 梁文锋署名DeepSeek新论文:突破GPU内存限制的技术革命
梁文锋署名DeepSeek新论文:突破GPU内存限制的技术革命

电子发烧友网报道 DeepSeek团队发布了一篇由创始人梁文锋署名的新论文,主题为《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》(直译为《基于可扩展查找的条件记忆:大语言模型稀疏性的新维度》)。这篇论文不仅揭示了当前大语言模型在知识检索方面的低效问题,还通过创新的Engram架构,将模型的“条件记忆”与“计算”分离,从而大幅降低错误率并节省算力。
条件记忆与Engram架构
论文的核心创新点在于提出了“条件记忆”这一概念,旨在解决当前大语言模型在知识检索方面的低效和算力消耗问题。梁文锋团队指出,语言建模本质上包含两类子任务:一类是组合式推理,需要依赖深层、动态计算完成;另一类是知识检索,面向命名实体等相对静态的内容,理论上可以通过简单查找更高效地处理。然而,现有Transformer架构缺乏原生的查找组件,遇到静态信息时往往仍需反复调用深层网络进行重建,加剧了算力浪费并推高了推理成本。
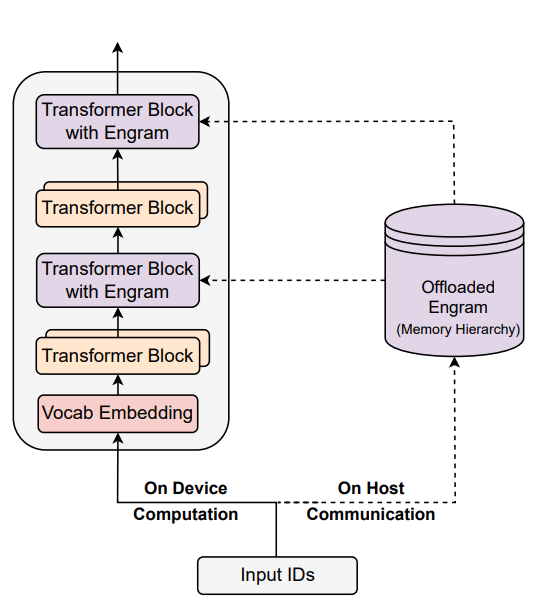
为了解决这一问题,DeepSeek团队提出了Engram架构(记忆痕迹架构),通过将静态知识存储与动态计算分离,实现了静态模式的常数时间O(1)查找。具体而言,条件记忆通过Engram模块实现,模型能够基于输入中的局部上下文模式,从大规模参数化记忆中快速检索并融合静态知识表示,从而避免在推理过程中反复通过深层计算重建高频、模板化信息。
突破GPU内存限制
在GPU内存限制方面,DeepSeek的新论文同样带来了革命性的突破。传统上,GPU内存容量有限,处理大规模数据集时往往需要频繁的数据传输和复杂的数据管理策略。而Engram架构通过稀疏存储模式,支持更大规模的知识存入,突破了传统注意力窗口的物理限制。当大约20%至25%的稀疏参数预算分配给Engram,剩余部分留给混合专家模型(MoE)时,模型性能达到最佳。
此外,DeepSeek团队还通过优化数据流动和调度机制,进一步降低了GPU内存的压力。例如,采用预取策略预测后续计算所需数据,提前从低速层加载至高速层;通过淘汰策略根据访问频率与重要性,将不活跃数据逐出至低速层;以及利用压缩策略对暂存于内存或磁盘的数据进行无损或有损压缩,减少I/O开销。这些技术手段的结合,使得GPU在处理大规模数据集时能够更加高效地利用内存资源。
当前,全球高端GPU资源90%集中于美国企业,且美国政府通过《芯片与科学法案》对中国实施高端GPU限售,直接导致中国AI企业面临“硬件卡脖子”困境。以训练千亿参数模型为例,传统架构需配置数万块H100 GPU,单次训练成本超1亿美元,而内存瓶颈更使模型规模受限于物理显存容量。
DeepSeek的Engram架构通过稀疏存储与动态计算分离技术,使模型在同等硬件条件下可处理3-5倍规模的参数。实验数据显示,其27B参数模型在32k上下文任务中,内存占用仅增加25%却实现13%的准确率提升。这种技术突破不仅降低中国AI企业对进口芯片的依赖度,更通过内存效率优化使现有硬件产能释放3倍以上算力。
结语
DeepSeek团队此次发布的新论文,不仅揭示了当前大语言模型在知识检索方面的低效问题,还通过创新的Engram架构和条件记忆概念,实现了GPU内存限制的革命性突破。这一技术突破不仅提高了模型运行效率,还为中国AI发展提供了战略支撑。在全球AI竞争日益激烈的背景下,DeepSeek的探索为中国AI企业开辟了一条自主创新、突破封锁的发展道路。
条件记忆与Engram架构
论文的核心创新点在于提出了“条件记忆”这一概念,旨在解决当前大语言模型在知识检索方面的低效和算力消耗问题。梁文锋团队指出,语言建模本质上包含两类子任务:一类是组合式推理,需要依赖深层、动态计算完成;另一类是知识检索,面向命名实体等相对静态的内容,理论上可以通过简单查找更高效地处理。然而,现有Transformer架构缺乏原生的查找组件,遇到静态信息时往往仍需反复调用深层网络进行重建,加剧了算力浪费并推高了推理成本。
为了解决这一问题,DeepSeek团队提出了Engram架构(记忆痕迹架构),通过将静态知识存储与动态计算分离,实现了静态模式的常数时间O(1)查找。具体而言,条件记忆通过Engram模块实现,模型能够基于输入中的局部上下文模式,从大规模参数化记忆中快速检索并融合静态知识表示,从而避免在推理过程中反复通过深层计算重建高频、模板化信息。
突破GPU内存限制
在GPU内存限制方面,DeepSeek的新论文同样带来了革命性的突破。传统上,GPU内存容量有限,处理大规模数据集时往往需要频繁的数据传输和复杂的数据管理策略。而Engram架构通过稀疏存储模式,支持更大规模的知识存入,突破了传统注意力窗口的物理限制。当大约20%至25%的稀疏参数预算分配给Engram,剩余部分留给混合专家模型(MoE)时,模型性能达到最佳。
此外,DeepSeek团队还通过优化数据流动和调度机制,进一步降低了GPU内存的压力。例如,采用预取策略预测后续计算所需数据,提前从低速层加载至高速层;通过淘汰策略根据访问频率与重要性,将不活跃数据逐出至低速层;以及利用压缩策略对暂存于内存或磁盘的数据进行无损或有损压缩,减少I/O开销。这些技术手段的结合,使得GPU在处理大规模数据集时能够更加高效地利用内存资源。
当前,全球高端GPU资源90%集中于美国企业,且美国政府通过《芯片与科学法案》对中国实施高端GPU限售,直接导致中国AI企业面临“硬件卡脖子”困境。以训练千亿参数模型为例,传统架构需配置数万块H100 GPU,单次训练成本超1亿美元,而内存瓶颈更使模型规模受限于物理显存容量。
DeepSeek的Engram架构通过稀疏存储与动态计算分离技术,使模型在同等硬件条件下可处理3-5倍规模的参数。实验数据显示,其27B参数模型在32k上下文任务中,内存占用仅增加25%却实现13%的准确率提升。这种技术突破不仅降低中国AI企业对进口芯片的依赖度,更通过内存效率优化使现有硬件产能释放3倍以上算力。
结语
DeepSeek团队此次发布的新论文,不仅揭示了当前大语言模型在知识检索方面的低效问题,还通过创新的Engram架构和条件记忆概念,实现了GPU内存限制的革命性突破。这一技术突破不仅提高了模型运行效率,还为中国AI发展提供了战略支撑。在全球AI竞争日益激烈的背景下,DeepSeek的探索为中国AI企业开辟了一条自主创新、突破封锁的发展道路。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
5271浏览量
136062 -
DeepSeek
+关注
关注
2文章
839浏览量
3397
发布评论请先 登录
相关推荐
热点推荐
内存要取代GPU?HBM之父警告:以英伟达GPU为核心的架构要被颠覆
电子发烧友网报道(文/梁浩斌)“主板插显卡上”,是PC DIY玩家对高性能显卡体积越来越大的调侃,随着显卡功率越来越高,硕大的散热模组让显卡投影面积甚至已经大于ITX规格的主板,在PC里显卡取代了

DeepSeek V3.1发布!拥抱国产算力芯片
电子发烧友网报道(文/李弯弯)2025年8月21日,DeepSeek正式官宣发布DeepSeek-V3.1大模型。新版本不仅在技术架构上实现重大升级,更通过参数精度优化与国产芯片深度适

腾讯阿里联手投资DeepSeek:估值飙升背后的AI资本博弈
美元估值实现翻倍。这场突如其来的资本博弈,不仅标志着DeepSeek创始人梁文锋“不引入外部资金”立场的彻底转变,更折射出中国AI产业在技术
探索DeepSeek多样化技术路径,英特尔架构师用至强CPU尝鲜
近期大模型领域里最火的热词,或者说技术创新点,非Engram (DeepSeek最新论文里设计的Engram机制) 莫属。今天我们想分享的,是英特尔围绕Engram开展的早期探索——用至强® 处理器
《电子发烧友电子设计周报》聚焦硬科技领域核心价值 26年第1期:2026.1.4--2025.1.16
:具身智能迈入“大小脑协同”新纪元
8、全球首款5G-A车载模组发布!打开万亿车联网市场发展新维度
9、梁文锋署名DeepSeek
发表于 01-16 20:20
DeepSeek开源Engram:让大模型拥有"过目不忘"的类脑记忆
2026年1月13日凌晨,DeepSeek突然发布由创始人梁文锋署名的新论文《Condition
TGV产业发展:玻璃通孔技术如何突破力学瓶颈?
在后摩尔时代,芯片算力提升的突破口已从单纯依赖制程工艺转向先进封装技术。当硅基芯片逼近物理极限,2.5D/3D堆叠技术通过Chiplet(芯粒)拆分与异构集成,成为突破光罩
科普:什么AI 内存技术
问题。 为什么 AI 内存很重要? 在 AI 模型训练和推理过程中,大量的数据需要从内存传输到处理器(如 GPU 或 TPU)进行计算。传统的内存技
【「DeepSeek 核心技术揭秘」阅读体验】+混合专家
感谢电子发烧友提供学习Deepseek核心技术这本书的机会。
读完《Deepseek核心技术揭秘》,我深受触动,对人工智能领域有了全新的认识。了解D
发表于 07-22 22:14
【「DeepSeek 核心技术揭秘」阅读体验】--全书概览
感谢平台提供的书籍,实物如下
这本书主讲从年前开始火热的DeepSeek 。书籍看起来轻薄,但言简意赅,通俗易懂,总览全局,比较精炼。
第一章 介绍DeepSeek的一系列技术突破与创
发表于 07-21 00:04
【「DeepSeek 核心技术揭秘」阅读体验】第三章:探索 DeepSeek - V3 技术架构的奥秘
时间减少,数据处理更流畅。这让我联想到工业生产中的流水线,AI 训练在此处借鉴类似思路,通过优化任务分配和流程,突破硬件限制,追求更高效率,体现了技术发展中持续优化、突破瓶颈的智慧。
发表于 07-20 15:07
【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
这本书有150多页,而且是彩色印刷的,图、表很多而且很有条理性。
书籍前言介绍如下:
第1章 介绍 DeepSeek 的一系列技术突破与创新,如架构创新、训练优化、推理与部署优化等,让读者
发表于 07-17 11:59
【书籍评测活动NO.62】一本书读懂 DeepSeek 全家桶核心技术:DeepSeek 核心技术揭秘
DeepSeek-V3技术突破
DeepSeek-V3 的模型架构整体上基于 Transformer 的 MoE 架构,并在细节实现上做了大量的创新和优化,如大量小专家模型、多头潜在
发表于 06-09 14:38
DeepSeek 引领边缘 AI 芯片向更高性能、更低功耗、更强泛化能力的方向演进
)等优化技术,从而在性能上取得优异表现。但其计算和内存需求也极高:部署原始的大型模型往往需要多卡 GPU 集群(如数十到上百块 H100)才能在
颠覆传统连接认知:M12 航空接头的快速插拔技术革命
M12 航空接头的快速插拔技术,不仅为工业连接带来了颠覆性的变革,更是打开了设备升级发展的全新大门。从智能制造到智慧检测,从交通枢纽到能源工程,这场技术革命正以磅礴之势重塑工业连接的新格局,引领连接领域迈向高效、智能的崭新时代。




评论