好的!对比学习(Contrastive Learning) 是机器学习,特别是无监督学习或自监督学习中的一种常用范式。它的核心思想是通过比较数据样本之间的相似性和差异性来学习有效的特征表示。
以下是关键概念的解释和对比:
核心思想:
- “对比”的含义: 不是单独看一个样本,而是同时看一对(或一组)样本。
- 拉近正样本,推开负样本:
- 正样本: 被认为相似或本质上相同的两个数据点(称为“锚点”和“正样本”)。例如:
- 同一张图片的不同数据增强版本(裁剪、旋转、颜色抖动等)。
- 同一段文本的不同表述(通过回译、掩码预测等生成)。
- 同一段视频的不同帧。
- 同一段音频的不同片段或加噪版本。
- 负样本: 被认为不相似或不同的数据点(相对于锚点)。通常随机选择其他样本(来自同一数据集的任意不同样本)。
- 学习目标: 模型学习将锚点和正样本在特征空间(学习到的向量表示)中拉近(使它们的向量表示更相似),同时将锚点和负样本在特征空间中推开(使它们的向量表示差异更大)。
- 正样本: 被认为相似或本质上相同的两个数据点(称为“锚点”和“正样本”)。例如:
与传统学习范式的对比:
| 特性 | 对比学习 | 监督学习 | 传统无监督学习 |
|---|---|---|---|
| 数据依赖 | 主要依赖未标注数据 (利用数据本身的构造关系) | 依赖大量标注数据 | 依赖未标注数据 |
| 学习信号 | 来自数据内部的关系 (构造的正负样本对) | 来自人工标注的标签 | 通常来自数据本身的结构 (如聚类、重建误差) |
| 核心目标 | 学习通用、可迁移的特征表示 (Encoder的输出) | 学习从输入到特定标签的映射关系 | 发现数据内在结构/模式 (如簇、低维表示) |
| 训练方式 | 最大化正样本对相似度,最小化负样本对相似度 | 最小化预测标签与真实标签的差异 (如交叉熵损失) | 最小化重构误差或最大化簇内相似度等 |
| 典型方法 | SimCLR, MoCo, BYOL, SwAV, CLIP (跨模态) | CNN, Transformer, SVM, 决策树等 | K-Means, PCA/Autoencoder, GAN |
| 优势 | 无需标注数据也能学习强大表示,特征可广泛应用于下游任务 | 在有标注数据充足时性能通常最优,目标明确 | 无需标注,可探索数据结构 |
| 劣势 | 需要精心设计数据增强和正负样本构造策略,计算开销大 | 依赖昂贵的人工标注,标注偏差影响模型,泛化性受限 | 学习到的表示不一定对下游任务友好,目标较模糊 |
为什么对比学习重要?
- 解决标注瓶颈: 高质量的标注数据获取成本高昂且耗时。对比学习利用大量易得的未标注数据学习通用特征,极大降低了对标注数据的依赖。
- 学习到强大的通用表示: 通过在大量数据上进行“对比”训练,模型学习到的特征表示(Encoder 的输出向量)能够捕捉数据内在的本质结构和语义信息。这些表示可以被“冻结”或微调后,迁移到各种下游任务(如图像分类、目标检测、语义分割、文本分类、问答、信息检索等)中,显著提升这些任务的性能和训练效率(迁移学习优势)。
- 对下游任务友好: 对比学习的目标是让相似样本靠近、不相似样本远离,这本身就符合很多判别式任务(如分类、检索)的需求,因此学习到的表示通常在下游任务上表现优异。
- 在自监督学习中扮演核心角色: 对比学习是目前自监督学习领域最成功、应用最广泛的技术路线之一。
关键组件与技术点:
- 数据增强: 是构造高质量正样本对的核心。好的增强策略能产生语义不变但外观变化的样本。
- 编码器: 模型的核心部分(通常是CNN、Transformer等),将输入数据映射到特征向量。对比学习的目标就是优化这个编码器。
- 投影头: 一个小的神经网络模块(通常由几层全连接层组成),接在编码器之后,将编码器输出的特征进一步映射到用于计算对比损失的投影空间。训练完成后通常丢弃投影头,只使用编码器输出的特征。
- 对比损失函数: 衡量锚点与正负样本之间相似度的函数。最常见的是InfoNCE损失。
- 负样本策略:
- 大批量: 一个批次内的其他样本自然作为负样本(如SimCLR)。
- 内存库: 维护一个存储历史特征的内存库来提供负样本(如MoCo)。
- 动量编码器: 使用动量更新的缓慢变化的编码器(EMA)来编码负样本,保持特征一致性(如MoCo)。
应用领域:
- 计算机视觉: 图像分类、目标检测、语义分割、图像检索、视频理解等。
- 自然语言处理: 文本分类、句子/段落相似度计算、语义搜索、问答系统(如Sentence-BERT)。
- 语音处理: 语音识别、说话人识别、语音情感分析。
- 多模态学习: 学习图像和文本的联合嵌入空间(如CLIP),用于跨模态检索、图像描述生成等。
总结:
对比学习是一种 “通过比较来学习” 的范式。它巧妙地利用未标注数据自身构造正样本对和负样本,让模型学会区分什么是相似、什么是不相似,从而在特征空间中将相似的样本聚拢、不相似的样本分离。这种方法克服了对大量标注数据的依赖,能够学习到强大、通用、可迁移的特征表示,是当前自监督学习领域的基石技术,并在计算机视觉、自然语言处理等领域取得了巨大的成功。核心在于 “拉近正对,推远负对”。
对比学习的关键技术和基本应用分析
对比学习的主要思想是相似的样本的表示相近,而不相似的远离。对比学习可以应用于监督和无监督的场景下,并且目前在CV、NLP等领域中取得了较好的性能。本文先对对比学习进行基础介绍,之后会介绍对比学习在NLP和多模态中的应用,欢迎大家批评和交流。
2022-03-09 16:28:46
对比学习中的4种典型范式的应用分析
对比学习是无监督表示学习中一种非常有效的方法,核心思路是训练query和key的Encoder,让这个Encoder对相匹配的query和key生成的编码距离接近,不匹配的编码距离远。想让对比
2022-07-08 11:03:49
上交提出RCLSTR:面向场景文本识别的关系对比学习

基于MoCo[3]的框架,该文提出了用于文本识别的关系对比学习框架(RCLSTR)。如下图所示:1、在Online分支(上半部分)中引入了一个新的重排阶段,从原始分支中产生水平重排的图像,称为关系正则化模块(Relational Regularization)。
2023-09-14 17:21:57
TPAMI 2023 | 用于视觉识别的相互对比学习在线知识蒸馏

本次文章介绍我们于 TPAMI-2023 发表的一项用于视觉识别的相互对比学习在线知识蒸馏(Online Knowledge Distillation via Mutual Contrastive
2023-09-19 10:00:04
结合句子间差异的无监督句子嵌入对比学习方法-DiffCSE
句向量表征技术目前已经通过对比学习获取了很好的效果。而对比学习的宗旨就是拉近相似数据,推开不相似数据,有效地学习数据表征。SimCSE方法采用dropout技术,对原始文本进行数据增强,构造出正样本,进行后续对比学习训练,取得了较好的效果;
2022-05-05 11:35:56
大模型Reward Model的trick应用技巧

借助对比学习和元学习的方法。增加对比学习的loss,对比学习通过增强模型区分能力,来增强RM的对好坏的区分水平。元学习则使奖励模型能够维持区分分布外样本的细微差异,这种方法可以用于迭代式的RLHF优化。
2024-01-25 09:31:54
PiCO核心点—对比学习引入PLL
有监督学习是最常见的一种机器学习问题,给定一个输入样本,预测该样本的label是什么。Partial Label Learning(PLL)问题也是预测一个样本对应的label,但是和有监督学习问题的差异是
2022-08-22 11:35:57
多模态大模型最全综述来了!

其中最后一个表示监督信号是从图像本身中挖掘出来的,流行的方法包括对比学习、非对比学习和masked image建模。在这些方法之外,文章也进一步讨论了多模态融合、区域级和像素级图像理解等类别的预训练方法。
2023-09-26 16:42:17
如何通过多模态对比学习增强句子特征学习
视觉作为人类感知体验的核心部分,已被证明在建立语言模型和提高各种NLP任务的性能方面是有效的。作者认为视觉作为辅助语义信息可以进一步促进句子表征学习。
2022-09-21 10:06:17
对比学习在开放域段落检索和主题挖掘中的应用
开放域段落检索是给定一个由数百万个段落组成的超大文本语料库,其目的是检索一个最相关的段落集合,作为一个给定问题的证据。密集检索已成为开放域段落检索的重要有效方法。典型的密集检索器通常采用双编码器结构,双编码器受制于单向量表示,面临表示能力的上界。
2022-08-17 15:18:32
自步对比学习框架及混合记忆模型

在基于聚类的伪标签法中,往往没有用到全部的目标域无标签数据,因为基于密度的聚类(如DBSCAN等)本身会产生聚类离群值(outlier),这些聚类离群值由于无法分配伪标签,所以被丢弃,不用于训练。
2020-11-03 09:33:45
为什么不同模态的embedding在表征空间中形成不同的簇
文中将一些经典的多模态对比学习模型中两个模态的embedding,通过降维等方法映射到二维坐标系中。
2022-12-05 14:06:27
最新3D表征自监督学习+对比学习:FAC

第二个是我们防止 3D 片段/对象之间的过度判别,并通过 Siamese 对应网络中的自适应特征学习鼓励片段级别的前景到背景的区别,该网络有效地自适应地学习点云视图内和点云视图之间的特征相关性。
2023-05-17 09:28:17
通过对比学习的角度来解决细粒度分类的特征质量问题

一、本文贡献 1.网络通过提取显著性区域并融合这些区域特征,以同时学习局部和全局的特征2.通过混杂来自负例的注意力特征来增强网络对于每个注意力区域的学习3.网络得到了 SOTA 的结果 二、动机
2022-05-13 16:54:06
一种基于prompt和对比学习的句子表征学习模型
我们发现prompt,再给定不同的template时可以生成不同方面的positive pair,且避免embedding bias。
2022-10-25 09:37:32
如何利用CLIP 的2D 图像-文本预习知识进行3D场景理解

自我监督学习的目的是获得有利于下游任务的良好表现。主流的方法是使用对比学习来与训练网络。受CLIP成功的启发,利用CLIP的预训练模型来完成下游任务引起了广泛的关注。本文利用图像文本预先训练的CLIP知识来帮助理解3D场景。
2023-10-29 16:54:09
光控开关暗通/亮通电路原理图 基于555芯片的光控开关电路设计

前面我们已经介绍过光控开关的电路 了,但是没有讲过加入555芯片控制的光控电路;今天我们讲解两款功能一样、 状态相反的光控开关电路。在学习过程中,可以对照之前的电路,找出相同点及不同点对比学习,效果会更好。本电路比较简单,好学易上手。
2023-07-20 15:15:59
稠密向量检索的Query深度交互的文档多视角表征
今天给大家带来一篇北航和微软出品的稠密向量检索模型Dual-Cross-Encoder,结合Query生成和对比学习技术,将文档与生成的不同伪query进行深度交互学习构建文档的不同视角的表征向量,再与Query向量进行稠密向量检索。
2022-08-18 15:37:33

基于使用对比学习和条件变分自编码器的新颖框架ADS-Cap
在本文中,我们研究了图像描述(Image Captioning)领域一个新兴的问题——图像风格化描述(Stylized Image Captioning)。
2022-11-03 14:30:11
STM32第一周复习 精选资料分享
熟练掌握一种开发环境库函数和寄存器对比学习入门一款单片机的学习目标基本外设GPIO输入输出,外部中断定时器串口基本外设接口SPIIICWDGFSMCADC/DAC...
![]() 冰箱洗衣机
2021-08-23 08:39:51
冰箱洗衣机
2021-08-23 08:39:51
CLIP-Chinese:中文多模态对比学习预训练模型
CLIP模型主要由文本编码器和图片编码器两部分组成,训练过程如下图所示。对于batch size为N的图文对数据,将N个图片与N个文本分别使用图片编码器和文本编码器进行编码,并且映射到同一个向量空间。然后分别计算两两图文对编码的点乘相似度,这样就能得到一个N*N的相似度矩阵。
2022-12-06 14:49:51
一种缓解负采样偏差的对比学习句表示框架DCLR
近年来,预训练语言模型在各种 NLP 任务上取得了令人瞩目的表现。然而,一些研究发现,由预训练模型得出的原始句表示相似度都很高,在向量空间中并不是均匀分布的,而是构成了一个狭窄的锥体,这在很大程度上限制了句表示的表达能力。
2022-06-07 09:54:56
浅析MAK基于开放世界取样提升不平衡对比学习
我们可能从一个bias的sample set开始训练,由于不知道相应的标注,传统用来处理不平衡数据集的方法,如伪标签、重采样或重加权不适用。
2022-12-02 09:46:53
基于Matlab的小型电力系统的建模与仿真
,它的突出优点是可行、简便、经济的。本实验目的是通过MATLAB 的simulink环境对一个典型的工厂供电系统进行仿真,以熟悉供电系统在发生各种短路故障时的分析方法并与课堂知识进行对比学习。二、预习与思...
![]() wanyou2345
2021-07-12 08:04:58
wanyou2345
2021-07-12 08:04:58
通过Token实现多视角文档向量表征的构建
该篇论文与前两天分享的DCSR-面向开放域段落检索的句子感知的对比学习一文有异曲同工之妙,都是在检索排序不引入额外计算量的同时,通过插入特殊Token构建长文档的多语义向量表征,使得同一文档可以与多种不同问题的向量表征相似。
2022-07-08 11:13:03
预训练语言模型的字典描述
今天给大家带来一篇IJCAI2022浙大和阿里联合出品的采用对比学习的字典描述知识增强的预训练语言模型-DictBERT,全名为《Dictionary Description Knowledge
2022-08-11 10:37:55
22nm平面工艺流程介绍

今天分享另一篇网上流传很广的22nm 平面 process flow. 有兴趣的可以与上一篇22nm gate last FinFET process flow 进行对比学习。 言归正传,接下来介绍平面工艺最后一个节点22nm process flow。
2023-11-28 10:45:51
触摸电子开关电路原理图 三极管延时开关电路原理图
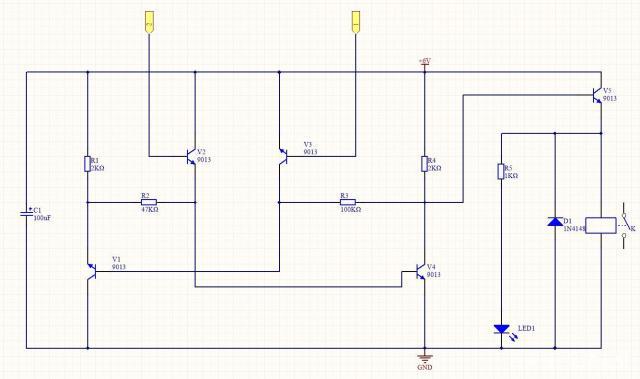
前面介绍了几种光控开关电路,都用到了继电器,现在再介绍两种开关电路,分别是是触摸电子开关电路和三极管延时开关电路,也用到了继电器,小伙伴们可以进行对比学习一下。
2023-07-20 15:16:15
利用Contrastive Loss(对比损失)思想设计自己的loss function
在非监督学习时,对于一个数据集内的所有样本,因为我们没有样本真实标签,所以在对比学习框架下,通常以每张图片作为单独的语义类别,并假设:同一个图片做不同变换后不改变其语义类别,比如一张猫的图片,旋转或局部图片都不能改变其猫的特性。
2023-03-22 10:03:09
 工商网监
工商网监


