 电子发烧友App
电子发烧友App


前言
如今的大模型被应用在各个场景,其中有些场景则需要模型能够支持处理较长文本的能力(比如8k甚至更长),其中已经有很多开源或者闭源模型具备该能力比如GPT4、Baichuan2-192K等等。
那关于LLM的长文本能力,目前业界通常都是怎么做的?有哪些技术点或者方向?今天我们就来总结一波,供大家快速全面了解。
当然也有一些关于LLM长文本的综述,感兴趣的小伙伴可以看看,比如:
《Advancing Transformer Architecture in Long-Context Large Language Models: A Comprehensive Survey》:https://arxiv.org/pdf/2311.12351.pdf
今天我们会从如下几个层面进行介绍::数据层面、模型层面、评估层面。每个层面挑几个还不错的工作浅浅学一下业界都是怎么做的。
全文涉及较多工作,建议收藏,方便后续查询细读或者下载数据。
数据层面
LongAlpaca-12k
链接:https://huggingface.co/datasets/Yukang/LongAlpaca-12k
其是LongAlpaca-12k的一个工作,共收集了9k条长文本问答语料对,包含针对名著、论文、深度报道甚至财务报表的各类问答。
同时为了兼顾短文本能力,还从原有的Alpaca数据集中挑选了3k左右的短问答语料即最终构建了12k。
LongQLoRA
链接:https://huggingface.co/datasets/YeungNLP/LongQLoRA-Dataset
其是LongQLoRA的一个工作,其开源了两部分数据一部分是54k的预训练数据,一部分是39k的sft数据。
Ziya-Reader
链接:https://arxiv.org/abs/2311.09198
本篇paper主要贡献是如何构建长文本问答训练数据,专注用于多文档或单文档问答,虽然训练数据没有开源,但是做数据的方法我们可以学习一下
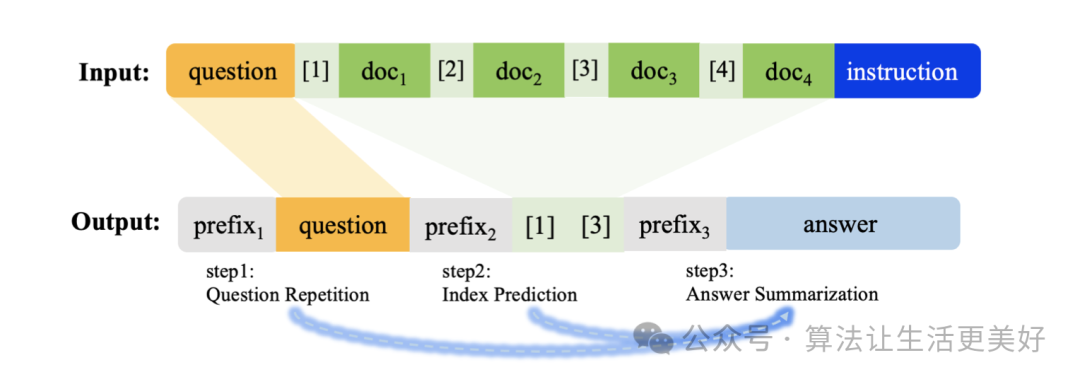
其主要借鉴cot的思路,在长文本问答领域也采用类cot,具体来说是:
(1)让模型先对问题进行复述,这使得模型在看了一段非常长的上下文信息后,也不会因为距离衰减的原因忘记原始的提问,因而在生成回复时,更加能够关注到问题。
(2)让模型预测正确上下文段落的索引下标,通过这样的方式可以让模型更加关注正确的上下文段落。
(3)预测最终答案
可以看到(1)(2)就是作者采用的cot
除此之外之外,还构建了一些负样本,比如没有正确上下文等等来增强模型的泛化性。
LongAlign
链接:https://huggingface.co/datasets/THUDM/LongAlign-10k
这篇工作主要聚焦做长文本的sft数据,具体来说作者从9个不同的来源收集长篇文章后使用Claude 2.1根据给定的长篇背景生成任务和答案。
模型层面
模型层面主要是探索外推性,即如何确保在模型推理阶段可以支持远远超过预训练的长度,其中限制外推的根本原因有两个即在inference阶段面对更长文本的时候,会出现更长的新位置编码(相比训练)以及历史上下文kv缓存过大这两个根本难题。
为此目前的探索主要发力解决这两个难题:(1)设计位置编码;(2)动态设计局部注意力机制。下面我们逐个详细看看~
(1)设计位置编码
关于这部分推荐一篇博客:https://mp.weixin.qq.com/s/RtI95hu-ZLxGkdGuNIkERQ
大模型的位置编码发展史: 绝对位置编码 -> 相对位置编码 -> 旋转位置编码。
其中绝对编码的一个缺点是模型无法显式的感知两个token之间的相对位置,而后续的比如Sinusoidal相对位置编码则通过正余弦函数实现了相对位置编码,而旋转位置编码则实现了通过简单的周期性旋转将位置信息编入了进去。
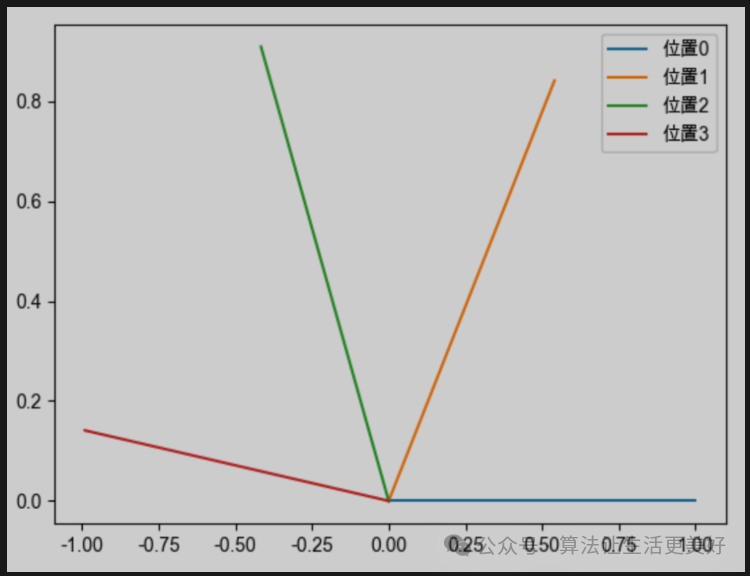
其中一个向量维度是d,越靠后的分组,它的旋转速度越慢,正弦函数的周期越大、频率越低。
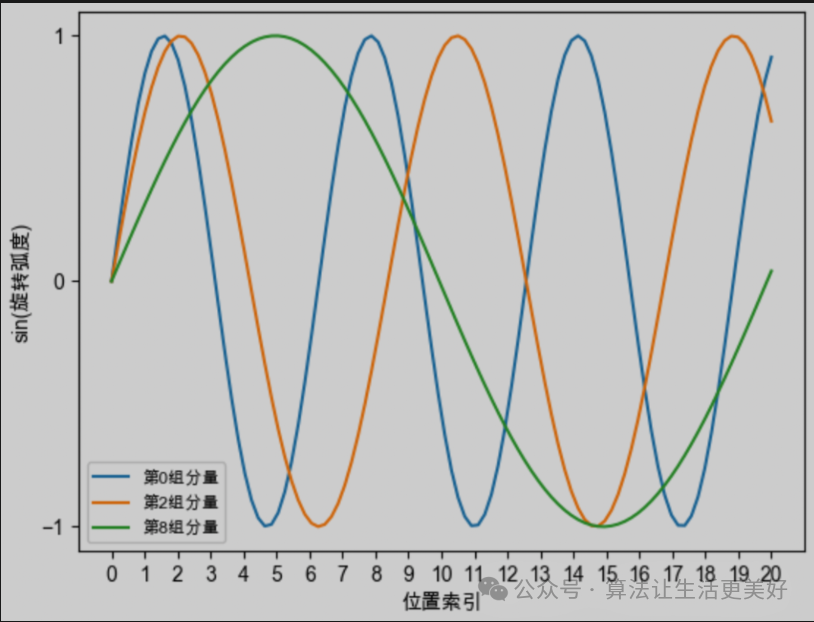
所以我们简单总结一下旋转位置编码直观的性质,他的核心是通过旋转向量来将位置信息植入进来(非常巧妙,不需要其他什么复杂的改变,只需要旋转向量就可以),具体的旋转过程是:假设当前向量是d维,那么就分为d/2个组,每个组进行各自的周期旋转,越靠后的分组,它的旋转速度越慢,正弦函数的周期越大、频率越低。
转化为数学一点为:向量q(维度为d)在位置m时, 它的第i组(总共d/2个组)分量的旋转弧度为
当训练长度为L时,模型训练的时候只见过即,当推理长度大于L时,模型不能cover新的旋转弧度也即无法插入新的位置信息了。
知道了卡点,下面我们来看几个相关的改进工作。
Position Interpolation
该方法为位置插值,思路也比较好的理解,既然超过L后的旋转模型因为没有见过就不能理解,那么我们就不超过,但是位置m还想扩大(比如一倍),那就可以通过缩小每个位置的旋转弧度(让向量旋转得慢一些),每个位置的旋转弧度变为原来的,这样的话长度就可以扩大几倍。具体的为:,这样的话即保证了没有超过训练的旋转范围,又插入更长或者更多的位置。
NTK-Aware Interpolation
该方法也是通过缩放,具体方法为如下:具体的是引入了一个缩放因子。
从数学角度看的话,Position Interpolation是将缩放因子放到了外面,而NTK是放到了里面(带有指数)。从直观的理论上看Position Interpolation方法是对向量的所有分组进行同等力度地缩小,而NTK对于较前的分组(高频分量)缩小幅度小,对于较后的分组(低频分量)缩小幅度大。
这样做的目的是靠前的分组,在训练中模型已经见过很多完整的旋转周期(因为旋转速度很快,这个性质之前已经介绍过了),位置信息得到了充分的训练,所以已经具有较强的外推能力。而靠后的分组,由于旋转的较慢,模型无法见到完整的旋转周期,或者见到的旋转周期很少,外推性能就很差,需要进行位置插值。
NTK-by-parts Interpolation
这个方法就更直接了,直接一刀切,对于高频分量就不缩小了(一点也不)即不进行插值,因为已经具备外推性,而对于低频分量由于训练没见过完整旋转周期所以外推性差,那就进行插值。相比于NTK-Aware Interpolation方法,这个方法更硬一些。
Dynamic NTK Interpolatio
NTK插值在超过训练长度L时表现还不错,但是在训练长度内反而表现较差,为此本方法实现了动态插值即当inference的长度l在训练长度L内就不进行插值,超过训练长度L才进行NTK-Aware Interpolation。
具体的缩小因子也是个动态值为:,其中l随着不断生成不断累加,是个动态值。
(2)动态设计局部注意力机制
在生成每一个token的时候,其实核心都是在计算attention score,那么就需要查询之前token的kv值,为了提高效率,一般来说会把历史的kv值都缓冲起来,这样后续就可以快速用了,但问题是当随着长度增加时,内存必然OOM。
知道了卡点,下面我们来看几个相关的改进工作。
EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS
论文链接:https://arxiv.org/pdf/2309.17453.pdf
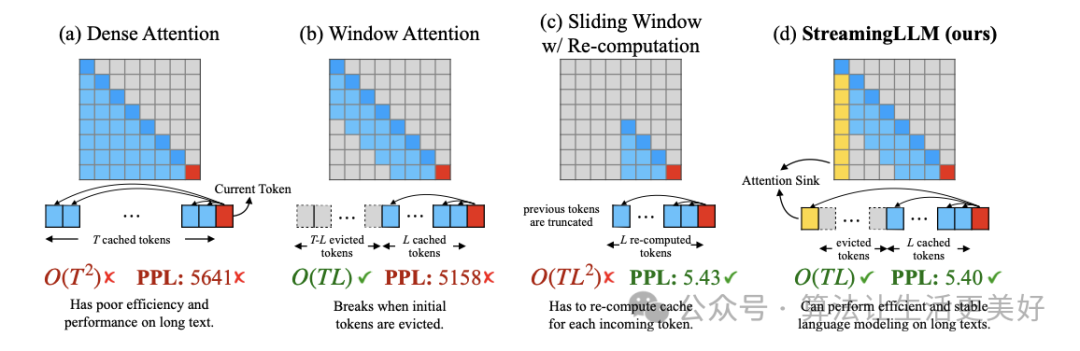
(a) 就是常规inference,可以看到不论是复杂度还是效果性能随着长度增加,都会变得严峻。
(b) 就是常说的滑动窗口,核心方法就是每次只缓冲最近几个token,这样的话可以保证效率,但是当文本变长后,性能会下降。
(c) 就是不缓冲,每次重新计算最近几个token的,好处是保住了性能,但是效率也大大降低,因为每次都要重新计算
(d) 就是本文提出的方法,其通过观察发现大量的注意力分数被分配给初始token(即使这些token与语言建模任务没有相关性),基于此作者沿用(b)的方法,只不过每次除了用缓冲的最近几个token,额外再加上开头的几个token。
通过(d)方法最终实现了无限外推,该工作的代码也已经开源,star非常多,很受欢迎。
LONGLORA: EFFICIENT FINE-TUNING OF LONG- CONTEXT LARGE LANGUAGE MODELS
论文地址:https://browse.arxiv.org/pdf/2309.12307.pdf
本篇主要的贡献在于开源了一个长文本训练数据(见上节)以及提出了一个shift short attention
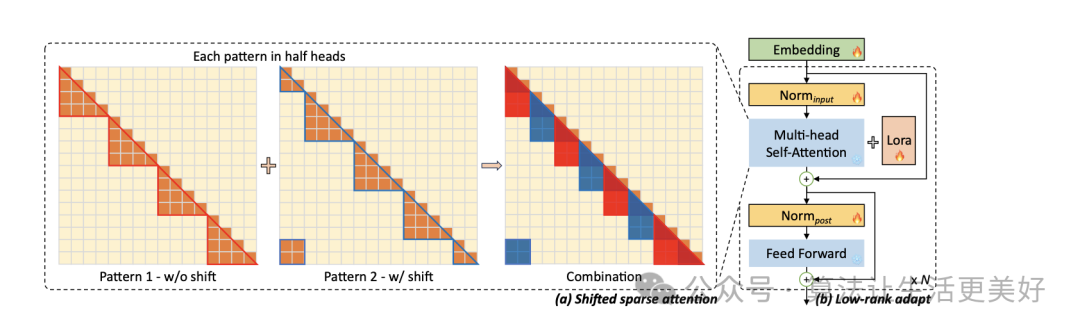
可以看到就是先分组(各个组内进行self attention),只不过由于各个组由于之间没有交互信息,导致效果变成,于是作者也采用滑窗口机制来缓解一下,即使用半组长度来滑,本质上就是滑动窗口,只不过就是先分组再滑。
同时其支持lora训练,可快速训练适配部署自己的模型。
LONGQLORA: EFFICIENT AND EFFECTIVE METHOD TO EXTEND CONTEXT LENGTH OF LARGE LANGUAGE MODELS
论文地址:https://arxiv.org/pdf/2311.04879.pdf
其和上篇的LONGLORA大同小异,主要不同是替用qlora进行训练,更节省资源,同时另外一个贡献就是开源了一个长文本数据集(见上节)
Soaring from 4K to 400K: Extending LLM’s Context with Activation Beacon
论文地址:https://arxiv.org/pdf/2401.03462v1.pdf
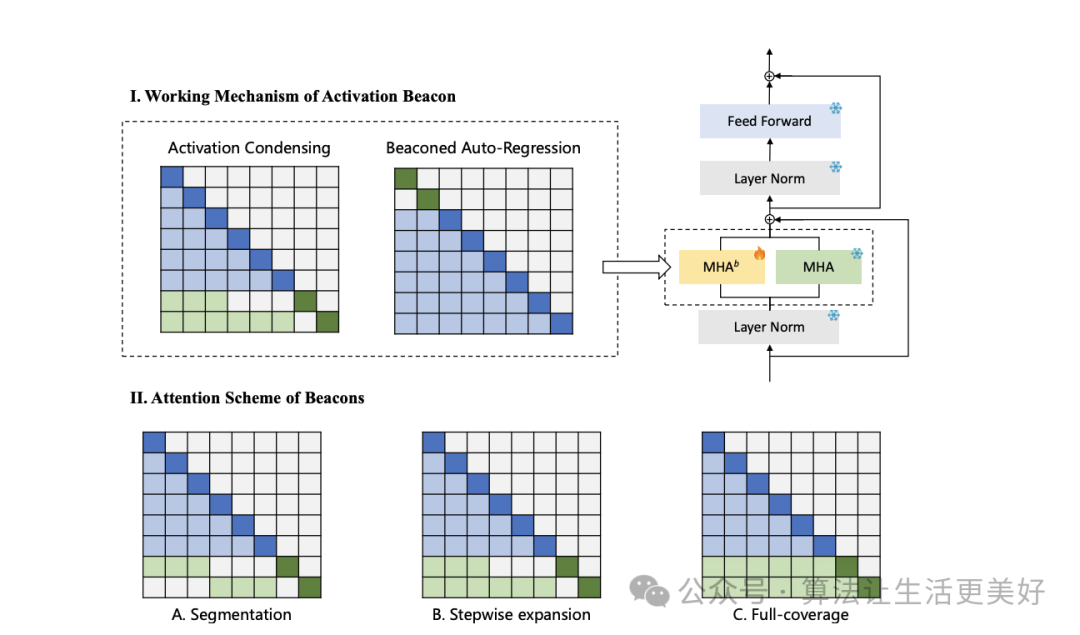
这篇论文的思路也很朴素:大的思路也是采用滑动窗口,只不过在怎么动态保存之前上下文的思路上采用的是压缩思路,即前面信息既然太多,那就压一压。
具体的前面咱们介绍的EFFICIENT是通过每次滑的时候始终保留最前面几个token,而本篇的思路就是把每个区间的信息(图中蓝色)压缩成一个激活信标(图中绿色),而后面就用这些单个激活信标来代表整个区间的信息。
那激活信标怎么得到呢?作者也是采用了注意力机制,具体的探索了三种方法,一种是分段即每个信标只用自己区间的信息(图A),第二种是逐步分段即每个信标可以关注比其前身多一个子区间(图B),第三种是完全覆盖,其中所有信标都可以关注整个上下文(图C)。这三种方法的计算成本相同。最后作者发现第二种最好。
有了信标后,便可以将信标和来自普通信息一起使用滑动窗口进行流式处理即每个滑动窗口由过去上下文区间的m个信标和最新上下文区间的普通标记组成。
评估层面
在迭代模型长文本能力的过程中,需要一个量化指标来不断指导,目前业界已经有一些评估,一起来看看吧~
ZeroSCROLLS
论文链接:https://arxiv.org/pdf/2305.14196.pdf
其由十个自然语言任务构成,包括摘要、问答、聚合任务(给50条评论,让模型预测正面评论的百分比)等等
longeval
论文链接:https://lmsys.org/blog/2023-06-29-longchat/
该工作通过设计topic和lines长文本记忆能力来测试模型的长文本能力。
L-Eval
论文链接:https://arxiv.org/pdf/2307.11088.pdf
该工作从公开数据集收集数据,然后手动过滤和校正,重新标注得到。
LongBench
论文链接:https://arxiv.org/abs/2308.14508
该工作也是设计了单文档问答、多文档问答、摘要任务、Few-shot任务、合成任务、代码补全等等
LooGLE
论文链接:https://arxiv.org/pdf/2311.04939.pdf
该工作从科学论文、维基百科文章、电影和电视中收集样本,然后也是设计摘要等任务。
FinLongEval
论文链接:https://github.com/valuesimplex/FinLongEval
主要聚焦金融领域的长文本评测
总结
可以看到,在助力LLM长文本能力的道路上目前有两个大的方向在发力:
(1)从数据入手即构建做高质量长文本数据,这非常重要,因为有了数据才能训练,其中长文本预训练数据相对来说比较好找,但是sft数据就比较难了,并不是说强行cat起来就是有效长文本,比如把多个单轮文本cat到8k,但是这是一个伪多轮,对模型学习全局信息帮助很小;关于怎么构建高质量的长文本数据尤其是中文领域的数据还需要更多的探索,可以借鉴长文本评测任务来汲取灵感进行构建训练数据。
(2)从模型层面入手进行外推,目前一个是探索位置编码,另外一个就是探索怎么缓解kv缓冲也即两个核心问题:第一就是寻找或设计合适的位置编码;第二是设计局部注意力机制。其中第一个大的方向都是缩放即通过缩放将旋转范围依然缩放到和训练一致但实现了插入了更多的或者更长的位置,第二个大的方向基本都是探索怎么把之前的信息进行动态压缩,更进一步这里的动态其实就是滑动,只不过在滑动上进行各种不同的逻辑。将两个技术点(本来就是解决不同问题的)合理的结合也是很重要的。
总的来说,首先尽可能的收集准备好高质量的长文本训练数据,然后在当前资源下训练到最大长度,最后在推理时可以借助各种外推手段进行拓展。
审核编辑:黄飞























 工商网监
工商网监
评论