 深度解读对残差网络动机的理解
深度解读对残差网络动机的理解

神经网络以其强大的非线性表达能力而获得人们的青睐,但是将网络层数加深的过程中却遇到了很多困难,随着批量正则化,ReLU 系列激活函数等手段的引入,在多层反向传播过程中产生的梯度消失和梯度爆炸问题也得到了很大程度的解决。然而即便如此,随着网络层数的增加导致的拟合能力退化现象依然存在,如下图所示
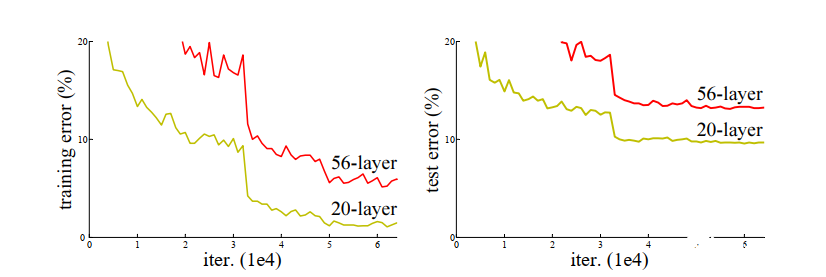
可以看到,训练误差和测试误差都随网络层数的增加而增加,可以排除过拟合造成的预测性能退化。所以这里存在一个逻辑上讲不通的问题,通常来说,我们认为神经网络可以学习出任意形状的函数,具体到这个问题上来,假如浅层网络可以获得一个不错的效果,那么理论上深层网络增加的额外层只需要学会恒等映射,即可获得与浅层网络相同的预测精度
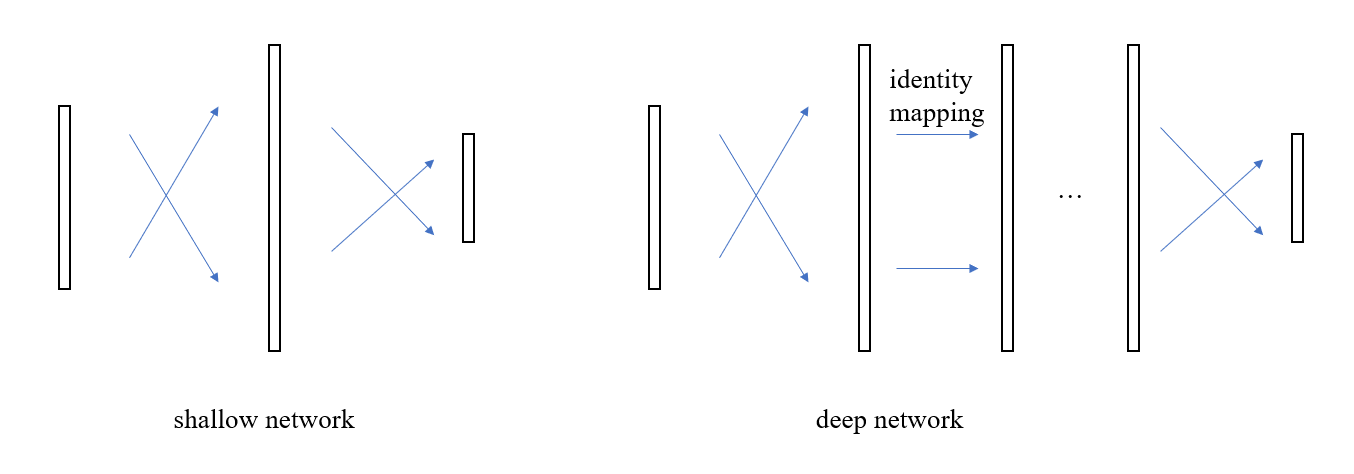
但实际情况根本不是这么回事儿,那么问题出在哪儿了呢?我们一厢情愿的认为中间层能够学会恒等映射,但事与愿违,这一假设不成立,也就是说,具有很强的非线性拟合能力的传统神经元结构却连最简单的恒等映射都模拟不了,抓住这一要点后,新的优化方向便映入眼帘了,既然这种交叉连接的神经元无法实现恒等映射,那么再增加一路恒等映射的连接不就行了
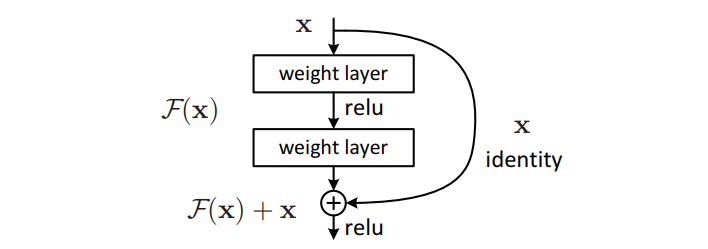
这样一来,假如两层之间的恒等映射是最优解,就像之前提到的那种情况,那么只需要权重层,即图中的 weight layer,学会把所有的权重都设为 0 就行了,而这种学习任务是很简单的。
所以可以总结道,resnet 的提出是因为发现了普通的神经网络连接方式无法实现有效的恒等映射,于是额外增加了一路恒等连接层来辅助学习。体现在最终效果上就是说普通神经网络的连接方式更容易学习到残差,所以这种方式就被称为残差学习。
编辑:jq
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
神经网络
+关注
关注
42文章
4847浏览量
108442 -
函数
+关注
关注
3文章
4423浏览量
68098
发布评论请先 登录
相关推荐
热点推荐
半导体UV贴膜与解胶全流程深度复盘:如何实现0.11%以下残胶率
半导体UV贴膜与解胶全流程深度复盘:如何实现0.11%以下残胶率? 摘要 本研究旨在深入剖析半导体UV贴膜与解胶全流程,以实现0.11%以下的超低残胶率。通过系统研究晶圆表面清洁、表面处理、UV贴膜
瑞芯微(EASY EAI)RV1126B resnet50训练部署教程
层堆叠得到的,但当网络堆叠到一定深度时,就会出现退化问题。残差网络的特点是容易优化,并且能够通过增加相当的

零基础手写大模型资料2026
行代码,大模型的开发是理论创新与工程实践的深度融合。即使不依赖复杂框架,掌握注意力机制、残差连接等核心原理的开发者,也能通过基础代码实现模型原型,进而理解LoRA微调、量化压缩等高级技
发表于 05-01 17:44
人工智能-Python深度学习进阶与应用技术:工程师高培解读
深度学习进阶的技术路线图,来分析解读一下从基础原理到前沿应用的多个关键节点。一、从基础到进阶:构建深度学习的完整认知深度学习的起点,是对神经网络

千兆以太网低残压大电流方案参考
(8/20μs) 。
网络变压器特点:小体积, 低高度。匝数比1:1;开路电感 : 350 uH ;插入损耗: -1.1 dB Max,直流电阻1.3Ω。
1.初级侧接线:
•差分对连接:网络变压器
发表于 03-16 16:14
TFT-LCD残影问题分析及激光修复方法
一、引言 残影是TFT-LCD液晶显示屏常见的显示异常问题,表现为屏幕长期显示固定图像后,切换画面时残留原图像轮廓,无法快速消退。该问题本质是液晶分子取向异常或相关驱动结构功能失衡,不仅严重影响用户

Transformer 入门:从零理解 AI 大模型的核心原理
为什么需要残差?
arduino
体验AI代码助手
代码解读
复制代码
问题:深度网络的\"梯度消失\"
想象传话游戏:
第1个人
发表于 02-10 16:33
LT1994:高性能全差分输入/输出放大器的深度剖析
LT1994:高性能全差分输入/输出放大器的深度剖析 在电子设计领域,放大器作为信号处理的关键组件,其性能的优劣对整个系统的表现起着至关重要的作用。今天,我们将深入探讨Linear
Amphenol FlexTraX:创新电缆管理解决方案深度剖析
Amphenol FlexTraX:创新电缆管理解决方案深度剖析 在电子设备和网络系统中,电缆管理一直是一个关键且具有挑战性的任务。合理的电缆管理不仅能提高系统的可靠性和可维护性,还能提升整体的美观
如何在机器视觉中部署深度学习神经网络
图 1:基于深度学习的目标检测可定位已训练的目标类别,并通过矩形框(边界框)对其进行标识。 在讨论人工智能(AI)或深度学习时,经常会出现“神经网络”、“黑箱”、“标注”等术语。这些概念对非专业

基于瑞芯微RK3576的resnet50训练部署教程
堆叠得到的,但当网络堆叠到一定深度时,就会出现退化问题。残差网络的特点是容易优化,并且能够通过增加相当的

TFT液晶显示屏为什么会显示残影、如何解决
TFT液晶屏(Thin-Film Transistor Liquid Crystal Display)显示残影(也称为图像残留)是一个涉及物理和电子原理的现象。
一、为什么工业TFT液晶屏会出现残影
发表于 09-08 09:04
轮式移动机器人电机驱动系统的研究与开发
【摘 要】以嵌入式运动控制体系为基础,以移动机器人为研究对象,结合三轮结构轮式移动机器人,对二轮差速驱动转向自主移动机器人运动学和动力学空间模型进行了分析和计算,研究和设计了自主移
发表于 06-11 14:30
革命性神经形态微控制器 **Pulsar** 的深度技术解读
以下是对荷兰公司Innatera推出的革命性神经形态微控制器 Pulsar 的深度技术解读,结合其架构设计、性能突破、应用场景及产业意义进行综合分析: 一、核心技术原理:神经形态架构的突破
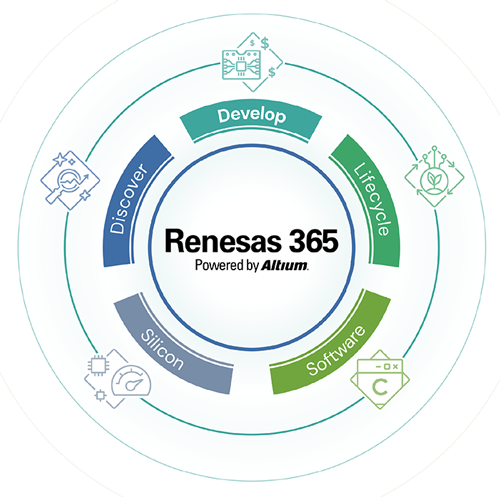
瑞萨365 深度解读
技术架构、核心功能、行业影响及未来展望四个维度进行深度解读: 一、技术架构:融合硬件与设计软件的跨领域协作平台 瑞萨365基于Altium 365云平台构建,整合了瑞萨的半导体产品组合与Altium的设计工具链,形成从芯片选型到系统部署的全流程数字环境。其核心架构围绕 五



评论