 英伟达发布基于Ampere架构的GPUA100
英伟达发布基于Ampere架构的GPUA100

据该公司CEO黄仁勋介绍,A100采用台积电当时最先进的7纳米工艺打造,拥有540亿个晶体管,面积高达826mm2,GPU的最大功率也达到了400W。又因为同时搭载了三星HBM2显存、第三代TensorCore和带宽高达600GB/s的新版NVLink,英伟达的A100在多个应用领域也展现出强悍的性能。
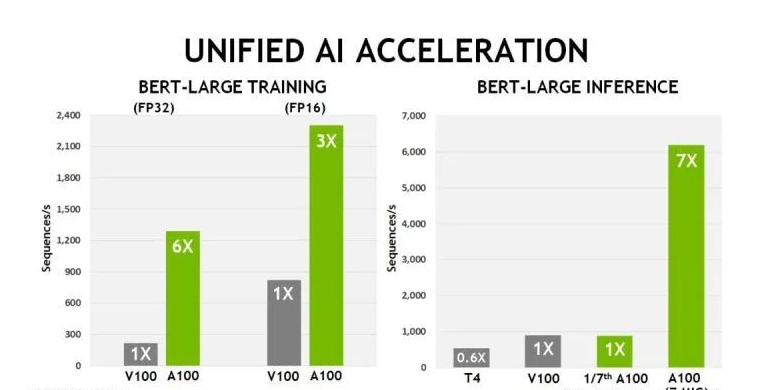
从英伟达提供的数据可以看到,如果用PyTorch框架跑AI模型,相比上一代V100芯片,A100在BERT模型的训练上性能提升6倍,BERT推断时性能提升7倍。而根据MLPerf组织在十月底发布的最新推理基准测试(Benchmark)MLPerfInferencev0.7结果,英伟达A100TensorCoreGPU在云端推理的基准测试性能是最先进英特尔CPU的237倍。
但英伟达不止步于此。在昨日,他们发布了面向AI超级计算的全球最强GPU——A10080GB;与此同时,他们还带来了一体式AI数据中心NVIDIADGXStationA100以及NVIDIAMellanox400GInfiniBand产品。
全球最强的AI超算GPU
据英伟达方面介绍,公司全新的A10080GBGPU的最大特点在于采用了HBM2E内存技术,能将A10040GBGPU的高带宽内存增加一倍至80GB,这样的设计也让英伟达成为业内首个实现了2TB/s以上的内存带宽的企业。
“若想获得HPC和AI的最新研究成果,则需要构建最大的模型,而这需要比以往更大的内存容量和更高的带宽。A10080GBGPU所提供的内存是六个月前推出的前代产品的两倍,突破了每秒2TB的限制,使研究人员可以应对全球科学及大数据方面最严峻的挑战。”NVIDIA应用深度学习研究副总裁BryanCatanzaro表示。
此外,第三代TensorCore核心、MIG技术、结构化稀疏以及第三代NVLink和NVSwitch,也是全新GPU能够获得市场认可的保证。
从英伟达提供的资料我们可以看到,该公司的第三代TensorCore核心通过全新TF32,能将上一代Volta架构的AI吞吐量提高多达20倍;通过FP64,新核心更是能将HPC性能提高多达2.5倍;而通过INT8,新核心也可以将AI推理性能提高多达20倍,并且支持BF16数据格式。
MIG技术则能将单个独立实例的内存增加一倍,并可最多提供七个MIG,让每个实例具备10GB内存。英伟达方面表示,该技术是一种安全的硬件隔离方法,在处理各类较小的工作负载时,可实现GPU最佳利用率。例如在如RNN-T等自动语言识别模型的AI推理上,单个A10080GBMIG实例可处理更大规模的批量数据,将生产中的推理吞吐量提高1.25倍。
至于结构化稀疏,则可以将推理稀疏模型的速度提高2倍;包括第三代NVLink和NVSwitch在内的新一代互连技术,则可使GPU之间的带宽增加至原来的两倍,将数据密集型工作负载的GPU数据传输速度提高至每秒600gigabytes。
除了性能提升以外,基于A10040GB的多样化功能设计的A10080GBGPU也成为需要大量数据存储空间的各类应用的理想选择。
以DLRM等推荐系统模型为例,他们为AI训练提供了涵盖数十亿用户和产品信息的海量表单。但A10080GB可实现高达3倍加速,使企业可以重新快速训练这些模型,从而提供更加精确的推荐;在TB级零售大数据分析基准上,A10080GB将其性能提高了2倍,使其成为可对最大规模数据集进行快速分析的理想平台;对于科学应用,A10080GB可为天气预报和量子化学等领域提供巨大的加速。
“作为NVIDIAHGXAI超级计算平台的关键组件,A10080GB还可训练如GPT-2这样的、具有更多参数的最大模型。”英伟达方面强调。
下一代400GInfiniBand
在发布A10080GB的同时,英伟达还带了下一代的400GInfiniBand产品。在讲述英伟达的新品之前,我们有必要先了解一下什么是InfiniBand。
所谓InfiniBand,是一种网络通信协议,它提供了一种基于交换的架构,由处理器节点之间、处理器节点和输入/输出节点(如磁盘或存储)之间的点对点双向串行链路构成。每个链路都有一个连接到链路两端的设备,这样在每个链路两端控制传输(发送和接收)的特性就被很好地定义和控制。而早前被英伟达收购的Mellanox则是这个领域的专家。
资料显示,Mellanox为服务器,存储和超融合基础设施提供包括以太网交换机,芯片和InfiniBand智能互连解决方案在内的大量的数据中心产品,其中,更以InfiniBand互连,是这些产品中重中之重。
据英伟达介绍,公司推出的第七代MellanoxInfiniBandNDR400Gb/s上带来了更低的延迟,与上一代产品相比,新的产品更是实现了数据吞吐量的翻倍。又因为英伟达为这个新品带来了网络计算引擎,这就让其能够获得额外的加速。
英伟达进一步指出,作为一个面向AI超级计算的业界最强大的网络解决方案,MellanoxNDR400GInfiniBand交换机,可提供3倍的端口密度和32倍的AI加速能力。此外,它还将框式交换机系统的聚合双向吞吐量提高了5倍,达到1.64petabits/s,从而使用户能够以更少的交换机,运行更大的工作负载。
“基于MellanoxInfiniBand架构的边缘交换机的双向总吞吐量可达51.2Tb/s,实现了具有里程碑意义的每秒超过665亿数据包的处理能力。”英伟达方面强调。而通过提供全球唯一的完全硬件卸载和网络计算平台,NVIDIAMellanox400GInfiniBand实现了大幅的性能飞跃,可加快相关研究工作的进展。
“我们的AI客户的最重要的工作就是处理日益复杂的应用程序,这需要更快速、更智能、更具扩展性的网络。NVIDIAMellanox400GInfiniBand的海量吞吐量和智能加速引擎使HPC、AI和超大规模云基础设施能够以更低的成本和复杂性,实现无与伦比的性能。”NVIDIA网络高级副总裁GiladShainer表示。
从他们提供的数据我们可以看到,包括Atos、戴尔科技、富士通、浪潮、联想和SuperMicro等公司在内的全球领先的基础设施制造商,计划将Mellanox400GInfiniBand解决方案集成到他们的企业级产品中去。此外,包括DDN、IBMStorage以及其它存储厂商在内的领先的存储基础设施合作伙伴也将支持NDR。
全球唯一的千兆级工作组服务器
为了应对不同开发者对AI系统的需求,在推出芯片和连接解决方案的同时,英伟达在2017年还推出一体式的AI数据中心NVIDIADGXStation。作为世界上首款面向AI开发前沿的个人超级计算机,开发者只需要对其执行简单的设置,就可以用Caffe、TensorFlow等去做深度学习训练、高精度图像渲染和科学计算等传统HPC应用,避免了装驱动和配置环境等麻烦,这很适合高校、研究所、以及IT力量相对薄弱的企业。
昨日,英伟达今日发布了全球唯一的千兆级工作组服务器NVIDIADGXStationA100。作为开创性的第二代人工智能系统,DGXStationA100加速满足位于全球各地的公司办公室、研究机构、实验室或家庭办公室中办公的团队对于机器学习和数据科学工作负载的强烈需求。而为了支持诸如BERTLarge推理等复杂的对话式AI模型,DGXStationA100比上一代DGXStation提速4倍以上。对于BERTLargeAI训练,其性能更是提高近3倍。
从性能来看,英伟达方面表示,DGXStationA100的AI性能可达2.5petaflops,是唯一一台配备四个通过NVIDIANVLink完全互连的全新NVIDIAA100TensorCoreGPU的工作组服务器,可提供高达320GB的GPU内存,能够助力企业级数据科学和AI领域以最速度取得突破。
作为唯一支持NVIDIA多实例GPU(MIG)技术的工作组服务器,单一的DGXStationA100最多可提供28个独立GPU实例以运行并行任务,并可在不影响系统性能的前提下支持多用户。
为了支持更大规模的数据中心工作负载,DGXA100系统还将配备全新NVIDIAA10080GBGPU使每个DGXA100系统的GPU内存容量增加一倍(最高可达640GB),从而确保AI团队能够使用更大规模的数据集和模型来提高准确性。
“全新DGXA100640GB系统也将集成到企业版NVIDIADGXSuperPODTM解决方案,使机构能基于以20个DGXA100系统为单位的一站式AI超级计算机,实现大规模AI模型的构建、训练和部署。”英伟达方面强调。
该公司副总裁兼DGX系统总经理CharlieBoyle则表示:“DGXStationA100将AI从数据中心引入可以在任何地方接入的服务器级系统。数据科学和AI研究团队可以使用与NVIDIADGXA100系统相同的软件堆栈加速他们的工作,使其能够轻松地从开发走向部署。”
从英伟达提供的资料我们可以看到,配备A10080GBGPU的NVIDIADGXSuperPOD系统将率先安装于英国的Cambridge-1超级计算机,以加速推进医疗保健领域研究,以及佛罗里达大学的全新HiPerGatorAI超级计算机,该超级计算机将赋力这一“阳光之州”开展AI赋能的科学发现。
在今年发布的第二季财报上,英伟达数据中心业务首超游戏,成为公司营收最大的业务板块。从营收增长上看,与去年同期相比,英伟达数据中心业务业务大幅增长167%,由此可以看到英伟达在这个市场影响力的提升以及公司对这个市场的信心。
考虑到公司深厚的技术积累和过去几年收购所做的“查漏补缺”,英伟达必将成为Intel在数据中心的最强劲挑战者。
责任编辑人:CC
-
英伟达
+关注
关注
23文章
4130浏览量
99839 -
Ampere
+关注
关注
1文章
81浏览量
4930
发布评论请先 登录
英伟达算力中心电源架构的变革性演进与国产生态应用研究报告

施耐德电气与英伟达深化合作以构建高效吉瓦级AI工厂
新思科技与英伟达多项硬核科技成果亮相GTC 2026
从英伟达电话会看Agentic AI推理与FPGA价值

英伟达Rubin平台引入微通道冷板技术,100%全液冷设计


英伟达重磅出手!AI 推理存储全面觉醒

黄仁勋:英伟达AI芯片订单排到2026年 英伟达上季营收加速增长62%再超预期
NVIDIA新闻:英伟达10亿美元入股诺基亚 英伟达推出全新量子设备
英伟达发布 NVQLink 开放系统架构;国内首个汽车芯片标准验证平台投入使用
纳微半导体助力英伟达打造800 VDC电源架构
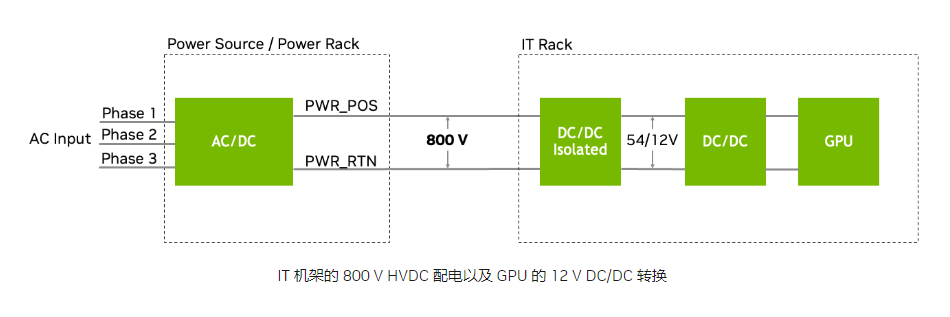
英伟达加速800V HVDC架构落地,三家本土企业打入供应链!



评论