 一种基于prompt和对比学习的句子表征学习模型
一种基于prompt和对比学习的句子表征学习模型

虽然BERT等语言模型有很大的成果,但在对句子表征方面(sentence embeddings)上表现依然不佳,因为BERT存在 sentence bias 、 anisotropy 问题;
我们发现prompt,再给定不同的template时可以生成不同方面的positive pair,且避免embedding bias。
相关工作
Contrastive Learning(对比学习) 可以利用BERT更好地学习句子表征。其重点在于如何寻找正负样本。例如,使用inner dropout方法构建正样本。
现有的研究表明,BERT的句向量存在一个 坍缩现象 ,也就是句向量受到高频词的影响,进而坍缩在一个凸锥,也就是各向异性,这个性质导致度量句子相似性的时候存在一定的问题,这也就是 anisotropy 问题。
发现
(1)Original BERT layers fail to improve the performance.
对比两种不同的sentence embedding方法:
对BERT的输入input embedding进行平均;
对BERT的输出(last layer)进行平均
评价两种sentence embedding的效果,采用sentence level anisotropy评价指标:
anisotropy :将corpus里面的sentence,两两计算余弦相似度,求平均。
对比了不同的语言模型,预实验如下所示:
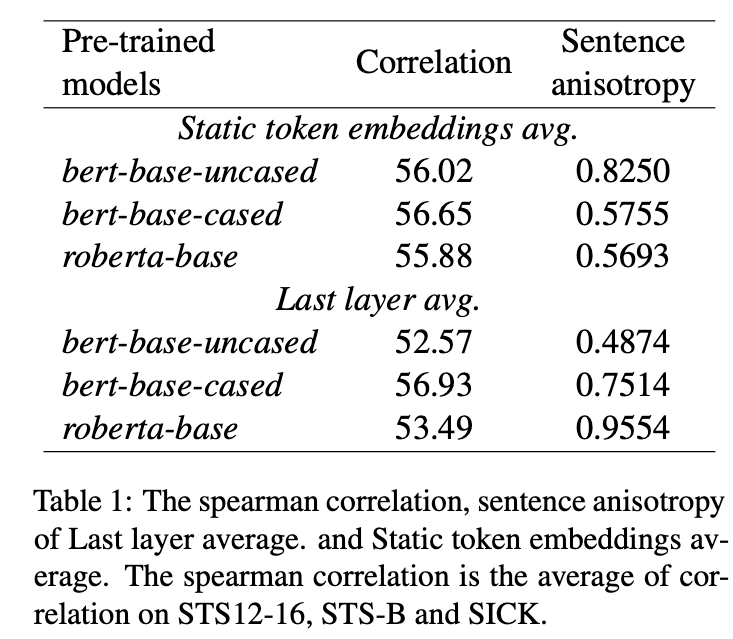
从上表可以看出,貌似anisotropy对应的spearman系数比较低,说明相关性不大。比如bert-base-uncased,
可以看出static token embedding的anisotropy很大,但是最终的效果也差不多。
(2)Embedding biases harms the sentence embeddings performance.
token embedding会同时受到token frequency和word piece影响
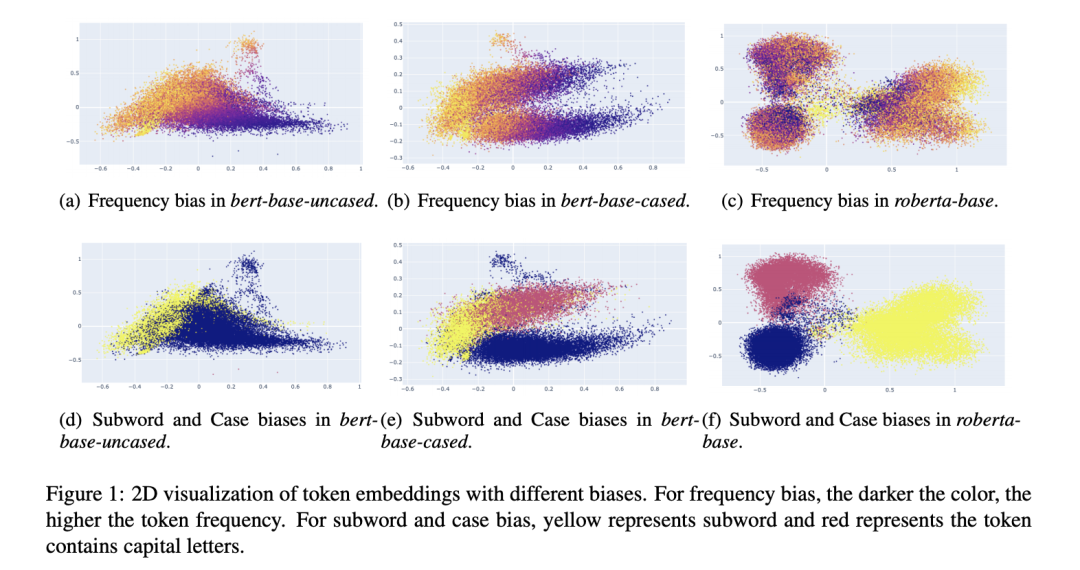
不同的语言模型的token embedding高度受到词频、subword的影响;
通过可视化2D图,高频词通常会聚在一起,低频词则会分散
For frequency bias, we can observe that high fre- quency tokens are clustered, while low frequency tokens are dispersed sparsely in all models (Yan et al., 2021). The begin-of-word tokens are more vulnerable to frequency than subword tokens in BERT. However, the subword tokens are more vul- nerable in RoBERTa.
三、方法
如何避免BERT在表征句子时出现上述提到的问题,本文提出使用Prompt来捕捉句子表征。但不同于先前prompt的应用(分类或生成),我们并不是获得句子的标签,而是获得句子的向量,因此关于prompt-based sentence embedding,需要考虑两个问题:
如何使用prompt表征一个句子;
如何寻找恰当的prompt;
本文提出一种基于prompt和对比学习的句子表征学习模型。
3.1 如何使用prompt表征一个句子
本文设计一个template,例如“[X] means [MASK]”,[X] 表示一个placehoder,对应一个句子,[MASK]则表示待预测的token。给定一个句子,并转换为prompt后喂入BERT中。有两种方法获得该句子embedding:
方法一:直接使用[MASK]对应的隐状态向量:;
方法二:使用MLM在[MASK]位置预测topK个词,根据每个词预测的概率,对每个词的word embedding进行加权求和来表示该句子:
方法二将句子使用若干个MLM生成的token来表示,依然存在bias,因此本文只采用第一种方法
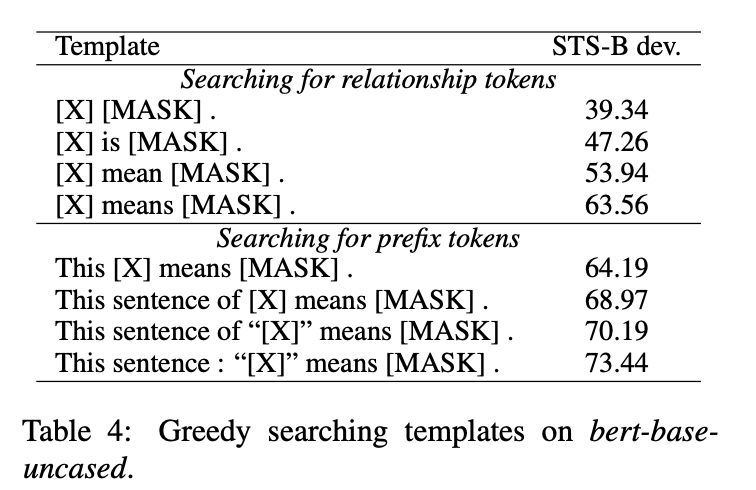
3.2 如何寻找恰当的prompt
关于prompt设计上,可以采用如下三种方法:
manual design:显式设计离散的template;
使用T5模型生成;
OptiPrompt:将离散的template转换为continuous template;
3.3 训练
采用对比学习方法,对比学习中关于positive的选择很重要,一种方法是采用dropout。本文采用prompt方法,为同一个句子生成多种不同的template,以此可以获得多个不同的positive embedding。
The idea is using the different templates to repre- sent the same sentence as different points of view, which helps model to produce more reasonable pos- itive pairs.
为了避免template本身对句子产生语义上的偏向。作者采用一种trick:
喂入含有template的句子,获得[MASK]对应的embedding ;
只喂入template本身,且template的token的position id保留其在原始输入的位置,此时获得[MASK]对应的embeding:
最后套入对比学习loss中进行训练:
四、实验
作者在多个文本相似度任务上进行了测试,实验结果如图所示:
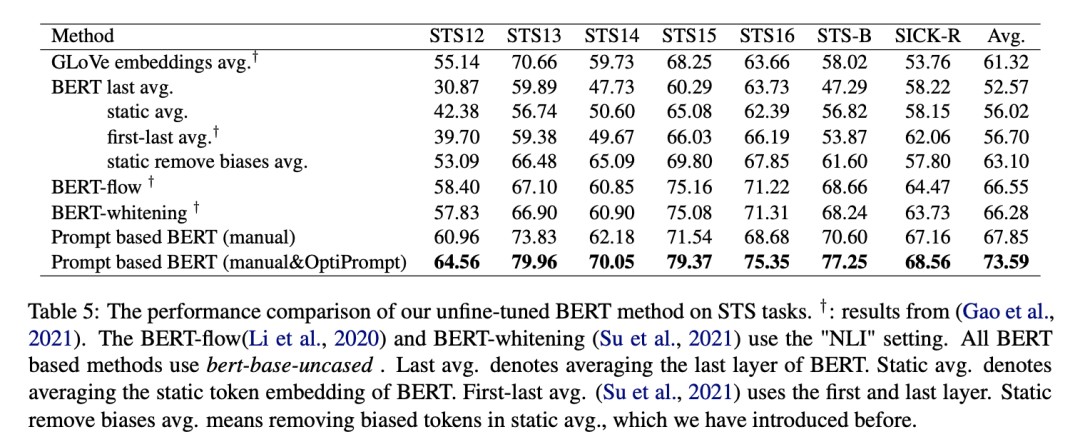
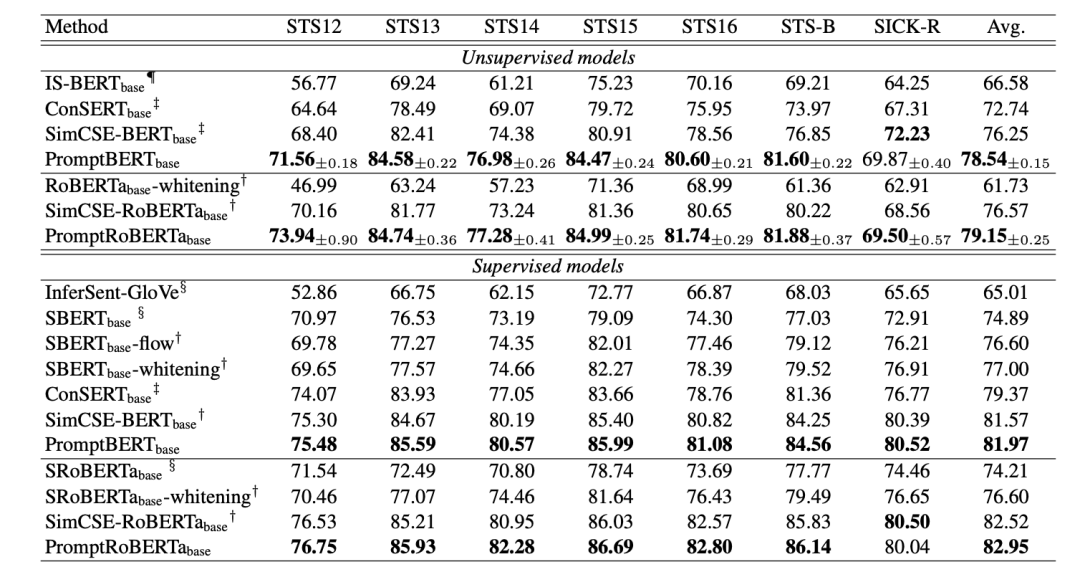
惊奇的发现,PromptBERT某些时候竟然比SimCSE高,作者也提出使用对比学习,也许是基于SimCSE之上精细微调后的结果。
审核编辑:刘清
-
语言模型
+关注
关注
0文章
575浏览量
11373
原文标题:Prompt+对比学习,更好地学习句子表征
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一种改进的句子相似度计算模型
一种新的目标分类特征深度学习模型
深度学习模型介绍,Attention机制和其它改进
语义表征的无监督对比学习:一个新理论框架
一种新型的AI模型可以提升学生的学习能力
一种注意力增强的自然语言推理模型aESIM

一种基于间隔准则的多标记学习算法
一种可分享数据和机器学习模型的区块链

一种基于排序学习的软件众包任务推荐方法




评论