 结合句子间差异的无监督句子嵌入对比学习方法-DiffCSE
结合句子间差异的无监督句子嵌入对比学习方法-DiffCSE

写在前面
今天分享给大家一篇NAACL2022论文,结合句子间差异的无监督句子嵌入对比学习方法-DiffCSE,全名《DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings》。该篇论文主要是在SimCSE上进行优化,通过ELECTRA模型的生成伪造样本和RTD(Replaced Token Detection)任务,来学习原始句子与伪造句子之间的差异,以提高句向量表征模型的效果。
paper:https://arxiv.org/pdf/2204.10298.pdf
github:https://github.com/voidism/DiffCSE
介绍
句向量表征技术目前已经通过对比学习获取了很好的效果。而对比学习的宗旨就是拉近相似数据,推开不相似数据,有效地学习数据表征。SimCSE方法采用dropout技术,对原始文本进行数据增强,构造出正样本,进行后续对比学习训练,取得了较好的效果;并且在其实验中表明”dropout masks机制来构建正样本,比基于同义词或掩码语言模型的删除或替换等更复杂的增强效果要好得多。“。这一现象也说明,「直接增强(删除或替换)往往改变句子本身语义」。
paper:https://aclanthology.org/2021.emnlp-main.552.pdf
github:https://github.com/princeton-nlp/SimCSE
论文解读:https://zhuanlan.zhihu.com/p/452761704
Dangovski等人发现,在图像上,采用不变对比学习和可变对比学习相互结合的方法可以提高图像表征的效果。而采用不敏感的图像转换(如,灰度变换)进行数据增强再对比损失来改善视觉表征学习,称为「不变对比学习」。而「可变对比学习」,则是采用敏感的图像转换(如,旋转变换)进行数据增强的对比学习。如下图所示,做左侧为不变对比学习,右侧为可变对比学习。对于NLP来说,「dropout方法」进行数据增强为不敏感变化,采用「词语删除或替换等」方法进行数据增强为敏感变化。
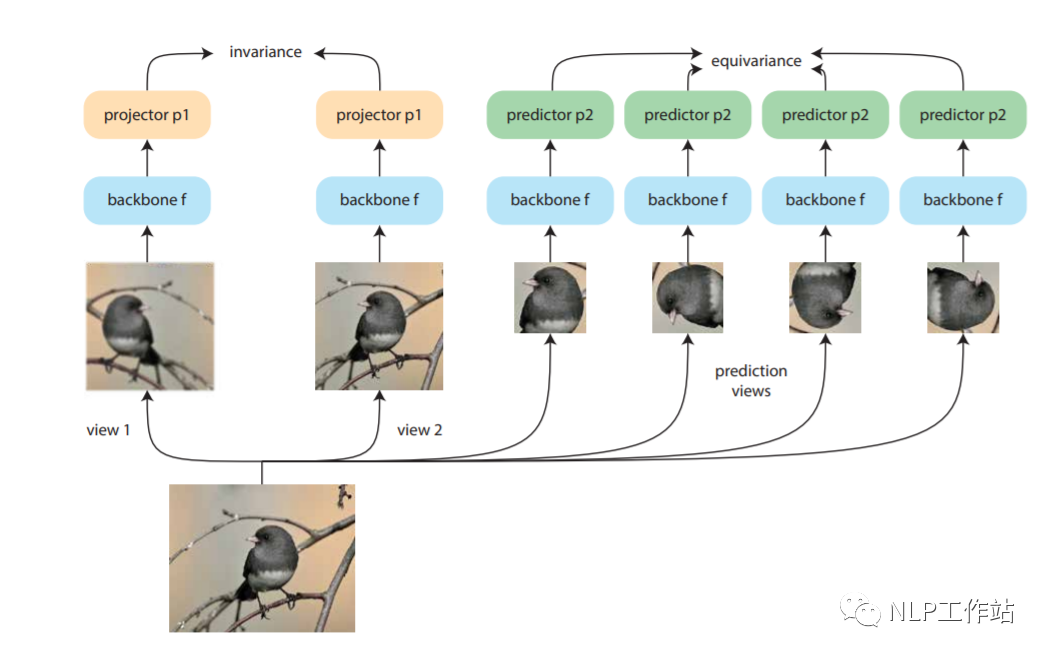
paper:https://arxiv.org/pdf/2111.00899.pdf
作者借鉴Dangovski等人在图像上的做法,提出来「DiffCSE方法」,通过使用基于dropout masks机制的增强作为不敏感转换学习对比学习损失和基于MLM语言模型进行词语替换的方法作为敏感转换学习「原始句子与编辑句子」之间的差异,共同优化句向量表征。
模型
模型如下图所示,
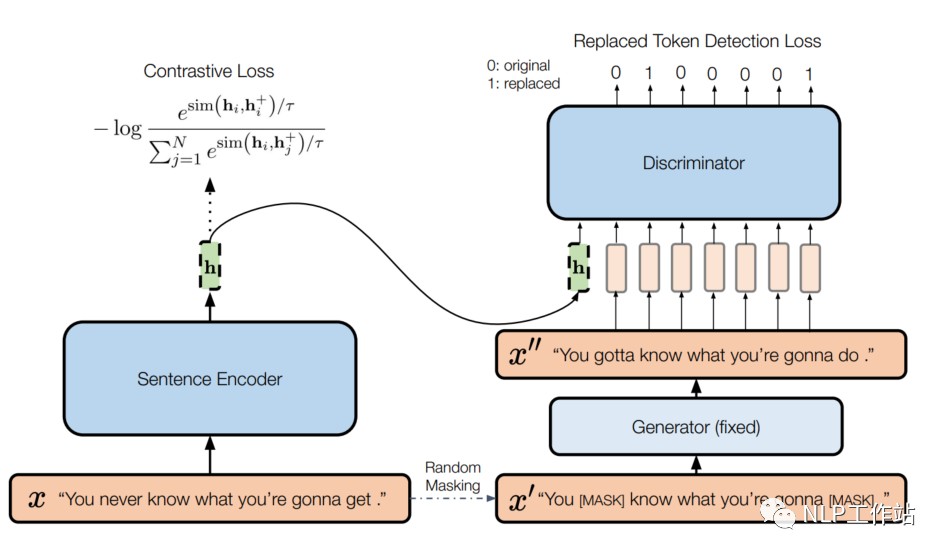
左侧为一个标准的SimCSE模型,右侧为一个带条件的句子差异预测模型。给定一个句子,SimCSE模型通过dropout机制构造一个正例,使用BERT编码器f,获取句向量,SimCSE模型的训练目标为:
其中,为训练输入batch大小,为余弦相似度,为温度参数.
右侧实际上是ELECTRA模型,包含生成器和判别器。给定一个长度为T的句子,,生成一个随机掩码序列,其中。使用MLM预训练语言模型作为生成器G,通过掩码序列来生成句子中被掩掉的token,获取生成序列。然后使用判别器D进行替换token检测,也就是预测哪些token是被替换的。其训练目标为:
针对一个batch的训练目标为。
最终将两个loss通过动态权重将其结合,
为了使判别器D的损失可以传播的编码器f中,将句向量拼接到判别器D的输入中,辅助进行RTD任务,这样做可以鼓励编码器f使信息量足够大,从而使判别器D能够区分和之间的微小差别。
当训练DiffCSE模型时,固定生成器G参数,只有句子编码器f和鉴别器D得到优化。训练结束后,丢弃鉴别器D,只使用句子编码器f提取句子嵌入对下游任务进行评价。
结果&分析
在句子相似度任务以及分类任务上的效果,如下表1和表2所示,相比与SimCSE模型均有提高,
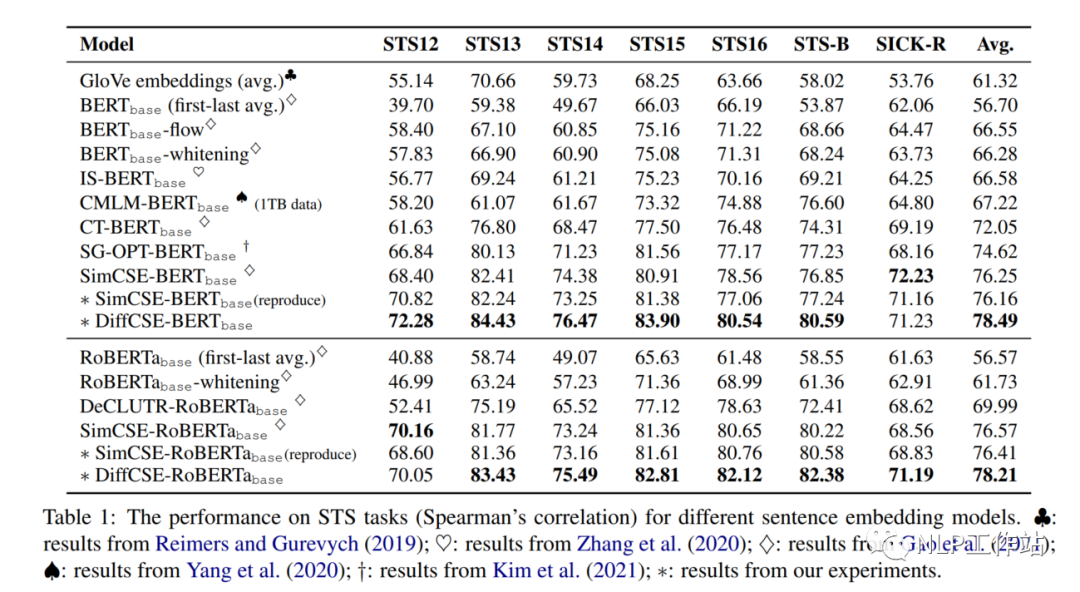
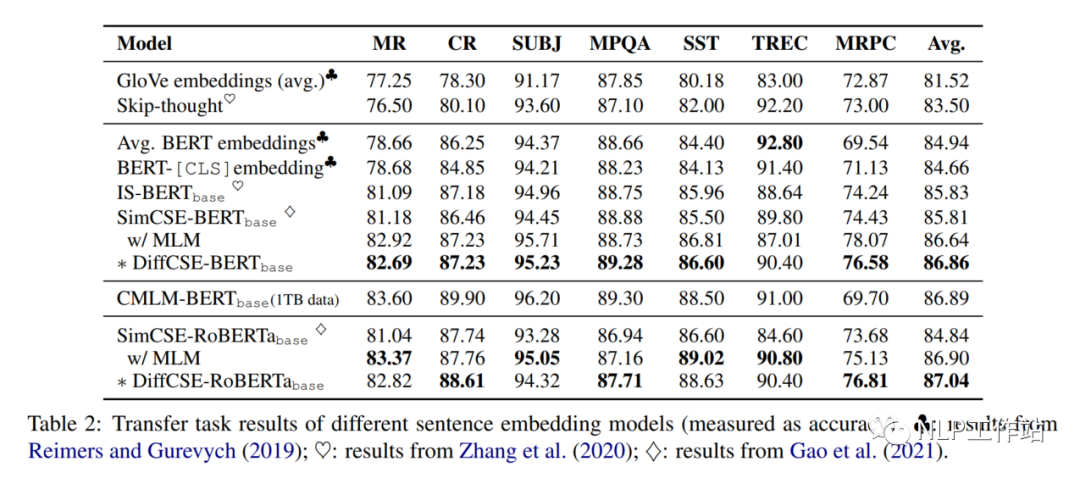
为了验证DiffCSE模型具体是哪个部分有效,进行以下消融实验。
Removing Contrastive Loss
如表3所示,当去除对比学习损失,仅采用RTD损失时,在句子相似度任务上,下降30%,在分类任务上下降2%。
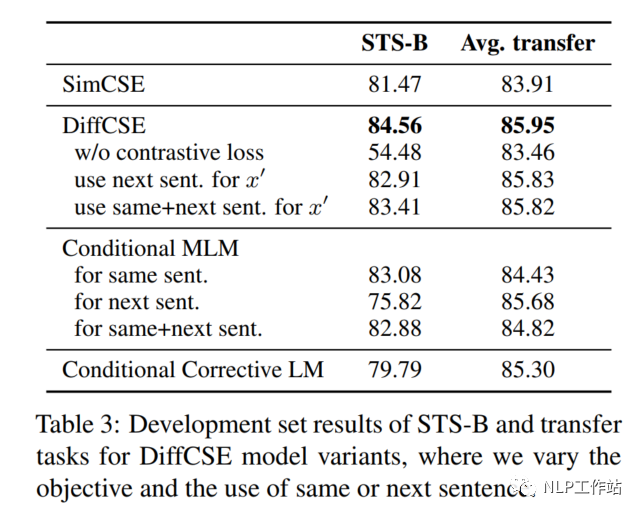
Next Sentence vs. Same Sentence
如表3所示,当将同句话预测任务,变成预测下句话任务时,在句子相似度任务和分类任务上,具有不同程度的下降。
Other Conditional Pretraining Tasks
DiffCSE模型采用MLM模型和LM模型分别作为生成器时,效果如表3所示,在句子相似度任务和分类任务上,具有不同程度的下降。句子相似度任务上下降的较为明显。
Augmentation Methods: Insert/Delete/Replace
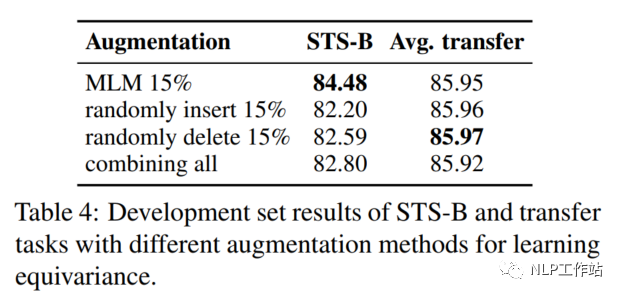
将MLM模型生成伪造句换成随机插入、随机删除或随机替换的效果,如表示所4,MLM模型的效果综合来说较为优秀。
Pooler Choice
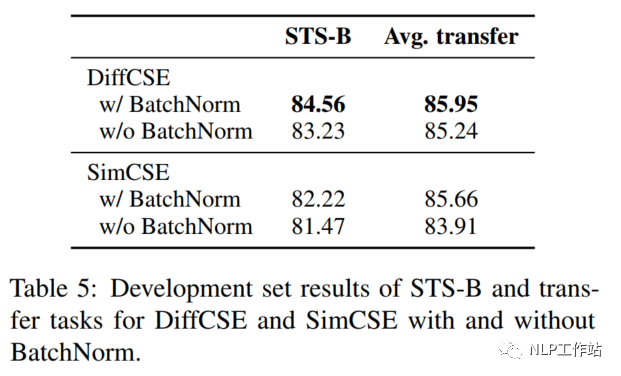
在SimCSE模型中,采用pooler层(一个带有tanh激活函数的全连接层)作为句子向量输出。该论文实验发现,采用带有BN的两层pooler效果更为突出,如表5所示;并发现,BN在SimCSE模型上依然有效。
代码如下:
classProjectionMLP(nn.Module):
def__init__(self,config):
super().__init__()
in_dim=config.hidden_size
hidden_dim=config.hidden_size*2
out_dim=config.hidden_size
affine=False
list_layers=[nn.Linear(in_dim,hidden_dim,bias=False),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(inplace=True)]
list_layers+=[nn.Linear(hidden_dim,out_dim,bias=False),
nn.BatchNorm1d(out_dim,affine=affine)]
self.net=nn.Sequential(*list_layers)
defforward(self,x):
returnself.net(x)
Size of the Generator
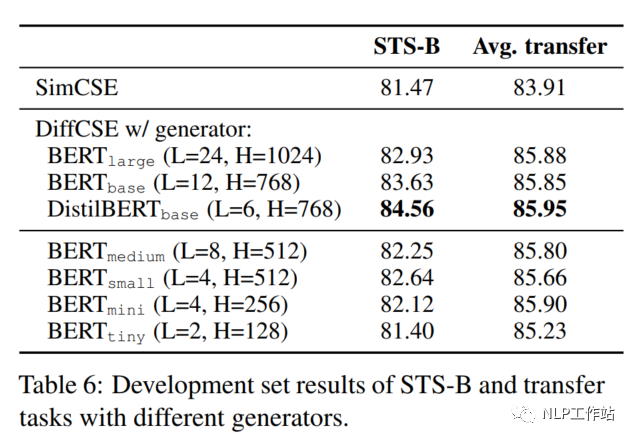
在DiffCSE模型中,尝试了不同大小的生成器G,如下表所示,DistilBERTbase模型效果最优。并且发现与原始ELECTRA模型的结论不太一致。原始ELECTRA认为生成器的大小在判别器的1/4到1/2之间效果是最好的,过强的生成器会增大判别器的难度。而DiffCSE模型由于融入了句向量,导致判别器更容易判别出token是否被替换,所以生成器的生成能力需要适当提高。
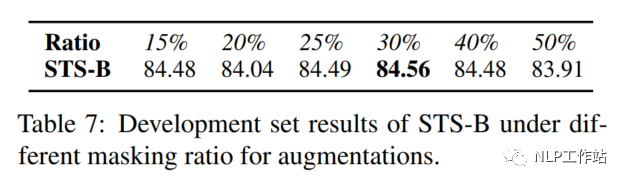
Masking Ratio
对于掩码概率,经实验发现,在掩码概率为30%时,模型效果最优。
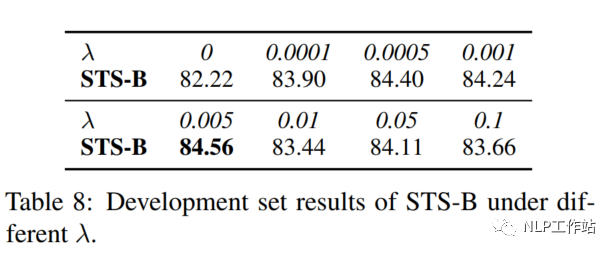
Coefficient λ
针对两个损失之间的权重值,经实验发现,对比学习损失为RTD损失200倍时,模型效果最优。
总结
个人觉得这篇论文的主要思路还是通过加入其他任务,来增强句向量表征任务,整体来说挺好的。但是该方法如何使用到监督学习数据上,值得思考,欢迎留言讨论。
-
数据
+关注
关注
8文章
7363浏览量
95158 -
生成器
+关注
关注
7文章
322浏览量
22853 -
向量
+关注
关注
0文章
55浏览量
12078
原文标题:DiffCSE:结合句子间差异的无监督句子嵌入对比学习方法
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
无源TSV转接板的制作方法

无铅焊接下,低TG与高TG板材表现差异全解析
无源探头与有源探头的安全性差异解析

【EMC标准分析】GB_T 18655最新2025版与2018版的标准差异对比

有铅VS无铅:PCBA加工工艺的6大核心差异,工程师必看
基于线电压差反电势过零检测的无刷直流电机驱动器
MSCMG无刷直流电机改进的I_f无位置起动方法
基于线电压差反电势过零检测的无刷直流电机驱动器
MSCMG无刷直流电机改进的I_f无位置起动方法
ARM入门学习方法分享
英语单词学习页面+单词朗读实现 -- 【1】页面实现 ##HarmonyOS SDK AI##
无刷直流电机单神经元自适应智能控制系统
机器学习异常检测实战:用Isolation Forest快速构建无标签异常检测系统

第一章 W55MH32 高性能以太网单片机的学习方法概述




评论