 存储与GPU性能皆已成倍增长,IO表现为何迟迟不见好转?
存储与GPU性能皆已成倍增长,IO表现为何迟迟不见好转?

存储与GPU性能皆已成倍增长,IO表现为何迟迟不见好转?
伴随着HPC、自动驾驶、深度学习和VR/AR需求的不断增加,IO性能也在逐步凸显瓶颈,尤其是GPU与存储之间的读写。处理器速度已经从KHz进化至了GHz,VRAM从KB进化至了GB,IO速度也从KB/s进化至了GB/s,然而GB/s的大幅度改善从直观角度来看依然像是MB/s。
比如在有线连接的VR应用中,图形需要经过电脑进行处理,再经有线传输显示在VR屏幕上,这就引发了高延迟和长读取时间等问题。这不禁让人开始遐想,在CPU、GPU和存储都已经革新换代的情况下,我们是否真正有效地应用了硬件性能?为此微软和英伟达都提出了直接存储的概念来改善IO的现状。
微软:Windows上的DirectStorage
微软在不久前的Windows 11发布会上重点提到了DirectStorage技术,这是一个最初为主机设计的DirectX API,如今微软也将把这一技术带到PC上。
在当前NVMe SSD和PCIe技术的演进下,存储带宽远超旧式的硬盘存储技术,过去10MB每秒的速度已经达到数GB每秒。但PC上的图形工作量也在逐步进化,数据量的增加对于读取提出了更高的要求。过去大量数据的读取只需要少量的IO请求,但如今的图形渲染会将材质等资源分成小块,只有在场景提出要求时载入所需的部分,如此一来虽然提高了效率,却引入了更多IO请求。

当前的GPU资源读取流程 / 微软
而目前的存储API并没有对大量IO请求作出优化,因此拖累了NVMe,使得读写瓶颈愈发明显。即便采用高端的PC硬件,也无法饱和利用存储带宽优势。除此之外,这些数据往往需要经过压缩传输下一个环节,传入内存后,还要CPU进行一部分解压工作,最后再传入GPU显存里,这样一来每个节点都存在效率损失。
而DirectStorage采用了全新的路径,从存储读取的数据传给内存后,直接传给GPU显存。而GPU对于这些数据的解压速度远快于CPU,所以极大地优化了IO性能。
英伟达:RTX IO和Magnum IO GPUDirect Storage
英伟达在RTX 30系列显卡上引入了RTX IO,面向消费市场,提升游戏场景下的读取速度。英伟达称RTX IO将与微软的DirectStorage结合,与传统硬盘下的存储API相比,可将IO性能提高百倍。过去需要数十个CPU内核的工作全部交由RTX GPU来处理。
值得一提的是,英伟达的RTX IO虽然也用到了微软的DirectStorage,但该技术并没有将数据传输到内存,而是直接由SSD转向GPU。微软一名图形开发者在GSL 2021大会上表示,未来DirectStorage的目标也是绕过系统内存。
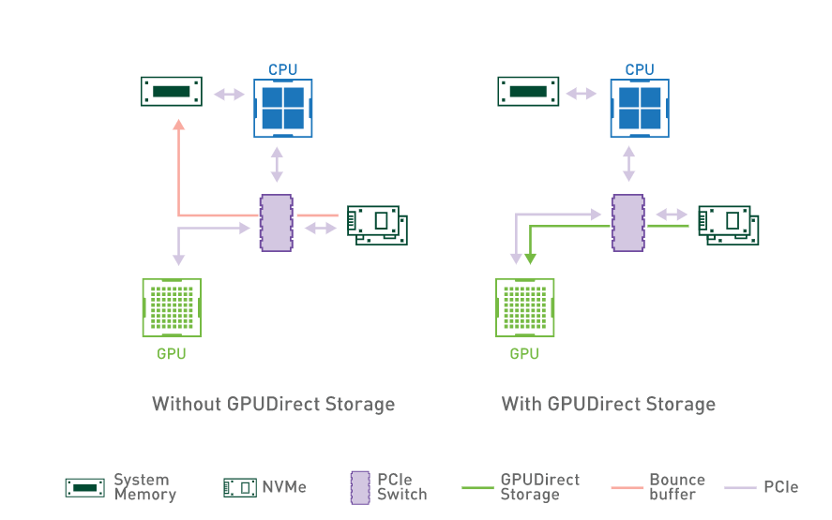
GDS技术 / 英伟达
除了消费市场外,英伟达在HPC市场也推出了对应的直接存储技术,Magnum IO GPUDirect Storage(GDS)。GDS技术同样是一个绕过CPU的技术,与消费级GPU不同,HPC场景下往往要用到多块GPU,如此一来受IO延迟和CPU的影响更大。GDS在本地存储与GPU显存之间建立直接的数据通道,消除了CPU引入的延迟和读写瓶颈。
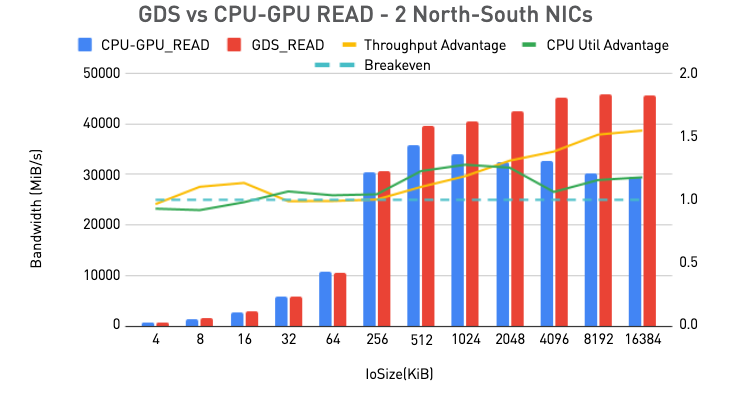
GDS与CPU传输至GPU读取性能对比 / 英伟达
在运用GDS后,带宽提升达到1.5倍,与传统CPU回弹缓冲的数据路径相比,CPU利用率也有2.8倍的提升。
目前英伟达已经将这一技术加入到其HGX AI超算中,DDN、VAST和WEKA三家公司已经开始了相关产品的量产,而IBM、美光等五家厂商也在积极引入这一技术。三星、铠侠、西数和戴尔等厂商也开始了GDS的早期集成与认证计划。
小结
直接存储技术进一步放大了GPU厂商与存储厂商的优势,目前HPC市场前景巨大,英伟达在相关业务上的盈利已经让其看到了商机。不仅是GPU,英伟达采用Arm架构的Grace CPU同样引入了NVLink这样的数据传输改善方案。在这样的性能改善下,即便存储方案不同,英伟达的GPU也很可能成为HPC应用的首选。
伴随着HPC、自动驾驶、深度学习和VR/AR需求的不断增加,IO性能也在逐步凸显瓶颈,尤其是GPU与存储之间的读写。处理器速度已经从KHz进化至了GHz,VRAM从KB进化至了GB,IO速度也从KB/s进化至了GB/s,然而GB/s的大幅度改善从直观角度来看依然像是MB/s。
比如在有线连接的VR应用中,图形需要经过电脑进行处理,再经有线传输显示在VR屏幕上,这就引发了高延迟和长读取时间等问题。这不禁让人开始遐想,在CPU、GPU和存储都已经革新换代的情况下,我们是否真正有效地应用了硬件性能?为此微软和英伟达都提出了直接存储的概念来改善IO的现状。
微软:Windows上的DirectStorage
微软在不久前的Windows 11发布会上重点提到了DirectStorage技术,这是一个最初为主机设计的DirectX API,如今微软也将把这一技术带到PC上。
在当前NVMe SSD和PCIe技术的演进下,存储带宽远超旧式的硬盘存储技术,过去10MB每秒的速度已经达到数GB每秒。但PC上的图形工作量也在逐步进化,数据量的增加对于读取提出了更高的要求。过去大量数据的读取只需要少量的IO请求,但如今的图形渲染会将材质等资源分成小块,只有在场景提出要求时载入所需的部分,如此一来虽然提高了效率,却引入了更多IO请求。
当前的GPU资源读取流程 / 微软
而目前的存储API并没有对大量IO请求作出优化,因此拖累了NVMe,使得读写瓶颈愈发明显。即便采用高端的PC硬件,也无法饱和利用存储带宽优势。除此之外,这些数据往往需要经过压缩传输下一个环节,传入内存后,还要CPU进行一部分解压工作,最后再传入GPU显存里,这样一来每个节点都存在效率损失。
而DirectStorage采用了全新的路径,从存储读取的数据传给内存后,直接传给GPU显存。而GPU对于这些数据的解压速度远快于CPU,所以极大地优化了IO性能。
英伟达:RTX IO和Magnum IO GPUDirect Storage
英伟达在RTX 30系列显卡上引入了RTX IO,面向消费市场,提升游戏场景下的读取速度。英伟达称RTX IO将与微软的DirectStorage结合,与传统硬盘下的存储API相比,可将IO性能提高百倍。过去需要数十个CPU内核的工作全部交由RTX GPU来处理。
值得一提的是,英伟达的RTX IO虽然也用到了微软的DirectStorage,但该技术并没有将数据传输到内存,而是直接由SSD转向GPU。微软一名图形开发者在GSL 2021大会上表示,未来DirectStorage的目标也是绕过系统内存。
GDS技术 / 英伟达
除了消费市场外,英伟达在HPC市场也推出了对应的直接存储技术,Magnum IO GPUDirect Storage(GDS)。GDS技术同样是一个绕过CPU的技术,与消费级GPU不同,HPC场景下往往要用到多块GPU,如此一来受IO延迟和CPU的影响更大。GDS在本地存储与GPU显存之间建立直接的数据通道,消除了CPU引入的延迟和读写瓶颈。
GDS与CPU传输至GPU读取性能对比 / 英伟达
在运用GDS后,带宽提升达到1.5倍,与传统CPU回弹缓冲的数据路径相比,CPU利用率也有2.8倍的提升。
目前英伟达已经将这一技术加入到其HGX AI超算中,DDN、VAST和WEKA三家公司已经开始了相关产品的量产,而IBM、美光等五家厂商也在积极引入这一技术。三星、铠侠、西数和戴尔等厂商也开始了GDS的早期集成与认证计划。
小结
直接存储技术进一步放大了GPU厂商与存储厂商的优势,目前HPC市场前景巨大,英伟达在相关业务上的盈利已经让其看到了商机。不仅是GPU,英伟达采用Arm架构的Grace CPU同样引入了NVLink这样的数据传输改善方案。在这样的性能改善下,即便存储方案不同,英伟达的GPU也很可能成为HPC应用的首选。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
微软
+关注
关注
4文章
6764浏览量
108161 -
gpu
+关注
关注
28文章
5323浏览量
136213 -
HPC
+关注
关注
0文章
351浏览量
25107 -
英伟达
+关注
关注
23文章
4128浏览量
99778
发布评论请先 登录
相关推荐
热点推荐
HMC814:高性能GaAs MMIC x2有源频率倍增器
HMC814:高性能GaAs MMIC x2有源频率倍增器 在电子工程领域,频率倍增器是实现特定频率信号生成和处理的关键元件。今天要给大家介绍的 HMC814,是一款采用 GaAs PHEMT 技术
探索HMC576:GaAs MMIC x2有源频率倍增器的卓越性能与应用
18 - 29 GHz。它在多种应用场景中表现出色,是一款性能卓越的频率倍增器。 (一)典型应用场景 时钟生成应用 :适用于
HMC370LP4 / 370LP4E:高性能SMT GaAs HBT MMIC x4有源频率倍增器
HMC370LP4 / 370LP4E:高性能SMT GaAs HBT MMIC x4有源频率倍增器 在电子工程领域,频率倍增器是实现特定频率输出的关键组件。今天,我们来深入了解HMC370LP4
亮相车百会|经纬恒润总裁兼CTO范成建:以系统创新抢占智能底盘战略高地
的最新实践。“汽车是带轮子的具身智能机器人。除了大脑,它一定要有比较好的小脑。”范成建以一个生动的比喻开场:人从婴儿到成年,手脚尺寸成倍增长,小脑却能始终精准适应并控制

基于openEuler平台的CPU、GPU与FPGA异构加速实战
随着 AI、视频处理、加密和高性能计算需求的增长,单一 CPU 已无法满足低延迟、高吞吐量的计算需求。openEuler 作为面向企业和云端的开源操作系统,在 多样算力支持 方面表现出色,能够高效调度 CPU、

MAX17409:高性能GPU的电源控制利器
MAX17409:高性能GPU的电源控制利器 在今日的高性能图形处理器(GPU)应用领域,对于高效、稳定且响应迅速的电源控制的需求日益增长。
NVIDIA RTX PRO 4000 Blackwell GPU性能测试
Generation 的全面超越。那么,这款划时代的专业 GPU 在真实应用场景中的表现究竟如何?今天,我们将通过深度实测,为您揭晓 NVIDIA RTX PRO 4000 Blackwell 相较于前代产品的性能跃迁。

康耐视机器视觉解决方案助力IMA E-COMMERCE提升电商订单包装
在电商日订单量成倍增长的今天,包装不再是简单的“装箱”环节,而是履约效率、运输成本与用户体验的三重竞技场。对于IMA E-COMMERCE而言,挑战不仅来自包装尺寸不精准导致的运输浪费,更来自人工
高性能网络存储设计:NVMe-oF IP的实现探讨
。
该机制能够根据 IO 类型、SSD 当前队列深度、任务并行度动态选择最优NVMe传输队列,避免队列热点(Queue Hotspot)与长尾延迟,有效提升NVMe层吞吐能力与指令并行度。在多流场景下
发表于 12-19 18:45
福田欧辉客车销量实现翻倍增长的核心密码
2025年中国大中客市场竞争白热化,福田欧辉客车凭借一份震撼行业的成绩单强势突围:10月单月销量同比暴涨179%,新能源车型增长289%,出口增长158%,前10月销量持续领跑细分赛道,全年销量剑指1.1万辆,实现翻倍增长。这
全球前四!京东云云海AI存储跻身IO500高性能存储榜单
存储技术,云海AI存储不采用 PMEM 硬件,具备更强通用性的同时也实现了更低存储成本。 IO500是全球高性能计算HPC领域最权威、最具影

如何实现高效的RoCE网卡状态采集与监控?
当下大规模AI训练成为常态,RoCEv2凭借高性能、低延迟与低CPU开销的优势,已成为构建智算中心的优先选择。然而,RoCE对网络无损的严苛要求,配置不当会放大拥塞,如 PFC、ECN、Buffer滞留等引发的高延迟、性能下降等
霄云科技银河存储:重构AI时代的存储新范式
在人工智能与高性能计算需求呈指数级增长的今天,数据存储的效率与可靠性已成为算力释放的关键支撑。上海霄云信息科技有限公司正式推出全新一代AI存储
芯朋微电子PN7885系列60A超大电流E-Fuse介绍
随着人工智能(AI)浪潮的到来,数据中心迎来前所未有的变革。服务器的功率需求激增,超高的功率对供电系统的需求成倍增长,板上电源越来越多。防止输入端涌入的电流使系统过载变得至关重要,否则高昂的停机成本变得不可接受!

【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理
前言
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」书中的芯片知识是比较接近当前的顶尖芯片水平的,同时包含了芯片架构的基础知识,但该部分知识比较晦涩难懂,或许是由于我一直从事的事芯片
发表于 06-18 19:31



评论