有消息准备就绪后立即将它们作为一个整体发送。
例如,如果节点上的 GPU 正在执行 all2all 操作,并且要从远程节点的所有八个 GPU 接收数据, NCCL 调用具有八个缓冲区和大小的多接收。在发送方方面,网络层可以等待所有八次发送就绪,然后一次发送所有八条消息,这会对消息速率产生显著影响。
消息聚合的另一个方面是,现在在给定目的地的所有 GPU 节点之间共享连接。这意味着要建立的连接更少。如果路由算法依赖于有很多不同的连接来获得良好的熵,这也会影响路由效率。
PXN 提高了所有 2 的性能
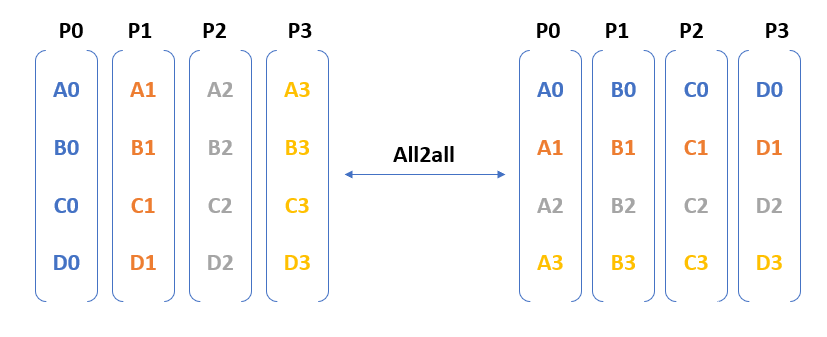
图 3 。所有 2 跨四个参与流程的所有集体操作
图 3 显示了 all2all 需要从每个进程到其他每个进程的通信。换句话说,在 N – GPU 集群中,作为 all2all 操作的一部分交换的消息数是$ O ( N ^{ 2 })$。
GPU 之间交换的消息是不同的,无法使用 树/环等算法(用于 allreduce ) 进行优化。当您在 GPU 的 100 秒内运行十亿个以上的参数模型时,消息的数量可能会触发拥塞、创建网络热点,并对性能产生不利影响。
如前所述, PXN 将 NVLink 和 PCI 通信结合起来,以减少通过第二层脊椎交换机的流量,并优化网络流量。它还通过将多达八条消息聚合为一条消息来提高消息速率。这两项改进都显著提高了所有 2 的性能。
所有 reduce 都基于 1:1 GPU:NIC 拓扑
PXN 解决的另一个问题是拓扑的情况,即每个 NIC 附近都有一个 GPU 。环形算法要求两个 GPU 靠近每个 NIC 。数据必须从网络传输到第一个 GPU ,通过 NVLink 绕过所有 GPU ,然后从最后一个 GPU 退出网络。第一个和最后一个 GPU 必须都靠近 NIC 。第一个 GPU 必须能够有效地从网络接收,最后一个 GPU 必须能够有效地通过网络发送。如果只有一个 GPU 靠近给定的 NIC ,则无法关闭环,必须通过 CPU 发送数据,这可能会严重影响性能。
有了 PXN ,只要最后一个 GPU 可以通过 NVLink 访问第一个 GPU ,它就可以将数据移动到第一个 GPU 。数据从那里发送到 NIC ,将所有传输保持在 PCI 交换机的本地。
这种情况不仅与每个 PCI 交换机具有一个 GPU 和一个 NIC 的 PCI 拓扑有关,而且当 NCCL 通信器仅包含 GPU 的子集时,也可能发生在其他拓扑上。考虑具有 nVLink 超立方体网格的 8x GPU 互连的节点。
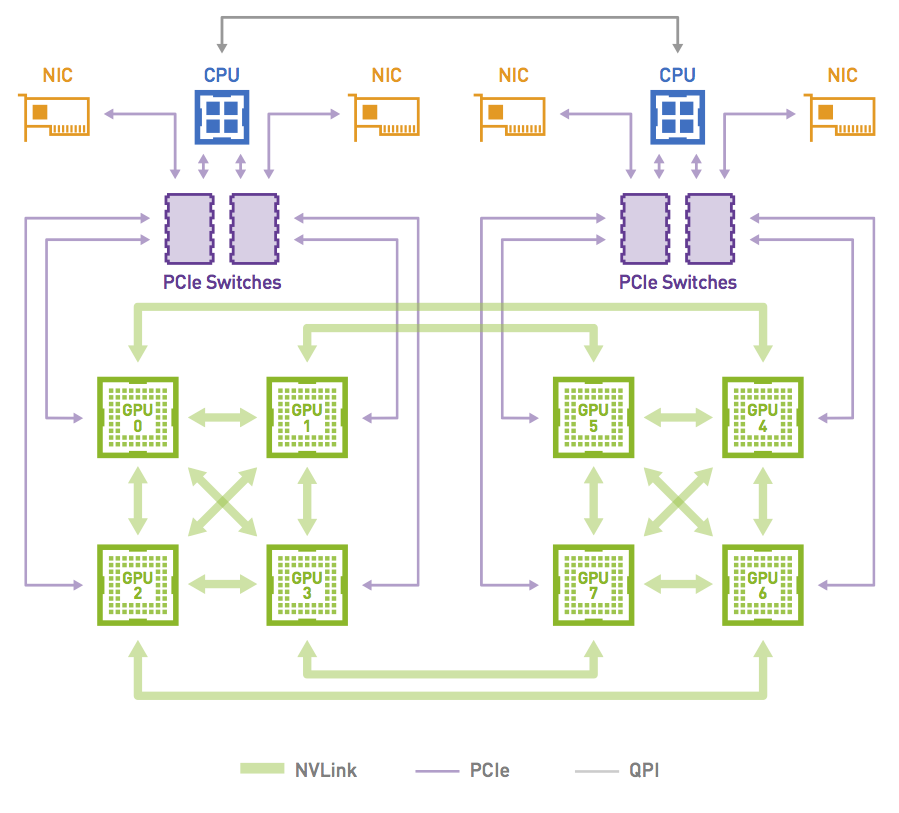
图 4 。 NVIDIA DGX-1 系统中的网络拓扑
图 5 显示了当通信器包括系统中的所有 8x GPU 时,利用拓扑中可用的高带宽 NVLink 连接可以形成的环。这是可能的,因为 GPU0 和 GPU1 共享对同一本地 NIC 的访问。
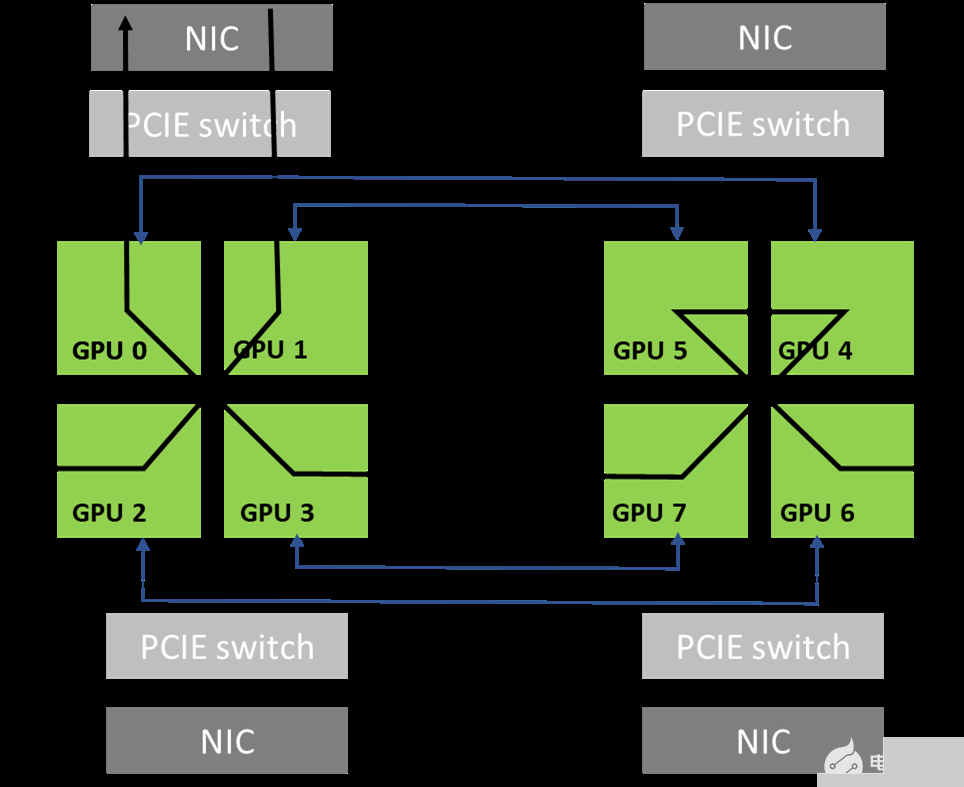
图 5 。 NCCL 使用的环形路径示例
通讯器只能包含 GPU 的一个子集。例如,它可以只包含 GPU 0 、 2 、 4 和 6 。在这种情况下,如果不穿过轨道,就不可能创建环:从 GPU 0 进入节点的环必须从 GPU 2 、 4 或 6 退出,这些环不能直接访问 GPU 0 ( NIC 0 和 1 )的本地 NIC 。
另一方面, PXN 允许形成环,因为 GPU 2 可以在通过 NIC 0 / 1 之前将数据移回 GPU 0 。
这种情况在模型并行性中很常见,具体取决于模型的拆分方式。例如,如果一个模型在 GPU 0-3 之间拆分,则另一个模型在 GPU 4-7 上运行。这意味着 GPU 0 和 4 负责模型的同一部分,并且在所有节点上创建了一个 NCCL 通信器,其中包含所有 GPU 0 和 4 ,以执行相应层的所有 reduce 操作。没有 PXN ,这些通讯器无法有效地执行所有 reduce 操作。
到目前为止,实现高效模型并行的唯一方法是在 GPU 0 , 2 , 4 , 6 和 1 , 3 , 5 , 7 上拆分模型,这样 NCCL 子通信程序将包括 GPU [0 , 1]、[2 , 3]、[4 , 5]和[6 , 7],而不是[0 , 4]、[1 , 5]、[2 , 6]和[3 , 7]。新的 PXN 特性为您提供了更大的灵活性,并简化了模型并行性的使用。
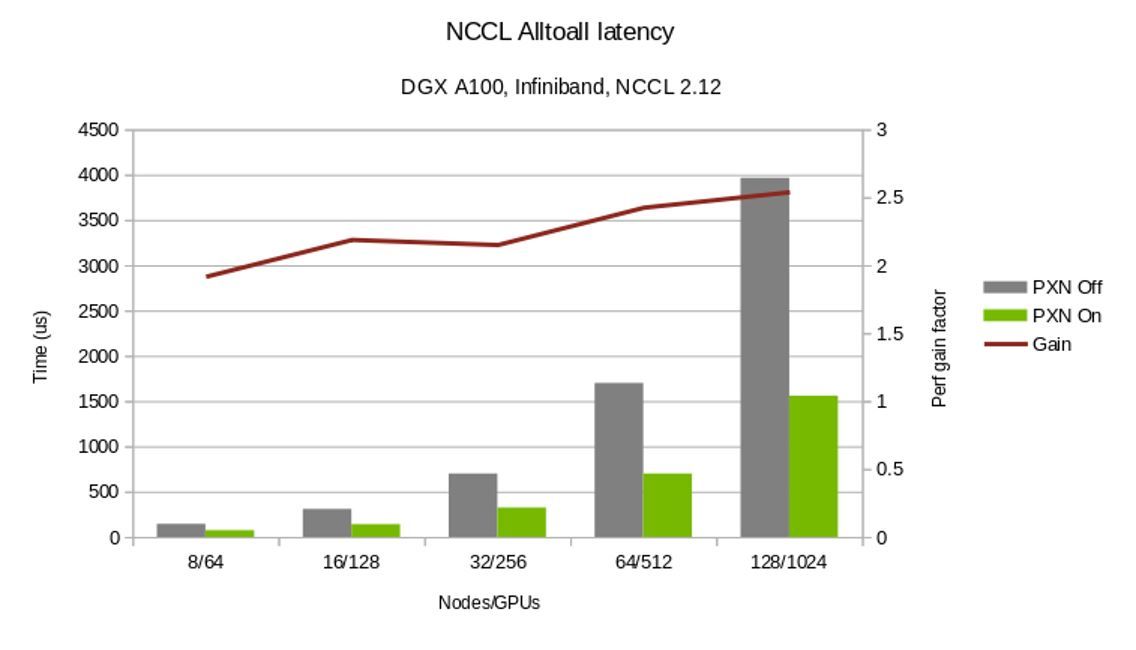
图 6 。 NCCL 2.12 PXN 性能改进
图 6 对比了在使用和不使用 PXN 的情况下完成所有集合操作的时间。此外, PXN 为所有 reduce 操作提供了更灵活的 GPU 选择。
总结
NCCL 2.12 版本显著提高了所有 2 所有通信集体性能。 Download 最新的 NCCL 版本,并亲身体验改进后的性能。
关于作者
Karthik Mandakolathur 是 NVIDIA Magnum IO 的产品经理,专注于加速分布式 AI 、数据分析和 HPC 应用。凭借 20 多年的行业经验, Karthik 曾在 Broadcom 和 Cisco 担任高级工程和产品职务。他在沃顿商学院获得工商管理硕士学位,在斯坦福大学获得工商管理硕士学位,在印度理工学院获得工商管理学士学位。他在高性能交换架构领域拥有多项美国专利。
Sylvain Jeaugey 是 NVIDIA 的高级软件工程师,自 2015 年创建 NCCL 库以来一直在开发该库。他在大规模分布式计算方面有 15 年的经验。他一直致力于各种 MPI 实现,开发和集成高速网络技术,并设计大型网络结构。
审核编辑:郭婷
-
gpu
+关注
关注
28文章
5270浏览量
136059 -
人工智能
+关注
关注
1820文章
50313浏览量
266865
发布评论请先 登录
华为拥抱AI WAN迈向All Intelligence新阶段
瞄准20W以内汽车小电机市场:英飞凌发布TLE9932与TLE9934 ALL-IN-ONE芯片

中兴通讯将携全栈AI创新成果亮相MWC 2026
IoT智能模块高速缓存核心IS61WV204816ALL-12B

全碳化硅 (All-SiC) 有源中点钳位 (ANPC) 拓扑解决方案研究报告

10 INCH-D-PRIME-MV Amphenol All Sensors 板机接口压力传感器 AXCXL 10 DN P
SeaVerse发布全球首个AI Native平台,“All in AI Native”引领AI创作前瞻革命
100 PSI-D-PRIME-MV-A6AAQ 板机接口压力传感器 Amphenol All Sensors
探索PROFET™ +2 12V客户评估套件:硬件设计与软件应用全解析
探索All Sensors EK - 02评估套件:简化传感器设计与测试流程
Amphenol All Sensors BFTM系列基础压力传感器:高精度与紧凑设计的完美结合
天合光能智慧光储解决方案亮相2025澳洲All Energy展会
studio编译过程中报错:syntax error: unexpected如何解决?
元能芯:用All-in-One芯片革新电机芯片市场




评论