 上交提出RCLSTR:面向场景文本识别的关系对比学习
上交提出RCLSTR:面向场景文本识别的关系对比学习

本文简单介绍ACMMM2023录用的论文“Relational Contrastive Learning for Scene Text Recognition”的主要工作。该论文主要研究了基于对比学习的文本识别自监督方法。文章受到基于上下文感知方法在文字监督学习中取得的巨大成功[1],利用文本和背景的异质性,将文字的上下文信息理解为文本基元的关系,为表征学习提供有效的自监督标签。但是由于词汇依赖[2],文本关系被限制在有限的数据集中,这可能导致过拟合并损害表征的鲁棒性。因此,该文提出通过重排、分层和交互来丰富文本关系,并设计了一个统一的框架RCLSTR: Relational Contrastive Learning for Scene Text Recognition。实验表明,该方法能够有效提升对比学习文本识别的自监督性能。
一、背景介绍
场景文本图像的特点与自然图像有很大的不同。首先,前景(文本)和背景是异构的,文本识别主要依赖于文本而不是背景。第二,大部分文本图像通常具有从左到右的结构。第三,文本图像包含了字符序列和多粒度的结构。先前的文本自监督方法主要是从自然图像迁移而来的,仅仅探索了文本的部分特点。该文章启发于上下文感知方法在文字监督学习中的成功应用,在自监督对比学习中充分探索文本的特点。提出通过重排、分层和交互来丰富文本关系,从而形成更完整的对比学习机制。

如上图所示,首先,对于“重排”,文本图像可以被分割并重新排列成新的上下文关系,该文设计了一个重排模块来生成新的单词图像,丰富了文本关系的多样性。第二,对于“分层”,由于文本图像中存在词、子词、字符等多个不同粒度的对象,提出了一种分层结构在多个层级上进行表征学习,从而丰富语义信息,增强表征的鲁棒性。第三,对于“交互”,利用不同层级对象之间的交互,例如字符-子词和子词-词相似度,约束不同层级上语义相似性的一致性,从而促进学习高质量的表征。
二、方法介绍
基于MoCo[3]的框架,该文提出了用于文本识别的关系对比学习框架(RCLSTR)。如下图所示:1、在Online分支(上半部分)中引入了一个新的重排阶段,从原始分支中产生水平重排的图像,称为关系正则化模块(Relational Regularization)。2、文章设计了一个分层结构来学习每一层内部的关系,称为分层关系模块(Hierarchical Relation)。3、提出了一个跨层次关系一致性模块(Cross-Hierarchy Relational Consistency),以便网络学习层级之间的关系。
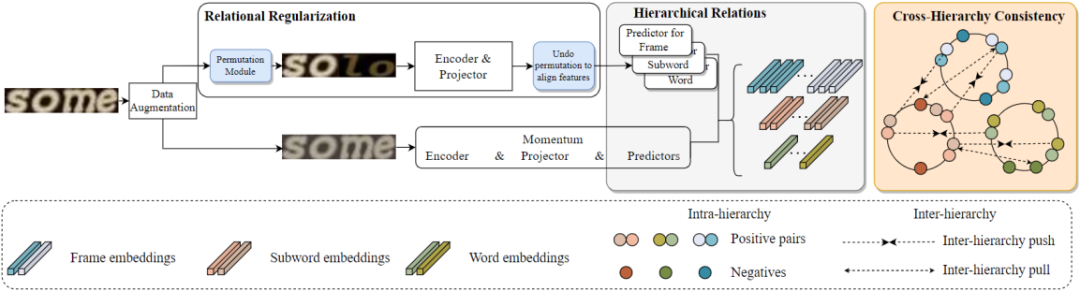
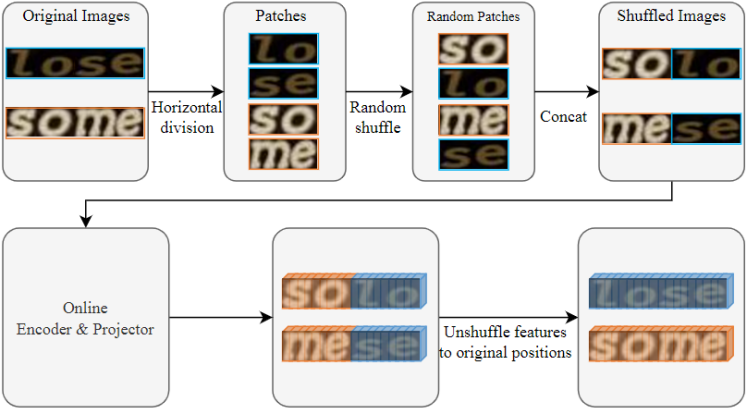
对于Relational Regularization,该文提出了一个重排模块来生成新的文本图像,生成的图像包含更多的上下文关系。如下图所示,该模块将文本图像水平划分为几个片段,然后随机打乱,重新连接片段后生成重排后的图像。重排后的图像经过Online编码器和投影层后得到对应特征,然后将特征复位到原始图片中的位置。
文章分别计算了原始特征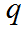 和正则化特征
和正则化特征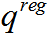 (对应于重新排列的图像)上的对比损失,然后将两者求和得到:
(对应于重新排列的图像)上的对比损失,然后将两者求和得到:
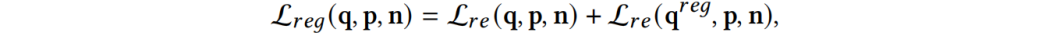
对于Hierarchical Relation,考虑到文本在水平方向上具有不同的粒度,该文提出了一种分层的对比学习结构,通过不同粒度的池化层将特征映射到帧、子词和词三个层次,然后进行分层级的关系对比学习,每个层级计算对比损失(上标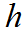 指代帧、子词和词三个层级),并求和得到:
指代帧、子词和词三个层级),并求和得到:
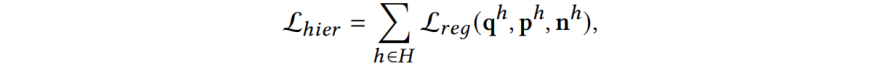
对于Cross-Hierarchy Relational Consistency,提出一致性约束来学习相邻层之间的关系,实现帧-子词和子词-词之间的一致性约束。对于帧-子词关系,由于来自相同空间位置(在同一图像中)的帧和子词特征在特征空间中表现出更高的相似性,因此将其视为正样本对,将其他位置的特征视为负样本对,子词-词之间的正负对关系类似。该模块通过KL损失来约束相似度分布之间的一致性:
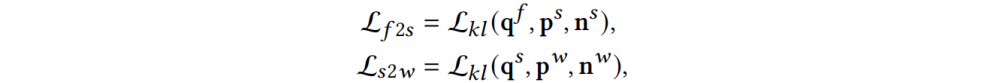
其中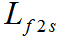 表示帧-子词一致性损失,
表示帧-子词一致性损失,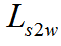 表示子词-词一致性损失。最后总的损失函数为正则化的多层级损失和跨层级损失求和:
表示子词-词一致性损失。最后总的损失函数为正则化的多层级损失和跨层级损失求和:
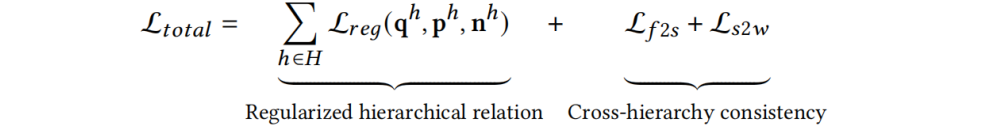
三、实验结果
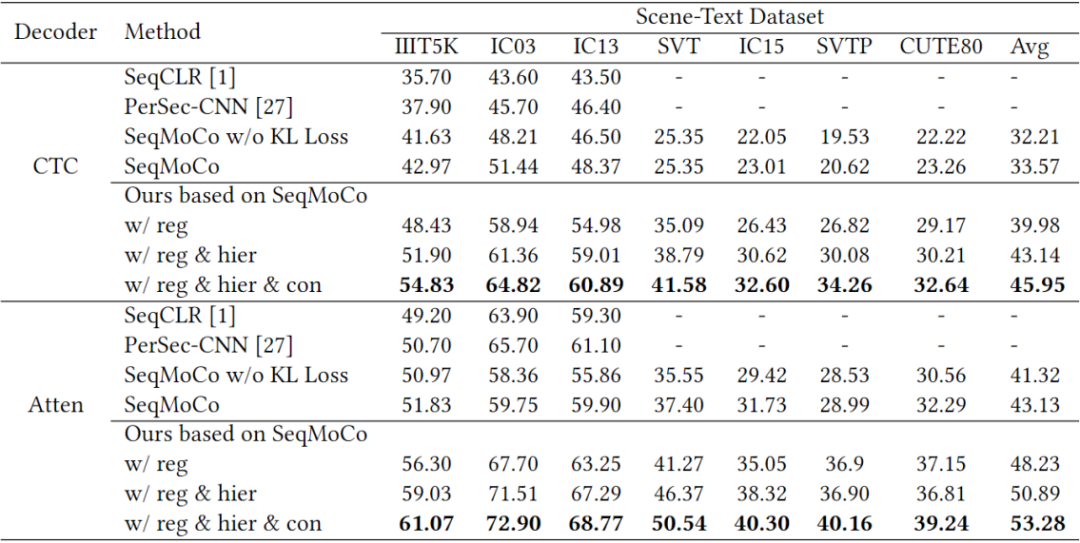
表征质量的结果如下表所示,与SeqMoCo的baseline相比,加入三个主要模块后,基于CTC的解码器性能平均提高了+12.38%,基于注意力的解码器平均提高了+10.15%。同时,该表也展示了三个关键模块各自的有效性。
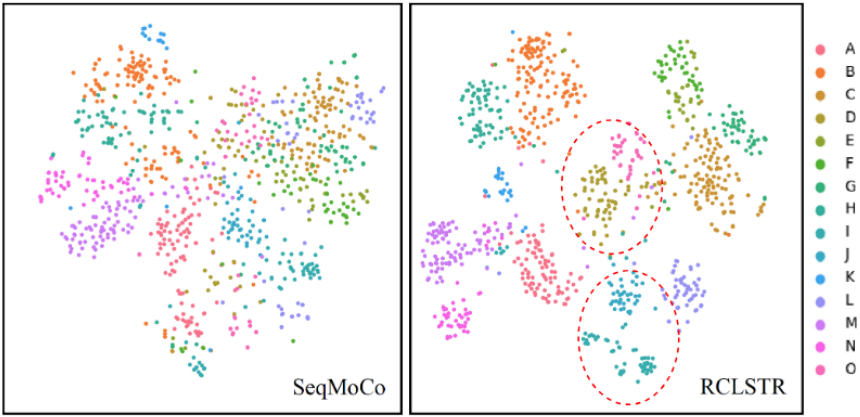
下图是使用t-SNE[4]将IIIT5K[5]数据集图像特征可视化的结果,对应于SeqMoCo(Baseline)和该文的方法RCLSTR。可以看出,RCLSTR方法能更好地挖掘字符关系,对应相同类别的字符特征能够更好地成簇。
四、总结
该工作提出了一个新的场景文本识别的关系对比学习框架(RCLSTR)。在这个框架中,通过三个模块对文本图像之间的关系进行了充分的探讨。提出了Relational Regularization模块,以丰富图像内部和图像间的上下文关系。同时设计了用于关系对比学习的Hierarchical Relation模块,在不同粒度上进行分层级对比学习。此外,针对场景文本图像中不同层次的交互,设计了Cross-Hierarchy Relational Consistency模块。实验结果表明该方法能够有效提升对比学习文本识别的自监督性能。
-
解码器
+关注
关注
9文章
1226浏览量
43855 -
模块
+关注
关注
7文章
2856浏览量
53547 -
数据集
+关注
关注
4文章
1242浏览量
26310
原文标题:ACM MM 2023 | 上交提出RCLSTR:面向场景文本识别的关系对比学习
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
请问instaspin foc识别的参数跟注入电流大小关系比较大怎么处理?
基于面向文本标题的任务关系抽取
面向人体动作识别的随机增量型混合学习机模型

面向实体识别的聚类算法
如何使用EAST文本检测器在自然场景下检测文本
语音识别的应用场景

浅谈面向人脸表情识别的双模板稀疏分类方法
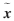
面向网络攻击识别的威胁情报画像分析方法
机器视觉与生物特征识别的关系
小模型也能进行上下文学习!字节&华东师大联合提出自进化文本识别器




评论