 什么是HBM3 为什么HBM很重要
什么是HBM3 为什么HBM很重要

点击蓝字关注我们
从高性能计算到人工智能训练、游戏和汽车应用,对带宽的需求正在推动下一代高带宽内存的发展。
HBM3将带来2X的带宽和容量,除此之外还有其他一些好处。虽然它曾经被认为是一种“慢而宽”的内存技术,用于减少芯片外内存中的信号传输延迟,但现在HBM3正变得越来越快,越来越宽。在某些情况下,甚至被用于L4缓存。
Arm首席研究工程师Alejandro Rico表示:“这些新功能将使每传输位的焦耳效率达到更高水平,而且更多设计可以使用HBM3-only内存解决方案,不需要额外的片外存储。AI/ML、HPC和数据分析等应用可以利用大带宽来保持可扩展性。合理利用HBM3带宽需要一个具有高带宽片上网络和处理元素的处理器设计,通过提高内存级并行性来使数据速率最大化。”
人工智能训练芯片通常需要处理万亿字节的原始数据,而HBM3可以达到这个水平。Rambus的产品营销高级总监Frank Ferro指出:“用户在开发ASIC电路来更好地解决人工智能问题的同时,需要更多的带宽。
每个用户都试图想用一个更高效的处理器来实现他们特定的神经网络,并在实现时达到更好的内存利用率和CPU利用率。对于人工智能训练来说,HBM一直是最佳选择,因为它提供了更多带宽和更低功耗。虽然价格上有点贵,但对于这些应用程序来说(尤其是进入云计算的应用程序)还是负担得起的。HBM3实际上只是一种自然迁移。”

虽然JEDEC尚未公布未获批准的HBM3规范细节,但Rambus报告称其HBM3子系统带宽将增加到8.4 Gbps(HBM2e为3.6Gbps)。采用HBM3的产品预计将在2023年初发货。
“当芯片的关键性能指标是每瓦特内存带宽,或者HBM3是实现所需带宽的唯一途径时,采用HBM3是有益的,”Cadence的IP组总监Marc Greenberg表示:“与基于PCB的方法(如DDR5、LPDDR5/5X或GDDR6)相比,这种带宽和效率的代价是在系统中增加额外的硅,并可能增加制造/组装/库存成本。额外的硅通常是一个插入器,以及每个HBM3 DRAM堆栈下面的一个基模。”
为什么HBM很重要
自HBM首次宣布以来的十年里,已有2.5代标准进入市场。在此期间,创建、捕获、复制和消耗的数据量从2010年的2 ZB增加到2020年的64.2 ZB,据Statista预测,这一数字将在2025年增长近三倍,达到181 ZB。
Synopsys的高级产品营销经理Anika Malhotra表示:“2016年,HBM2将信令速率提高了一倍,达到2 Gbps,带宽达到256 GB/s。两年后,HBM2E出现了,实现了3.6 Gbps和460 GB/s的数据速率。性能需求在增加,高级工作负载对带宽的需求也在增加,因为更高的内存带宽是实现计算性能的关键因素。”
“除此之外,为了更快地处理所有这些数据,芯片设计也变得越来越复杂,通常需要专门的加速器、片内或封装内存储器及接口。HBM被视为将异构分布式处理推到一个完全不同水平的一种方式。”
“最初,高带宽内存只是被图形公司视为进化方向上的一步;但是后来网络和数据中心意识到HBM可以为内存结构带来更多的带宽。所有推动数据中心采用HBM的动力在于更低延迟、更快访问和更低功耗。”Malhotra说。“通常情况下,CPU为内存容量进行优化,而加速器和GPU为内存带宽进行优化。但是随着模型尺寸的指数增长,系统对容量和带宽的需求同时在增长(即不会因为增加容量后,对带宽需求降低)。我们看到更多的内存分层,包括支持对软件可见的HBM + DDR,以及使用HBM作为DDR的软件透明缓存。除了CPU和GPU, HBM也很受数据中心FPGA的欢迎。”
HBM最初的目的是替代GDDR等其他内存,由一些领先的半导体公司(特别是英伟达和AMD)推动。这些公司仍然在JEDEC工作组中大力推动其发展,英伟达是该工作组的主席,AMD是主要贡献者之一。
Synopsys产品营销经理Brett Murdock表示:“GPU目前有两种选择。一种是继续使用GDDR,这种在SoC周围会有大量的外设;另一种是使用HBM,可以让用户获得更多的带宽和更少的物理接口,但是整体成本相对更高。还有一点需要强调的是物理接口越少,功耗越低。所以使用GDDR非常耗电,而HBM非常节能。所以说到底,客户真正想问的是花钱的首要任务是什么?对于HBM3,已经开始让答案朝‘可能应该把钱花在HBM上’倾斜。”
尽管在最初推出时,HBM 2/2e仅面向AMD和Nvidia这两家公司,但现在它已经拥有了庞大的用户基础。当HBM3最终被JEDEC批准时,这种增长有望大幅扩大。
关键权衡
芯片制造商已经明确表示,当系统中有插入器时HBM3会更有意义,例如基于chiplet的设计已经使用了硅插入器。Greenberg表示:“在许多系统中还没有插入器的情况下,像GDDR6、LPDDR5/5X或DDR5这样的PCB内存解决方案可能比添加插入器来实现HBM3更具成本优势。”
然而,随着规模经济发挥作用,这些权衡可能不再是一个问题。Synopsys的Murdock表示,对于使用HBM3的用户来说,最大的考虑是管理PPA,因为与GDDR相比,在相同的带宽下,HBM设备的硅面积更小、功耗更低,需要处理的物理接口也更少。
“此外,与DDR、GDDR或LPDDR接口相比,IP端的HBM设备在SoC上的物理实现方法相当野蛮粗暴。对于一般物理接口,我们有很多方法去实现它:可以在模具的侧面放一个完整的线性PHY,可以绕过拐角,也可以把它折叠起来。但是对于HBM,当要放下一个HBM立体时,JEDEC已经准确地定义了这个立体上的bump map是什么样子的。用户将把它放在插入器上,它将紧挨着SoC,所以如何在SoC上构建bump map只有一个可行的选择。”
这些决策会影响可靠性。虽然在bump方面减少了灵活性,但增加的可预测性意味着更高的可靠性。
特别是在2.5D和3D带来的复杂性下,可以消除的变量越多越好。
Malhotra表示,在HBM3被广泛采用的AI/ML应用中,电源管理是最重要的考虑因素。“对于数据中心和边缘设备来说都是如此。权衡围绕着功耗、性能、面积和带宽。对于边缘计算,随着第四个变量(带宽)加入到传统的PPA方程中,复杂性正在不断增加。在AI/ML的处理器设计或加速器设计中,功耗、性能、面积、带宽的权衡很大程度上取决于工作负载的性质。”
如何确保正常工作?
虽然HBM3实现看起来足够简单,但由于这些内存通常用于关键任务应用程序,必须确保它们能够按预期工作。Rambus的产品营销工程师Joe Rodriguez表示,应该使用多个供应商提供的芯片调试和硬件启动工具,以确保整个内存子系统正常运行。
用户通常利用供应商提供的测试平台和模拟环境,这样他们就可以使用控制器开始运行模拟,看看系统在HBM 2e/3系统上的表现如何。
Rambus公司的Ferro表示:“在考虑整体系统效率时,HBM实现一直是一个挑战,因为面积太小。面积小是件好事,但现在系统有了CPU或GPU,可能有4个或更多HBM DRAM。这意味着热量、功耗、信号完整性、制造可靠性都是物理实现时必须解决的问题。”
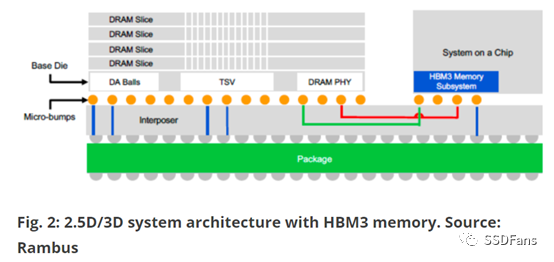
为了从插入器和封装设计中获得最优性能,即使在HBM2e,许多公司都努力通过插入器获得良好的信号完整性。更复杂的是,每个代工厂对于这些插入器都有不同的设计规则,有些规则比其他的更具挑战性。
结论
在可预见的未来,我们将继续实现更高内存带宽,即将到来的HBM3有望开启系统设计的一个新阶段,将系统性能提升到一个新的水平。
为了实现这一点,行业参与者必须继续解决数据密集型SoC的设计和验证需求,以及最先进协议(如HBM3)的验证解决方案。作为一个整体,这些解决方案应该结合在一起,以允许对协议和时序检查进行规范性验证,保证设计可以得到充分验证。
原文链接:
https://semiengineering.com/hbm3s-impact-on-chip-design/
编辑:jq
-
芯片
+关注
关注
462文章
53534浏览量
458981 -
soc
+关注
关注
38文章
4514浏览量
227588 -
人工智能
+关注
关注
1813文章
49734浏览量
261463 -
HBM
+关注
关注
2文章
426浏览量
15698 -
HBM3
+关注
关注
0文章
74浏览量
468
原文标题:HBM3来了!
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
GPU猛兽袭来!HBM4、AI服务器彻底引爆!
AI大算力的存储技术, HBM 4E转向定制化

半导体“HBM和3D Stacked Memory”技术的详解

HBM技术在CowoS封装中的应用
传英伟达自研HBM基础裸片
突破堆叠瓶颈:三星电子拟于16层HBM导入混合键合技术

SK海力士HBM技术的发展历史
Cadence推出HBM4 12.8Gbps IP内存系统解决方案
三星与英伟达高层会晤,商讨HBM3E供应
三星电子将供应改良版HBM3E芯片
AI兴起推动HBM需求激增,DRAM市场面临重塑
AEC-Q102之静电放电测试(HBM)

美光发布HBM4与HBM4E项目新进展
芯片静电测试之HBM与CDM详解





 工商网监
工商网监
评论