 加速AI落地、推动边缘计算应用实践——开放计算在中国行至高潮
加速AI落地、推动边缘计算应用实践——开放计算在中国行至高潮

8年后,在中国再谈开放计算,不论是技术原动力还是整个产业生态,都有了翻天覆地的变化。
时间拨回2011年,Facebook 主导发起了OCP(Open Compute Project; 开放计算项目),旨在以开源开放的方式,重构当时的数据中心硬件,发展面向下一代数据中心的服务器、存储、网络、基础设施等。
当时,我国互联网技术正以惊奇世界的姿态飞速发展着。软件开源已经成为趋势,但如果你提到硬件开源,那年刚刚出现的从英文“Maker”翻译过来的“创客”,会和你聊聊树莓派,聊聊包括电路原理图、设计图在内的开源许可。
但这并不是OCP的着眼点,IT基础设施才是。
同年,阿里巴巴、百度、腾讯三家发起ODCC组织的前身“天蝎计划”,并在同年年底确立了最初的技术规范。
百度从2011到2014年间,几乎花了3年的时间与OCP社区进行沟通,试图推动在数据中心的分享与合作。但现实的反差是巨大的,由于国内外数据中心的巨大差异、地区的差异、认知的差异等限制,最终没有达成共识。
时间来到2019年,国内互联网和泛互联网产业取得长足发展,也使得更多的中国企业共同站在这个舞台上面向未来进行深入探讨。今年也是继2014年之后,百度重新回归OCP。此时,OCP的成员企业大约达到200家,包括英特尔、谷歌、微软、Facebook、LinkedIn以及中国的阿里巴巴、百度、腾讯、浪潮等,囊括了全球服务器采购量最大的企业用户。
浪潮与OCP联合主办的首届OCP China Day(开放计算中国日)6月25日在北京举行,那么,现在在中国聊起开放计算,我们都在关注什么?
关注一:OAM——简化AI基础架构设计,加速创新设计
AI是OCP China Day上多次被提及的话题之一。伴随着AI的火热,有越来越多的AI芯片出现。但是在推动芯片落地时却发现很大的问题,需要从零开始进行板卡兼容等工作。AI加速器越来越多,技术更新也越来越快,AI硬件系统的技术挑战和设计复杂度在增加,将加速器集成到系统中通常需要大约6-12个月。这种延迟阻碍了AI加速器的快速采用。
基于此,OCP社区在服务器项目组下设立了OAI(OpenAccelerator Infrastructure)小组,负责开发OAM(OCP Accelerator Module)规范,将加速器模块标准化,简化AI基础架构的设计,缩短硬件设计周期。OAM规范的内容包括电源/冷却,稳健性,可维护性,配置,编程,管理和调试,以及模块间通信,以扩展和输入/输出带宽。OAM目前仍在开发阶段,已经在3月14日公布了第一个非正式版本V0.85,4月30日公布了第二个非正式版本0.9。OAM标准,就是针对上述问题设计的一套指导AI硬件加速模块和系统设计的标准,它集合定义了AI硬件加速模块本身、主板、互联拓扑、机箱、供电、散热以及系统管理等系列设计规范,主要目标是通过模块化、标准化来增强不同AI硬件加速模块和系统的互操作性,加速新的AI硬件加速模块的落地和应用。
为什么需要OAM?
先从典型的AI加速系统设计来看,它通常由三部分构成,包括承载多个OAI模块的基板,控制整个系统执行流程的CPU,连接AI芯片和CPU的PCIe开关。由于PCIe供电能力有限,无法很好地支持高速互联,所以出现了很多新的解决方案,这样就出现了非标准系统。由于AI芯片之间和CPU之间需要互联起来,由于计算节点的限制,包括对于存储的需求、I/O互联的需求不一样,所以在设计PCIe拓扑的时候有差异,导致硬件系统适应新的需求比较困难。
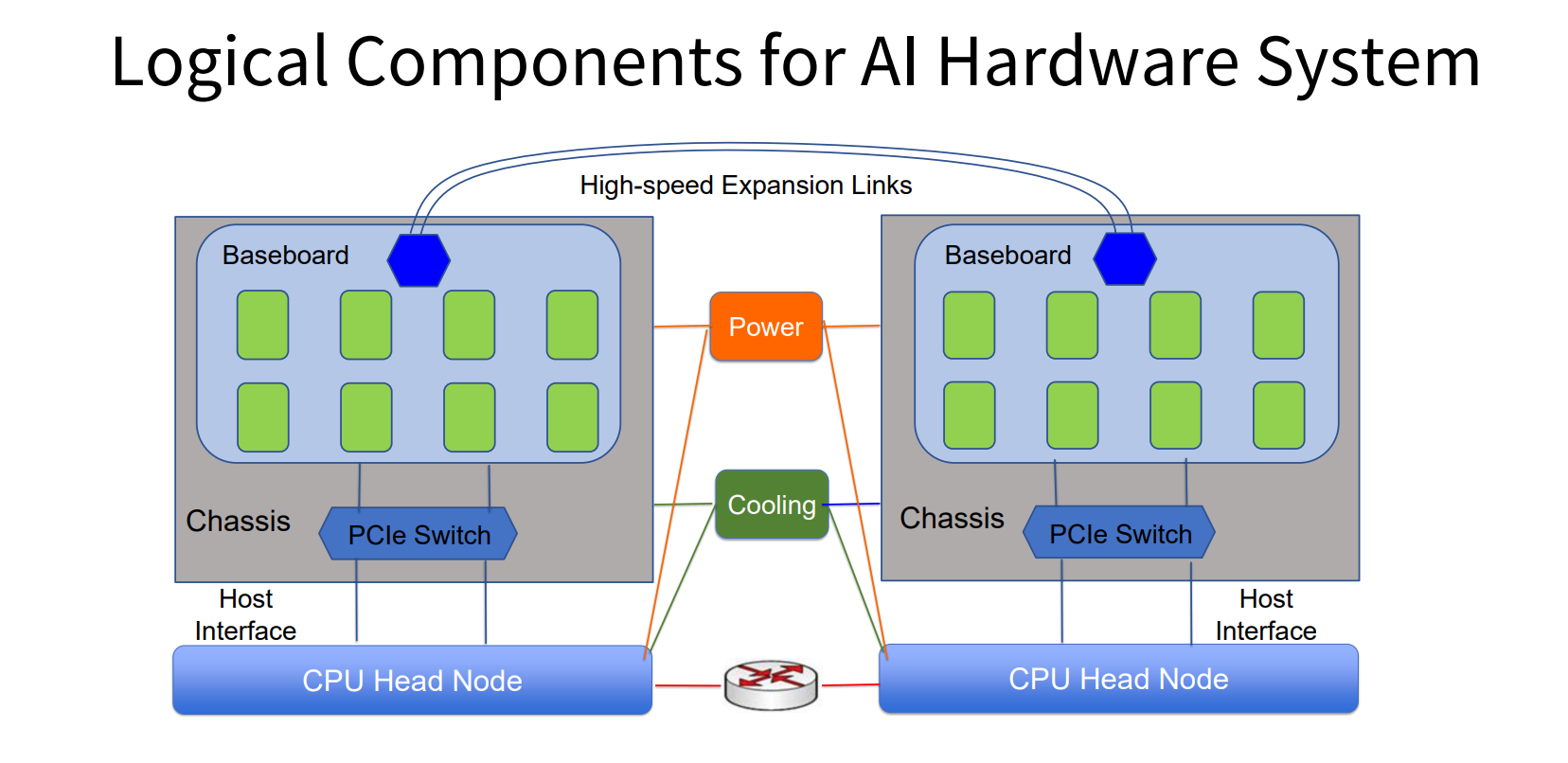
同时,大规模的AI的爆发需要很强大的算力,一个节点不够用时,需要更好的扩展能力。有两种典型方式:一是通过传统的以太网交换机实现互联,但是这个license费用比较高,互联的带宽也是有限的;二是通过新兴技术实现AI加速芯片之间私有的互联,这是一种更高速的互联,有更低的延时,可以大幅提升大规模训练的性能。从一个单机扩展到多机,构建了典型的大规模训练系统。除此之外还有基础设施,包括供电、散热这些很有挑战的问题。系统内不同模块之间的组合能够实现不同目标,取决于系统整体的权衡。
针对场景众多的AI应用,不论是系统本身的设计,还是在系统的扩展方面,一家公司单枪匹马攻克了一个目标之后,下一个目标可能又要重新设计方案。从这个角度看,长期快速跟进甚至引领市场比较困难,所以需要协作,开放AI加速的基础架构,采用模块化的思路,增强不同的模块与系统之间的互操作性,加速相关技术的创新,推动新的AI芯片快速落地。
在这一过程中,OCP定义了AI加速的基础架构规范,把相关模块之间的边界定义清楚,只要满足相关接口都可以在系统中共存,这样可以很好地将共性需求抽离出来,将特定的需求通过模块化的形式去满足,能够更好地加速相关创新。
当前公布的OAM标准,是由参与OCP开放计算项目的百度、微软、Facebook三家国际AI领先企业联合定义,已经得到包括Google、阿里、腾讯等互联网企业,英伟达、英特尔、AMD、高通、赛灵思等AI芯片企业,Graphcore、Habana Labs等AI芯片及处理器初创企业,以及IBM、浪潮等厂商的参与和支持。
关注二:边缘计算的应用实践
伴随着5G的到来,边缘计算也来了。目前看来,似乎只有自动驾驶、VR/AR等应用场景提出了低延迟、高带宽的需求,智慧城市、工业互联网等提出了高带宽、低延时以及安全方面的要求。在此基础上,如何发展边缘计算?如何满足边缘计算的需求?仍然不清楚。
针对边缘计算的实践,百度提出了“DEC”(Device、Edge、Cloud)算力部署,中国移动认为运营商提供分流管道,边缘计算业务由行业客户自营。提到边缘计算,势必要考虑边缘服务器的特性。它需要紧凑、可扩展的功能,并且提供短期高温环境。
但是,服务器的研发周期很长,从研发到批量供货需要1年时间,此后还会难以避免的进行部分升级换代,比如,主板升级、PCI-E模块的升级等,这些升级很可能会带来服务器主体设计的重构,很多时候不得不从头开始研发新一代服务器。
对边缘服务器的看法,中国移动主要看到三方面:业务需求、机房条件和本身的可维护性。可能在未来边缘计算的大规模部署的时候,如果确定了一个比较具体的场景,会有一种模块化的交付方式,使得能够非常快速,大批量的跟软件一起来交付。
腾讯与浪潮研发的T-Flex2.0架构就是为了解决上述问题,对空间进行有效规划, 通过I/O池化技术(支持PCI-E交换和Gen-z两类互联协议)支持未来模块化迭代和灵活组合, 服务器可以单独升级部分模块并不影响其他模块,T-Fle2.0x是一个更为灵活的架构。
从前向后,T-Flex2.0高度为2OU,分为A、B、C等3个区,每个区域可以放置不同的模块,实现服务器的主体功能,覆盖各类应用场景,甚至可以去掉A区或者C区,减少长度成为一款边缘计算服务器。
作为OCP、Open19和ODCC全球三大开放计算标准组织的共同成员,浪潮从贡献IP,参与开发标准到主导标准制定,在开放硬件社区中的参与度越来越高,先后贡献了首批基于Open19标准的服务器、第一款OCP标准基于Intel Skylake平台的主板、第一款Olympus四路服务器。同时,浪潮还参与了OCP OAM项目,牵头成立了OpenRMC项目,开发完成了全球第一个基于OCP标准的整机柜管理架构。
关注三:OpenRMC项目,下一代数据中心的管理框架
OpenRMC是OCP社区硬件管理项目组下的子项目组,由浪潮牵头成立。该项目目标是完成OpenBMC与Redfish的融合,形成下一代数据中心管理的统一框架。OpenBMC是Facebook发起的开源项目,希望解决闭源的BMC(Baseboard Management Controller,基板管理控制器)以及相关的软件包标准不一的问题,这个问题给数据中心统一管理带来了很多技术障碍。DMTF(Distributed Management Task Force,分布式管理任务组)制定了下一代服务器管理技术标准Redfish,以取代当前IPMI 2.0,Redfish具有扩展性好、功能丰富、针对地址不同和供应商不同的基础设施向客户提供规范化管理接口的优点,能够满足现代数据中心的管理需求。
OpenRMC项目希望能够解决两个标准之间的互操作性等一系列问题,并建立协同机制,形成规范,推进下一代数据中心管理技术和产业的发展。
未来,数据中心继续充满挑战,数据中心整合将继续推进。边缘计算也将以更快的速度实现增长。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
OCP
+关注
关注
0文章
85浏览量
17129 -
5G
+关注
关注
1368文章
49214浏览量
639022 -
边缘计算
+关注
关注
22文章
3560浏览量
53691
发布评论请先 登录
相关推荐
热点推荐
边缘计算AI芯片企业爱芯元智港股上市
(中国香港)2026年2月10日,人工智能感知与边缘计算芯片领军企业爱芯元智半导体股份有限公司(0600.HK)正式于香港交易所主板挂牌上市,成为首家在港股上市的边缘
2025年中科曙光联合多家企业共同推出AI计算开放架构
2025年,人工智能产业步入规模化应用深水区,大模型技术迭代加速,对算力规模与效率提出更高要求。在这一背景下,9月,中科曙光依托国家先进计算产业创新中心,联合产业链上下游20多家企业共同推出AI
重磅合作!Quintauris 联手 SiFive,加速 RISC-V 在嵌入式与 AI 领域落地
(ADAS);
嵌入式平台的 AI 与机器学习加速器;
工业物联网与自动化系统(开放标准架构的优势能充分发挥)。
对咱们开发者来说,这波合作最大的好处就是能拿到集成式解决方案,不仅能缩短开发周期,还能
发表于 12-18 12:01
一文了解ai计算盒子(边缘计算盒子)是到底是什么产品?
在物联网与人工智能深度融合的当下,数据处理的效率和实时性成为各行业数字化转型的关键。ai计算盒子(又称边缘计算盒子、ai

边缘计算中的AI加速器类型与应用
人工智能正在推动对更快速、更智能、更高效计算的需求。然而,随着每秒产生海量数据,将所有数据发送至云端处理已变得不切实际。这正是边缘计算中AI

【今晚7点半】正点原子 x STM32:智能加速边缘AI应用开发!今晚正点原子B站直播间等你
【联合直播】正点原子 x STM32:智能加速边缘AI应用开发!
一、直播介绍 随着人工智能技术在边缘计算领域的快速发展,STM32系列
发表于 09-25 14:14
此芯科技发布“合一”AI加速计划,赋能边缘与端侧AI创新
产品组合,覆盖从1.5B至32B参数规模的端侧AI模型推理需求,满足工业、消费电子、智能终端等多样化场景的部署需求,推动AI技术从云端向边缘高效落地

智慧农业新基建:边缘计算网关在精准农业中的落地实践案例
智慧农业新基建:边缘计算网关在精准农业中的落地实践案例 传统农业生产中,水肥管理依赖经验判断,往往造成资源浪费和产量不稳定;同时,恶劣的自然环境也给农业生产带来诸多挑战。而蓝蜂
研华推出ACE应用导向边缘计算解决方案及WISE-STACK私有云平台
研华科技今日举办法说会,公司2025上半年营收呈双位数成长。面对市场对边缘计算与 AI 的高度需求,研华推出ACE应用导向边缘计算方案与WI
AI 边缘计算网关:开启智能新时代的钥匙—龙兴物联
在数字化浪潮的当下,AI 边缘计算网关正逐渐崭露头角,成为众多行业转型升级的关键力量。它宛如一座智能桥梁,一端紧密连接着各类物理设备,如传感器、摄像头、工业机器等,负责收集丰富的数据信息;另一端则
发表于 08-09 16:40
是德科技邀您相约2025开放计算创新技术大会
2025开放计算创新技术大会将于8月7日在北京国际饭店举办,围绕“开放变革”主题,分享开放计算技术的创新与
Axelera AI:边缘计算加速智能创新解决方案
。AxeleraAI凭借其卓越的AI加速解决方案,致力于协助企业快速部署高性能、低功耗的边缘计算平台,广泛应用于智慧城市、智慧交通及工业检测等领域。接下来说明AxeleraAI产品特色

AI芯片:加速人工智能计算的专用硬件引擎
人工智能(AI)的快速发展离不开高性能计算硬件的支持,而传统CPU由于架构限制,难以高效处理AI任务中的大规模并行计算需求。因此,专为AI优



评论