 有关深度森林的新论文和Jeffery Dean机器学习进展研究综述
有关深度森林的新论文和Jeffery Dean机器学习进展研究综述

本周的论文既有周志华有关深度森林的新论文和Jeffery Dean机器学习进展研究综述,也有华为和DeepMind的学术之争。
目录:
Multi-label Learning with Deep Forest
Unifying machine learning and quantum chemistry with a deep neural network for molecular wavefunctions
The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design
CenterMask : Real-Time Anchor-Free Instance Segmentation
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
EfficientDet: Scalable and Efficient Object Detection
α^α-Rank: Practically Scaling α-Rank through Stochastic Optimisation
论文 1:Multi-label Learning with Deep Forest
作者:Liang Yang、Xi-Zhu Wu、Yuan Jiang、Zhi-Hua Zhou
论文链接:https://arxiv.org/pdf/1911.06557.pdf
摘要:在多标签学习领域,每个势力都和多个表现相关联,因此最重要的任务是如何让构建的模型学到标签关系。深度神经网络通常会联合嵌入特征和标签信息到一个隐式空间,用于发掘表现关系。然而,这一方法能够成功是因为对模型深度的准确选择。深度森林是近来基于集成树模型的深度学习框架,不依赖反向传播。研究者采用了深度森林算法用于解决多标签问题。因此,他们设计了 MLDF 方法,包括两个机制:重复利用度量感知特征和度量感知层增长。度量感知特征重复利用机制能够根据置信度重新使用之前层使用过的好的特征。而度量感知层增长机制则保证 MLDF 会根据性能瓶颈逐渐提升模型的复杂度。MLDF 同时解决了两个问题:一个是控制模型复杂度以减少过拟合问题,另一个是根据用户需求优化性能评价,因为在多标签学习评价中有很多不同的度量标准。实验说明,研究者提出的方法不仅在基准测试的 6 个评价标准上胜过了其他方法,还具有多标签学习中标签关系发掘和其他不错的特性。
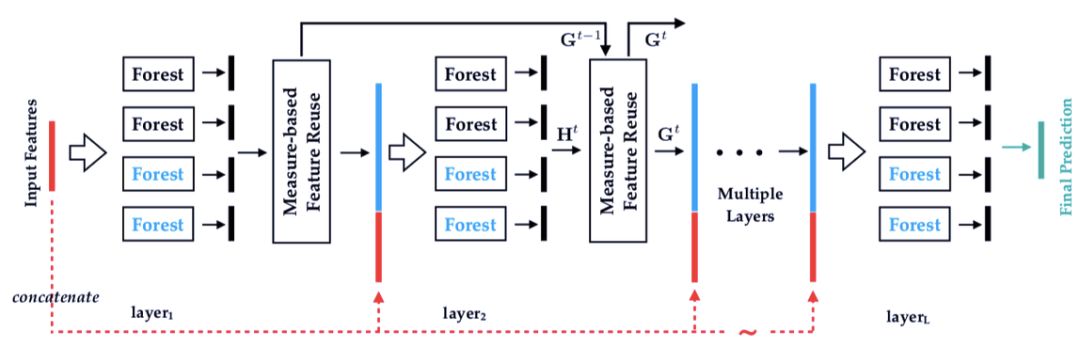
图 1:多标签深度森林算法(NLDF)。每个层集成两个不同的森林(上部的黑色和下部的蓝色)。

度量感知特性重复利用的算法图示。

度量感知层增长的图示。
推荐:近日,南大周志华等人首次提出使用深度森林方法解决多标签学习任务。该方法在 9 个基准数据集、6 个多标签度量指标上实现了最优性能。
论文 2:Unifying machine learning and quantum chemistry with a deep neural network for molecular wavefunctions
作者:K. T. Schütt、M. Gastegger、A. Tkatchenko、K.-R. Müller、R. J. Maurer
论文链接:https://www.nature.com/articles/s41467-019-12875-2
摘要:通过对基于量子化学计算的化学空间进行大规模探索,机器学习可以促进化学和材料科学的发展。虽然这些机器学习模型可以对原子化学属性进行快速和准确的预测,但却无法显式地捕获到分子的电子自由度,由此限制了它们对反应化学和化学分子的适用性。在本文中,研究者提出了一种深度学习框架,用于在原子轨道局部基中预测量子力学波函数,进而可以推导出其他基态性质。通过类力场效率下的波函数,这种方法可以继续完全访问电子结构,并以一种分析上可微的表征捕获到了量子力学。在列举的几个例子中,研究者证明这将为针对电子性能优化的分子结构逆向设计提供有前途的方法,并为增强机器学习和量子化学之间的协同提供清晰的发展道路。
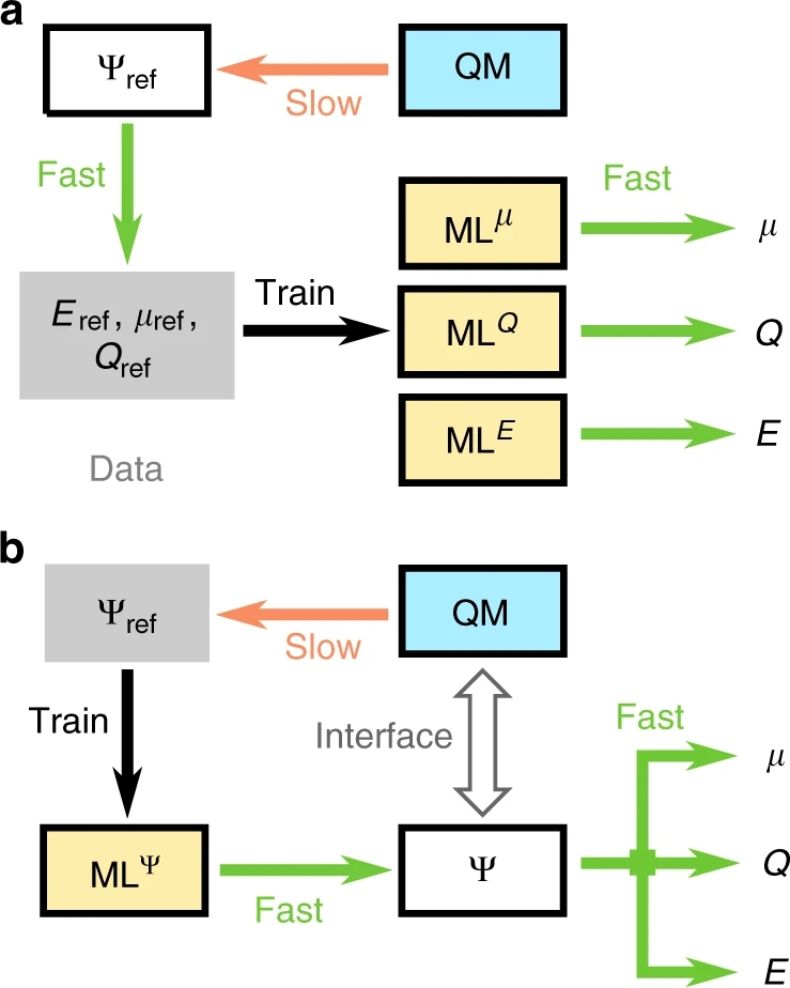
量子化学与机器学习的协同。a 表示前向模型,机器学习基于参考计算预测化学性能;b 表示混合模型,机器学习预测波函数。
推荐:本文作者通过一个新颖的深度学习框架,进一步探索了机器学习在量子化学领域的作用,刊登在了《Nature Communications》上。
论文 3:The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design
作者:Jeffery Dean
论文链接:https://arxiv.org/abs/1911.05289
摘要:过去十年我们见证了机器学习的显著进步,特别是基于深度学习的神经网络。机器学习社区也一直在尝试构建新模型,用于完成具有挑战性的工作,包括使用强化学习,通过和环境进行交互的方式完成难度较大的任务,如下围棋、玩电子游戏等。机器学习对算力的需求无疑是庞大的,从计算机视觉到自然语言处理,更大的模型和更多的数据往往能够取得更好的性能。在摩尔定律时代,硬件进步带来的算力增长尚且能够满足机器学习的需求,但当摩尔定律被榨干后,怎样让硬件中的算力资源被机器学习模型充分利用成了下一个需要探讨的问题。
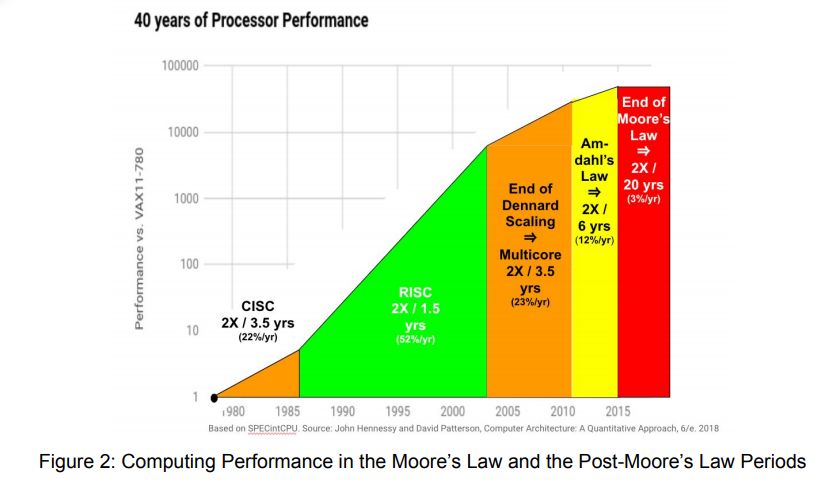
摩尔定律和后摩尔定律时代的计算需求增长态势,其中自 1985 年至 2003 年,通用 CPU 性能每 1.5 年提升一倍;自 2003 年至 2010 年,通用 CPU 性能每 2 年提升一倍;而 2010 年以后,通用 CPU 性能预计每 20 年才能提升一倍。

AlexNet、GoogleNet、AlphaZero 等重要的机器学习网络架构以及它们的计算需求增长态势。
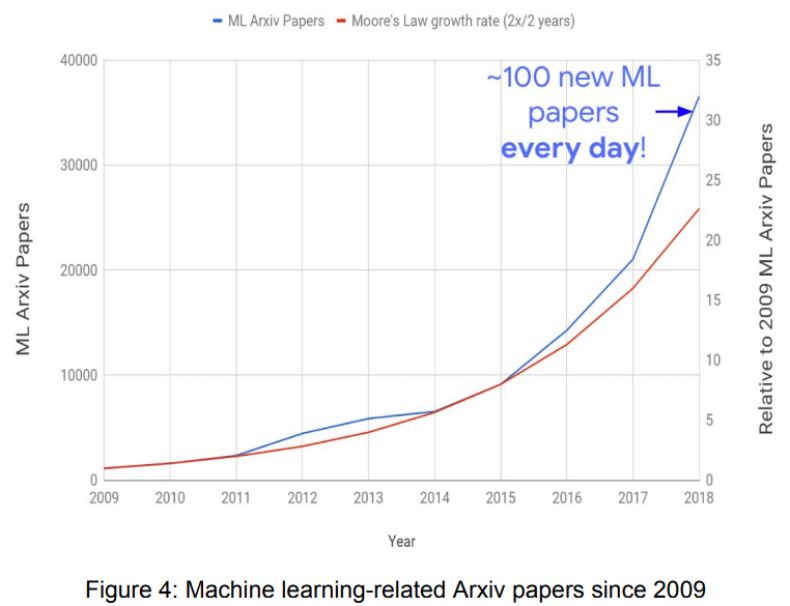
自 2009 年以来,机器学习相关 Arxiv 论文发表数量的增长态势(蓝)和摩尔定律增长率(红)。
推荐:深度学习和硬件怎样结合?Jeff Dean 长文介绍了后摩尔定律时代的机器学习研究进展,以及他对未来发展趋势的预测判断。
论文 4:CenterMask : Real-Time Anchor-Free Instance Segmentation
作者:Youngwan Lee、Jongyoul Park
论文链接:https://arxiv.org/abs/1911.06667
摘要:在本文中,来自韩国电子通讯研究院(ETRI)的两位研究者提出了一种简单却高效的无锚点实例分割方法,被称为 CenterMask,该方法将一个新颖的空间注意力导向 mask(SAG-Mask)添加进 anchor-free 单级目标检测器中(FCOS),后者与 Mask R-CNN 相同。通 SAG-Mask 分支嵌入到 FCOS 目标检测器中,它可以利用空间注意力地图来每个框上预测分割掩码,从而有助于分割掩码。此外,研究者还展示了一种性能提升的 VoVNetV2,它有以下两种有效策略:添加残差连减弱接以缓解更大 VoVNet 的饱和问题;利用有效的挤压-激励(effective Squeeze-Excitation,eSE)处理原始 SE 的信息损失问题。借助于 SAG-Mask 和 VoVNetV2,研究者设计了分别针对大模型和小模型的 CenterMask 和 CenterMask-Lite。其中 CenterMask 的性能优于当前所有的 SOTA 模型,并且速度较这些模型更快;CenterMask-Lite 也实现了 33.4% 的 mask AP 和 38.0% 的 box AP 结果,并在 Titan Xp 显卡上以 35fps 的速度分别超出了当前 SOTA 模型 2.6% 和 7.0% 的 AP gain。研究者希望 CenterMask 和 VoVNetV2 可以分别作为各种视觉任务上实时实例分割和骨干网络的可靠基线。

CenterMask 架构。

CenterMask 与其他方法在 COCO tes-dev2017 数据集上的实例分割和检测性能对比。
推荐:论文作者称「CenterMask 的性能优于当前所有的 SOTA 模型,并且速度较这些模型更快」,分割精度也打败了先前所有的 State-of-the-art!
论文 5:Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
作者:Julian Schrittwieser、Ioannis Antonoglou、Thomas Hubert 等
论文链接:https://arxiv.org/pdf/1911.08265.pdf
摘要:基于前向搜索的规划算法已经在 AI 领域取得了很大的成功。在围棋、国际象棋、西洋跳棋、扑克等游戏中,人类世界冠军一次次被算法打败。此外,规划算法也已经在物流、化学合成等诸多现实世界领域中产生影响。然而,这些规划算法都依赖于环境的动态变化,如游戏规则或精确的模拟器,导致它们在机器人学、工业控制、智能助理等领域中的应用受到限制。最受欢迎的方法是基于无模型强化学习的方法,即直接从智能体与环境的交互中估计优化策略和/或价值函数。但在那些需要精确和复杂前向搜索的领域(如围棋、国际象棋),这种无模型的算法要远远落后于 SOTA。在新的研究中,DeepMind 联合伦敦大学学院的研究者提出了 MuZero,这是一种基于模型的强化学习新方法。研究者在 57 个不同的雅达利游戏中评估了 MuZero,发现该模型在雅达利 2600 游戏中达到了 SOTA 表现。此外,他们还在不给出游戏规则的情况下,在国际象棋、日本将棋和围棋中对 MuZero 模型进行了评估,发现该模型可以匹敌 AlphaZero 超越人类的表现,而且,在该实验中,AlphaZero 提前获知了规则。
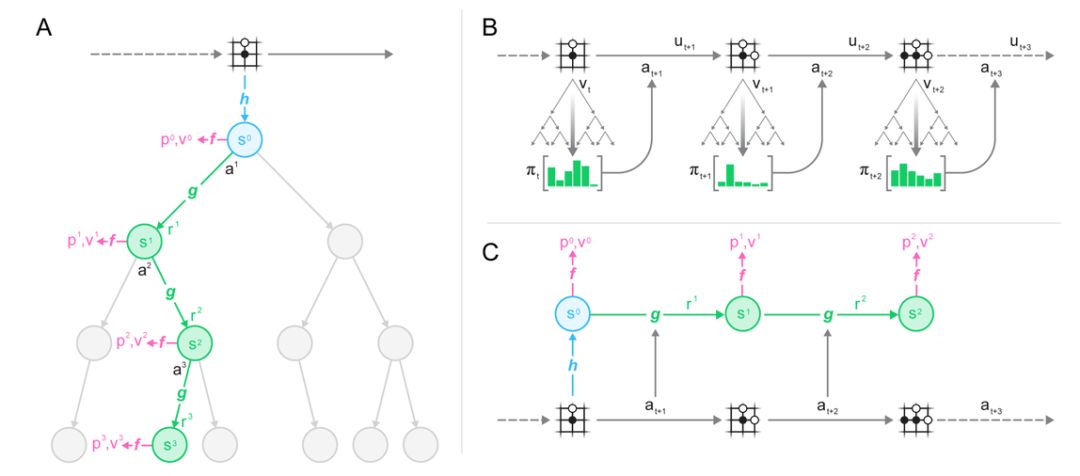
图 1:用一个训练好的模型进行规划、行动和训练。(A)MuZero 利用其模型进行规划的方式;(B)MuZero 在环境中发生作用的方式;(C)MuZero 训练其模型的方式。
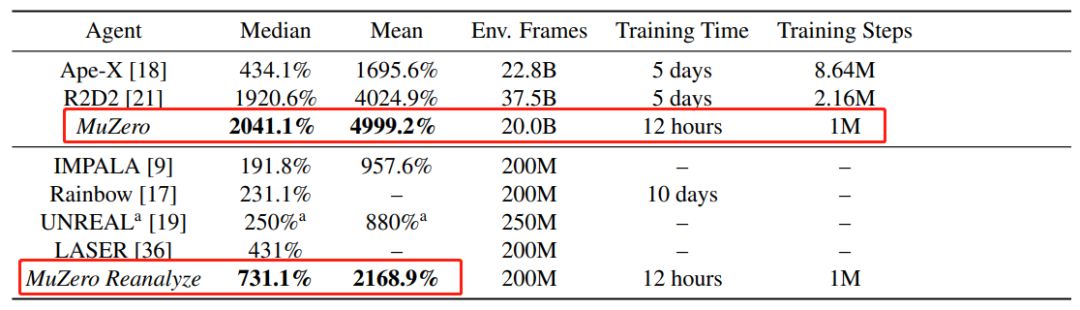
表 1:雅达利游戏中 MuZero 与先前智能体的对比。研究者分别展示了大规模(表上部分)和小规模(表下部分)数据设置下 MuZero 与其他智能体的对比结果,表明 MuZero 在平均分、得分中位数、Env. Frames、训练时间和训练步骤五项评估指标(红框)取得了新的 SOTA 结果。
推荐:DeepMind 近期的一项研究提出了 MuZero 算法,该算法在不具备任何底层动态知识的情况下,通过结合基于树的搜索和学得模型,在雅达利 2600 游戏中达到了 SOTA 表现,在国际象棋、日本将棋和围棋的精确规划任务中可以匹敌 AlphaZero,甚至超过了提前得知规则的围棋版 AlphaZero。
论文 6:EfficientDet: Scalable and Efficient Object Detection
作者:Mingxing Tan、Ruoming Pang、Quoc V. Le
论文链接:https://arxiv.org/abs/1911.09070
摘要:在计算机视觉领域,模型效率已经变得越来越重要。在本文中,研究者系统地研究了用于目标检测的各种神经网络架构设计选择,并提出了一些关键的优化措施来提升效率。首先,他们提出了一种加权双向特征金字塔网络(weighted bi-directional feature pyramid network,BiFPN),该网络可以轻松快速地进行多尺度特征融合;其次,他们提出了一种复合缩放方法,该方法可以同时对所有骨干、特征网络和框/类预测网络的分辨率、深度和宽度进行统一缩放。基于这些优化,研究者开发了一类新的目标检测器,他们称之为 EfficientDet。在广泛的资源限制条件下,该检测器始终比现有技术获得更高数量级的效率。具体而言,在没有附属条件的情况下,EfficientDet-D7 在 52M 参数和 326B FLOPS1 的 COCO 数据集上实现了 51.0 mAP 的 SOTA 水平,体积缩小了 4 倍,使用的 FLOPS 减少了 9.3 倍,但仍比先前最佳的检测器还要准确(+0.3% mAP)。
推荐:本文探讨了计算机视觉领域的模型效率问题,分别提出了加权双向特征金字塔网络和复合缩放方法,进而开发了一种新的 EfficientDet 目标检测器,实现了新的 SOTA 水平。
论文 7:α^α-Rank: Practically Scalingα-Rank through Stochastic Optimisation
作者:Yaodong Yang、Rasul Tutunov、Phu Sakulwongtana、Haitham Bou Ammar
论文链接:https://arxiv.org/abs/1909.11628
摘要:作为 DeepMind「阿尔法」家族的一名新成员,α-Rank 有关强化学习,并于今年 7 月登上了《Nature Scientific Reports》。研究人员称,α-Rank 是一种全新的动态博弈论解决方法,这种方法已在 AlphaGo、AlphaZero、MuJoCo Soccer 和 Poker 等场景上进行了验证,并获得了很好的结果。但是,华为的这篇论文指出,DeepMind 的这项研究存在多个问题。研究者认为,如果要复现这篇论文,需要动用高达一万亿美元的算力,这是全球所有算力加起来都不可能实现的。
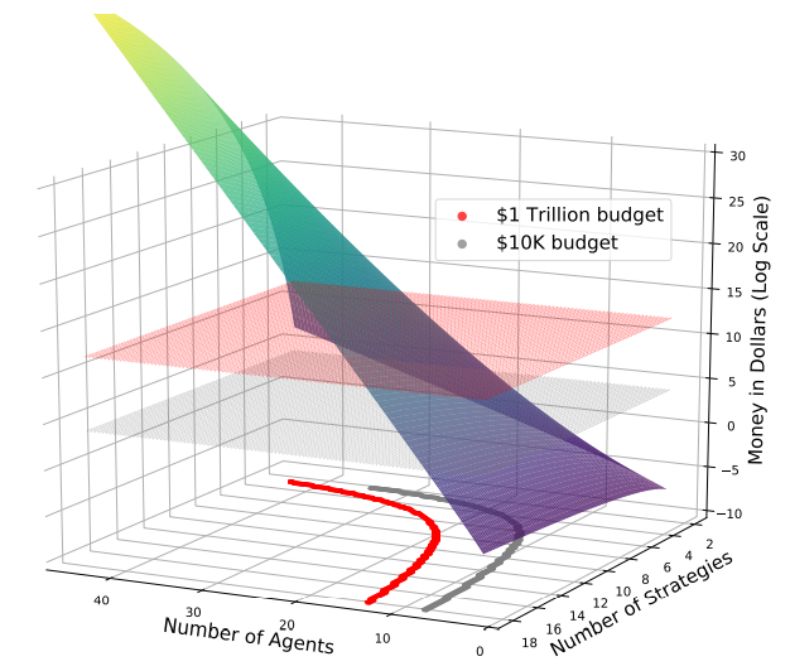
计算α-Rank 时构造转换矩阵 T 的花销成本。这里请注意,当前全球计算机的总算力约为 1 万亿美元(红色平面)。投影轮廓线表明,由于α-Rank「输入」的算力需求呈指数级增长,用十个以上的智能体进行多智能体评估是根本不可能的。
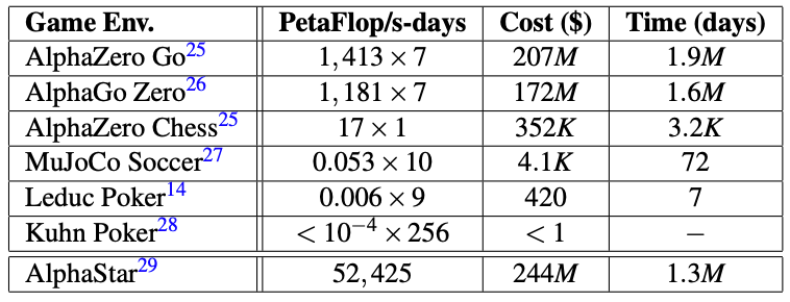
其他的算法也都不可行——在华为研究人员估算下,即使将收益矩阵加入α-Rank 跑 DeepMind 几个著名算法需要用到的资金花费和时间都是天文数字。注意:在这里预设使用全球所有的算力。
推荐:近日,DeepMind 之前时间发表在 Nature 子刊的论文被严重质疑。来自华为英国研发中心的研究者尝试实验了 DeepMind 的方法,并表示该论文需要的算力无法实现。
-
神经网络
+关注
关注
42文章
4842浏览量
108178 -
深度学习
+关注
关注
73文章
5608浏览量
124634
原文标题:7 papers | 周志华深度森林新论文;谷歌目标检测新SOTA
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
深度学习驱动的超构表面设计进展及其在全息成像中的应用

人工智能与机器学习在这些行业的深度应用
梁文锋署名DeepSeek新论文:突破GPU内存限制的技术革命
机器学习和深度学习中需避免的 7 个常见错误与局限性
穿孔机顶头检测仪 机器视觉深度学习
如何深度学习机器视觉的应用场景
如何在机器视觉中部署深度学习神经网络

易控智驾与中科院端到端自动驾驶方案入选CoRL 2025

中软国际AI深度应用创新论坛成功举办
中国科学院西安光机所在计算成像可解释性深度学习重建方法取得进展
机器学习赋能的智能光子学器件系统研究与应用

贸泽电子2025技术创新论坛探讨“边缘AI与机器学习”新纪元

智聚边缘 创见未来丨贸泽电子2025技术创新论坛探讨“边缘AI与机器学习”新纪元

智聚边缘 创见未来 贸泽电子2025技术创新论坛探讨“边缘AI与机器学习”新纪元
上海光机所在基于深度时空先验的动态定量相位成像研究方面取得进展



评论