 for竟然有那么多种用法!
for竟然有那么多种用法!

【说在前面的话】
通过本系列前面两篇文章的学习,我们掌握了宏的基本语法和使用规则,讽刺的是这些所谓的“基本语法和规则”却恰恰是正规C语言教育中所缺失的。本文的内容将建立在前面构筑的基础之上,以for功能的挖掘和封装为契机,手把手的教会你如何正确使用宏来简化日常开发,增强C语言的可读性、降低应用开发的难度、同时还尽可能避免宏对日常代码调试带来的负面影响。
【被低估的价值】
想必大家对C语言中的 for 循环结构并不陌生。根据C/C++语法网站cppreference.com 的介绍,for 的语法结构如下:
for ( init_clause ; cond_expression ; iteration_expression ) loop_statement
这里,我并不想假设大家对 for 结构一无所知,并介绍一堆教科书上已有的内容。然而,在 for 的语法结构中有几个大家容易忽视的地方,而它们恰恰是本文后续各种“展开”的基础:
for 循环中的 cond_expression 和 interation_expression 都必须是表达式,而不能是直接的语句。
for 循环中第一个部分 init_clause 一开始是用来放置给变量赋值的表达式;但从ANSI-C99开始,init_clause 可以被用来建立局部变量;而局部变量的生命周期覆盖且仅覆盖整个for循环——这一点非常有利用价值,也是大家容易忽略的地方。
为了说明这一点,我们不妨举几个例子。首先在C99标准之前,如果你要在 for 循环中使用一个循环变量,你只能在进入 for 之前将其定义好:
int i = 0;。..for (i = 0; i 《 100; i++) { 。..}
如你所见,虽然我们可以在 init_clause 的位置对变量赋值,但它并不是必须的——多少一点鸡肋是不是?也许更鸡肋的是,你可以在 init_clause 这里完成更多的赋值操作,比如:
int i = 0, j,k;。..for (i = 0, j = 100, k = 1; i 《 100; i++) { 。..}
实际上,明眼人都可以看出,init_clause 中所作的事情完全可以放置到 for 循环之前去完成,还可以避免“使用逗号进行分隔” 这样让人不那么习惯的使用方式。也许是意识到这一点,C99允许在 init_clause 里定义局部变量,而正是这一点,完全改变了 for 的命运(关于这一点,我们将在随后的内容中详细介绍)。现在,上述代码可以等效的改写为:
for (int i = 0, j = 100, k = 1; i 《 100; i++) { 。..}
需要强调的是,这里仍然有一个小小的限制,即:init_clause 里虽然可以定义局部变量,但这些变量只能是同一类型的,或者是指向这一类型的指针。因此下面的写法是非法的:
for (int i = 0, short j = 100; i 《 100; i++) { 。..}
而这样的写法是合法的:
for (int i = 0, *p = NULL; i 《 100; i++) { 。..}
请大家务必留意这里的语法细节,我们将在后面的封装中大规模使用。
另外一个值得注意的是 for 的执行顺序,它可以用下面的流程图来表示:
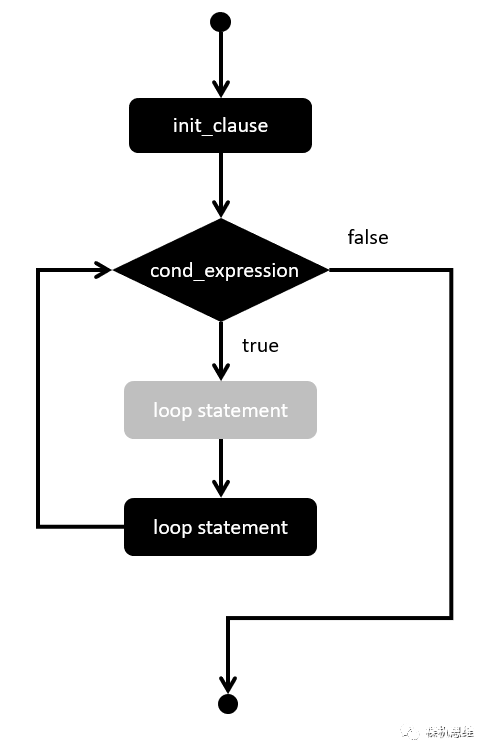
容易发现,经过必要的“构造”,我们可以恰好实现一个如同 do { } while(0) 一样的效果:
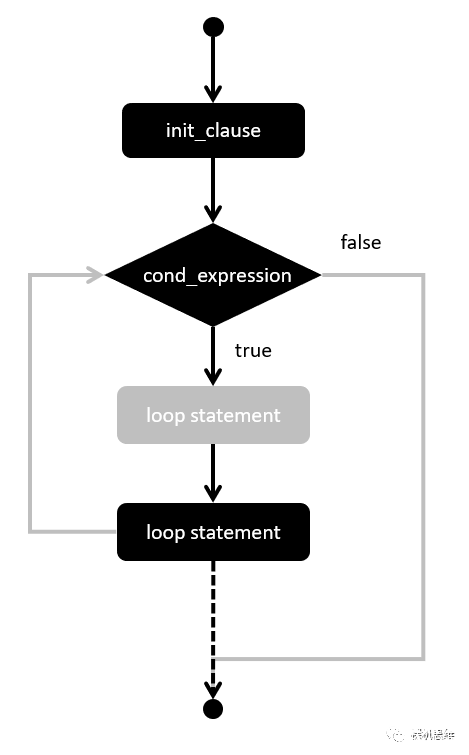
图中灰色的部分为原本实际的执行流程,而纯黑色的线条以及最下方的虚线箭头则为等效的运行流程。与do {} while(0) 相比,在我们眼中 for 循环的几个关键部分就有了新的意义:
在执行用户代码之前(灰色部分),有能力进行一定的“准备工作”(Before部分);
在执行用户代码之后,有能力执行一定的“收尾工作”(After部分)
在init_clause阶段有能力定义一个“仅仅只覆盖” for 循环的,并且只对 User Code可见的局部变量——换句话说,这些局部变量是不会污染 for 循环以外的地方的。
【构造using结构】
上面所提到的结构,在C#中有一个类似的语法,叫做 using(),其典型的用法如下:
using (StreamReader tReader = File.OpenText(m_InputTextFilePath)){ while (!tReader.EndOfStream) { 。.. }}
以上述代码为例进行讲解:
在 using 圆括号内定义的变量,其生命周期仅覆盖 using 紧随其后的花括号内部;
当用于代码离开 using 结构的时候,using 会自动执行一个“扫尾工作”,而这个扫尾工作是对应的类事先定义好的。在上述例子中,所谓的扫尾工作就是关闭 与 类StreamReader的实例tReader 所关联的文件——简单说就是using会自动把文件关闭,而不必用户亲自动手。
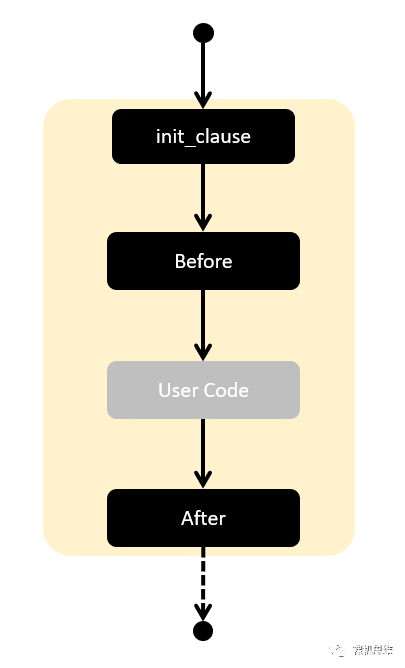
是不是闻到了熟悉的味道?不要搞错因果关系——我们正是对C#中的using结构“甚是眼馋”才决定自己动手,用 for 来创造一个——现有C#的using结构才有我们后面的尝试。下图是using所等校流程图,可以看到他比我们此前的结构还少了一个“Before”部分:

要实现类似using的结构,首先要考虑如何构造一个“至执行一次”的for循环结构。要做到这一点,毫无难度:
for (int i = 1; i 》 0; i++) { 。..}
以此为起点,对比我们的“蓝图”,发现至少有以下几个问题:
如何实现 before和after的部分?
现在用的变量 i 固定是 int 类型的,如何允许用户在 init_clause 定义自己的局部变量,并允许使用自己的类型?
问题一:如何实现 before 和 after 部分
对比前面的图例,我们知道 before 和 after 的部分实际上分别对应 for 循环的 cond_expression 和 iteration_expression;同时,这两个部分都必须是表达式——由于表达式的限制,能插入在 before 和 after 部分的内容实际上就只能是“普通表达式”或者是“函数”。
由于我们还必须至少借助 cond_expression 来实现 “只运行一次” 的功能,如何见缝插针的实现 before 的功能呢?不绕弯子,看代码:
//! 假设用户要插入的内容我们都放在叫做 before 和after的函数里extern void before(void);extern void after(void);for (int i = 1; //!《 init_clause i--?(before(),1):0; //!《 cond_expression after()) //!《 iteration_expression{ 。..}
我们知道,cond_expression 只在乎用户表达式的返回值是0还是非0,因此,这里其实真正起作用的本体是 “i--”——第一次判断的时候返回值是1,由于自减操作,第二次判断的时候就是0了——这就完成了让 for 运行且只运行一次的功能。
接下来,我们借助一个问好表达式,尝试给 i-- 的结果做一个等效“解释”,即:
(i--) ? 1 : 0
用人话说就是,如果 (i--)值是非0的,我们就返回1,反之返回0。这么做的意义是为了进一步通过逗号表达式对 “1” 所在的部分进行扩展:
(i--) ? (before(), 1) //!《 使用逗哈表达式进行扩展: 0
由于逗号表达式只管 最右边的结果,忽略所有左边的返回值,因此,哪怕before()函数没有实际返回值对C编译器来说都是无所谓的。同理,由于我们在cond_expression部分已经完成了所有功能,因此 iteration_expression 就任由我们宰割了——编译器原本就对此处表达式所产生的数值并不感兴——我们直接放下 after() 函数即可。
至此,插入 before() 和 after() 的问题圆满解决。
问题二:如何允许用户定义自己的局部变量,并且拥有自己的类型
要解决这个问题,首先必须打破定势思维,即:for循环只能用整型变量。实际并非如此,对for来说真正起作用的只有 cond_expression 的返回值,而它只关心用户的表达式返回的 布尔量 是什么——换句话说,有无数种方法来产生 cond_expression,而使用普通的整形计数器,并对其进行判断只是众多方法中的一种。
打破了这一定势思维后,我们就从问题本身出发考虑:允许用户用自己的类型定义自己的变量——虽然看似我们并不能知道用户会用什么类型来定义变量,因而就无法写出通用的 cond_expression 来实现“让for执行且执行一次”的功能,然而,你们也许忘记了 init_clause 的一个特点:它还可以定义指针——换句话说,无论用户定义了什么类型,我们都可以在最后定义一个指向该类型的指针:
#define using(__declare, __on_enter_expr, __on_leave_expr) \ for (__declare, *_ptr = NULL; \ _ptr++ == NULL ? \ ((__on_enter_expr),1) : 0; \ __on_leave_expr \ )
为了验证我们的结果,不妨写一个简单的代码:
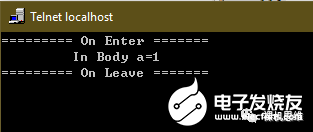
using(int a = 0,printf(“========= On Enter =======\r\n”), printf(“========= On Leave =======\r\n”)) { printf(“\t In Body a=%d \r\n”, ++a);}
这是对应的执行效果:
我们不妨将上述的宏进行展开,一个可能的结果是:
for (int a = 0, *_ptr = NULL; _ptr++ == NULL ? ((printf(“========= On Enter =======\r\n”)),1) : 0; printf(“========= On Leave =======\r\n”) ) { printf(“\t In Body a=%d \r\n”, ++a);}
从 init_clause 的展开结果来看,完全符合要求:
int a = 0, *_ptr = NULL;
接下来,为了提高宏的鲁棒性,我们可以继续做一些改良,比如给指针一个唯一的名字:
#define using(__declare, __on_enter_expr, __on_leave_expr) \ for (__declare, *CONNECT3(__using_, __LINE__,_ptr) = NULL; \ CONNECT3(__using_, __LINE__,_ptr)++ == NULL ? \ ((__on_enter_expr),1) : 0; \ __on_leave_expr \ )
这里,实际上是使用了前面文章中介绍的宏 CONNECT3() 将 “__using_”,__LINE__所表示的当前行号,以及 “_ptr” 粘连在一起,形成一个唯一的局部变量名:
CONNECT3(__using_, __LINE__,_ptr)
如果你对 CONNECT() 宏的来龙去脉感兴趣,可以单击这里。
更进一步,如果用户有不同的需求:比如想定义两个以上的局部变量,或是想省确 __on_enter_expr 或者是 __on_leave_expr ——我们完全可以定义多个不同版本的 using:
#define __using1(__declare) \ for (__declare, *CONNECT3(__using_, __LINE__,_ptr) = NULL; \ CONNECT3(__using_, __LINE__,_ptr)++ == NULL; \ )#define __using2(__declare, __on_leave_expr) \ for (__declare, *CONNECT3(__using_, __LINE__,_ptr) = NULL; \ CONNECT3(__using_, __LINE__,_ptr)++ == NULL; \ __on_leave_expr \ )#define __using3(__declare, __on_enter_expr, __on_leave_expr) \ for (__declare, *CONNECT3(__using_, __LINE__,_ptr) = NULL; \ CONNECT3(__using_, __LINE__,_ptr)++ == NULL ? \ ((__on_enter_expr),1) : 0; \ __on_leave_expr \ )#define __using4(__dcl1, __dcl2, __on_enter_expr, __on_leave_expr) \ for (__dcl1, __dcl2, *CONNECT3(__using_, __LINE__,_ptr) = NULL; \ CONNECT3(__using_, __LINE__,_ptr)++ == NULL ? \ ((__on_enter_expr),1) : 0; \ __on_leave_expr \ )
借助宏的重载技术,我们可以根据用户输入的参数数量自动选择正确的版本:
#define using(。..) \ CONNECT2(__using, VA_NUM_ARGS(__VA_ARGS__))(__VA_ARGS__)
至此,我们完成了对 for 的改造,并提出了__using1, __using2, __using3 和 __using4 四个版本变体。那么问题来了,他们分别有什么用处呢?
【提供不阻碍调试的代码封装】
前面的文章中,我们曾有意无意的提供过一个实现原子操作的封装:即在代码的开始阶段关闭全局中断并记录此前的中断状态;执行用户代码后,恢复关闭中断前的状态。其代码如下:
#define SAFE_ATOM_CODE(。..) \{ \ uint32_t CONNECT2(temp, __LINE__) = __disable_irq(); \ __VA_ARGS__ \ __set_PRIMASK((CONNECT2(temp, __LINE__))); \}
因此可以很容易的通过如下的代码来保护关键的寄存器操作:
/** \fn void wr_dat (uint16_t dat) \brief Write data to the LCD controller \param[in] dat Data to write*/static __inline void wr_dat (uint_fast16_t dat) { SAFE_ATOM_CODE ( LCD_CS(0); GLCD_PORT-》DAT = (dat 》》 8); /* Write D8..D15 */ GLCD_PORT-》DAT = (dat & 0xFF); /* Write D0..D7 */ LCD_CS(1); )}
唯一的问题是,这样的写法,在调试时完全没法在用户代码处添加断点(编译器会认为宏内所有的内容都写在了同一行),这是大多数人不喜欢使用宏来封装代码结构的最大原因。借助 __using2,我们可以轻松的解决这个问题:
#define SAFE_ATOM_CODE() \ __using2( uint32_t CONNECT2(temp,__LINE__) = __disable_irq(), \ __set_PRIMASK(CONNECT2(temp,__LINE__)))
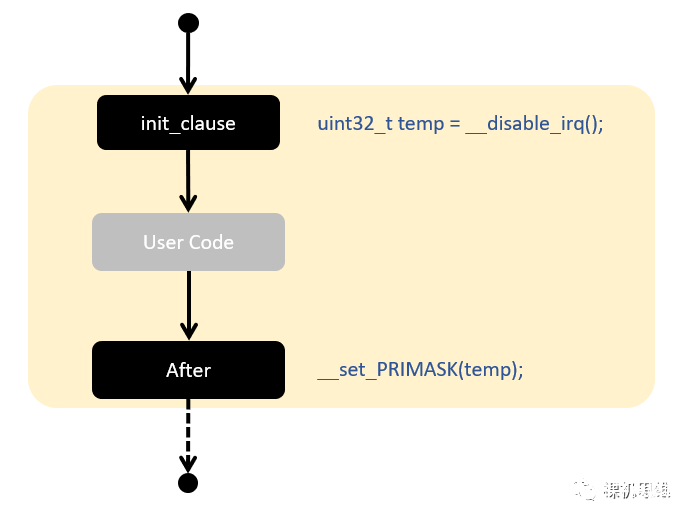
修改上述的代码为:
static __inline void wr_dat (uint_fast16_t dat) { SAFE_ATOM_CODE() { LCD_CS(0); GLCD_PORT-》DAT = (dat 》》 8); /* Write D8..D15 */ GLCD_PORT-》DAT = (dat & 0xFF); /* Write D0..D7 */ LCD_CS(1); }}
由于using的本质是 for 循环,因为我们可以通过花括号的形式来包裹用户代码,因此,可以很方便的在用户代码中添加断点,单步执行。至于原子保护的功能,我们不妨将上述代码进行宏展开:
static __inline void wr_dat (uint_fast16_t dat){ for (uint32_t temp154 = __disable_irq(), *__using_154_ptr = NULL; __using_154_ptr++ == NULL ? ((temp154 = temp154),1) : 0; __set_PRIMASK(temp154) ) { LCD_CS(0); GLCD_PORT-》DAT = (dat 》》 8); GLCD_PORT-》DAT = (dat & 0xFF); LCD_CS(1); }}
通过观察,容易发现,这里巧妙使用 init_clause 给 temp154 变量进行赋值——在关闭中断的同时保存了此前的状态;并在原本 after 的位置放置了 恢复中断的语句 __set_PRIMASK(temp154)。
举一反三,此类方法除了用来开关中断以外,还可以用在以下的场合:
在OOPC中自动创建类,并使用 before 部分来执行构造函数;在 after 部分完成 类的析构。
在外设操作中,在 init_clause 部分定义指向外设的指针;在 before部分 Enable或者Open外设;在after部分Disable或者Close外设。
在RTOS中,在 before 部分尝试进入临界区;在 after 部分释放临界区
在文件操作中,在 init_clause 部分尝试打开文件,并获得句柄;在 after 部分自动 close 文件句柄。
在有MPU进行内存保护的场合,在 before 部分,重新配置MPU获取目标地址的访问权限;在 after部分再次配置MPU,关闭对目标地址范围的访问权限。
……
【构造with块】
不知道你们在实际应用中有没有遇到一连串指针访问的情形——说起来就好比是:
你邻居的-》朋友的-》亲戚家的-》一个狗的-》保姆的-》手机
如果我们要操作这里的“手机”,实在是不想每次都写这么一长串“恶心”的东西,为了应对这一问题,Visual Basic(其实最早是Quick Basic)引入了一个叫做 WITH 块的概念,它的用法如下:
WITH 你邻居的-》朋友的-》亲戚家的-》一个狗的-》保姆的-》手机 # 这里可以直接访问手机的各项属性,用 “。” 开头就行 。 手机壳颜色 = xxxxx 。 贴膜 = 玻璃膜END WITH
不光是Visual Basic,我们使用C语言进行大规模的应用开发时,或多或少也会遇到同样的情况,比如,配置 STM32 外设时,填写外设配置结构体的时候,每一行都要重新写一遍结构体变量的名字,也是在是很繁琐:
static UART_HandleTypeDef s_UARTHandle = UART_HandleTypeDef(); s_UARTHandle.Instance = USART2; s_UARTHandle.Init.BaudRate = 115200; s_UARTHandle.Init.WordLength = UART_WORDLENGTH_8B; s_UARTHandle.Init.StopBits = UART_STOPBITS_1; s_UARTHandle.Init.Parity = UART_PARITY_NONE; s_UARTHandle.Init.HwFlowCtl = UART_HWCONTROL_NONE; s_UARTHandle.Init.Mode = UART_MODE_TX_RX;
入股有了with块的帮助,上述代码可能就会变得更加清爽,比如:
static UART_HandleTypeDef s_UARTHandle = UART_HandleTypeDef();with(s_UARTHandle) { .Instance = USART2; .Init.BaudRate = 115200; .Init.WordLength = UART_WORDLENGTH_8B; .Init.StopBits = UART_STOPBITS_1; .Init.Parity = UART_PARITY_NONE; .Init.HwFlowCtl = UART_HWCONTROL_NONE; .Init.Mode = UART_MODE_TX_RX;}
遗憾的是,如果要完全实现上述的结构,在C语言中是不可能的,但借助我们的 using() 结构,我们可以做到一定程度的模拟:
#define with(__type, __addr) using(__type *_p=(__addr))#define _ (*_p)
在这里,我们要至少提供目标对象的类型,以及目标对象的地址:
static UART_HandleTypeDef s_UARTHandle = UART_HandleTypeDef();with(UART_HandleTypeDef &s_UARTHandle) { _.Instance = USART2; _.Init.BaudRate = 115200; _.Init.WordLength = UART_WORDLENGTH_8B; _.Init.StopBits = UART_STOPBITS_1; _.Init.Parity = UART_PARITY_NONE; _.Init.HwFlowCtl = UART_HWCONTROL_NONE; _.Init.Mode = UART_MODE_TX_RX;}
注意到,这里“_”实际上被用来替代 s_UARTHandle——虽然感觉有点不够完美,但考虑到脚本语言 perl 有长期使用 “_” 表示本地对象的传统,这样一看,似乎“_” 就是一个对 “perl” 的完美致敬了。
【回归本职 foreach】
很多高级语言都有专门的 foreach 语句,用来实现对数组(或是链表)中的元素进行逐一访问。原生态C语言并没有这种奢侈,即便如此,Linux也定义了一个“野生”的 foreach 来实现类似的功能。为了演示如何使用 using 结构来构造 foreach,我们不妨来看一个例子:
typedef struct example_lv0_t { uint32_t wA; uint16_t hwB; uint8_t chC; uint8_t chID;} example_lv0_t;example_lv0_t s_tItem[8] = { {.chID = 0}, {.chID = 1}, {.chID = 2}, {.chID = 3}, {.chID = 4}, {.chID = 5}, {.chID = 6}, {.chID = 7},};
我们希望实现一个函数,能通过 foreach 自动的访问数组 s_tItem 的所有成员,比如:
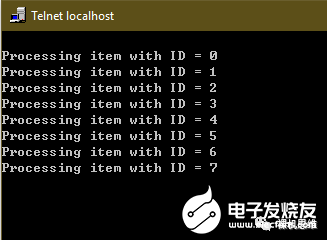
foreach(example_lv0_t, s_tItem) { printf(“Processing item with ID = %d\r\n”, _.chID);}
跟With块一样,这里我们仍然“致敬” perl——使用 “_” 表示当前循环下的元素。在这个例子中,为了使用 foreach,我们需要提供至少两个信息:目标数组元素的类型(example_lv0_t)和目标数组(s_tItem)。
这里的难点在于,如何定义一个局部的指针,并且它的作用范围仅仅只覆盖 foreach 的循环体。此时,坐在角落里的 __with1() 按耐不住了,高高的举起了双手——是的,它仅有的功能就是允许用户定义一个局部变量,并覆盖由第三方所编写的、由 {} 包裹的区域:
#define dimof(__array) (sizeof(__array)/sizeof(__array[0]))#define foreach(__type, __array) \ __using1(__type *_p = __array) \ for ( uint_fast32_t CONNECT2(count,__LINE__) = dimof(__array); \ CONNECT2(count,__LINE__) 》 0; \ _p++, CONNECT2(count,__LINE__)-- \ )
上述的宏并不复杂,大家完全可以自己看懂,唯一需要强调的是,using() 的本质是一个for,因此__using1() 下方的for 实际上是位于由 __using1() 所提供的循环体内的,也就是说,这里的局部变量_p其作用域也覆盖 下面的for 循环,这就是为什么我们可以借助:
#define _ (*_p)
的巧妙代换,通过 “_” 来完成对指针“_p”的使用。为了方便大家理解,我们不妨将前面的例子代码进行宏展开:
for (example_lv0_t *_p = s_tItem, *__using_177_ptr = NULL; __using_177_ptr++ == NULL ? ((_p = _p),1) : 0; ) for ( uint_fast32_t count177 = (sizeof(s_tItem)/sizeof(s_tItem[0])); count177 》 0; _p = _p+1, count177-- ) { printf(“Processing item with ID = %d\r\n”, (*_p).chID); }
其执行结果为:
foreach目前的用法看起来“岁月静好”,似乎没有什么问题,可惜的是,一旦进行实际的代码编写,我们会发现,假如我们要在 foreach 结构中再用一个foreach,或是在foreach中使用 with 块,就会出现 “_” 被覆盖的问题——也就是在里层的 foreach或是 with 无法通过 “_” 来访问外层“_” 所代表的对象。为了应对这一问题,我们可以对 foreach 进行一个小小的改造——允许用户再指定一个专门的局部变量,用于替代“_” 表示当前循环下的对象:
#define foreach2(__type, __array) \ using(__type *_p = __array) \ for ( uint_fast32_t CONNECT2(count,__LINE__) = dimof(__array); \ CONNECT2(count,__LINE__) 》 0; \ _p++, CONNECT2(count,__LINE__)-- \ )#define foreach3(__type, __array, __item) \ using(__type *_p = __array, *__item = _p, _p = _p, ) \ for ( uint_fast32_t CONNECT2(count,__LINE__) = dimof(__array); \ CONNECT2(count,__LINE__) 》 0; \ _p++, __item = _p, CONNECT2(count,__LINE__)-- \ )
这里的 foreach3 提供了3个参数,其中最后一个参数就是用来由用户“额外”指定新的指针的;与之相对,老版本的foreach我们称之为 foreach2,因为它只需要两个参数,只能使用“_”作为对象的指代。进一步的,我们可以使用宏的重载来简化用户的使用:
#define foreach(。..) \ CONNECT2(foreach, VA_NUM_ARGS(__VA_ARGS__))(__VA_ARGS__)
经过这样的改造,我们可以用下面的方法来为我们的循环指定一个叫做“ptItem”的指针:
foreach(example_lv0_t, s_tItem, ptItem) { printf(“Processing item with ID = %d\r\n”, ptItem-》chID);}
展开后的形式如下:
for (example_lv0_t *_p = s_tItem, ptItem = _p, *__using_177_ptr = NULL; __using_177_ptr++ == NULL ? ((_p = _p),1) : 0; ) for ( uint_fast32_t count177 = (sizeof(s_tItem)/sizeof(s_tItem[0])); count177 》 0; _p = _p+1, ptItem = _p, count177-- ) { printf(“Processing item with ID = %d\r\n”, ptItem-》chID); }
代码已经做了适当的展开和缩进,这里就不作进一步的分析了。
【后记】
本文的目的,算是对【为宏正名】系列所介绍的知识进行一次示范——告诉大家如何正确的使用宏,配合已有的老的语法结构来“固化”一个新的模板,并以这个模板为起点,理解它的语法意义和用户,简化我们的日常开发。在这篇文章中,老的语法结构就是 for,它是由C语言原生支持的,借助宏,我们封装了一个新的语法结构 using(), 借助它的4种不同形式、理解它们各自的特点,我们又分别封装了非常实用的SAFE_ATOM_CODE(),With块和foreach语法结构——他们的存在至少证明了以下几点:
宏不是奇技淫巧
宏可以封装出其它高级语言所提供的“基础设施”
设计良好的宏可以提升代码的可读性,而不是破坏它
设计良好的宏并不会影响调试
宏可以用来固化某些模板,避免每次都重新编写复杂的语法结构,在这里,using() 模板的出现,避免了我们每次都重复通过原始的 for 语句来构造所需的语法结构,极大的避免了重复劳动,以及由重复劳动所带来的出错风险
-
for
+关注
关注
0文章
44浏览量
16323 -
宏汇编器
+关注
关注
0文章
7浏览量
9092
发布评论请先 登录
经颅磁那么多模式都管啥?

变频器的特殊用法
IIC的正确用法

在物联网设备面临的多种安全威胁中,数据传输安全威胁和设备身份安全威胁有何本质区别?
C语言的printf基本用法介绍

温度测量仪器有哪些?有何品牌推荐?
编译vision_board_mipi_2.0inch_lvgl工程,cpu能跑到100%,竟然需要41分钟,怎么解决?

多种空间矢量调制方法的谐波分析
Allegro Skill布线功能之删除Dangling介绍

光模块为什么有那么多的波长?该如何选择?



评论