 快速了解文本语义相似度领域的研究脉络和进展
快速了解文本语义相似度领域的研究脉络和进展

本文旨在帮大家快速了解文本语义相似度领域的研究脉络和进展,其中包含了本人总结的文本语义相似度任务的处理步骤,文本相似度模型发展历程,相关数据集,以及重要论文分享。
文本相似度任务处理步骤
通过该领域的大量论文阅读,我认为处理文本相似度任务时可以分为一下三个步骤:
预处理:如数据清洗等。此步骤旨在对文本做一些规范化操作,筛选有用特征,去除噪音。
文本表示:当数据被预处理完成后,就可以送入模型了。在文本相似度任务中,需要有一个模块用于对文本的向量化表示,从而为下一步相似度比较做准备。这个部分一般会选用一些 backbone 模型,如 LSTM,BERT 等。
学习范式的选择:这个步骤也是文本相似度任务中最重要的模块,同时也是区别于 NLP 领域其他任务的一个模块。其主要原因在于相似度是一个比较的过程,因此我们可以选用各种各样的比较的方式来达成目标。可供选择的学习方式有:孪生网络模型,交互网络模型,对比学习模型等。
文本相似度模型发展历程
从传统的无监督相似度方法,到孪生模型,交互式模型,BERT,以及基于BERT的一些改进工作,如下图:
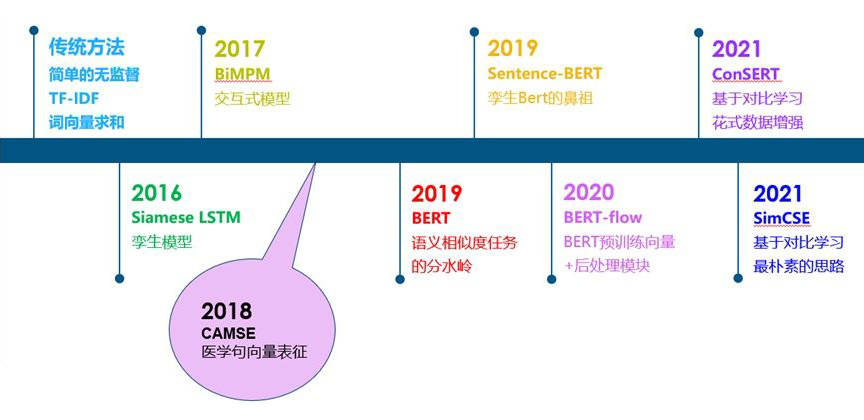
总体来说,在 BERT 出现之前,文本相似度任务可以说是一个百花齐放的过程。大家通过各种方式来做相似度比较的都有。从 BERT 出现之后,由于 BERT 出色的性能,之后的工作主要是基于 BERT 的改进。在这个阶段,大家所采用的数据集,评价指标等也逐渐进行了统一。
数据集
在 BERT 以后,大家在文本相似度任务上逐渐统一了数据集的选择,分别为 STS12,STS13,STS14,STS15,STS16,STS-B,SICK-R 七个数据集。STS12-16 分别为 SemEval 比赛 2012~2016 年的数据集。此外,STS-B 和 SICK-R 也是 SemEval 比赛数据集。在这些数据集中,每一个文本对都有一个 0~5 分的人工打标相似度分数(也称为 gold label),代表这个文本对的相似程度。
评价指标
首先,对于每一个文本对,采用余弦相似度对其打分。打分完成后,采用所有余弦相似度分数和所有 gold label 计算 Spearman Correlation。
其中,Pearson Correlation 与 Spearman Correlation 都是用来计算两个分布之间相关程度的指标。Pearson Correlation 计算的是两个变量是否线性相关,而 Spearman Correlation 关注的是两个序列的单调性是否一致。并且论文《Task-Oriented Intrinsic Evaluation of Semantic Textual Similarity》证明,采用 Spearman Correlation 更适合评判语义相似度任务。Pearson Correlation 与 Spearman Correlation 的公式如下:
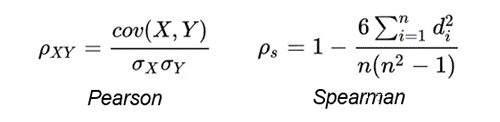
论文分享
Siamese Recurrent Architectures for Learning Sentence Similarity, AAAI 2016
https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/download/12195/12023
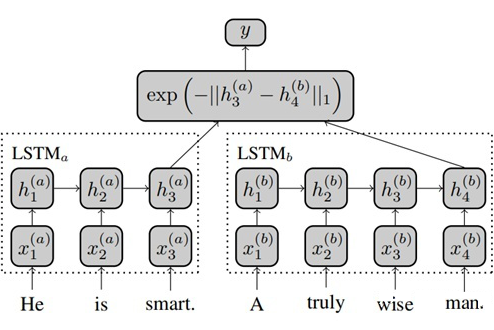
Siamese LSTM 是一个经典的孪生网络模型,它将需要对比的两句话分别通过不同的 LSTM 进行编码,并采用两个 LSTM 最后一个时间步的输出来计算曼哈顿距离,并通过 MSE loss 进行反向传导。
Bilateral Multi-Perspective Matching for Natural Language Sentences, IJCAI 2017
https://arxiv.org/abs/1702.03814
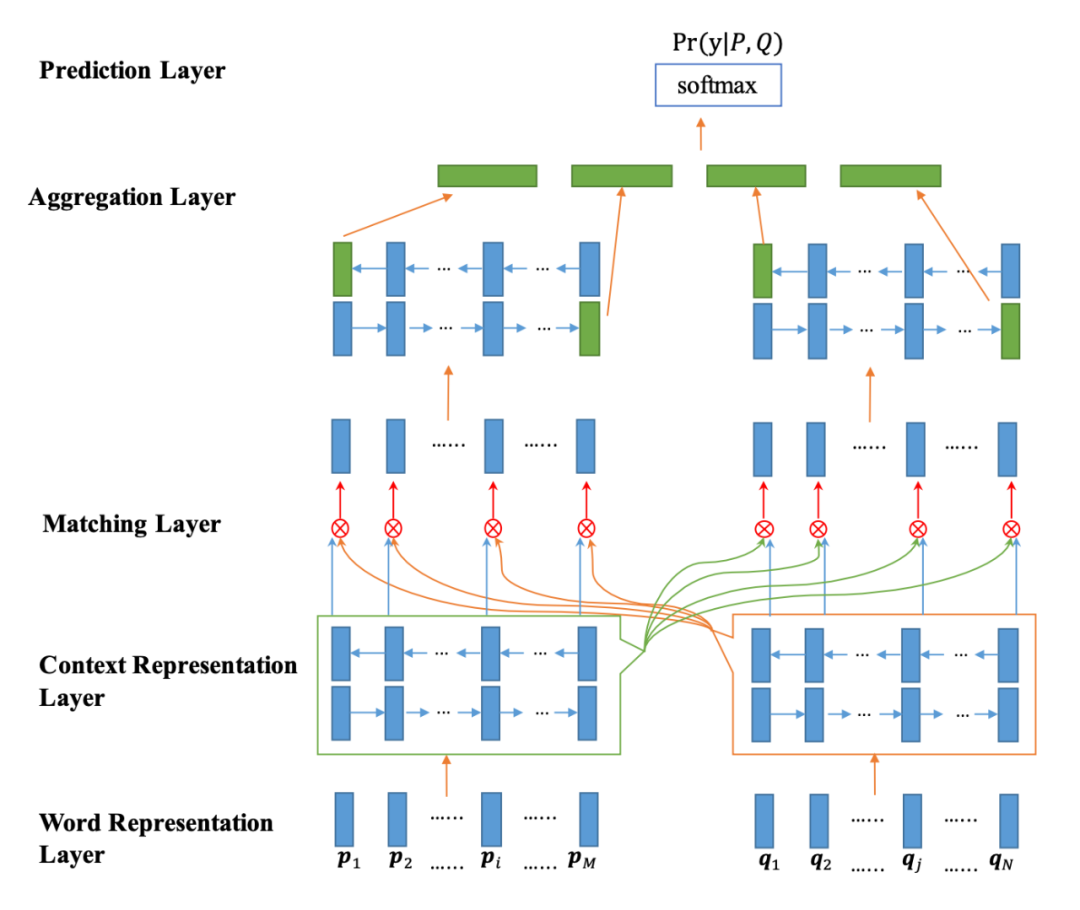
BiMPM 是一个经典的交互式模型,它将两句话用不同的 Bi-LSTM 模型分别编码,并通过注意力的方式使得当前句子的每一个词都和另一个句子中的每一个词建立交互关系(左右句子是对称的过程),从而学习到更深层次的匹配知识。在交互之后,再通过 Bi-LSTM 模型分别编码,并最终输出。
对于交互的过程,作者设计了四种交互方式,分别为:
句子 A 中每个词与句子 B 的最后一个词进行交互
句子 A 中每个词与句子 B 的每个词进行交互,并求 element-wise maximum
通过句子 A 中的词筛选句子 B 中的每一个词,并将句子 B 的词向量加权求和,最终于 A 词对比
与 c 几乎一致,只不过将加权求和操作变成 element-wise maximum
具体的交互形式是由加权的余弦相似度方式完成。
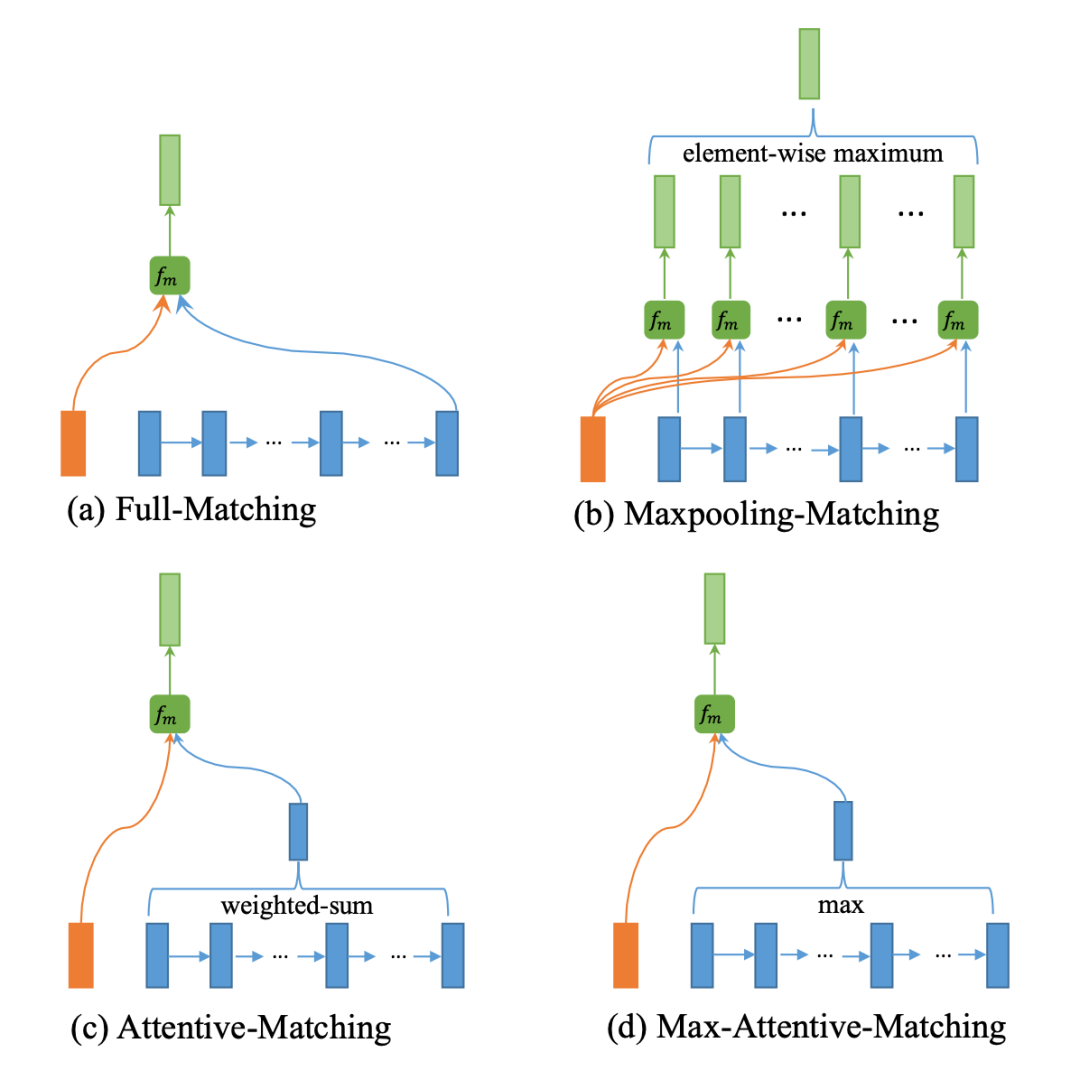
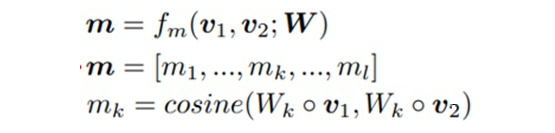
其中,Wk 是参数矩阵,可以理解为 attention 的 query 或者 key,v1 和 v2 分别是要进行交互的两个词,这样计算 l 次余弦相似度,就会得到 m 向量(一个 l 维向量)。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/abs/1810.04805
BERT 可以认为是语义相似度任务的分水岭。BERT 论文中对 STS-B 数据集进行有监督训练,最终达到了 85.8 的 Spearman Correlation 值。这个分数相较于后续绝大部分的改进工作都要高,但 BERT 的缺点也很明显。对于语义相似度任务来说:
在有监督范式下,BERT 需要将两个句子合并成一个句子再对其编码,如果需要求很多文本两两之间的相似度,BERT 则需要将其排列组合后送入模型,这极大的增加了模型的计算量。
在无监督范式下,BERT 句向量中携带的语义相似度信息较少。从下图可以看出,无论是采用 CLS 向量还是词向量平均的方式,都还比不过通过 GloVe 训练的词向量求平均的方式要效果好。

基于以上痛点,涌现出一批基于 BERT 改进的优秀工作。
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, EMNLP 2019
https://arxiv.org/abs/1908.10084
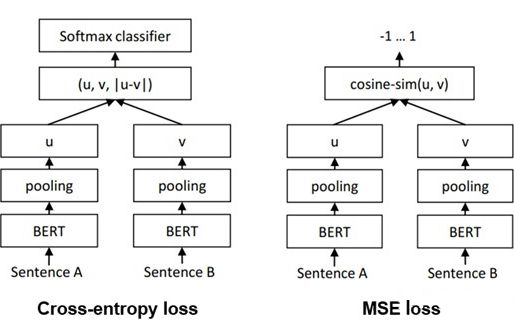
Sentence-BERT 是一篇采用孪生 BERT 架构的工作。Sentence-BERT 作者指出,如果想用 BERT 求出 10000 个句子之间两两的相似度,排列组合的方式在 V100 GPU 上测试需要花费 65 小时;而如果先求出 10000 个句子,再计算余弦相似度矩阵,则只需要花费 5 秒左右。因此,作者提出了通过孪生网络架构训练 BERT 句向量的方式。
Sentence-BERT 一共采用了三种 loss,也就是三种不同的方式训练孪生 BERT 架构,分别为 Cross-entropy loss,MSE loss 以及 Triple loss,模型图如下:
On the Sentence Embeddings from Pre-trained Language Models, EMNLP 2020
https://arxiv.org/abs/2011.05864
BERT-flow 是一篇通过对 BERT 句向量做后处理的工作。作者认为,直接用 BERT 句向量来做相似度计算效果较差的原因并不是 BERT 句向量中不包含语义相似度信息,而是其中包含的相似度信息在余弦相似度等简单的指标下无法很好的体现出来。
首先,作者认为,无论是 Language Modelling 还是 Masked Language Modelling,其实都是在最大化给定的上下文与目标词的共现概率,也就是 Ct 和 Xt 的贡献概率。Language Modelling 与 Masked Language Modelling 的目标函数如下:
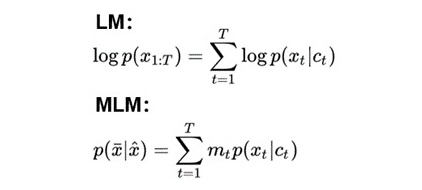
因此,如果两句话预测出的 Xt 一致,那么两句话的 Ct 向量很有可能也是相似的!考虑如下两句话:
今天中午吃什么?
今天晚上吃什么?
通过这两句话训练出的语言模型都通过上下文预测出了“吃“这个字,那说明这两句话的句向量也很可能是相似的,具有相似的语义信息。
其次,作者通过观察发现,BERT 的句向量空间是各向异性的,且高频词距离原点较近,低频词距离较远,且分布稀疏。因此 BERT 句向量无法体现出其中包含的相似度信息。
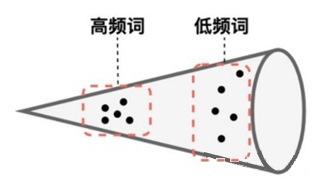
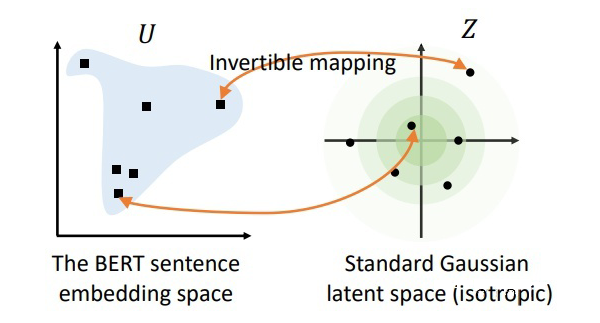
因此,作者认为可以通过一个基于流的生成模型来对 BERT 句向量空间进行映射。具体来说,作者希望训练出一个标准的高斯分布,使得该分布中的点可以与 BERT 句向量中的点一一映射。由于该方法采用的映射方式是可逆的,因此就可以通过给定的 BERT 句向量去映射回标准高斯空间,然后再去做相似度计算。由于标准高斯空间是各向同性的,因此能够将句向量中的语义相似度信息更好的展现出来。
SimCSE: Simple Contrastive Learning of Sentence Embeddings, EMNLP 2021
https://arxiv.org/abs/2104.08821
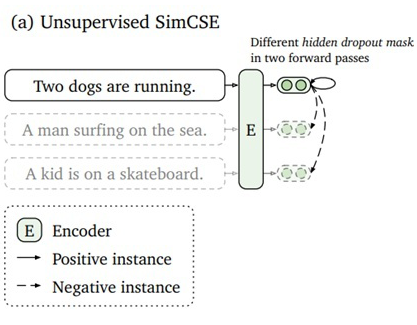
SimCSE 是一篇基于对比学习的语义相似度模型。首先,对比学习相较于文本对之间的匹配,可以在拉近正例的同时,同时将其与更多负例之间的距离拉远,从而训练出一个更加均匀的超球体向量空间。作为一类无监督算法,对比学习中最重要的创新点之一是如何构造正样本对,去学习到类别内部的一些本质特征。
SimCSE 采用的是一个极其朴素,性能却又出奇的好的方法,那就是将一句话在训练的时候送入模型两次,利用模型自身的 dropout 来生成两个不同的 sentence embedding 作为正例进行对比。模型图如下:
ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer, ACL 2021
https://arxiv.org/abs/2105.11741
ConSERT 同样也是一篇基于对比学习的文本相似度工作。ConSERT 是采用多种数据增强的方式来构造正例的。其中包括对抗攻击,打乱文本中的词顺序,Cutoff以及 Dropout。这里需要注意的是,虽然 ConSERT 与 SimCSE 都采用了 Dropout,但 ConSERT 的数据增强操作只停留在 embedding layer,而 SimCSE 则是采用了 BERT 所有层中的 Dropout。此外,作者实验证明,在这四种数据增强方式中,Token Shuffling 和 Token Cutoff 是最有效的。
Exploiting Sentence Embedding for Medical Question Answering, AAAI 2018
https://arxiv.org/abs/1811.06156
注:由于本人工作中涉及的业务主要为智慧医疗,因此会有倾向的关注医疗人工智能领域的方法和模型。
MACSE 是一篇针对医学文本的句向量表征工作,虽然其主要关注的是 QA 任务,但他的句向量表征方式在文本相似度任务中同样适用。
医学文本区别于通用文本的一大特征就是包含复杂的多尺度信息,如下:
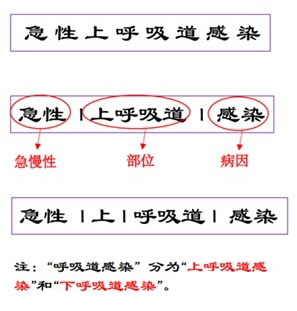
因此,我们就需要一个能够关注到医学文本多尺度信息的模型。
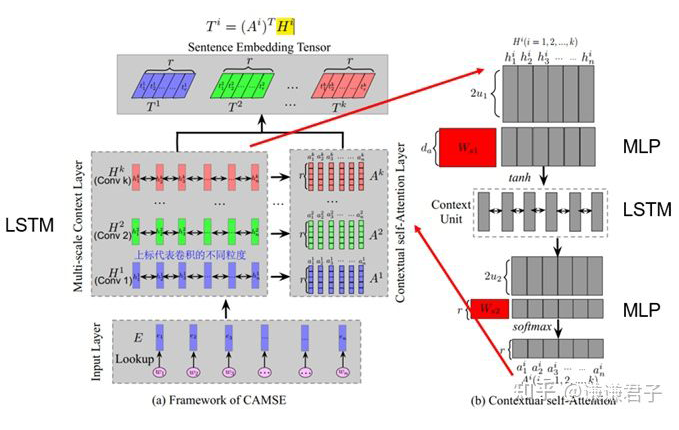
在本文中,通过多尺度的卷积操作,就可以有效的提取到文本中的多尺度信息,并且通过注意力机制对多尺度信息进行加权,从而有效的关注到特定文本中在特定尺度上存在的重要信息。
实验结果汇总
以下为众多基于 BERT 改进的模型在标准数据集上测试的结果,出自 SimCSE 论文:
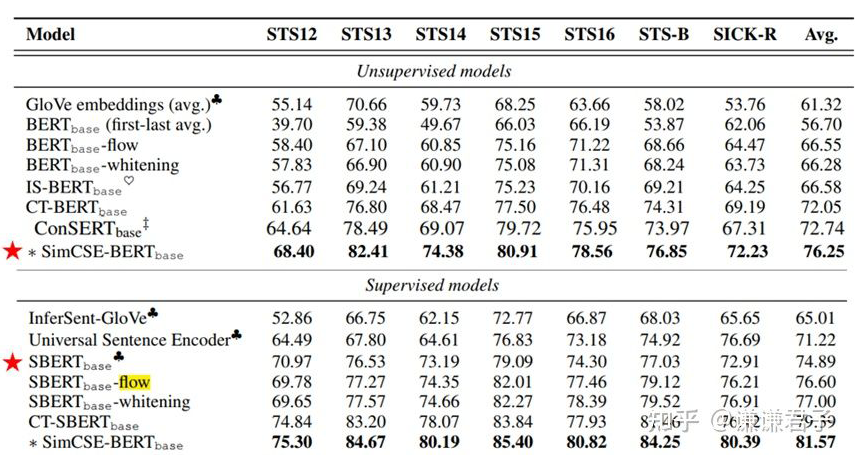
可以看到,BERT-flow 相较于原生 BERT 提升了将近 10 个点,而基于对比学习的工作又要比基于后处理的工作的效果好很多。此外需要注意的是,在这里 Sentence-BERT 被归为了有监督模型中。这是因为 Sentence-BERT 虽然没有用到 STS 标签,但训练时用的是 NLI 数据集,也用到了 NLI 中人工打标的标签,因此 SimCSE 作者将 Sentence-BERT 归为了有监督模型中。
好了,以上就是文本语义相似度领域的研究脉络和进展,希望能对大家有所帮助。当然 2022 年也有不少优秀的工作出现,不过这一部分就留到以后吧!
审核编辑 :李倩
-
模型
+关注
关注
1文章
3879浏览量
52353 -
语义
+关注
关注
0文章
22浏览量
8816 -
文本
+关注
关注
0文章
120浏览量
17943
原文标题:一文详解文本语义相似度的研究脉络和最新进展
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Elasticsearch7.x搜索实战
贺喜!GPMI入选“2025年度信息通信领域十大科技进展”,中星联华聚焦物理层测试,支撑GPMI产业落地

淘宝API+API:图片搜索相似商品利器
百度地图分享在AI汽车领域的最新战略思考与量产进展
上海高等研究院在阿秒X射线研究方面取得重要进展

RDMA设计46:RoCE v2原语功能:单边语义
东南大学团队多能X射线智能成像研究获重要进展

清华大学在分焦面超像素阵列光刻制造领域取得新进展
Progress-Think框架赋能机器人首次实现语义进展推理

SGS为TCL华星自然光MNT显示颁发高自然光相似度 Performance Tested Mark

上海光机所在全息光刻研究方面取得进展
大华股份入选2025年度物联网领域十大科技进展
格灵深瞳视觉基础模型Glint-MVT的发展脉络
微双重驱动的新型直线电机研究
氧化镓射频器件研究进展



评论